Find and replace line not starting with pattern and copy text from previous line
-
I have CSV text file which have Chat logs starting with “[” and after that it contains system date & time, there are few lines which not starting with square brackets as chat user may have sent multiples line in that message. Now i want to find all those lines and copy the previous line date & time with sender name in starting of that.
how do I find lines not starting with “[” and than replace text from previous line user with “[ ]” time stamp.
Here is input and desired output file .
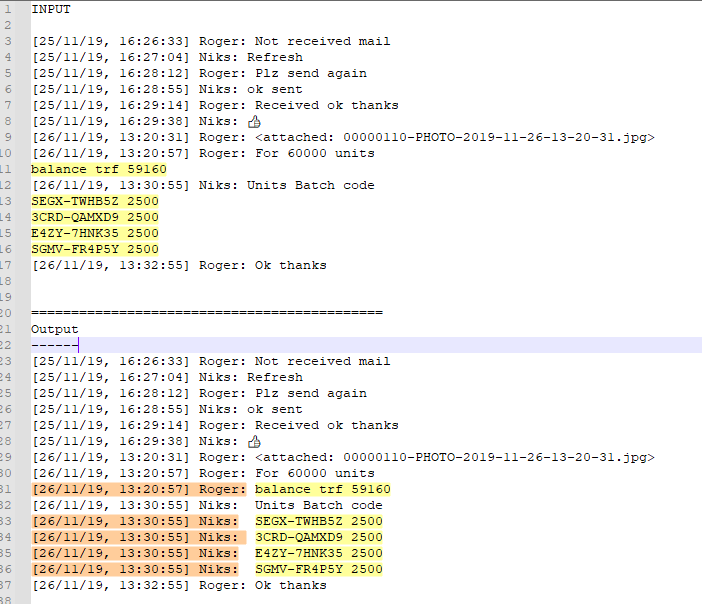
INPUT
[25/11/19, 16:26:33] Roger: Not received mail
[25/11/19, 16:27:04] Niks: Refresh
[25/11/19, 16:28:12] Roger: Plz send again
[25/11/19, 16:28:55] Niks: ok sent
[25/11/19, 16:29:14] Roger: Received ok thanks
[25/11/19, 16:29:38] Niks: 👍🏻
[26/11/19, 13:20:31] Roger: <attached: 00000110-PHOTO-2019-11-26-13-20-31.jpg>
[26/11/19, 13:20:57] Roger: For 60000 units
balance trf 59160
[26/11/19, 13:30:55] Niks: Units Batch code
SEGX-TWHB5Z 2500
3CRD-QAMXD9 2500
E4ZY-7HNK35 2500
SGMV-FR4P5Y 2500
[26/11/19, 13:32:55] Roger: Ok thanks============================================
Output[25/11/19, 16:26:33] Roger: Not received mail
[25/11/19, 16:27:04] Niks: Refresh
[25/11/19, 16:28:12] Roger: Plz send again
[25/11/19, 16:28:55] Niks: ok sent
[25/11/19, 16:29:14] Roger: Received ok thanks
[25/11/19, 16:29:38] Niks: 👍🏻
[26/11/19, 13:20:31] Roger: <attached: 00000110-PHOTO-2019-11-26-13-20-31.jpg>
[26/11/19, 13:20:57] Roger: For 60000 units
[26/11/19, 13:20:57] Roger: balance trf 59160
[26/11/19, 13:30:55] Niks: Units Batch code
[26/11/19, 13:30:55] Niks: SEGX-TWHB5Z 2500
[26/11/19, 13:30:55] Niks: 3CRD-QAMXD9 2500
[26/11/19, 13:30:55] Niks: E4ZY-7HNK35 2500
[26/11/19, 13:30:55] Niks: SGMV-FR4P5Y 2500
[26/11/19, 13:32:55] Roger: Ok thanksFinding lines in Yellow color & replace with Orange text which is taken from previous lines.
Thanks in advance
-
I came up with something that mostly works, except for on the line after the 👍🏻. I haven’t figured out why that is messing up my regex:
- FIND =
(?-s)^(\x5B.*?\x5D.*?:\h*).*$\R\K(?!\x5B) - REPLACE =
$1 - SEARCH MODE = regular expression
- REPLACE ALL multiple times, until it’s really all done
The line after the thumbs-up has difficulty because, as @Alan-Kilborn found a couple years back, such chat logs will occasionally have the U+200E LEFT-TO-RIGHT MARK peppered throughout… and that photo line contains two instances. So before running the regex I showed, also replace
\x{200E}with empty … or I’d suggest[\x{200B}-\x{200F}\x{202A}-\x{202F}]with empty (which will get rid of other zero-width characters).So run the zero-width replacement first, then REPLACE ALL multiple times on the first one I shared until all the lines have that. (If your longest block is four lines that don’t start with
[, you will have to REPLACE ALL four times) - FIND =
-
Hello, @nitin-jain, @peterjones and All,
Oh… Peter beats me at it ! Here is my solution, quite similar !
