Getting "Invalid Regular Expression" for an extremely simple expression
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
The
regexPython package is generally considered one of the most capable regex engines out there, but even that package takes quadratic time (in the length of the input) when testing the regular expression".*employeeId"on many repetitions of the string"employeeI"(including a space after the closing quote).As I understand it, some regex implementations (like this one) enable compiling a regex to a DFA, which has no backtracking and thus could never take more than linear time to process any input, but there’s a big issue here:
The Notepad++ regex engine would need to automatically determine when a regular expression can be represented with a DFA (which no engine that I know of can do), because I somehow doubt that the user base would be in favor of a new option that can’t even be understood without studying CS theory.
NOTE: To spare the ambitious among you some trouble, don’t even bother trying to come up with a general algorithm that can determine whether a Boost regex can be represented with a DFA. Such an algorithm is literally impossible for boring pedantic reasons.
-
I was more just surprised that there are (apparently) no optimizing heuristics such as recognizing that if B contains no back-references to A, if A.*B doesn’t match at the first position A matches, it can’t match anywhere in the line (if . does not match line endings) or anywhere at all (if . does match line endings). I would have thought that .*, especially, was so common that simple expressions joined by .* would have more clever processing.
Apparently regular expressions are executed rather literally (like compiling code in debug mode with optimization off). Then again, aside from here, in Notepad++, I guess regular expressions are usually used by fairly “geeky” types who are capable of recognizing what the expressions imply and optimizing them before handing them to the regular expression engine.
-
@mkupper You are 100% correct, I don’t dispute anything you said. Also, I misspoke in an earlier reply when I said this RE had no backtracking, what I meant to say was that it had no back references. Obviously backtracking is the bread and butter of regular expressions.
The fact is that I started with a much more complicated regular expression and got the error, so I simplified the regular expression, then simplified it again until I got a super simple regular expression, the one I posted, that still caused the error.
However, now I have to admit that the problem was my assumptions. What I didn’t realize was that there was a couple of rogue json files that had come in with a project. These files were 10k and the whole JSON was in one line, no carriage returns at all (which isn’t all that different from the test file you created). Not sure why, maybe they were just generated by some code like that or maybe they were trying for some kind of minification, though I can’t imagine doing without the CRs would make that much difference.
Also, when I said that Visual Studio did it fine, it turns out I was lying. I had started the search and then walked away so I didn’t realize how long it took (though it did eventually finish it took hours because of those giant files, and it used 100% CPU for most of that time, DOH!).
So, in the end the only thing left is a suggestion that the multi-file find shouldn’t fail because it runs into a file that breaks, when all the other files work just fine. Once I removed the heinous one-line JSON files the search completed for my original (complex) RE. Strangely enough I still get the error for “.*employeeId”, so there’s something else that’s tweaking it. However “[^”]*employeeId" works just fine as well as “[^”\r\n]*employeeId".
I think in the end it’s good I came here first rather than reporting it straight to GitHub as the conversation definitely made me take a second look at my assumptions. Thanks guys!
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
Hmmm… honestly, I’m not sure there is a good way to word that message — the very existence of the message is the problem. The right way (in my oh-so-humble opinion) to handle this would be to pop up a progress dialog when searches take more than a user-configurable amount of time, and let the user decide when it’s been going on too long and should be canceled.
Doing something like that with the search in Columns++ is on my list of potential future enhancements. I think it might require modifying Boost::regex, though; if it does, I will find that idea rather uncomfortable. If I ever do get it done and working right in my plugin, that could serve as a proof-of-concept for doing it in Notepad++.
Or (considering that the problem @mkupper demonstrated would have been avoided if the regex processing recognized that if a fixed string didn’t match from a given position to the end of a line it couldn’t possibly match from a later position in the line to the end of the same line), maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
Absolutely. It’s not the expression that fails, it’s the combination of the expression and the data.
By the way, did you ever try either of these expressions on your data:
"[^"\r\n]*employeeId"
"(.*employeeId"|.*(*SKIP)(*FAIL))just to see if they would work to find what you wanted?
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
Absolutely. It’s not the expression that fails, it’s the combination of the expression and the data.
