How to bookmark lines around a line containing a specific expression 'XXX' ?
-
Hi, All,
From that issue created in August 2019 by @scott-sumner ( Scott, thanks for your many GitHub contributions ! )
https://github.com/notepad-plus-plus/notepad-plus-plus/issues/6018
and the commit :
https://github.com/alberto-dev/notepad-plus-plus/commit/520678cf1bc20bf701bc130564463a40e2391cef
We are, from now on, able to mark any non-empty line, involved in a multi-lines search ;-))
Due to this nice improvement, my previous post, below, about multi-lines bookmarking is rather obsolete :-(
https://notepad-plus-plus.org/community/topic/16701/how-to-mark-lines-above-marked-lines/8
So, here is an updated version ;-))
Notes :
-
First, you’re presently using the Notepad++ version
7.8or above -
I assume that you’re using the
Edit > Mark...dialog :-
The options
Bookmark lines,Purge for each searchandWrap aroundare ticked -
The
Regular expressionmode is selected
-
-
The search process is supposed to be sensitive to case, due to the
(?-i)in-line modifier -
To simplify, I assume that the lines, containing the
XXXcriterion, do not overlap with the lines around, which need bookmarking !
Edited on 11-16-2019
The end of this present post is rather obsolete and/or erroneous, as my updated regexes can, now, handle pure empty lines, too !
So you should better to refer to the next post, below :
https://community.notepad-plus-plus.org/post/48541
-
You certainly noticed that the marking feature does not bookmark empty lines. So, if your text contains empty lines, that you would like to bookmark, too, a possible work-around could be to use a dummy character, not used yet in your file and, temporarily, replace any true empty line with some of these dummy chars, using the following regex S/R :
-
SEARCH
^(?=\R) -
REPLACE
###, if the#symbol is presently absent from your file contents
-
After the red-marking and bookmarking operation, with an appropriate search regex :
-
In your original file, just perform an
Edit > Undooperation ( orCtrl + Z) -
In the new tab, where you would had copied all the bookmarked lines (
Search > Bookmark > Copy Bookmarked Lines) run this simple regex S/R :-
SEARCH
^### -
REPLACE
Leave EMPTY
-
This first table, below, shows how to mark consecutive lines, around a line containing a specific expression
XXX. Almost obvious ;-))•======================================================•===========•==========•===========• | REGULAR expression to mark Line X, containing 'XXX' | Nth lines | Line X | Mth lines | | and Nth lines BEFORE and/or Mth lines AFTER line X | BEFORE | | AFTER | •======================================================•===========•==========•===========• | (?-is)^(.+\R){N}(?=.*XXX) | YES | NO | NO | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^.*XXX.*\R\K(.+\R){M} | NO | NO | YES | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^(.+\R){N}(?=.*XXX)|^.*XXX.*\R\K(.+\R){M} | YES | NO | YES | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^.*XXX.* ( TRIVIAL case ) | NO | YES | NO | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^(.+\R){N}.*XXX.* | YES | YES | NO | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^.*XXX.*\R(.+\R){M} | NO | YES | YES | •------------------------------------------------------•-----------•----------•-----------• | (?-is)^(.+\R){N}.*XXX.*\R(.+\R){M} | YES | YES | YES | | (?-is)^(.+\R){N}.*XXX.*\R(?1){M} | | | | •======================================================•===========•==========•===========•IMPORTANT :
Of course, you must replace the
NandMvariables, in the regexes, with an non-null integer, standing for the number of wanted lines, respectively, before and after the specific line X !
In this second table, here are the regexes which does NOT bookmark any
Line X, but only the1or2lines around theLine X:•=========================================================•==========•==========•==========•==========•==========• | REGULAR expression, marking ONE or TWO lines, BEFORE | 2nd line | 1st line | Line X | 1st line | 2nd line | | / AFTER a line X, containing 'XXX', except the line X | BEFORE | BEFORE | | AFTER | AFTER | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*XXX.*\R.+\R\K.+ | NO | NO | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R\K.+ | NO | NO | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R\K.+\R.+ | NO | NO | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+(?=\R.*XXX) | NO | YES | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.*XXX)|^.*XXX.*\R.+\R\K.+ | NO | YES | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.*XXX)|^.*XXX.*\R\K.+ | NO | YES | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.*XXX)|^.*XXX.*\R\K.+\R.+ | NO | YES | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+(?=\R.+\R.*XXX) | YES | NO | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R.+\R\K.+ | YES | NO | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R\K.+ | YES | NO | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R\K.+\R.+ | YES | NO | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+\R.+(?=\R.*XXX) | YES | YES | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+(?=\R.*XXX)|^.*XXX.*\R.+\R\K.+ | YES | YES | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+(?=\R.*XXX)|^.*XXX.*\R\K.+ | YES | YES | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+(?=\R.*XXX)|^.*XXX.*\R\K.+\R.+ | YES | YES | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========•
- In the third table, here are the regexes which do bookmark the
Line X, as well as1or2lines aroundLine X:
•=========================================================•==========•==========•==========•==========•==========• | REGULAR expression, marking line X, containing 'XXX', | 2nd line | 1st line | Line X | 1st line | 2nd line | | as well as ONE or TWO lines, BEFORE / AFTER line X | BEFORE | BEFORE | | AFTER | AFTER | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*XXX.* ( Trivial case ) | NO | NO | YES | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R|\G.+\R\K.+ | NO | NO | YES | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R.+ | NO | NO | YES | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R.+\R.+ | NO | NO | YES | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+\R.*XXX.* | NO | YES | YES | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.*XXX.*\R|\G.+\R\K.+ | NO | YES | YES | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.*XXX.*\R.+ | NO | YES | YES | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.*XXX.*\R.+\R.+ | NO | YES | YES | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.* | YES | NO | YES | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R|\G.+\R\K.+ | YES | NO | YES | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R.+ | YES | NO | YES | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+(?=\R.+\R.*XXX)|^.*XXX.*\R.+\R.+ | YES | NO | YES | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.+\R.+\R.*XXX.* | YES | YES | YES | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+\R.*XXX.*\R|\G.+\R\K.+ | YES | YES | YES | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+\R.*XXX.*\R.+ | YES | YES | YES | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.+\R.+\R.*XXX.*\R.+\R.+ | YES | YES | YES | YES | YES | •=========================================================•==========•==========•==========•==========•==========•
Although, the different regexes still seem rather difficult to interpret, there are more simple than before ;-))
Best Regards
guy038
-
-
@guy038 said
…and the commit…
https://github.com/alberto-dev/notepad-plus-plus/commit/...I think here is the REAL commit into Notepad++ master source for this: https://github.com/notepad-plus-plus/notepad-plus-plus/commit/132441867e48240153e3b84c6e2b213ba3e0655e
I’m not sure who “alberto” is…
-
@guy038 said
We are, from now on, able to mark any non-empty line, involved in a multi-lines search ;-))
Why is the qualifier “non-empty” used here? I can make it mark empty lines as well; example:
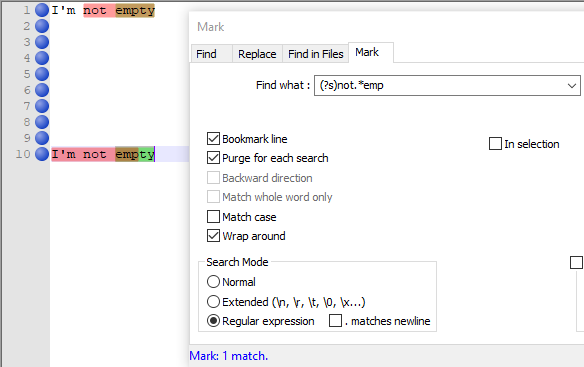
-
Hi @alan-kilborn and All,
Good point, Alan ! Indeed, your example works fine, too, on my configuration ;-)) It’s a chance that I wanted to be specific, mentioning “not empty” lines ! Luckily, I understood what happens :
Consider the simple regex
(?-is).*, against any text containing several pure empty lines, only. Obviously, the regex matches a zero length empty string, in any empty line. And, if your try to mark and bookmark these lines nothing is displayed on screen !Now, slightly change the regex as
(?-is).*\R, against this multi-lines empty text. This time, the regex does match any EOF characters. So, if you use theMarkfeature, with theBookmark lineoption ticked, all these empty lines are normally bookmarked, and, if you click on theShow All Charactersbutton, of the toolbar, theCRand/orLFcontrol characters, of each pure blank line, are well highlighted in red, as expected !In some of my regexes, in order to shorten them, I did not end them with the
\Rsyntax. Thus, this made me think, wrongly, that using the star quantifier*, instead of the plus quantifier+was useless, anyway and that empty lines could not be bookmarked :-((But it is not ! So, thanks to you, Alan, I’m going to reexamine all the regexes, described in my previous post, changing, as much as possible, any
+quantifier with a*quantifier and adding the\Rsyntax.See you later,
Best Regards,
guy038
-
Hi, All,
So I’ve updated all my previous regexes, in order to bookmark pure empty lines, as well ! ( They do not contain the
+quantifier, anymore ! )
This first table, below, shows how to mark consecutive lines, around a line containing a specific expression
XXX. Almost obvious ;-))•===•======================================================•===========•==========•===========• | | REGULAR expression to mark Line X, containing 'XXX' | Nth lines | Line X | Mth lines | | | and Nth lines BEFORE and/or Mth lines AFTER line X | BEFORE | | AFTER | •===•======================================================•===========•==========•===========• | | (?-is)^(.*\R){N}(?=.*XXX) | YES | NO | NO | •---•------------------------------------------------------•-----------•----------•-----------• | | (?-is)^.*XXX.*\R\K(.*\R){M} | NO | NO | YES | •---•------------------------------------------------------•-----------•----------•-----------• | X | (?-is)^(.*\R){N}(?=.*XXX)|.*XXX.*\R\K(.*\R){M} | YES | NO | YES | •---•------------------------------------------------------•-----------•----------•-----------• | | (?-is)^.*XXX.* ( TRIVIAL case ) | NO | YES | NO | •---•------------------------------------------------------•-----------•----------•-----------• | | (?-is)^(.*\R){N}.*XXX.* | YES | YES | NO | •---•------------------------------------------------------•-----------•----------•-----------• | | (?-is)^.*XXX.*\R(.*\R){M} | NO | YES | YES | •---•------------------------------------------------------•-----------•----------•-----------• | Y | (?-is)^(.*\R){N}.*XXX.*\R(.*\R){M} | YES | YES | YES | •===•======================================================•===========•==========•===========•Notes :
-
You must replace the
NandMvariables, in the regexes, with an integer, standing for the number of wanted lines, respectively, before and after the specific line X ! -
If you choose
N = 0and/orM = 0, the different regexes still work ! So, with the help of the regexes identified with an,XorYyou can, as well, solve all the described cases ;-)) -
However, if you choose
N = 0andM <> 0, the regex, identified with anX, will not work properly when a criterionXXXbegins a line