If you are sure that all the dates are in increasing order, simply use the following regex S/R :
-
Open the Replace dialog (
Ctrl + H) -
SEARCH
(?-s)^(\[.+\]).+\R\K(?=\w) -
REPLACE
\1$0\x20 -
Tick the
Wrap aroundoption -
Select the
Regular repressionsearch mode -
Click several times on the
Replace Allbutton, till you see the message0 occurrences were replaced in entire file
So, from the INPUT text :
[25/11/19, 16:26:33] Roger: Not received mail [25/11/19, 16:27:04] Niks: Refresh [25/11/19, 16:28:12] Roger: Plz send again [25/11/19, 16:28:55] Niks: ok sent [25/11/19, 16:29:14] Roger: Received ok thanks [25/11/19, 16:29:38] Niks: 👍🏻 [26/11/19, 13:20:31] Roger: <attached: 00000110-PHOTO-2019-11-26-13-20-31.jpg> [26/11/19, 13:20:57] Roger: For 60000 units balance trf 59160 [26/11/19, 13:30:55] Niks: Units Batch code SEGX-TWHB5Z 2500 3CRD-QAMXD9 2500 E4ZY-7HNK35 2500 SGMV-FR4P5Y 2500 [26/11/19, 13:32:55] Roger: Ok thanksyou’ll get the expected OUTPUT result :
[25/11/19, 16:26:33] Roger: Not received mail [25/11/19, 16:27:04] Niks: Refresh [25/11/19, 16:28:12] Roger: Plz send again [25/11/19, 16:28:55] Niks: ok sent [25/11/19, 16:29:14] Roger: Received ok thanks [25/11/19, 16:29:38] Niks: 👍🏻 [26/11/19, 13:20:31] Roger: <attached: 00000110-PHOTO-2019-11-26-13-20-31.jpg> [26/11/19, 13:20:57] Roger: For 60000 units [26/11/19, 13:20:57] balance trf 59160 [26/11/19, 13:30:55] Niks: Units Batch code [26/11/19, 13:30:55] SEGX-TWHB5Z 2500 [26/11/19, 13:30:55] 3CRD-QAMXD9 2500 [26/11/19, 13:30:55] E4ZY-7HNK35 2500 [26/11/19, 13:30:55] SGMV-FR4P5Y 2500 [26/11/19, 13:32:55] Roger: Ok thanksBest regards,
guy038
-
-
Hi, all,
I suppose I find out a bug, in our
Boostregex engine !Let’s take this simple example tet :
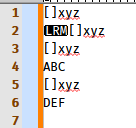
[]xyz []xyz []xyz ABC []xyz DEFNow, the four regexes below, should look for the literal string
[]beginning a line, followed with any non-null string and its line-ending chars, ONLY IF not followed with a leading[symbol !(?-s)^\\[\\].+\R(?!\\[)(?-s)^\\[\\].+\r\n(?!\\[)(?-s)^\x5b\x5d.+\R(?!\x5b)(?-s)^\x5b\x5d.+\r\n(?!\x5b)
Thus, it should only match the txo lines, below :
-
The
[]xyzline before the stringABC -
The
[]xyzline before the stringDEF
But, unfortunately, it also matches the first line
[]xyz???Am I wrong in any way, in this matter ?
BR
guy038
-
-
@guy038 said in Find and replace line not starting with pattern and copy text from previous line:
But, unfortunately, it also matches the first line []xyz ???
Am I wrong in any way, in this matter ?When I copy -n-paste your black box data, there is an LRM in it, which seems to cause your erroneous match!
-
@alan-kilborn said in Find and replace line not starting with pattern and copy text from previous line:
there is an LRM in it, which seems to cause your erroneous match!
Indeed. I was originally going to ask Guy why my regex wasn’t working with the supplied data (the same question Guy asked us), when I happened to left arrow from the
[and stayed on that same line! That told me there was a hidden character, which is why I ran the reveal-hidden-characters script from the old conversation, and I saw the infamous LRM – which is why I added the paragraph to tell @nitin-jain to do the zero-width search/replace before doing the main search/replace. -
Hi, @nitin-jain, @peterjones, @alan-kilborn and All,
Ah ah ! Alan, I, first, didn’t understand why you had the LRM sigle in the second line of my text. My second thought was that you created a Python script to make all these fancy Unicode format characters clearly visible ! But, luckily, marking any
\x{200e}character did the trick and showed me a thin red mark when this special char is present !
So, @nitin-jain, as @peterjones said, use this simple regex S/R, below, to get rid of these format characters !
SEARCH
[\x{200B}-\x{200F}\x{202A}-\x{202F}]REPLACE
Leave EMPTYHowever, verify that this operation does not break down your text in any way ! I personally saw this case, while pasting Unicode characters from a long list, produced by this excellent and valuable site, regarding Unicode :
https://r12a.github.io/uniview/
Now, I’m pleased to note that there is no bug of our
Boostregex engine, in this matter, as that specialLRMchar is quite a character different from a[symbol !BR
guy038
-
@guy038 said in Find and replace line not starting with pattern and copy text from previous line:
Alan, … you created a Python script to make all these fancy Unicode format characters clearly visible
Well, yes, I did. :-)