By the way, did you ever try either of these expressions on your data:
"[^"\r\n]*employeeId"
"(.*employeeId"|.*(*SKIP)(*FAIL))just to see if they would work to find what you wanted?
I didn’t try the second, but I did try the first and once I got rid of the heinous json files it works. The “real” RE that I was trying to run (which is much more complex than the one above, which was the simplest I found that produced the error) works as well (I never put that in here because it wasn’t germane to the discussion).
-
Hello, @scott-gartner, @alan-kilborn, @coises, @mkupper, @mark-Olson, @terry-r and All,
I’ve been away for the last few days as we’ve been on a 4-day trip to Burgundy with some friends: hiking trails, visiting monuments, including the ‘must-see’ Hospice de Beaune, and, of course, the local gastronomy !
Interesting and disturbing topic, indeed !
But, before I get into that, let me correct two common mistakes :
First, @scott-gartner said :
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed
This assertion is FALSE !
To be convinced of this fact :
-
Open a new tab
-
Type in the following text :
"this is a test to see the scope of the search "this is a test to see the scope of the searchIf you search for the regex
"[^"]*test, even if the. matches newlineoption is not set, you should get two matches :-
The first match in line
1( obvious one ) -
The second match in line
6and7, which includes one CRLF, at the end of line6
This result is due to the regex part
[^"]which matches absolutely all chars but the double quote, and so, including theEOLchars as well !Now, if you use, instead, the regex
"[^"\r\n]*test, you’ll get only one match, in line1
Secondly, @mkupper said :
Surprisingly, it also fails if I try “.*?employeeId” which I though would disable backtracking.
No, adding the
?symbol in order to get a lazy quantifier, instead of the gready one, is not related to the backtracking process. There are two independant things ! My personal idea about it, is that the term bactracking process should be named the retry process !For example :
-
Open a new tab
-
Type in this one-line text :
this is a test to see what happens_with_that_regexAnd let’s use the simple regex
^.+?a\w+$-
At first sight, we could say that the regex letter
a, after the LAZY quantifier, should match the first letteraof the subject string ! -
But, after matching the part
this is a, the regex wait for a word char as next character. this is not the case as it’s aspacechar. -
Thus the process backtracks ( I would say retries ) and increases the number of chars before an other
aletter, till the stringthis is a test to see wha -
The next char is, indeed, a word char ( letter
t), but again the next one is aspacechar -
So, the process backtracks ( I would say retries ) increasing the number of chars for an other
aletter, till the stringthis is a test to see what ha. This time, the remainder of the subject stringppens_with_that_regexis entirely made of word characters -
As a result, the regex
^.+?a\w+$is truly verified against this subject string :
this is a test to see what happens_with_that_regex ^<----------.+?------------->a<--------\w+-------->$To be convinced, simply use the regex S/R, below :
SEARCH
(?x) ^ (.+?) (a) (\w+) $REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\nto see the different groups involved !
In other words :
-
We are not searching for the closest letter
a, after the string matched by the regex^.+?, but : -
We are searching for the closest expression, matched by the regex
a\w+$, after the string matched by the regex^.+?
If we had used, instead, the regex
^(.+)a\w+$:-
The part
^.+awould have directly matched thethis is a test to see what happens_with_thastring -
And the part
\w+$correctly finds the stringt_regexwhich is an ending block of word chars
Leading to :
this is a test to see what happens_with_that_regex ^<--------------------.+------------------>a<-\w+->$See the difference, with the previous case, by using this regex S/R :
SEARCH
(?x) ^ (.+) (a) (\w+) $REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\n
An other example with TRUE backtracking process :
If we consider the simple regex
\w+\w{14}\d+, against the subject stringABC12345DEFABC34566677890-
First, of course, the sub-regex
\w+matches all the subject string -
Then, the
\w+backtracks, so decreases, one position at a time, till14positions, in order that the stringABC12345DEFmatches the\w+part and the stringABC34566677890matches the regex part\w{14} -
Finally, the sub-regex
\w+backtracks again by1position, in order that the stringABC12345DEmatches the\w+part, the stringFABC3456667789matches the\w{14}part and the final0matches the\d+part
Again, you may verify, the results with the regex S/R :
SEARCH
(?x) (\w+) (\w{14}) ( \d+)REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\n
Now, let’s go back to our main problem !