In this second table, here are the regexes which does NOT bookmark any
Line X, but only the1or2lines around theLine X:•=========================================================•==========•==========•==========•==========•==========• | REGULAR expression, marking ONE or TWO lines, BEFORE | 2nd line | 1st line | Line X | 1st line | 2nd line | | / AFTER a line X, containing 'XXX', except the line X | BEFORE | BEFORE | | AFTER | AFTER | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*XXX.*\R.*\R\K.*\R | NO | NO | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R\K.*\R | NO | NO | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*XXX.*\R\K.*\R.*\R | NO | NO | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*\R(?=.*XXX) | NO | YES | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*XXX)|^.*XXX.*\R.*\R\K.*\R | NO | YES | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*XXX)|^.*XXX.*\R\K.*\R | NO | YES | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*XXX)|^.*XXX.*\R\K.*\R.*\R | NO | YES | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*\R(?=.*\R.*XXX) | YES | NO | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.*\R.*\R\K.*\R | YES | NO | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.*\R\K.*\R | YES | NO | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.*\R\K.*\R.*\R | YES | NO | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========• | (?-is)^.*\R.*\R(?=.*XXX) | YES | YES | NO | NO | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R.*\R(?=.*XXX)|^.*XXX.*\R.*\R\K.*\R | YES | YES | NO | NO | YES | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R.*\R(?=.*XXX)|^.*XXX.*\R\K.*\R | YES | YES | NO | YES | NO | •---------------------------------------------------------•----------•----------•----------•----------•----------• | (?-is)^.*\R.*\R(?=.*XXX)|^.*XXX.*\R\K.*\R.*\R | YES | YES | NO | YES | YES | •=========================================================•==========•==========•==========•==========•==========•
- In the third table, here are the regexes which do bookmark the
Line X, as well as1or2lines aroundLine X:
•===•===========================================================•==========•==========•==========•==========•==========• | | REGULAR expression, marking line X, containing 'XXX', | 2nd line | 1st line | Line X | 1st line | 2nd line | | | as well as ONE or TWO lines, BEFORE / AFTER line X | BEFORE | BEFORE | | AFTER | AFTER | •===•===========================================================•==========•==========•==========•==========•==========• | | (?-is)^.*XXX.* ( Trivial case ) | NO | NO | YES | NO | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | X | (?-is)^.*(?=XXX)|\GXXX.*\R.*\R\K.*\R | NO | NO | YES | NO | YES | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*XXX.*\R.*\R | NO | NO | YES | YES | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*XXX.*\R.*\R.*\R | NO | NO | YES | YES | YES | •===•===========================================================•==========•==========•==========•==========•==========• | | (?-is)^.*\R.*XXX.* | NO | YES | YES | NO | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | X | (?-is)^.*\R.*(?=XXX)|\GXXX.*\R.*\R\K.*\R | NO | YES | YES | NO | YES | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R.*XXX.*\R.*\R | NO | YES | YES | YES | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R.*XXX.*\R.*\R.*\R | NO | YES | YES | YES | YES | •===•===========================================================•==========•==========•==========•==========•==========• | | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.* | YES | NO | YES | NO | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | X | (?-is)^.*\R(?=.*\R.*XXX)|^.*(?=XXX)|\GXXX.*\R.*\R\K.*\R | YES | NO | YES | NO | YES | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.*\R.*\R | YES | NO | YES | YES | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R(?=.*\R.*XXX)|^.*XXX.*\R.*\R.*\R | YES | NO | YES | YES | YES | •===•===========================================================•==========•==========•==========•==========•==========• | | (?-is)^.*\R.*\R.*XXX.* | YES | YES | YES | NO | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | X | (?-is)^.*\R.*\R.*(?=XXX)|\GXXX.*\R.*\R\K.*\R | YES | YES | YES | NO | YES | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R.*\R.*XXX.*\R.*\R | YES | YES | YES | YES | NO | •---•-----------------------------------------------------------•----------•----------•----------•----------•----------• | | (?-is)^.*\R.*\R.*XXX.*\R.*\R.*\R | YES | YES | YES | YES | YES | •===•===========================================================•==========•==========•==========•==========•==========•Notes :
-
Due to the
\Gsyntax, in the4regexes, identified with anX, results are not correct when a criterionXXXbegins a line -
When these regexes are used and that the criterion
XXX, does not begin a line, as a side-effect, the only characters, beforeXXX, will be red-marked. But, luckily, any line, containingXXX, will be correctly bookmarked :-))
Best Regards,
guy038
-
-
@guy038 said:
…the regex matches a zero length empty string, in any empty line. And, if your try to mark and bookmark these lines nothing is displayed on screen !
Yes, I suppose that one needs to keep in mind that if a (successful) operation results in no marked text (such as a zero-length match) then as a consequence there is not going to be any bookmarked line either.
-
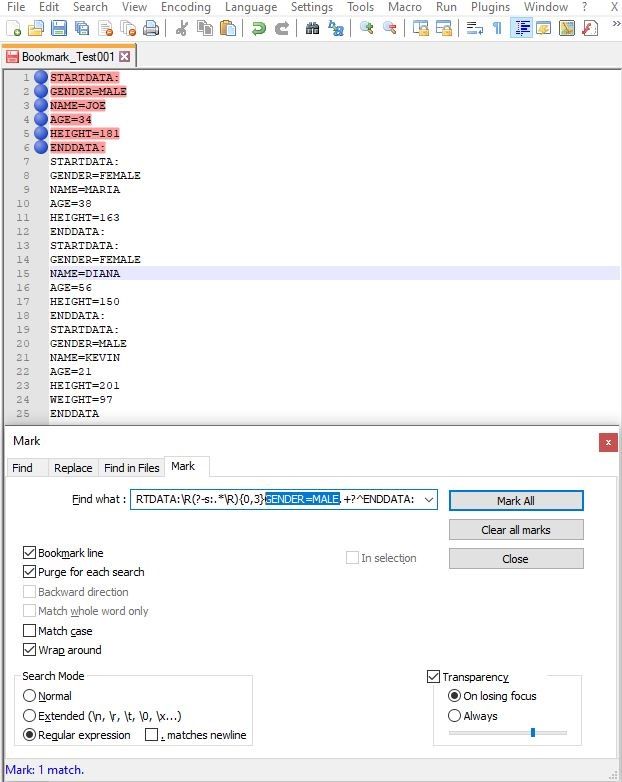
Hi,
I tried to understand this topic and wonder how to solve the following task:Below is a list with various data – and I would like to Mark a ’Bookmark Line’ for all the Data for ’GENDER=MALE’. I want to Mark all lines between the words “STARTDATA” and “ENDDATA” for every found ’GENDER=MALE’ as seen in the Before and After text below.
