Enhance UDL lexer
-
-
I’d say the burden is on posters to post in English, not others to translate later. (AFAIK, the accepted language of this forum in English.)
-
Manager summary :-)
I failed at the documentation by stating that comment style is using id 2 and
comment line style is using 1 whereas it is exactly the opposite. -
(AFAIK, the accepted language of this forum in English.)
maybe one accepted language as we see more often :-)
-
But thanks, @Alan-Kilborn,
Chrome used to be my backup browser, but I’ve recently switched to it being my primary, and I didn’t know there was an easy RClick>Translate option in Chrome. When I ran it on the German on this page, it translated okay for me. (Which is good, because my 2 years of highschool German from more than a quarter-century ago just didn’t cut it.)
But I do agree that the forum’s default language is English, and if people want help here, they should at least provide the translation for us. I understand that some of the posters might be more comfortable (or equally comfortable) in German; and it’s fine for someone fluent in German to answer in German; but also provide a translation to English, so the other people who read this thread – both for those who have started to help, and got lost when it switched language; and for those who come here searching for a solution to a similar problem, and find that the actual answer is buried in another language, when it started in English.
-
In the source code I find the place where the numbers are assigned or do not arise.
I would like to find that to be able to understand it.
Then the template would have to be adjusted. -
Ok, :-D
the outcome of the discussion is that I need to post another version of the script
which hopefully adresses @guy038 findings as well,So dear future reader,
if you have read until here - forget about everything you read and hope that you will find
a new version of the script as another post after this one.
:-D -
omg … you are german speaking … that’s the last thing i would have expected … your name sounded so apocalyptically greek 😉
-
starting from line 266.
-
well my name is eren and a nickname is eko.
And you are absolutely right about apocalypse.
In my first week at work, everyone learned that I could be called eko.
At one time I did something terribly wrong which lead to an failure of the
whole production system. My colleague said something like
“this must be the feeling when the 4 apocalyptic riders arrive” and another one
managed to make eko and apocalyptic to result in ekopalypse.
So here comes the ekopalypse :-D -
thanks for the insight, @Ekopalypse
the combination of all, name, mishap at work, and this community, gives way to a perfect book title:… the holy apocalypse and his fantastic 4 riders … 😂😂👍
-
LOL :-D
-
In order to be able to solve the issue about scrolling the second editor
instance and having styling in it, it is needed to have a way to identify which
scintilla instance sent which scintilla notification.
This can be achieved by using the SCI_SETIDENTIFIER as described here.I’ve opened two issues one here and one there to address this.
Hopefully this will be implemented soon.The issue about zooming and word wrap, actually it is a word wrap only issue,
should be solved with this version, also the documentation fix is implemented ;-)# -*- coding: utf-8 -*- from Npp import editor, editor1, editor2, notepad, NOTIFICATION, SCINTILLANOTIFICATION, INDICATORSTYLE import ctypes import ctypes.wintypes as wintypes from collections import OrderedDict regexes = OrderedDict() # ------------------------------------------------- configuration area --------------------------------------------------- # # Define the lexer name exactly as it can be found in the Language menu lexer_name = 'BR! Source' # Definition of colors and regular expressions # Note, the order in which regular expressions will be processed # is determined by its creation, that is, the first definition is processed first, then the 2nd, and so on # # The basic structure always looks like this # # regexes[(a, b)] = (c, d) # # regexes = an ordered dictionary which ensures that the regular expressions are always processed in the same order # a = a unique number - suggestion, start with 0 and always increase by one # b = color in the form of (r,g,b) such as (255,0,0) for the color red # c = raw byte string, describes the regular expression. Example r'\w+' # d = number of the match group to be used # Examples: # All found words which may consist of letter, numbers and the underscore, # with the exception of those that begin with fn, are displayed in a blue-like color. # The results from match group 1 should be used for this. regexes[(0, (79, 175, 239))] = (r'fn\w+\$|(\w+\$)', 1) # All numbers are to be displayed in an orange-like color, the results from # matchgroup 0, the standard matchgroup, should be used for this. regexes[(1, (252, 173, 67))] = (r'\d', 0) # Definition of which area should not be styled # 1 = comment style # 2 = comment line style # 16 = delimiter1 # ... # 23 = delimiter8 excluded_styles = [1, 2, 16, 17, 18, 19, 20, 21, 22, 23] # ------------------------------------------------ /configuration area --------------------------------------------------- try: EnhanceUDLLexer().main() except NameError: user32 = wintypes.WinDLL('user32') WM_USER = 1024 NPPMSG = WM_USER+1000 NPPM_GETLANGUAGEDESC = NPPMSG+84 SC_INDICVALUEBIT = 0x1000000 SC_INDICFLAG_VALUEFORE = 1 class SingletonEnhanceUDLLexer(type): ''' Ensures, more or less, that only one instance of the main class can be instantiated ''' _instance = None def __call__(cls, *args, **kwargs): if cls._instance is None: cls._instance = super(SingletonEnhanceUDLLexer, cls).