From the @mkupper’s file, that I downloaded, I tried to simplify the problem. Thus, I used this text :
".*employeeId" See https://community.notepad-plus-plus.org/topic/25868/getting-invalid-regular-expression-for-an-extremely-simple-expression/ "abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyz.........."abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyzAs you can see, the first five lines are identical to the @mkupper’s text :
-
A first empty line
-
The second line, matched by the
".*employeeId"regex -
A third empty line
-
A fourth line with the link
-
A fifth empty line
-
Finally, a sixth line containing the string
"abcdefghijklmnopqrstuvwxyz, repeated exactly2,672times, without any line-break -
Save this file with name
Text_OK.txt
Note : the
Test_OK.txtfile should have a size of72,294bytes-
Now, select all the file contents
-
Copy it in the clipboard
-
Open a new tab
-
Paste the clipboard contents
-
Add an unique string
"abcdefghijklmnopqrstuvwxyzat the very end of file -
Save it with name
Test_KO.txt
This time, the
Test_KO.txtshould have a size of72321bytes ( the sum72,294 + 27)
Regarding the search process, itself :
-
Move to the very first line of each file
-
Open the Find dialog (
Ctrl + F) -
Uncheck all the box options
-
SEARCH
".*employeeId" -
Select the
Regular expressionsearch mode -
Click two times on the
Find Nextbutton
Note that I first did the tests on my old
Win XP - 32 bitslaptop, with just1 Gbof RAM, and N++ portablev7.9.2-
With a sixth line containing exactly
2,672times the string"abcdefghijklmnopqrstuvwxyz( fileTest_OK.txt), the regex search".*employeeId"detects the unique match, in line2then displays the messageFind: Can't find the text "".*employeeId""=> Results OK -
With a sixth line containing exactly
2,673times the string"abcdefghijklmnopqrstuvwxyz( fileTest_KO.txt), the regex search".*employeeId"detects the unique match, in line2, then wrongly finds all the file contents !
Remember that, before N++
v.8.0, when explanations on regex syntax were absent, in the search dialog, it was the normal way for the regex engine to display a possible regex problem !!
Then, using my recent
Win 10 - 64 bitslaptop, with32 Gbof RAM and N++ portablev8.6.5, I did the same tests. I initially thought that the limit between the two cases would be much higther, given the capacities of my new laptop, but the most extraordinary thing is that I got exactly the same limit, namely :-
With a sixth line containing exactly
2,672times the string"abcdefghijklmnopqrstuvwxyz( fileTest_OK.txt), the regex search".*employeeId"detects the unique match, in line2, then the messageFind: Can't find the text "".*employeeId"" from caret to end-of-file=> Results OK -
With a sixth line containing exactly
2,673times the string"abcdefghijklmnopqrstuvwxyz( fileTest_KO.txt), the regex search".*employeeId"detects the unique match, in line2, then writes the messageFind invalid Regular Expressionand the error message said
The complexity of matching the regular expression ... ... that takes an indefinite period of time to locate
I also tested this regex against the same files with the
SciTEsoftware ofSCIntilla, downloading theSingle file 64-bits executablenamed Sc550.exe. Unlike with Notepad++,SciTEdoes not find any wrong second match !So, as a conclusion, I think that it seems to be a real bug. However, I can’t decide if it’s a Boost regex’s bug or a N++ bug in the way to use the
Boost regexengine !Best Regards,
guy038
Could someone repeat my tests, with recent N++ version and confirm my assumptions regarding the
Test_OK.txtandText_KO.txtfiles, which differ of27characters only !! -
-
 G guy038 referenced this topic on
G guy038 referenced this topic on
-
@guy038 said in Getting "Invalid Regular Expression" for an extremely simple expression:
Could someone repeat my tests, with recent N++ version and confirm my assumptions regarding the Test_OK.txt and Text_KO.txt files, which differ of 27 characters only !!
I can replicate these results on a no-plugin version of my 64-bit Notepad++ clone (which was between 8.6.7 and 8.6.8 at the time I ran your tests). So it sounds like this bug is real and still exists.