As seen below - the 2nd found ’GENDER=MALE’ contains one more extra line between its “STARTDATA” and “ENDDATA”.
The EXAMPLE USE CASE:
How the Data looks like BEFORE:
STARTDATA:
GENDER=MALE
NAME=JOE
AGE=34
HEIGHT=181
ENDDATA:
STARTDATA:
GENDER=FEMALE
NAME=MARIA
AGE=38
HEIGHT=163
ENDDATA:
STARTDATA:
GENDER=FEMALE
NAME=DIANA
AGE=56
HEIGHT=150
ENDDATA:
STARTDATA:
GENDER=MALE
NAME=KEVIN
AGE=21
HEIGHT=201
WEIGHT=97
ENDDATA:The requested Data AFTER where I also added the Line Numbers and dots just for highlight.
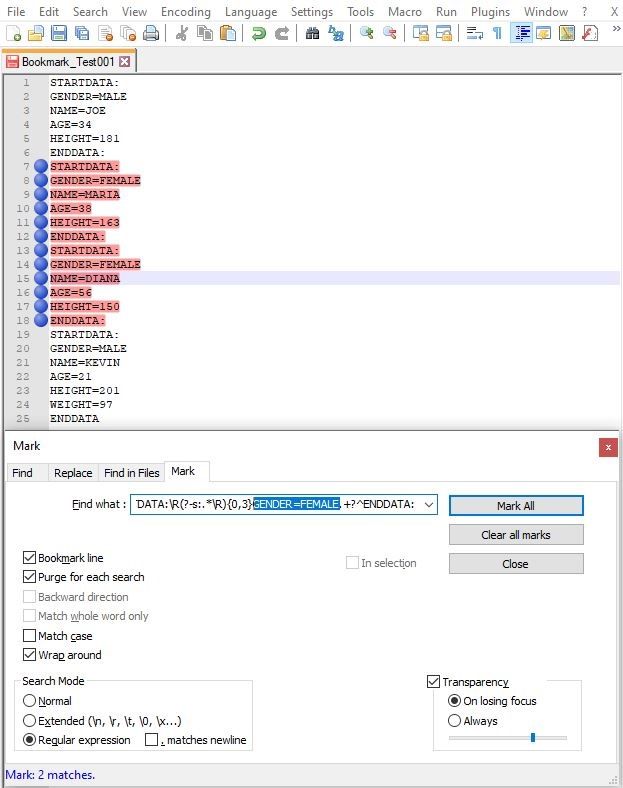
1 • STARTDATA:
2 • GENDER=MALE
3 • NAME=JOE
4 • AGE=34
5 • HEIGHT=181
6 • ENDDATA:
7 STARTDATA:
8 GENDER=FEMALE
9 NAME=MARIA
10 AGE=38
11 HEIGHT=163
12 ENDDATA:
13 STARTDATA:
14 GENDER=FEMALE
15 NAME=DIANA
16 AGE=56
17 HEIGHT=150
18 ENDDATA:
19 • STARTDATA:
20 • GENDER=MALE
21 • NAME=KEVIN
22 • AGE=21
23 • HEIGHT=201
24 • WEIGHT=97
25 • ENDDATA:Thanks a lot,
-
Hello, @notpad001, and All,
First, thanks for your exact description of your problem :-))
Ah… I see ! My regexes described in previous posts, of this topic, are useless, in your case, because you may not have the same number of lines, between your criterion
GENDER= MALEand the end of the current sectionENDDATA:. The previous regex examples are line-oriented ( because of the(?-is)syntax ) and catch an exact amount of lines !In your case, we must use the no-single line concept, so the syntax
(?s-i), which allows the regex engine to consider that the dot regex symbol.matches absolutely any single character, including EOL chars. In other words, the regex will be able to match any multi-lines range of text !
Then, if we assume that the line
GENDER=.....comes right after the lineSTARTDATA:, the following regex could be the right one !SEARCH
(?s-i)^STARTDATA:\RGENDER=MALE.+?^ENDDATA:Notes :
-
I suppose that the search is sensible to case. If NOT, simply change the beginning of the regex as
(?si) -
Now, it looks for any line
STARTDATA:, beginning a line (^), followed with its line-break (\R) and the lineGENDER=MALE -
Then the part
.+?tries to match the shortest non-null range of any character, till the lineENDDATA:, beginning a line (^) -
All lines, even partially, involved in the match, are then bookmarked
Remark : In case the line
GENDER=.....is preceded with a fix or variable amount of line(s), even empty, use the generic regex :SEARCH
(?s-i)^STARTDATA:\R(?-s:.*\R){N,M} GENDER=MALE.+?^ENDDATA:For instance, if we suppose this initial text :
STARTDATA: 11111 3333 GENDER=MALE NAME=JOE AGE=34 HEIGHT=181 ENDDATA: STARTDATA: GENDER=FEMALE NAME=MARIA AGE=38 HEIGHT=163 ENDDATA: STARTDATA: GENDER=MALE NAME=JOHN AGE=37 HEIGHT=197 WEIGHT=105 ENDDATA: STARTDATA: GENDER=FEMALE NAME=DIANA AGE=56 HEIGHT=150 ENDDATA: STARTDATA: 1111 2222 GENDER=MALE NAME=KEVIN AGE=21 HEIGHT=201 WEIGHT=97 ENDDATA:
The regex :
(?s-i)^STARTDATA:\R(?-s:.*\R){0,3}GENDER=MALE.+?^ENDDATA:correctly mark the sections, containing the line
GENDER=MALE, if it exists from0to3lines between a lineSTARTDATA:and its lineGENDER=MALENote :
-
The part
(?-s:begins a non-capturing group and any dot regex symbol, inside this non-capturing group, will match a single standard char ( not EOL ones ) -
The part
{0,3}matches from0to3complete lines, with their line-break(s).*\R, located before the lineGENDER=MALE
Best Regards
guy038
-
-
Thanks guy038 and this was very good help –and looks promising! - but I have a dilemma:
For GENDER=MALE I used the regex (?s-i)^STARTDATA:\R(?-s:.*\R){0,3}GENDER=MALE.+?^ENDDATA:
=> This correctly Marked row 1-6 (Great)
However: Row 19-25 was not MarkedFor GENDER=FEMALE I used the regex (?s-i)^STARTDATA:\R(?-s:.*\R){0,3}GENDER=FEMALE.+?^ENDDATA:
=> This correctly Marked Two set of FEMALE rows 7-12 and 13-18 (Great)The dilemma is that the file I have contains a lot of data and I want to be able to filter out all GENDER=MALE date. (Row 1-6 and 19-25)
I toggled:
Bookmark line ticked
Purge for each search
Wrap around
Regular expressionThanks a lot!