__call__(*args, **kwargs) return cls._instance class EnhanceUDLLexer(object): ''' Provides additional color options and should be used in conjunction with the built-in UDL function. An indicator is used to avoid style collisions. Although the Scintilla documentation states that indicators 0-7 are reserved for the lexers, indicator 0 is used because UDL uses none internally. Even when using more than one regex, it is not necessary to define more than one indicator because the class uses the flag SC_INDICFLAG_VALUEFORE. See https://www.scintilla.org/ScintillaDoc.html#Indicators for more information on that topic ''' __metaclass__ = SingletonEnhanceUDLLexer def __init__(self): ''' Instantiated the class, because of __metaclass__ = ... usage, is called once only. ''' editor.callbackSync(self.on_updateui, [SCINTILLANOTIFICATION.UPDATEUI]) notepad.callback(self.on_langchanged, [NOTIFICATION.LANGCHANGED]) notepad.callback(self.on_bufferactivated, [NOTIFICATION.BUFFERACTIVATED]) self.doc_is_of_interest = False self.lexer_name = None self.npp_hwnd = user32.FindWindowW(u'Notepad++', None) self.configure() @staticmethod def rgb(r, g, b): ''' Helper function Retrieves rgb color triple and converts it into its integer representation Args: r = integer, red color value in range of 0-255 g = integer, green color value in range of 0-255 b = integer, blue color value in range of 0-255 Returns: integer ''' return (b << 16) + (g << 8) + r @staticmethod def paint_it(color, pos, length): ''' This is where the actual coloring takes place. Color, the position of the first character and the length of the text to be colored must be provided. Coloring occurs only if the position is not within the excluded range. Args: color = integer, expected in range of 0-16777215 pos = integer, denotes the start position length = integer, denotes how many chars need to be colored. Returns: None ''' if pos < 0 or editor.getStyleAt(pos) in excluded_styles: return editor.setIndicatorCurrent(0) editor.setIndicatorValue(color) editor.indicatorFillRange(pos, length) def style(self): ''' Calculates the text area to be searched for in the current document. Calls up the regexes to find the position and calculates the length of the text to be colored. Deletes the old indicators before setting new ones. Args: None Returns: None ''' start_line = editor.docLineFromVisible(editor.getFirstVisibleLine()) end_line = editor.docLineFromVisible(start_line + editor.linesOnScreen()) start_position = editor.positionFromLine(start_line) end_position = editor.getLineEndPosition(end_line) editor.setIndicatorCurrent(0) editor.indicatorClearRange(0, editor.getTextLength()) for color, regex in self.regexes.items(): editor.research(regex[0], lambda m: self.paint_it(color[1], m.span(regex[1])[0], m.span(regex[1])[1] - m.span(regex[1])[0]), 0, start_position, end_position) def configure(self): ''' Define basic indicator settings, the needed regexes as well as the lexer name. Args: None Returns: None ''' editor1.indicSetStyle(0, INDICATORSTYLE.TEXTFORE) editor1.indicSetFlags(0, SC_INDICFLAG_VALUEFORE) editor2.indicSetStyle(0, INDICATORSTYLE.TEXTFORE) editor2.indicSetFlags(0, SC_INDICFLAG_VALUEFORE) self.regexes = OrderedDict([ ((k[0], self.rgb(*k[1]) | SC_INDICVALUEBIT), v) for k, v in regexes.items() ]) self.lexer_name = u'User Defined language file - %s' % lexer_name def check_lexer(self): ''' Checks if the current document is of interest and sets the flag accordingly Args: None Returns: None ''' language = notepad.getLangType() length = user32.SendMessageW(self.npp_hwnd, NPPM_GETLANGUAGEDESC, language, None) buffer = ctypes.create_unicode_buffer(u' ' * length) user32.SendMessageW(self.npp_hwnd, NPPM_GETLANGUAGEDESC, language, ctypes.byref(buffer)) self.doc_is_of_interest = True if buffer.value == self.lexer_name else False def on_bufferactivated(self, args): ''' Callback which gets called every time one switches a document. Triggers the check if the document is of interest. Args: provided by notepad object but none are of interest Returns: None ''' self.check_lexer() def on_updateui(self, args): ''' Callback which gets called every time scintilla (aka the editor) changed something within the document. Triggers the styling function if the document is of interest. Args: provided by scintilla but none are of interest Returns: None ''' if self.doc_is_of_interest: self.style() def on_langchanged(self, args): ''' Callback gets called every time one uses the Language menu to set a lexer Triggers the check if the document is of interest Args: provided by notepad object but none are of interest Returns: None ''' self.check_lexer() def main(self): ''' Main function entry point. Simulates two events to enforce detection of current document and potential styling. Args: None Returns: None ''' self.on_bufferactivated(None) self.on_updateui(None) EnhanceUDLLexer().main() -
@Ekopalypse said:
I’ve opened two issues one here and one there to address this.
