Show only lines that contain a search term
-
@Alan-Kilborn I’ve tried you script now, too and it works well for me. Thank you for that!
Is it possible to do a case insensitive search? ( I suppose not yet).
BTW, I tried to copy all filtered lines to the clipboard but the whole file content gets copied - is this the expected behaviour?
-
@Paul-Wormer said in Show only lines that contain a search term:
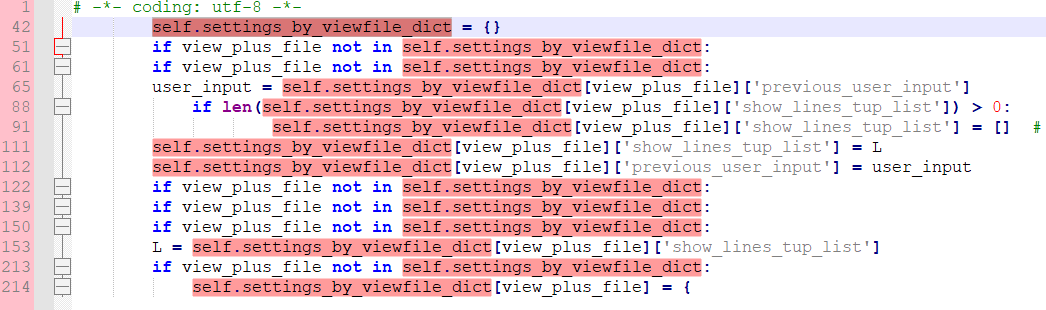
self.settings_by_viewfile_dict
I think what I see is the correct result:
-
@datatraveller1 said in Show only lines that contain a search term:
Is it possible to do a case insensitive search? ( I suppose not yet).
Right, let’s “walk before we run” with this… :-)
BTW, I tried to copy all filtered lines to the clipboard but the whole file content gets copied - is this the expected behaviour?
For now, yes. If you select lines (e.g. have a “filtered” view and do a Ctrl+a select-all) that cross visible/hidden boundaries and then do some operation on the selection, you’ll get all real lines in that region – reference my cautions about deleting selected text earlier.
-
@datatraveller1 said in Show only lines that contain a search term:
I think what I see is the correct result:
@Alan-Kilborn Do you know why I get the correct result if I filter for self.settings_by_viewfile_dict while Paul and you get the wrong result? :-)
-
@datatraveller1 I run the script three times in a new session:
- Hide lines not containing the string
- Undo it (show all lines again)
- Hide lines not containing the string
Then: step 1 gives too many lines and step 3 is OK.
-
@Paul-Wormer I still get always correct results (also after repeating steps 1-3 up to 10 times).
-
@datatraveller1 Also in a new session? That is, after closing Npp and starting it again?
-
@Paul-Wormer Yes, always correct results.
-
@Alan-Kilborn
I made a small step forward. After line 170 I modified the code as follows:# hide all lines first: self.show_all_lines(False) import time print('sleep ..') time.sleep(60) # show only lines with hits from the search based on user criterion: for (pos_start, pos_end) in L: editor.setIndicatorCurrent(SCE_UNIVERSAL_FOUND_STYLE) editor.indicatorFillRange(pos_start, pos_end - pos_start) line_start = editor.lineFromPosition(pos_start) line_end = editor.lineFromPosition(pos_end) editor.showLines(line_start, line_end) time.sleep(60) print('Woke up')The sleep(60) gave me time to look at what’s happening and I noticed that often not all lines are hidden at the first sleep. These lines stay visible after the second sleep. The lines that stay visible are more or less random, so I get the feeling that it is a matter of timing. When I increase the length of the file by adding comments different lines stay visible. Datatraveller1 may well have a faster PC than Alan and me.
-
Hello, @alan-kilborn, @paul-wormer, @datatraveller1 and All,
Well, I finished the traditional sequence of greetings, by phone, SMS and letters. So I just tested your Python script, Alan, and here are the results of my experiments !
-
Personally, I never saw the case of visible lines not containing the literal string to search for. Good point !