-
@guy038 said in Getting "Invalid Regular Expression" for an extremely simple expression:
First, @scott-gartner said :
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed
This assertion is FALSE !
Guy, be careful. He made that assertion with regards to the original regex he showed us:
".*employeeId"– you then tested the assertion using a completely different regex:"[^"]*test. The.*that he was talking about is wholly different than the[^"]*that you tested. With the test textthis "has employeeId" in a single line this "does not have employeeId" on the same line as the start quote so the second will not match the third "employeeId" will match as wellUsing the original
".*employeeId"does not stretch the match over multiple lines, as expected (see below) when. matches newlinesis checked. Using the equivalent of your test,"[^"]*employeeId", of course it will spread across multiple lines, because the manual character class is not the same as the.*that he made the assertion about, and has no.for. matches newlineto influence.".*employeeId"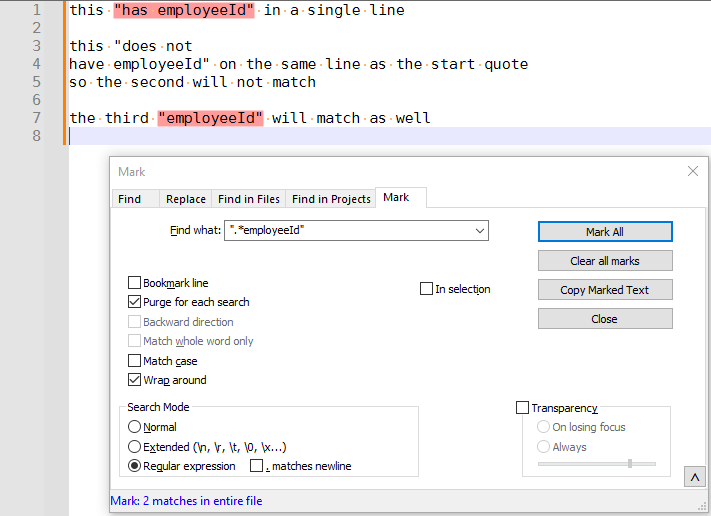
"[^"]*employeeId"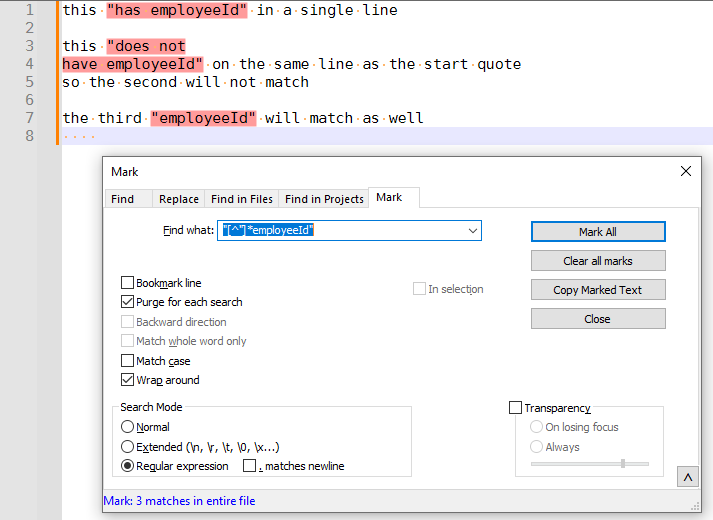
-
Hello, @scott-gartner, @peterjones and All,
Oh…, yes, Peter, you’re right about it ! So, @scott-gartner, I’m sorry for misinterpreting your statement !
Best regards,
guy038
-
Hi, @mark-olson and All,
Many thanks for confirming my tests. Now, the next step, I suppose, would be to open these two files with an other editor which also uses the
Boostregex engine,. Then :-
If the problem is still there, it’s probably a
Boostregex engine bug ! -
If the problem has gone over, it’s more likely a
Notepad++bug when using theBoostlibrary !
The worst solution would be that, both, the
Boostengine andNotepad++were concerned by this bug :-((BR
guy038
-
-
-
@guy038 That is excellent background on the error, especially the historical differences in how it handled the RE failures.
