Replace 2nd occurrence in string per line, then nth occurrence Npp v8.8.1
-
I’m trying to simplify my regex for this task:
I have this input text:
foo bar bash 1 foo dash mesh 3 foo poly 3 for foo foo tar hash 1 foo gash gesh 3 foo toly 3 vor foo foo sar wash 1 foo rash nesh 3 foo koly 3 sor fooThe regex replaces the 2nd occurence of this string ‘foo’:
foowith this new string:
XOOCurrently I’ve used this regex which works:
Find what (with Regular Expression radio button on):^(.*?foo.*?)fooReplace with:
$1XOOProducing this output:
https://regex101.com/r/UmF5wv/1foo bar bash 1 XOO dash mesh 3 foo poly 3 for foo foo tar hash 1 XOO gash gesh 3 foo toly 3 vor foo foo sar wash 1 XOO rash nesh 3 foo koly 3 sor fooIf needing the 3rd occurence instead, just adding the 2nd occurence into the group used with the placeholder works this way:
Input:
foo bar bash 1 foo dash mesh 3 foo poly 3 for foo foo tar hash 1 foo gash gesh 3 foo toly 3 vor foo foo sar wash 1 foo rash nesh 3 foo koly 3 sor fooOutput:
https://regex101.com/r/hmcZ1l/1foo bar bash 1 foo dash mesh 3 XOO poly 3 for foo foo tar hash 1 foo gash gesh 3 XOO toly 3 vor foo foo sar wash 1 foo rash nesh 3 XOO koly 3 sor fooFind:
^(.*?foo.*?foo.*?)fooReplace:
$1XOOMy problem is it can become long with many occurences.
Is there a simpler/shorter way to do it, maybe with some sort of indexing if available?
-
@Fra said in Replace 2nd occurrence in string per line, then nth occurrence Npp v8.8.1:
^(.*?foo.*?foo.*?)fooThat regex behaves the same as
^((?:.*?foo){2}.*?)fooso if you want to keep the first 5, and do the replacement on the N+1=6th, it would be
^((?:.*?foo){5}.*?)foo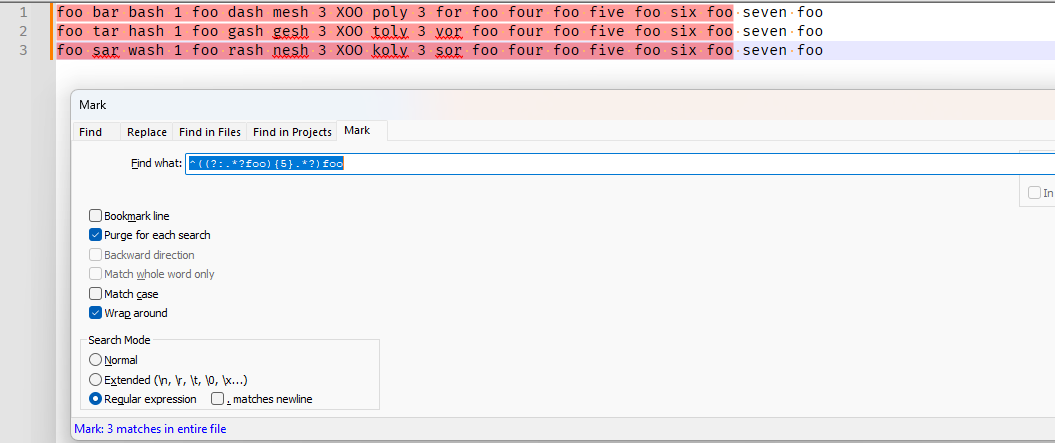
=>
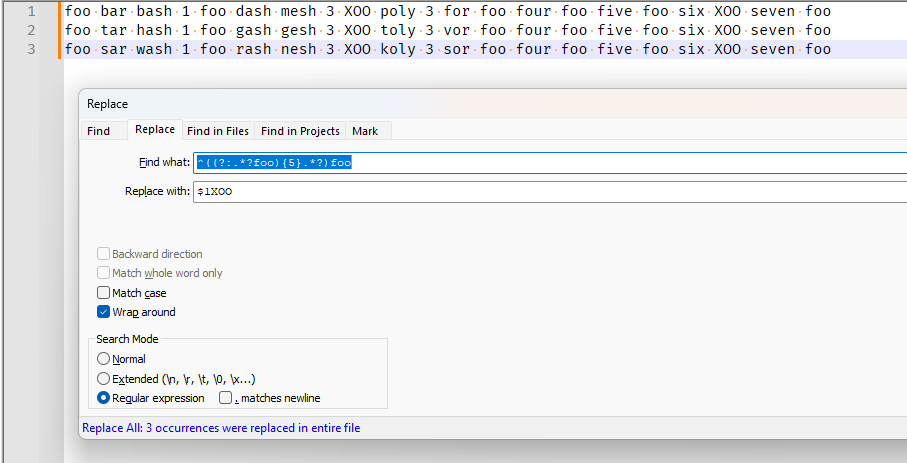
[URL] regex101.com [.../URL]Please note that
regex101.comdoesn’t use the same regex engine as Notepad++'s Boost regex, so there can sometimes be differences in results. (Not in this instance, but in general, one shouldn’t assume that a regex will work at some website and in some unrelated app unless you know that they use the same engine, or it’s a simple enough one that it’s only using the syntax common to both engines.)-—
Useful References
-
@PeterJones Nice solution, with minimal editing needed, just what I was looking for!