-
Like you, @alan-kilborn, I used the
License.txtfile, which I duplicated several times and enter the lower-case wordfreewhen running the script And, as I increased the size of the test file, the waiting time to get the line margin highlighted, in salmon color, increased in parallel :
Search of the literal lower-case word 'free' Times "License.txt" Size Lines Hiding lines time --------------------------------------------------------------------------------------- license.txt × 1 35,500 bytes 231 lines 0,4 s license.txt × 5 177,500 bytes 1,155 lines 1,95 s license.txt × 10 355,000 bytes 2,310 lines 3,5 s license.txt × 50 1,775,000 bytes 11,550 lines 17 s license.txt × 100 3,550,000,bytes 23,100 lines 34 s license.txt × 500 17,750,000 bytes 115,500 lines 165 s license.txt × 1000 35,500,000,bytes 231,000 lines 335 sNow, if we choose to look for the literal string
COPYING, which occurs once only in thelicense.txtfile ( instead of24times for the wordfree), the results are very fast, in comparison :Search of the literal upper-case word 'COPYING' Times "License.txt" Size Lines Hiding lines time --------------------------------------------------------------------------------------- license.txt × 1000 35,500,000,bytes 231,000 lines 12,5 sOf course, if I tried to re-run the script, before getting the highlighted line margin, I received the usual message :
Another script is currently running. Running two scripts at the same time could produce unpredicable results, and is therefore disabledNote that I tested this script with a portable N++
v8.4.6version, located on anUSBdrive
Now, @datatraveller1, in order to ONLY copy the visible lines, here is a work-around :
-
Run the @alan-kilborn Python script first
-
Open the Mark dialog (
Crl + M) -
Write the same string than in Alan’s Python script, in the
Find whatzone -
Tick the four options
Bookmark line,Purge for each search,Match caseandwrap around, only -
Select the
Normalsearch mode -
Click on the
Mark Allbutton -
Run the
Search > Bookmark > Copy Bookmarked Linesoption or right-click on the bookmark margin and choose it -
Open a new tab (
Ctrl + N) -
Paste the copied text (
Ctrl + V)
Finally, @alan-kilborn, @paul-wormer and @datatraveller1, regarding the method, wouldn’t it be better to :
-
Trigger a usual Mark action, with the
Bookmark lineoption set -
Elaborate a
Pythonscript which simply would hide ALL non-marked lines, from the Mark results !
3immediate advantages of this method :-
You are not limited, anymore to a
literalstring -
You could choose a
sensitiveornon-insensitivesearch -
You could choose the search mode :
Normal,ExtendedorRegular expresion
Best Regards,
guy038
-
-
@guy038 said in Show only lines that contain a search term:
as I increased the size of the test file, the waiting time to get the line margin highlighted, in salmon color, increased in parallel
I did mention earlier: “Large files may produce performance problems. Scripts aren’t blazingly fast…”
I use a variant of this script on what I consider a large file (in the work that I do). It works acceptably, performance wise.
HOWEVER: The correctness (or rather incorrectness) problem observed by some users needs to be addressed; if it doesn’t show/hide the correct lines, who cares how fast/slow it is?
wouldn’t it be better to :
Trigger a usual Mark action, with the Bookmark line option set
Elaborate a Python script which simply would hide ALL non-marked lines, from the Mark results !The downsides to that approach are:
- It requires multiple steps
- Bookmarks become dedicated to that purpose (I like to “filter lines” and then set meaningful bookmarks on only some of the matches, before revealing all lines again and continuing to work with what I’ve bookmarked)
The user interface of the script could evolve to allow things like regex, match-case, etc. But…let’s go for correctness first.
-
Hi, @alan-kilborn and All,
Ah…OK. I understand your working method. You should indeed remove these false positive answers, first of all !
By the way, I’m really surprised that I never encountered any visible false lines during my tests, even in the case of a heavy file ! However, my laptop is not a WAR LIGHTNING ! Bought in
July 2021, this HP laptop comes withWindow 10 Pro 64, a512 MbSolid State Drive and16 Mb DDR4of RAM.Moreover, as I have not finished cleaning my old micro and moved all my data yet, I still use a
USBkey containing the N++ portable version8.4.6for all my tests, which must certainly slow down the execution of yourPythonscript ??BR
guy038
-
@guy038 said in Show only lines that contain a search term:
I have not finished cleaning my old micro and moved all my data yet,
What is taking so long? Are you ever going to finish with this?? :-)
I still use a USB key containing the N++ portable version 8.4.6 for all my tests, which must certainly slow down the execution of your Python script ??
I don’t see how…everything should be “in memory” for the operations of the script.
I’m really surprised that I never encountered any visible false lines during my tests
Yes that is interesting…
You should indeed remove these false positive answers, first of all !
Indeed. However, at the moment, I’m out of ideas on what the problem might be. :-(
-
Hi all,
Just two thoughts-
I’m not sure - what does PC speed have to do with line visibility?
-
Doesn’t “Find All in Current Document” basically do the same thing as the Python script? Actually, the Notepad++ programmer just has to output the same thing in the same window to filter the text, doesn’t he?
-
-
@datatraveller1 said in Show only lines that contain a search term:
I’m not sure - what does PC speed have to do with line visibility?
I don’t think it has anything to do with it, but until the root cause is found, everything is “on the table” as a possible problem.