I believe that I assumed (bad move on my part) that NOT checking the “. matches newline” also meant that the RE would only run in respect to single logical lines (regardless of the use of “.” or a character set in the expression). I was thinking that this was the equivalent of adding /m to the end of a Perl RE.
Starting with your short sample, I thought maybe if I included ^$ that would limit it to only logical lines, but it still doesn’t work the way I expect either. If I search for
^.*test.*$it limits to single lines, yay. If I then check “. matches newline” then it matches the entire file, which also makes sense. If I search for^.*[^"]*test$it still matches multiple lines, so [^"]* is matching newlines even with ^$ in the expression.So, if N++ has the feature at all (honoring logical lines), I don’t know how to invoke it. Obviously, I can code that into the RE myself, but for the same reason that /m exists in Perl REs I would think this would be a useful feature to have.
Looking in the Boost documentation, and it claims that “Normally Boost.Regex behaves as if the Perl m-modifier is on: so the assertions ^ and $ match after and before embedded newlines respectively, setting this flags is equivalent to prefixing the expression with (?-m).”, so the boost::regex_constants::no_mod_m must always be specified in N++? I thought maybe this meant that I could do
?-m^.*[^"]*test$or(?-m)^.*[^"]*test$but that just results in “Invalid regular expression.” -
@guy038 said in Getting "Invalid Regular Expression" for an extremely simple expression:
Then, using my recent Win 10 - 64 bits laptop, with 32 Gb of RAM and N++ portable v8.6.5, I did the same tests. I initially thought that the limit between the two cases would be much higther, given the capacities of my new laptop, but the most extraordinary thing is that I got exactly the same limit, namely :
With a sixth line containing exactly 2,672 times the string "abcdefghijklmnopqrstuvwxyz ( file Test_OK.txt ), the regex search ".*employeeId" detects the unique match, in line 2, then the message Find: Can't find the text "".*employeeId"" from caret to end-of-file => Results OK With a sixth line containing exactly 2,673 times the string "abcdefghijklmnopqrstuvwxyz ( file Test_KO.txt ), the regex search ".*employeeId" detects the unique match, in line 2, then writes the message Find invalid Regular Expression and the error message saidThe complexity of matching the regular expression … … that takes an indefinite period of time to locate
The limiting, which occurs in Boost::regex code, has nothing to do with machine capabilities. It doesn’t measure timing. It is a heuristic attempt by the regex engine to guess when it seems like the amount of text being examined, or re-examined, is growing “too fast” compared to the progress in moving the point at which the attempt to match is made forward. In practice, that means it is scanning the same text over and over again.¹
I did not succeed in understanding the details of how this is implemented. (I think I would need to find some kind of design document that explains how the Boost::regex engine works before I could hope to comprehend the code.)
I don’t have a pre-8.0 version handy, but I was able to replicate your results with Notepad++ 8.6.8 64-bit. I do not believe it is a bug. You have found the threshold — for this particular expression and data pattern — that triggers the error message.
The message is the result of a heuristic, not a mathematically exact determination. It doesn’t mean the regular expression is technically invalid, it means that, when applied to the data in question, it appears to be very inefficient (possibly — not necessarily — non-terminating).
That said, in my opinion it’s a bit of a design flaw… the message is confusing, and it should be up to the user to decide, for example, via a cancel button on a (hopefully informative) progress dialog, when things have been going on too long.²
¹ This is probably what people think “backtracking” means… though backtracking means backtracking in the expression, not in the text. This case doesn’t arise because of backtracking, but because every occurrence of a quote requires a scan all the way to the end of the same line. If that line has lots of quotes and lots of text, the heuristic can be triggered — incorrectly, I would say, because the search will complete, just very inefficiently — but it is, after all, a heuristic, not a mathematical certainty (which is probably impossible due to the halting theorem).
² However, as far as I could see, the design of Boost::regex doesn’t allow for a way to periodically interrupt the matching process to update a progress dialog and check for a cancel action. Replacing or modifying Boost::regex is probably not feasible. At some point I hope to examine, in my Columns++ plugin, whether the search could be run in a separate thread (avoiding the need to have a hook within Boost::regex). This would be a lot harder to do in Notepad++, though, since it integrates the search as part of Scintilla’s search function.