-
Hi NotPad001 and All,
Ah ! I understood why the regex does not match the
2ndsection withGENDER=MALEDon’t you see it ? Well, seemingly, from your picture, the last line ( line25) does not end with a colon character ! And it’s obvious that searching fromGENDER=FEMALEsections worked perfectly right ;-))So the correct regex to process is :
SEARCH
(?s-i)^STARTDATA:\R(?-s:.*\R){0,3}GENDER=MALE.+?^ENDDATA:?I just added a regex question mark symbol (
?), which is a shorthand of the{0,1}quantifier, at the end of the regexBTW, note that, if the line
GENDER=....is located right after theSTARTDATA:line, you may simply use the shorter regex :SEARCH
(?s-i)^STARTDATA:\RGENDER=MALE.+?^ENDDATA:?
Now, there are a lot of methods to filter out your text : Let’s suppose that you want to keep sections with
GENDER=MALE, only :-
First, you could use an option from the Bookmark menu (
Search > Bookmark)-
Bookmark sections containing
GENDER=MALE, with the appropriate regex and, then, use the optionSearch > Bookmark > Remove Unmarked lines -
Bookmark sections containing
GENDER=FEMALE, with the appropriate regex and, then, use the optionSearch > Bookmark > Remove Bookmarked lines
-
-
Secondly, you could use one of the two regex S/R, below, (
Ctrl + H), directly, searching forGENDER=FEMALEsections and clicking on theReplace Allbutton :-
SEARCH
(?s-i)^STARTDATA:\RGENDER=FEMALE.+?^ENDDATA:?\R? -
REPLACE
Leave EMPTY -
SEARCH
(?s-i)^STARTDATA:\R(?-s:.*\R){M,N}GENDER=FEMALE.+?^ENDDATA:?\R? -
REPLACE
Leave EMPTY
-
Remark that, in order to delete the entire lines
ENDDATA:, we need to add the part\R?at the end of the regexes to match the line-break of linesENDDATA(:)too, which is optional, in case that the very last line of your file is not followed with a line-break !Best regards,
guy038
-
-
Thanks guy038 – you are spot on!
Now it works very well after I included the missing : on the last row in my example. My fault – and I will be more observant! Also thanks for the additional information. You know your stuff!!Related questions on this topic:
Is it possible to include wildcard search criteria such as instead of searching for GENDER=MALE you only search for NDER=MA in a similar way as using the star (*) in front of NDER=MA when searching for things in Excel. The requested result is to Bookmark Line the same lines as in the example that you guy038 solved.Because: I noticed that in case I have spaces in front of the GENDER=MALE – I cannot get it to work. Do you have any ideas how to solve that use case?
Example: GENDER=MALE has 2 spaces in front of it – but the number of spaces can vary. Ideally I would like to use the wildcard approach as well in the cases where there are spaces in front of the text.
Also: In case the lines STARTDATA: and ENDDATA: also have empty Spaces in front of it – can that be captured as well? The use case is to mark the same Lines as successfully marked in the example that you guy038 fixed.
Thanks a lot!
-
@NotPad001 said in How to bookmark lines around a line containing a specific expression 'XXX' ?:
wildcard search criteria
You should pay closer attention.
@guy038 is attempting to educate you about “regular expressions”.
To even speak of “wildcard search” in the same breath is blasphemous. -
Hello, @notpad001 and All,
No problem ! We just have to add the regex
\h*, matching any range, even null, of horizontal blank characters, so, mainly, the tab and space chars, at every beginning of line of the regexSo, in case you want to keep sections, containing the
GENDER=MALEstring, this would result in the *new regex syntaxes, below :-
SEARCH
(?s-i)^\h*STARTDATA:\R\h*GENDER=FEMALE.+?^\h*ENDDATA:?\R? -
REPLACE
Leave EMPTY
OR
-
SEARCH
(?s-i)^\h*STARTDATA:\R(?-s:.*\R){M,N}\h*GENDER=FEMALE.+?^\h*ENDDATA:?\R?( Do not forget to replace M and N variables with true integers ! ) -
REPLACE
Leave EMPTY
Test, for example, the regex
(?s-i)^\h*STARTDATA:\R\h*GENDER=FEMALE.+?^\h*ENDDATA:?\R?against the text, below :STARTDATA: GENDER=MALE NAME=JOE AGE=34 HEIGHT=181 ENDDATA: STARTDATA: GENDER=FEMALE NAME=MARIA AGE=38 HEIGHT=163 ENDDATA: STARTDATA: GENDER=FEMALE NAME=DIANA AGE=56 HEIGHT=150 ENDDATA: STARTDATA: GENDER=MALE NAME=KEVIN AGE=21 HEIGHT=201 WEIGHT=97 ENDDATA:You should get the text :
STARTDATA: GENDER=MALE NAME=JOE AGE=34 HEIGHT=181 ENDDATA: STARTDATA: GENDER=MALE NAME=KEVIN AGE=21 HEIGHT=201 WEIGHT=97 ENDDATA:And, in order to delete any blank character, after the first
Ncharacters of each line :-
Use the
Edit > Blank Operations > TAB to Spacemenu option to replace each tab char with its appropriate number of space character(s) -
Secondly, use this generic regex S/R, which will delete any space char, after the first
N: characters of the each line-
SEARCH
^\x20{N}\K\x20+( we’ll use, in our case, the real regex^\x20{4}\K\x20+) -
REPLACE
Leave EMPTY
-
After clicking on the
Replace Allbutton, exclusively, you’re left with that expected result :STARTDATA: GENDER=MALE NAME=JOE AGE=34 HEIGHT=181 ENDDATA: STARTDATA: GENDER=MALE NAME=KEVIN AGE=21 HEIGHT=201 WEIGHT=97 ENDDATA:Cheers,
guy038
-
-
Hi, @notpad001, @alan-kilborn,
Alan, I wouldn’t say it is blasphemous, but rather inappropriate !