Doesn’t “Find All in Current Document” basically do the same thing as the Python script?
I think the key idea behind the script is you can edit in the filtered view.
-
@Alan-Kilborn said in Show only lines that contain a search term:
I think the key idea behind the script is you can edit in the filtered view.
THIS! There is a
vimode for this IIRC, but I just figured with all the plugins and search window in Notepad++ never supporting this editing of the filtered view - just putting the results into a different view - we’d just never get it.Thanks @Alan-Kilborn - I assigned a hotkey and will try getting this filtered editing into my workflow.
Cheers.
-
@Alan-Kilborn and @Paul-Wormer
I have noticed that your line numbers don’t match my line numbers, e.g. my (correct) first occurence of
self.settings_by_viewfile_dictis line 42.
I use the script https://community.notepad-plus-plus.org/post/82787 - Are you perhaps using a different script with potentially problematic changes? Does the problem also occur with this original version? -
@datatraveller1 said in Show only lines that contain a search term:
I have noticed that your line numbers don’t match my line numbers
I said before “(Don’t be concerned if my line numbers don’t match yours)”.
The reason for any mismatches would be because I’ve inserted some extra debugging statements in to possibly help solve the problem. As I’m seeing the undesired results with the original code or any variant, what I’ve changed isn’t causing the problem.
-
@Alan-Kilborn ok, sometimes debugging code can also contain errors, but this does not apply in your case.
I still get correct results no matter what I filter for :-)
-
@datatraveller1 , @Alan-Kilborn , @Paul-Wormer,
The first time I created the script, and ran it, it properly filtered (showed @datatraveller1’s screenshot). And every subsequent run in that load of Notepad++ worked properly.
I then restarted Notepad++, and the first run after restarting gave more lines (some of the comment lines). If I run it and do the clear (shift+OK), then run it to highlight again, it works correctly. If I restart NPP and re-run to get the extra lines, then run again with the same exact search string (not shifted), it filters correctly.
The sequence behaves the same when searching for
self.settings_by_viewfile_dictor justself.I set the debug flag to TRUE (set that line to a 1 not a 0), restarted Notepad++, and then ran with the longer search string again.
For the bad highlight:LFVH1<DBG>: view_plus_file: 0C:\Users\PJones2\AppData\Roaming\Notepad++\plugins\config\PythonScript\scripts\nppCommunity\23xxx\23929-AlanK-LineFilterViaHiding1.py LFVH1<DBG>: view_plus_file: 0C:\Users\PJones2\AppData\Roaming\Notepad++\plugins\config\PythonScript\scripts\nppCommunity\23xxx\23929-AlanK-LineFilterViaHiding1.py LFVH1<DBG>: L: [(1648, 1678), (2255, 2285), (2749, 2779), (2939, 2969), (4190, 4220), (4449, 4479), (5182, 5212), (5265, 5295), (5675, 5705), (6407, 6437), (6936, 6966), (7047, 7077), (9877, 9907), (9922, 9952)]for the good highlight immediately after:
LFVH1<DBG>: view_plus_file: 0C:\Users\PJones2\AppData\Roaming\Notepad++\plugins\config\PythonScript\scripts\nppCommunity\23xxx\23929-AlanK-LineFilterViaHiding1.py LFVH1<DBG>: L: [(1648, 1678), (2255, 2285), (2749, 2779), (2939, 2969), (4190, 4220), (4449, 4479), (5182, 5212), (5265, 5295), (5675, 5705), (6407, 6437), (6936, 6966), (7047, 7077), (9877, 9907), (9922, 9952)]There is no difference in the L list, which says that the problem doesn’t lie in the searching/list, but rather someplace else.
Additional datapoint: if I have the bad filter (with extra comments showing), switch to another tab, and switch back, it shows the correct filtering, with the debug info:
LFVH1<DBG>: BUFFERACTIVATED: {'code': 1010, 'bufferID': 3019234076800L} LFVH1<DBG>: view_plus_file: 0C:\Users\PJones2\AppData\Roaming\Notepad++\plugins\config\PythonScript\scripts\nppCommunity\23xxx\23929-AlanK-LineFilterViaHiding1.pyIf I take original line#114 – the
self.freshen_user_view_of_active_tab()at the end ofprompt_for_string_to_match()'s definition – and duplicate it, so it runs that freshen twice, on the first freshen, it shows wrong; on the second, it shows right.I’m wondering if before the “hide” side of that command, if you need to clear all the lineVisible flags to known values before your script does its hiding… maybe the active lexer or other NPP feature has already tagged some lines in a way that confuses your logic.
That’s probably all the time I’ll have for helping debug this today, but I hope some of that info turns out to be useful.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login