-
I believe that I assumed (bad move on my part) that NOT checking the “. matches newline” also meant that the RE would only run in respect to single logical lines (regardless of the use of “.” or a character set in the expression). I was thinking that this was the equivalent of adding /m to the end of a Perl RE.
. matches newlineis the equivalent of(?s)/min Perl or(?m)in a Perl RE or PCRE or Boost/Notepad++ RE changes whether^and$match at the beginning or ending of every line –(?m)says they do,(?-m)says they only match beginning-of-full-string and end-of-full-string. Since, in Notepad++, the “full string” is the entire document,(?-m)^will match only at the beginning of the document and(?-m)$will only match at the end of the docuement, making them equivalent to\Aand\Z.And just like in Perl RE,
(?s)only affects behavior of.and(?m)only affects behavior of^and$– neither of those options influences behavior of `` character classes. For any character class, if you want to include or exclude newline sequences, it must be explicitly part of the character class. The same is true for actual Perl regex or PCRE or Boost as used in Notepad++.So, if N++ has the feature at all (honoring logical lines), I don’t know how to invoke it.
As generically as you define “honoring logical lines”, Boost does not have that feature, nor does any other regex language I’ve dealt with (as far as I know).
Obviously, I can code that into the RE myself,
And that is the correct behavior, whether in Notepad++'s Boost or in Perl.
I thought maybe this meant that I could do
?-m^.*[^"]*test$those options must be in parens;
?-mis searching for “0 or more of the previous token”, but there is no previous token. Notepad++ even tells you this if you hover over the speech bubble in the error:
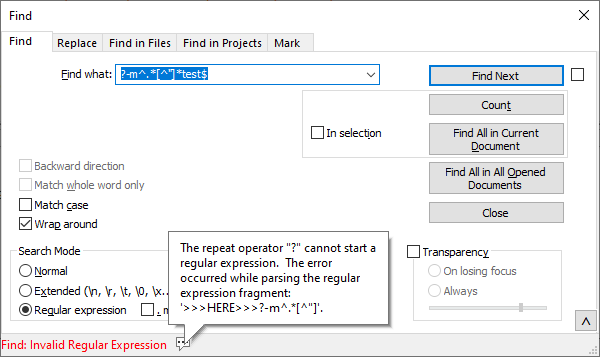
or
(?-m)^.*[^"]*test$but that just results in “Invalid regular expression.”The first resulted in Invalid Regular Expression; the second just finds no match, because you’ve told it that
^should only match the beginning of the file and$should only match the end of the file, and your file is more than one line long. -
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
So, if N++ has the feature at all (honoring logical lines), I don’t know how to invoke it. Obviously, I can code that into the RE myself, but for the same reason that /m exists in Perl REs I would think this would be a useful feature to have.
See
(?s)in npp manual for Regex. Normally something like.*stops at the end of the line. When(?s)is active then.*stops at the end of the file. Like all of the flags, you can toggle this on and off as needed in an expression and can toggle the state several times if desired.Semi related is that
\Rworks much like(?:\r\n|\r|\n)meaning it will match any of the newline styles.abc\Rdefmatchesabcdefsplit in the middle.(?:.*\R)*will match from the current position to the end of the file much like(?s).*.For example, yesterday I wanted to select the description text from the Windows event viewer’s detailed dump of events records and so used
(?-i)(?<=^Description:\r\n)(?s).*?(?=\REvent Xml:)$I used\r\ninstead of\Rin in the(?<=lookbehind)part as\Ris variable length, matching both 1 and 2 character end-of-line styles and lookbehind only works with a fixed length match. I chose to flip the(?s)flag on mid-expression to make it clearer that the middle part is the multi-line thing I was extracting. I left(?s)turned on as I knew it does not affect$anchors. -
Regarding your
Test_OK.txtandTest_KO.txtfiles…I have a resident script that shows me, e.g., “Found match 6 of 27” on the Find window’s status bar when I press Find Next.