I don’t mean to be a debbie downer but good luck with the “there” one. The “here” one is much more likely to happen, although it seems that even PS development has slowed way down after being encouragingly active for a while.
-
Hopefully this will be implemented soon.
my experience says this is rather “en attendant godot” or “warten auf godot” ;-)
-
@Ekopalypse
What is this script for, please ?
I have come here, because I was looking up existing Notepad++ issues, have found this https://github.com/notepad-plus-plus/notepad-plus-plus/issues/7622 and followed a link in a comment pointing to here.My problem is that I am trying to configure a UDL in Notebook++ for Jenkins Pipeline syntax,
but the UDL lexer in Notepad++ does not find and colour string “stage” if there is “stage(”.Can I use your script to replace the Notepad++’ lexer ?
BR
Rainer
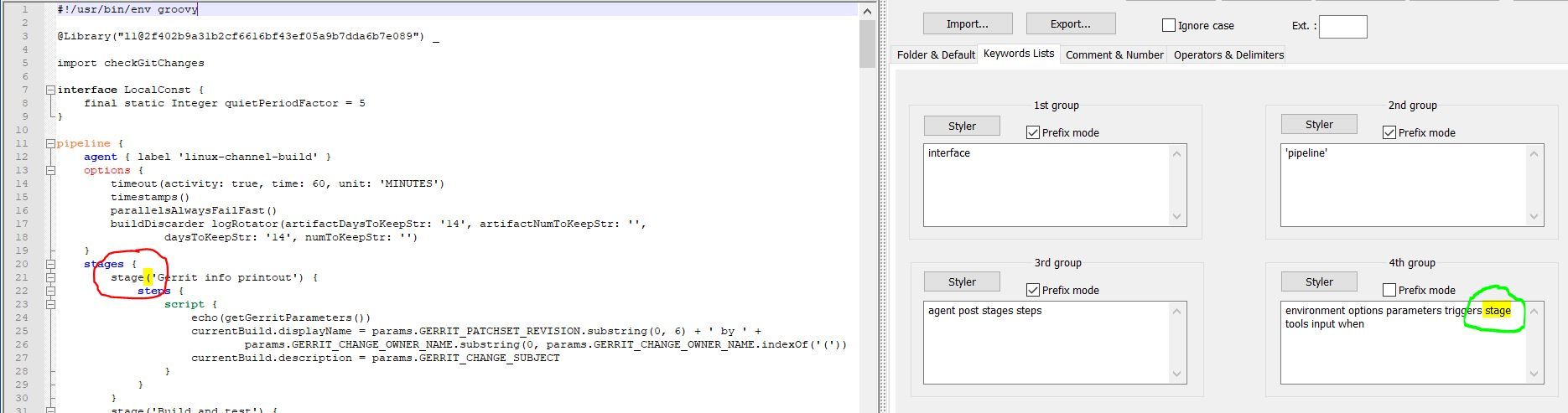
-
If this is still an issue for you, let me know.
The idea of the script is to enhance the existing UDL
with coloring which otherwise isn’t possible to do
with the builtin lexer, means, script, normally,
runs together with the UDL lexer. -
I found this and am quite interested in it but am not sure how to implement this. I’m an engineer not a CS so my programing is only fair. Can someone tell me how to actually use this in notepad++ or where to go to read what I will need to get it going? Thanks
-
You must have installed the PythonScript plugin, which you can do via PluginAdmin in the plugin menu.
Use plugins->pythonscript->new script and save it under a meaningful name. Copy the content from here into the script.
Save it. Now you need to define the regexes to add additional colours to the lexer. The script is commented, let me know if anything is unclear.
-
@ekopalypse
I have now had a chance to give this a solid go and have not been able to get it working. To start with I installed the PythonScript plugin.In your comments I do not understand what is meant by “d = integer, denotes which match group should be considered” because I’m not clear on what a match group does.
I defined my own user defined language ml and then just tried to highlight letters in one color and digits in another. I followed your examples and now have the following in the file:
ml_regexes = _dict()
ml_regexes = [(0, (0, 0, 224))] = (r’\d’, 0)
ml_regexes = [(1, (224, 0, 0))] = (r’\w’, 0)
ml_excluded_styles = []
_enhance_lexer = EnhanceLexer()
_enhance_lecer.register_lexer(‘ml’, ml_regexes, ml_excluded_styles)I saved the modified code as ml.py in the folder C:\Users\CS_laptop\AppData\Roaming\Notepad++\plugins\config\PythonScript\scripts
Then I made a new file to test with containing the following:
hello
12345I set language to the empty user defined language ml.
Then I went to Plugins>Python Scripts>scripts> and selected ml.
This produced no result.Please let me know where I have gone wrong. Thanks for your help.