Thanks for the refs too, I’ll check them out asap!Nice too the indexing starts from zero:
{0} = 1st occurrence.
^((?:.*?foo){0}.*?)fooOutput:
XOO bar bash 1 foo dash mesh 3 foo poly 3 for foo poly 3 for foo poly 3 for foo{1} = 2nd occurrence.
^((?:.*?foo){1}.*?)fooOutput:
foo bar bash 1 XOO dash mesh 3 foo poly 3 for foo poly 3 for foo poly 3 for foo{2} = 3rd occurrence.
^((?:.*?foo){2}.*?)fooOutput:
foo bar bash 1 foo dash mesh 3 XOO poly 3 for foo poly 3 for foo poly 3 for foo{3} = 4th occurrence.
^((?:.*?foo){3}.*?)fooOutput:
foo bar bash 1 foo dash mesh 3 foo poly 3 for XOO poly 3 for foo poly 3 for foo{4} = 5th occurrence.
^((?:.*?foo){4}.*?)fooOutput:
foo bar bash 1 foo dash mesh 3 foo poly 3 for foo poly 3 for XOO poly 3 for foo{5} = 6th occurrence.
^((?:.*?foo){5}.*?)fooOutput:
foo bar bash 1 foo dash mesh 3 foo poly 3 for foo poly 3 for foo poly 3 for XOOand so on.
-
@Fra said in Replace 2nd occurrence in string per line, then nth occurrence Npp v8.8.1:
Nice too the indexing starts from zero:
Personally, I would say that’s a dangerous way to think about it, and it will confuse you as you learn more about Boost regex and capture groups.
The
{ℕ}“multiplying operator”, as described in the documentation, is saying there must be ℕ matches of whatever came before the operator: so, in the case of my regex, it is saying "there must be ℕ occurrences of something followed byfoo, and all ℕ of those are put into capture group #1; group#1 must be followed by the (ℕ+1)th occurrence offoo, and it’s only that last that is replaced (because you included$1in the replacement, which means the contents of group#1.The problem with thinking of 0-indexing in this case is because it will confuse you as you learn more about capture groups. Because capture groups are numbered starting at 1, so
(a)(b)(c)will putainto group#1,binto group#2, andcin group#3 – a replacement of$3$1$2would becab. Further, “group#1” (referenced as$0in the replacement) is not one of the captured groups, but is, in fact, the entire match, so replacing with$3$1$2//$0would givecab//abc. Then you’ll get yourself into trouble thinking that it’s 0-based, because it’s really and truly 1-based. -
@PeterJones thanks a lot for the nuances. Indeed, I first wondered about the difference from the group indexing starting at 1. Then also about the difference from the quantifier ( {n} where n is an integer >= 1 https://www.regular-expressions.info/refquick.html).
Thanks for the $0 group placeholder mention, I wondered about that too, now I understand what it captures.I understand the regex as this:
Find:
- Put everything that preceeds the occurence of interest into a group (1st group referenced by the placeholder with the starting index at 1 ($1) — though there is a placeholder 0 ($0) which references the whole set/string instead of any subgroup of it)).