BR
guy038
-
@guy038
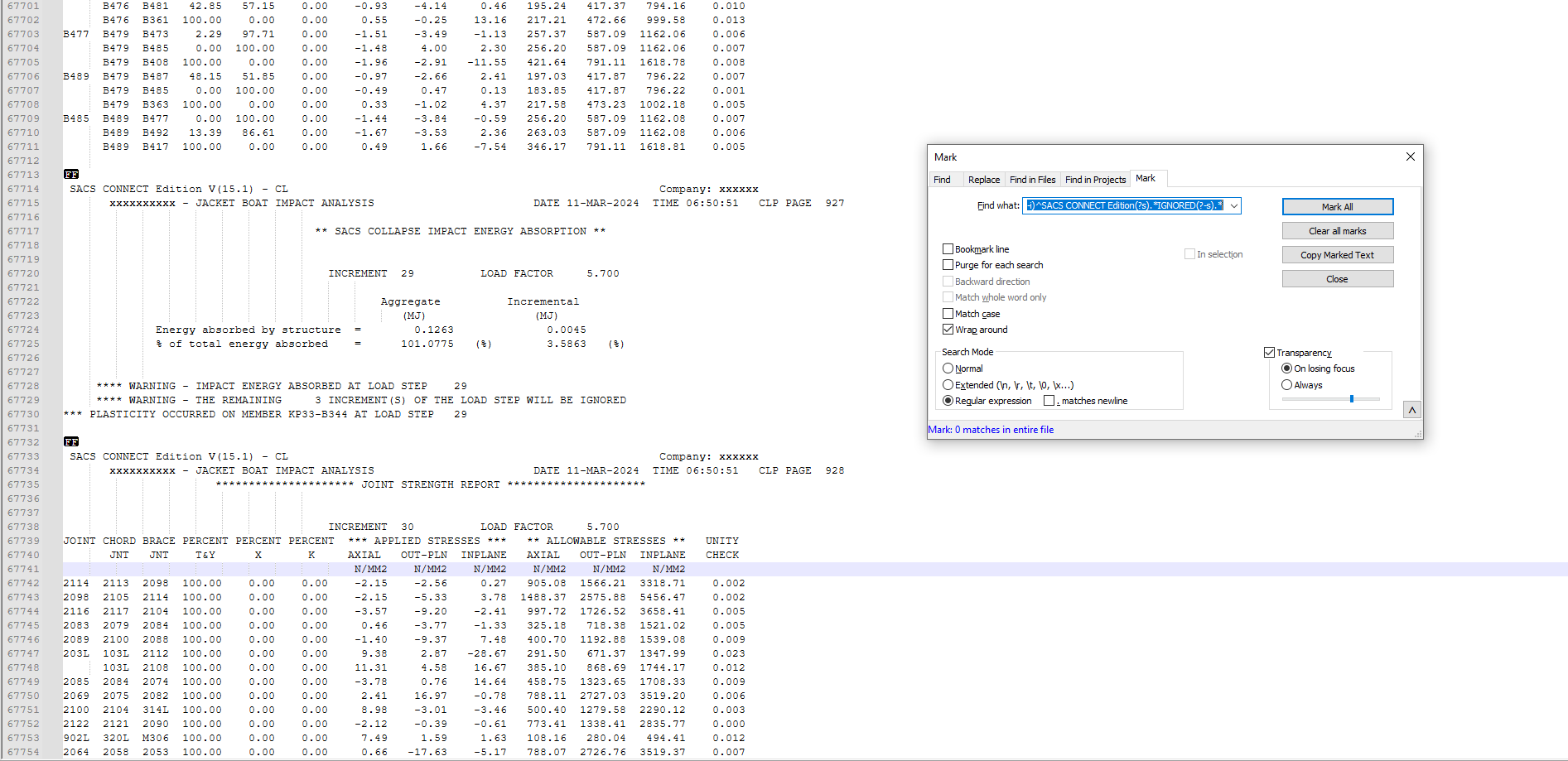
Hey, i am trying to extract 10 lines above word “ignored”, i tried using this command from your other post(.*\R){10}^.*ignored.*\Rbut it is showing Invalid Regular Expression.