I noticed that when trying your test for the
Test_OK.txtfile, my script crashes with this error in the PythonScript console window:editor.research(find_what_regex_text, lambda m: retval_list.append(m.span(0))) RuntimeError: The complexity of matching the regular expression exceeded predefined bounds. Try refactoring the regular expression to make each choice made by the state machine unambiguous. This exception is thrown to prevent "eternal" matches that take an indefinite period time to locate.Again note that this is for the
Test_OK.txtfile, where Notepad++ itself has no problem finding the match.My understanding is that PythonScript integrates its own copy of Boost, so, one would think, with all other things being equal (ha!), that it would succeed when N++ succeeds. But clearly something is not equal.
I thought this just another interesting tidbit in this topic’s “journey”. :-)
-
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
My understanding is that PythonScript integrates its own copy of Boost, so, one would think, with all other things being equal (ha!), that it would succeed when N++ succeeds. But clearly something is not equal.
There is a macro variable, BOOST_REGEX_MAX_STATE_COUNT, that influences one of the limits Boost::regex tests when evaluating whether to issue that message. Notepad++ leaves it at its default value, but it is possible that Python changes it.
-
@PeterJones said in Getting "Invalid Regular Expression" for an extremely simple expression:
or
(?-m)^.*[^"]*test$but that just results in “Invalid regular expression.”The first resulted in Invalid Regular Expression; the second just finds no match, because you’ve told it that
^should only match the beginning of the file and$should only match the end of the file, and your file is more than one line long.Well damn, you’re right. I was sure it gave me a syntax error for both of my examples. I must have gotten myself confused while I was testing.
Now that I see that, from my testing,
(?-m)means ^$ should match the beginning and end of the same line (no intervening LF) and(?m)(the default for NP++) means ^$ has to match the beginning and end of any line in the file. So(?-m)absolutely affects the[^"]*portion of the RE. -
Now that I see that, from my testing,
(?-m)means ^$ should match the beginning and end of the same line (no intervening LF) and(?m)(the default for NP++) means ^$ has to match the beginning and end of any line in the file. So(?-m)absolutely affects the[^"]*portion of the RE.I guess I used loose terminology when I described what
(?m)/(?-m)affect. I should have said those options affect the beginning-of-line^anchor and the end-of-line$anchor.They don’t affect all
^symbols, because in some locations, like the beginning of a character class where it negates the character class, and has nothing to do with the beginning-of-line-anchor^. To clarify,[^"]literally means “the class that contains every character that is not the ASCII double-quote”, and the^in that class is the class-negation operator, it is not the beginning-of-line anchor nor the literal ASCII caret character.With those definitions, I cannot see how
(?m)/(?-m)affect[^"]*. But, maybe I’m wrong. Can you share a text file and regex where they change the meaning of the[^"]*? (It would have to be something other than a regex that contains a^or$anchor, because those two anchors are affected by the m-option)Further, your statement of what the anchors mean in the non-multiline context (“
(?-m)means ^$ should match the beginning and end of the same line (no intervening LF)”) is not phrased in a way that matches with my experience and understanding of the specs. But maybe I am not interpreting that phrase in the way you intended.For this example, I will start with a 3-line file (ie, no empty line 4)
This file has multiple lines in itIf I run the regex
(?m)^and hit Find Next repeatedly, it will match at three locations, because^can match any beginning-of-line in that mode. If I run the regex(?-m)^, Find Next will only match the beginning of the first line, not the beginning of lines 2 or 3, because(?-m)restricts^to only be the beginning of the string rather than of any line (where, in Notepad++, the string is either the entire file). Similarly,(?m)$will match the end of lines 1, 2, and 3; whereas(?-m)$will only match the end of the last line of the file.Your phrasing indicates to me that you think that the
^and$have to be on the same line in(?-m)mode, but my examples show that’s not right – but again, maybe I am misunderstanding your sentence.Combining the two ideas: the example file has no quote marks, so
[^"]*will match all the non-quote characters the same file). Thus,(?m)^[^"]*$will match from the beginning of the file to the end, as will(?-m)^[^"]*$– the m-state is irrelevant. Then make it non-greedy:(?m)^[^"]*?$will only match one line at a time, because the$causes the non-greedy section before it to stop at the first end-of-line found; on the other hand,(?-m)^[^"]*?$will still match the entire file – because the^anchor only matches at one location in the entire file (at the beginning) and the$anchor only ; in this non-greedy, the m-state changes the meaning of the^and$anchors, not the meaning of the[^"]*?.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login