- Exclude the occurence of interest from the that group, but state is a the search delimiter for the regex just outside the group.
Replace with:
- Capture the group with it’s placeholder (make a copy of it and store it: $1 = foo / ^((?:.?foo){0}.?) for the 1st occurence (N+1) with index 0).
- Use the 2nd/next occurence as external delimiter reference to stop the regex search at (^((?:.?foo){0}.?)foo).
- Then append the new value (XOO) to the copied unchanged group.
I think I see what you mean when considering there must always be a 2nd /next occurence for the regex to work so it can’t be starting at zero? While in the background the engine uses a zero based indexing for the 1st element of the occurences series.
0 is the 1st element in the indexes series, 1 is the 2nd and so on.
While for the groups placeholders, 0 isn’t an ordinal reference, it’s an arbitrary reference to the set. The ordinal reference starting at 1 in this case.I need to check the doc and do more practice to get over the confusing parts!
The quantifier also starting at 1 though index 0 is still valid but return no value (or the whole set but with empty values)?
For example:
19 empty string matches:
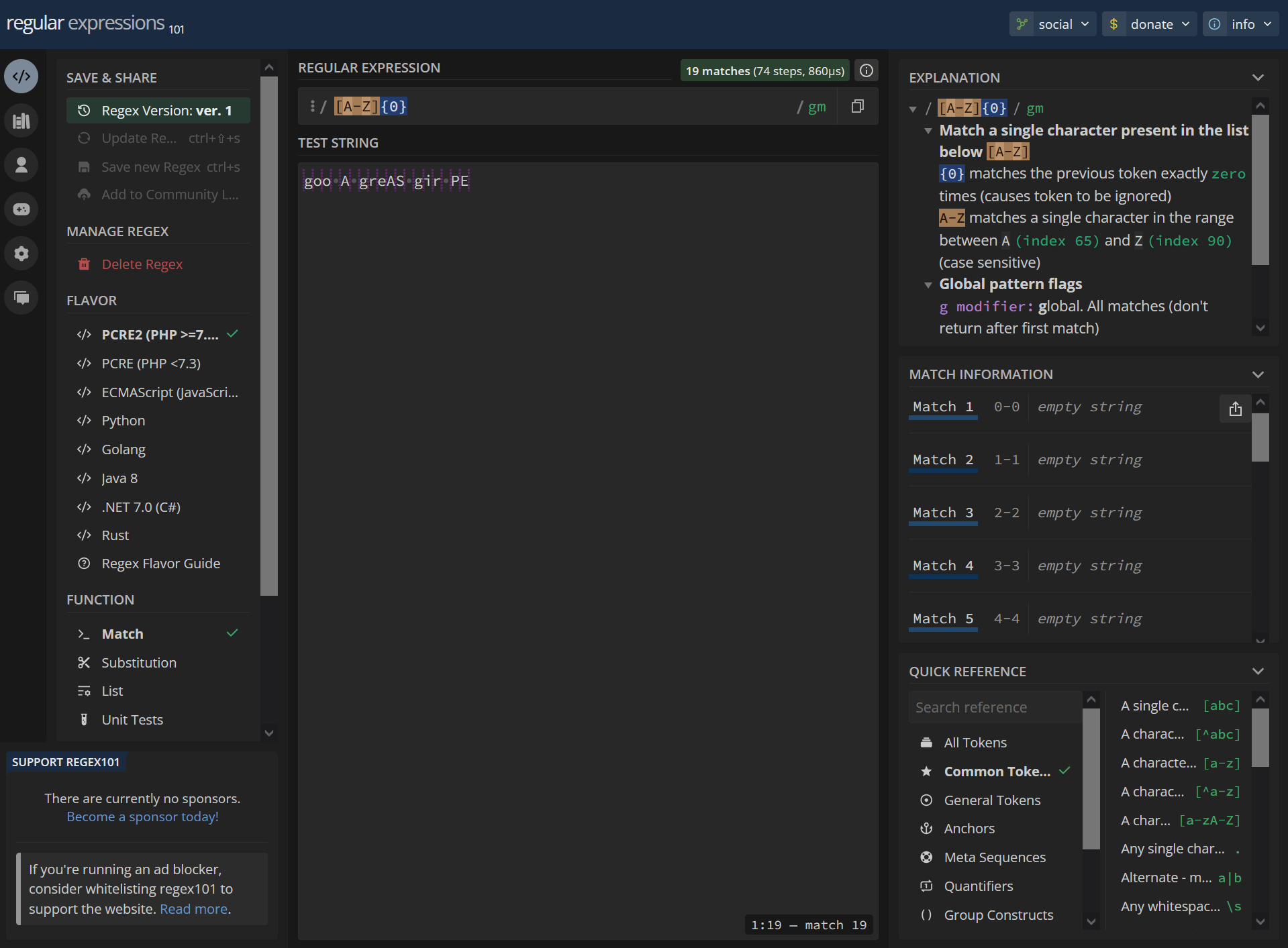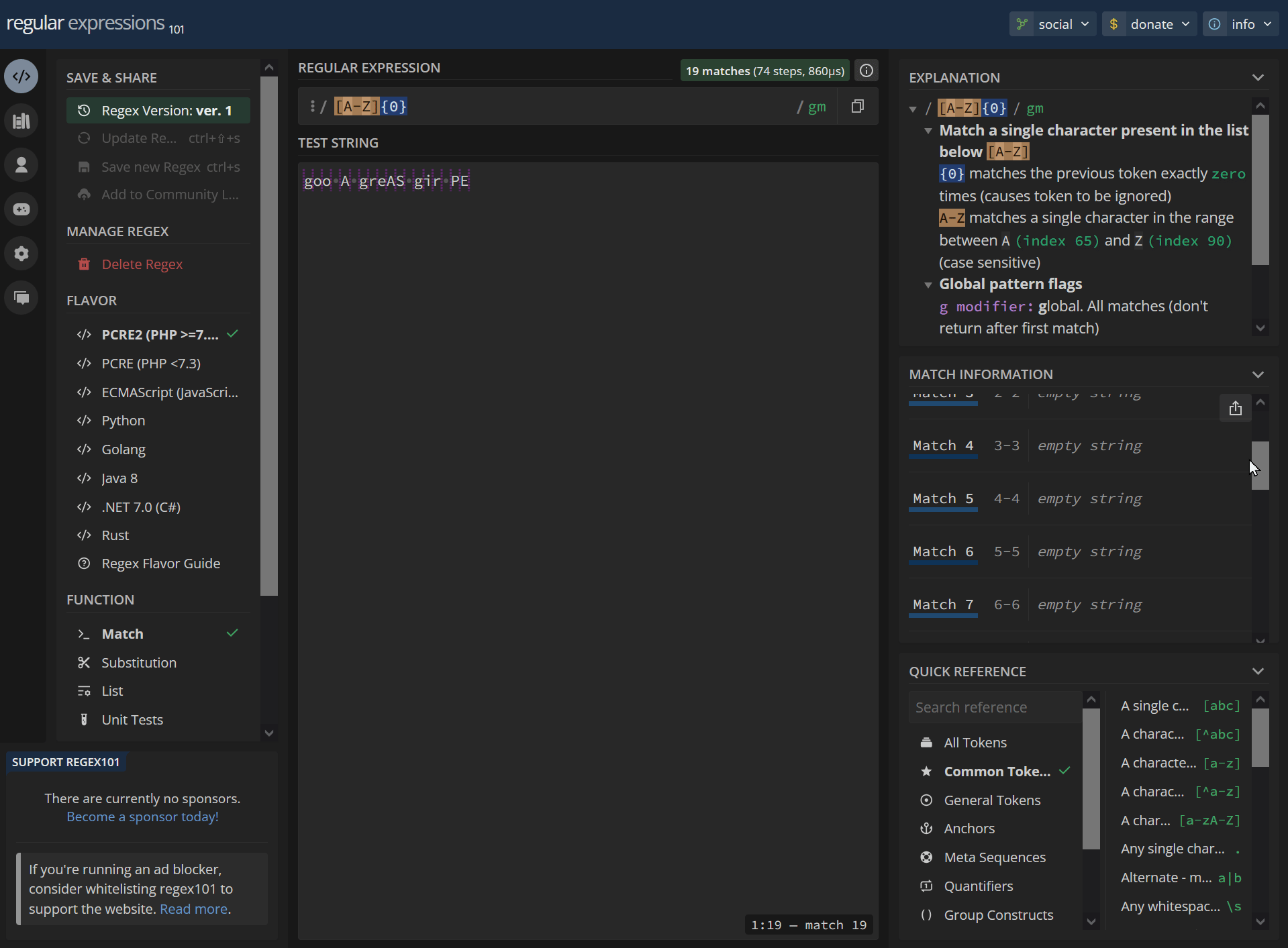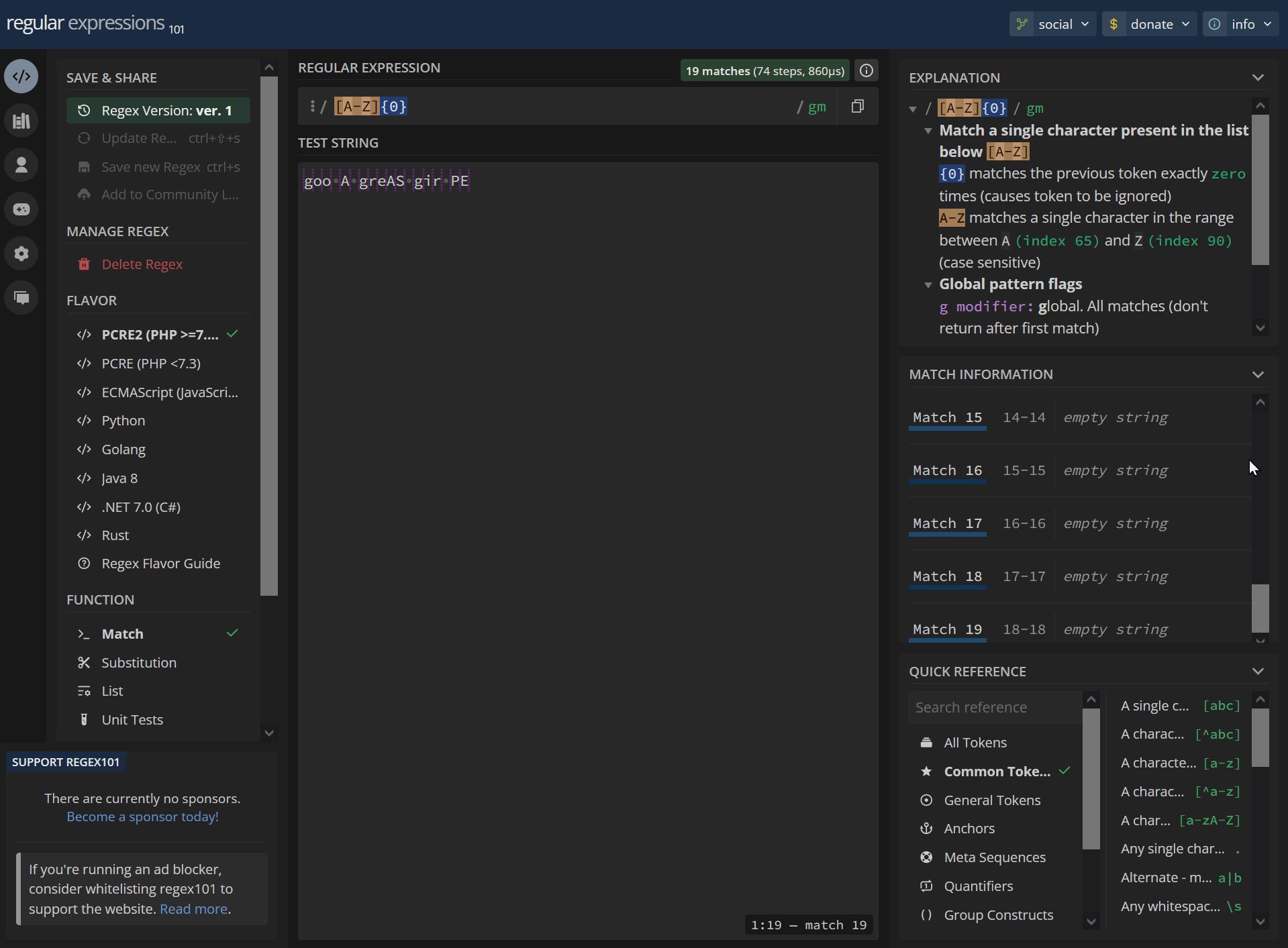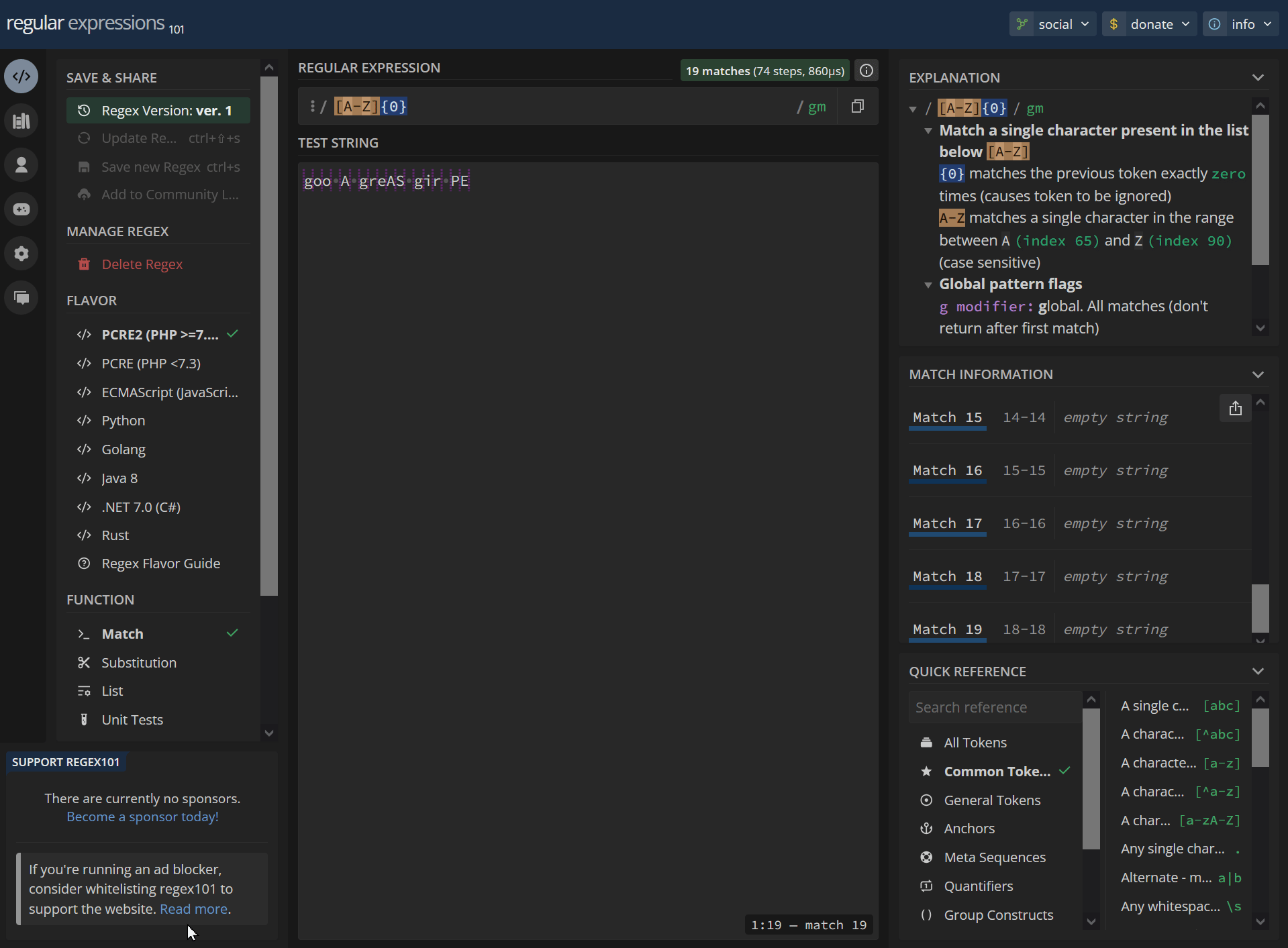
[A-Z]{0} goo A greAS gir PEhttps://regex101.com/r/dYnJmE/1
/ [A-Z]{0} / gm Match a single character present in the list below [A-Z] {0} matches the previous