Following are few lines from the whole text file.l, can u help me out. Thanks for your valuable posts.B465 B416 100.00 0.00 0.00 1.17 -32.75 -12.11 346.17 791.11 1618.77 0.042 B483 B478 B486 100.00 0.00 0.00 -0.88 -2.81 1.55 211.14 417.77 795.80 0.007 B478 B363 100.00 0.00 0.00 4.29 -2.66 -14.84 302.41 721.07 1413.40 0.011 B479 B476 B477 0.00 100.00 0.00 -0.35 2.33 0.63 183.52 417.34 794.06 0.006 B476 B481 26.71 73.29 0.00 -0.61 -4.35 -2.34 190.81 417.34 794.06 0.011 B476 B361 100.00 0.00 0.00 3.32 -1.65 32.38 217.19 472.63 999.46 0.033 B477 B479 B473 3.69 96.31 0.00 -5.24 -5.33 0.82 258.08 587.08 1162.04 0.010 B479 B485 0.00 100.00 0.00 -5.05 4.64 2.77 256.20 587.08 1162.04 0.009 B479 B408 100.00 0.00 0.00 -2.39 -10.75 -12.76 421.63 791.10 1618.76 0.016 B489 B479 B487 41.71 58.29 0.00 -0.69 -2.92 0.72 195.22 417.80 795.95 0.007 B479 B485 0.00 100.00 0.00 -0.39 0.16 0.72 183.81 417.80 795.95 0.001 B479 B363 100.00 0.00 0.00 0.26 -1.57 22.99 217.53 473.15 1001.83 0.023 B485 B489 B477 9.91 90.09 0.00 -5.01 -5.55 0.06 261.25 587.09 1162.07 0.010 B489 B492 0.00 100.00 0.00 -4.52 -4.82 4.16 256.20 587.09 1162.07 0.009 B489 B417 100.00 0.00 0.00 0.30 -6.94 -7.89 346.17 791.11 1618.80 0.010 [FF] SACS CONNECT Edition V(15.1) - CL Company: Lamprell Energy Ltd. CRPO-126-MRJN 2050/2059 - JACKET BOAT IMPACT ANALYSIS DATE 11-MAR-2024 TIME 06:50:22 CLP PAGE 1151 ** SACS COLLAPSE IMPACT ENERGY ABSORPTION ** INCREMENT 37 LOAD FACTOR 6.200 Aggregate Incremental (MJ) (MJ) Energy absorbed by structure = 0.1262 0.0021 % of total energy absorbed = 100.9477 (%) 1.6442 (%) **** WARNING - IMPACT ENERGY ABSORBED AT LOAD STEP 37 **** WARNING - THE REMAINING 96 INCREMENT(S) OF THE LOAD STEP WILL BE IGNORED [FF] SACS CONNECT Edition V(15.1) - CL Company: Lamprell Energy Ltd. CRPO-126-MRJN 2050/2059 - JACKET BOAT IMPACT ANALYSIS DATE 11-MAR-2024 TIME 06:50:22 CLP PAGE 1152 **** FINAL DEFLECTIONS AND ROTATIONS FOR LOAD SEQUENCE LCE1 **** LOAD CASE OE01 LOAD FACTOR 6.200 ****** DEFLECTIONS ****** ******* ROTATIONS ******* JOINT X Y Z X Y Z CM CM CM RAD RAD RAD 0243 0.192 -0.712 -0.005 0.00146 0.00058 -0.00019 0269 0.348 -0.873 -0.736 0.00168 0.00070 0.00022 0276 0.399 -0.518 -1.297 0.00117 0.00063 0.00030 0277 0.137 -0.584 -0.590 0.00151 0.00037 0.00020 101L 0.364 -0.914 -0.734 0.00168 0.00070 0.00022 102L 0.414 -0.547 -1.296 0.00117 0.00063 0.00030Regards,
Aaditya-–
moderator added code markdown around text; please don’t forget to use the
</>button to mark example text as “code” so that characters don’t get changed by the forum -
@sam-rathod said in How to bookmark lines around a line containing a specific expression 'XXX' ?:
post
(.*\R){10}^.*ignored.*\Rbut it is showing Invalid Regular Expression.What you typed in your post is valid regex, so I have to assume that’s not what you had in the FIND WHAT field. If that’s exactly what you had, please show a screenshot of the whole dialog box
-
@sam-rathod As @PeterJones noted, your regular expression is valid.
@all - I discovered it’s challenging as I think I think @sam-rathod intended to start the extraction at the line that starts with
SACS CONNECT Editionand that the does not count empty or blank-only lines as “lines.”But, how can can we go backwards by nine lines that are not blank/empty from the
IGNOREDanchor?Thinking forwards is much easier for me:
^SACS CONNECT Edition(?s).*IGNORED(?-s).*@sam-rathod the
(?s)part puts the regular expression engine in a mode where dot also matched end of lines meaning we will skip/match all lines fromSACS CONNECT Editionup to the wordIGNORED. Once we get toIGNOREDwe do(?-s)which turns the dot matching end-of-line thing off and the final.*picks up the remainder of the line.To make this safer I would use the case-sensitive
(?-i)^SACS CONNECT Edition(?s).*IGNORED(?-s).* -
@PeterJones
Hey
The output that I am expecting:
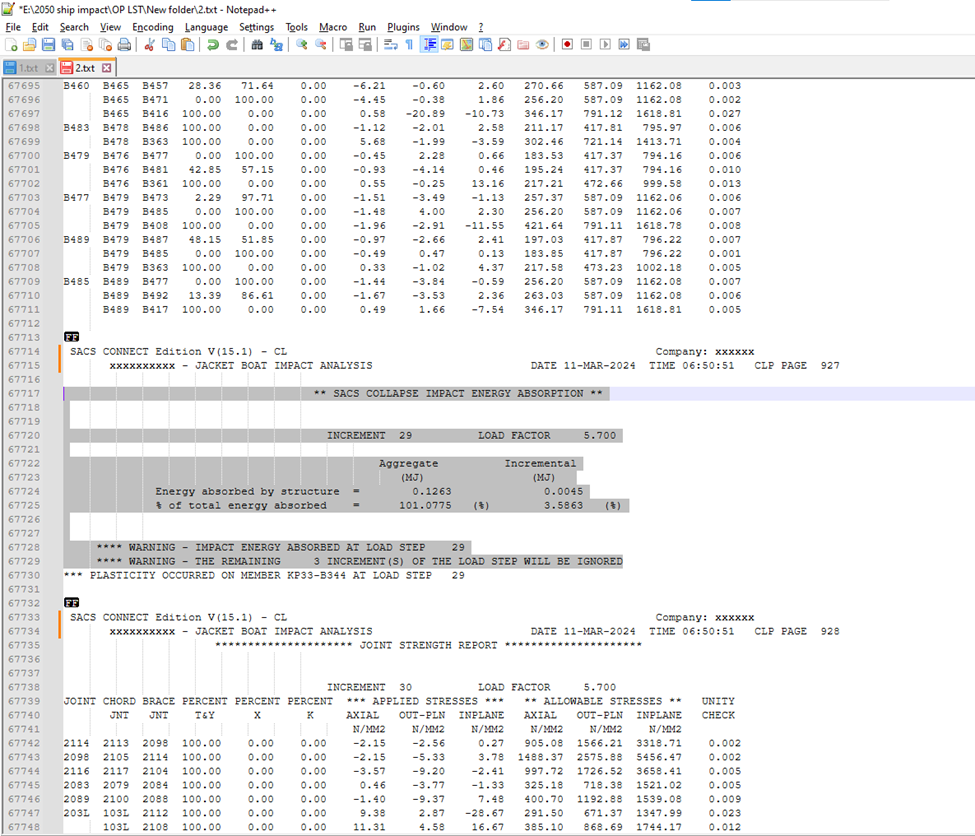
The area marked in grey is what i want MARKEDThis is the error that it is showing after entering the regex command:
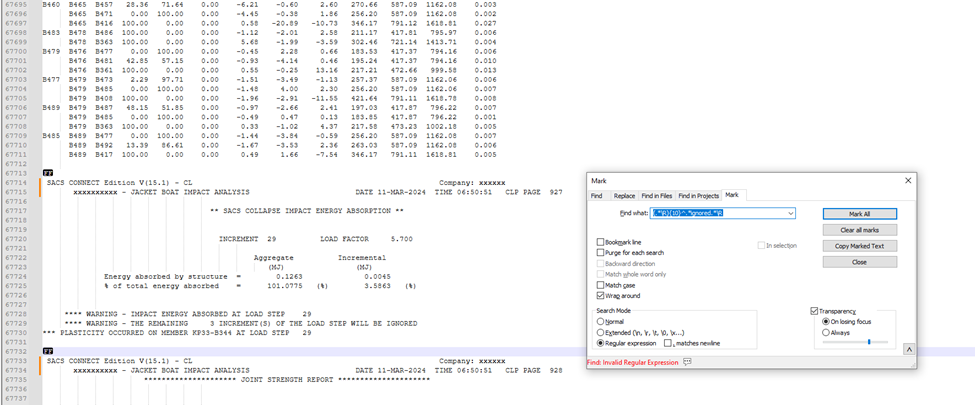
I tried attaching files but i am unable to.
Thanks guys for reaching out so quick to such an old topic, much appreciated.
Regards,
Aaditya -
@mkupper
Hello,Actually the occurrence of SACS CONNECT Edition is at multiple times so i guess that might be one issue, also i tried the <(?-i)^SACS CONNECT Edition(?s).IGNORED(?-s).> but it is giving this error:
Regards,
Aaditya -
@sam-rathod - I start out by trying to see if there is a pattern to the data that I can take advantage of. I test this carefully to understand any possible exceptions to the pattern.
You have provided two examples and so from that the pattern I see is the the sections that you want to highlight start with these lines:
** SACS COLLAPSE IMPACT ENERGY ABSORPTION ** **** FINAL DEFLECTIONS AND ROTATIONS FOR LOAD SEQUENCE LCE1 ****I also see that above this is the page header which starts with
SACS CONNECT Editionand so first do a test(?-i)^SACS CONNECT Editionand count how many page headers there are. Let’s say there are 957 in the file. I write down957so I won’t forget.I then build a regular expression that matches the start of the data. I’ll do
(?-i)^ +\*+ [A-Z0-9 ]+ \*+$and verify that it matches exactly957times in the file. If it fails to match exactly957times then I tighten or loosen the regular expression as needed until it nails957.I do the same thing for the IGNORED lines. I first do
(?-i)IGNORED$and count. Let’s say there are57and so I write that down. The full pattern for the IGNORED lines seems to be(?-i)^ +\*{4} WARNING - THE REMAINING +[0-9]+ INCREMENT\(S\) OF THE LOAD STEP WILL BE IGNORED$Adjust that expression until it gets exactly57matches.Now we know we have
957page headers and57of them are the ones we are interested in. As the sample size you have provided only has one example of what we want to match I will use a more general(?-i)^(?: +\*+ [A-Z][A-Z0-9 ]+ \*+\R)(?:.*\R){1,25}(?: +\*{4} WARNING - THE REMAINING +[0-9]+ INCREMENT\(S\) OF THE LOAD STEP WILL BE IGNORED)$Drop that into Notepad++. I added a couple of extra parentheses in there so that when you move the cursor to a
(or)that Notepad++ will highlight the other one of of the(…)pairs.The groups within that rather long expression are:
(?-i)- Turn the ignore letter case flag off.^(?: +\*+ [A-Z][A-Z0-9 ]+ \*+\R)- This is the thing that matches the start of the blocks we want to select. We know it matches957times.(?:.*\R){1,25}- Allow for one to 25 lines that may be empty or may have stuff.(?: +\*{4} WARNING - THE REMAINING +[0-9]+ INCREMENT\(S\) OF THE LOAD STEP WILL BE IGNORED)$- This matches the last line of the things we are interested in.
In this case I solved the problem by using
(?:.*\R){1,25}. I know that the first line will match many times but don’t want to bother with scanning too far before testing for the last line. With a better sample size I likely would tune{1,25}to be a better match for how far down thatIGNOREDline is.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login