token exactly zero times (causes token to be ignored) A-Z matches a single character in the range between A (index 65) and Z (index 90) (case sensitive) Global pattern flags g modifier: global. All matches (don't return after first match) m modifier: multi line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)0-0 empty string 1-1 empty string 2-2 empty string 3-3 empty string 4-4 empty string 5-5 empty string 6-6 empty string 7-7 empty string 8-8 empty string 9-9 empty string 10-10 empty string 11-11 empty string 12-12 empty string 13-13 empty string 14-14 empty string 15-15 empty string 16-16 empty string 17-17 empty string 18-18 empty stringNo match/invalid:
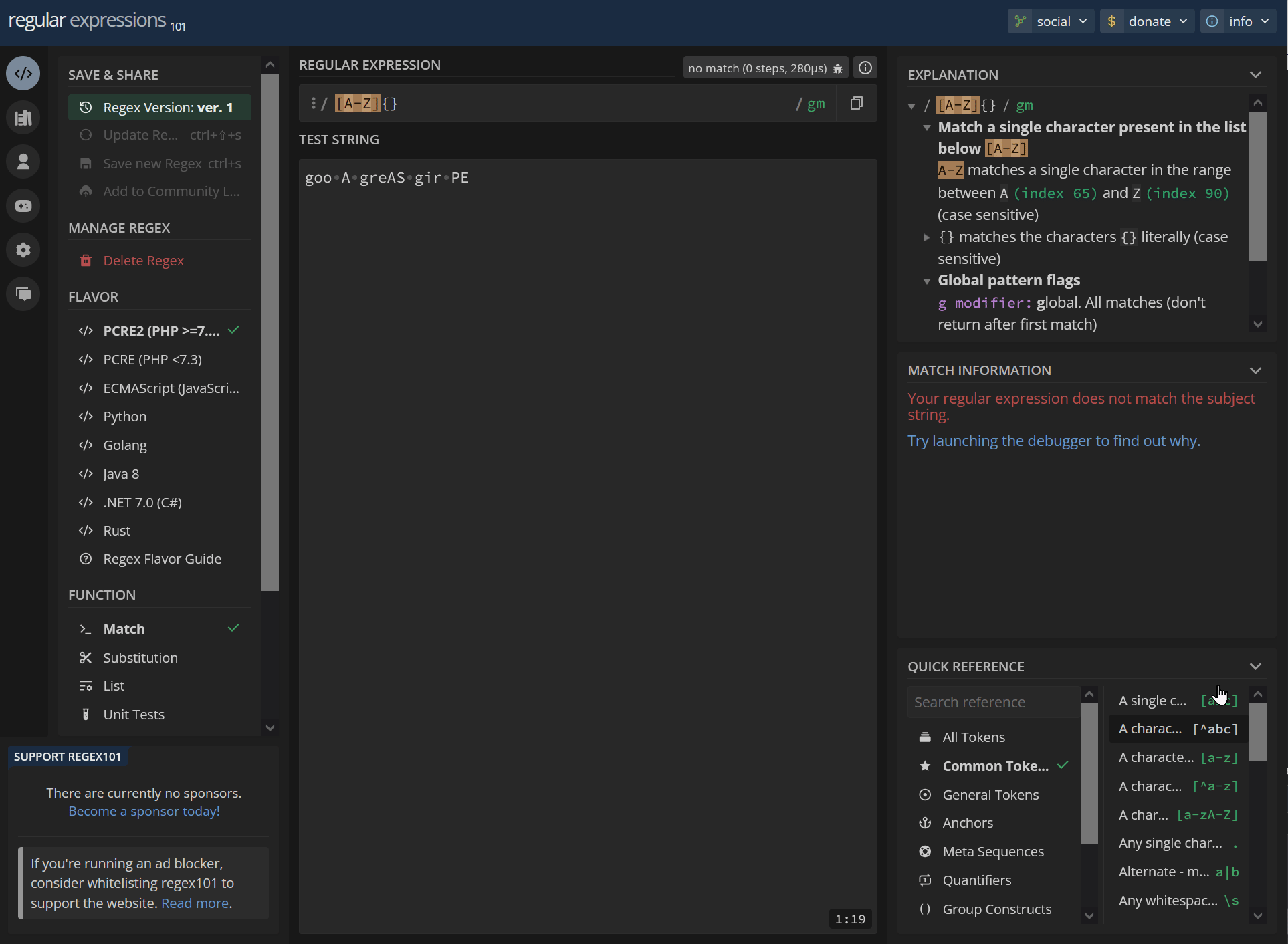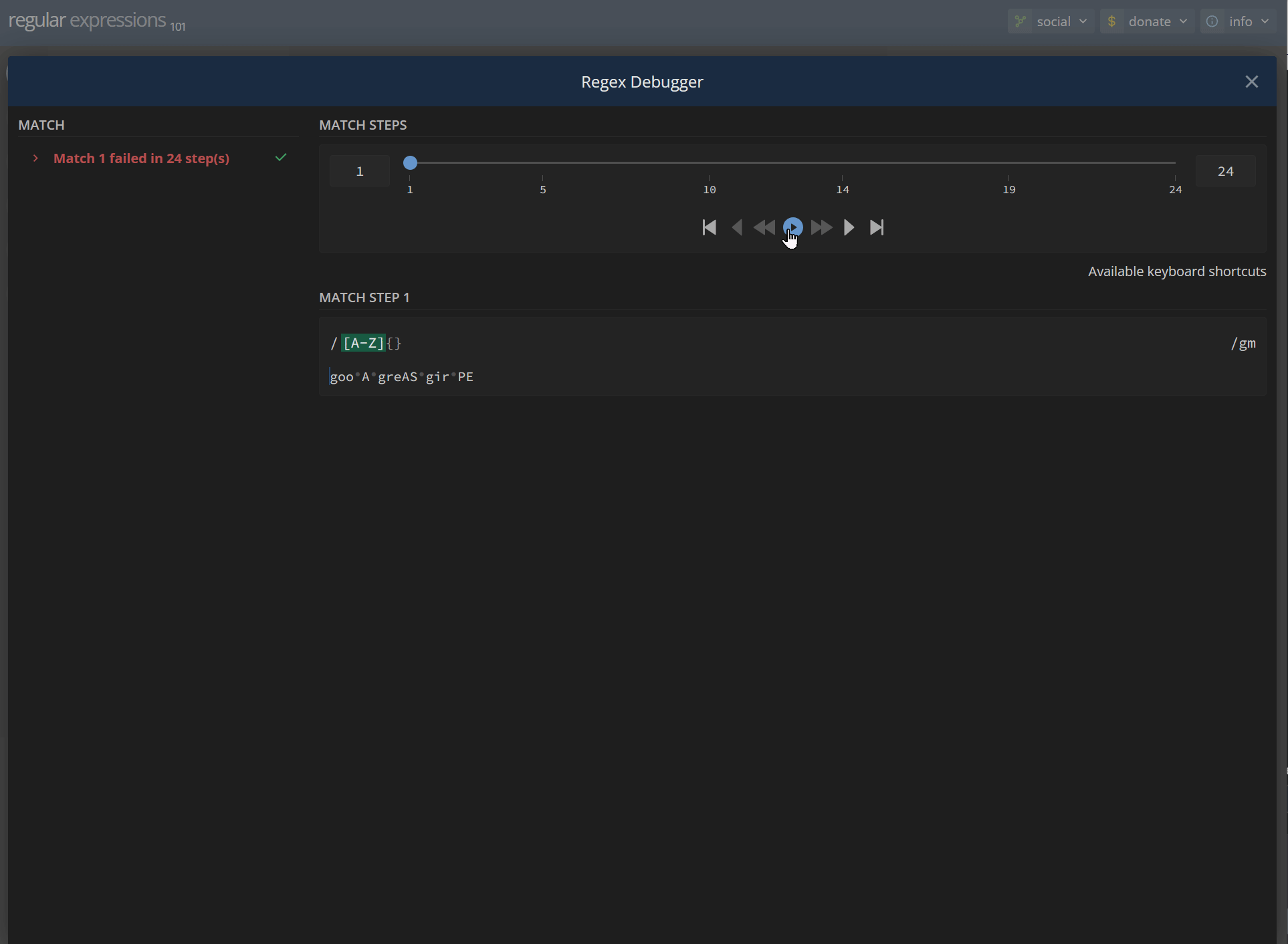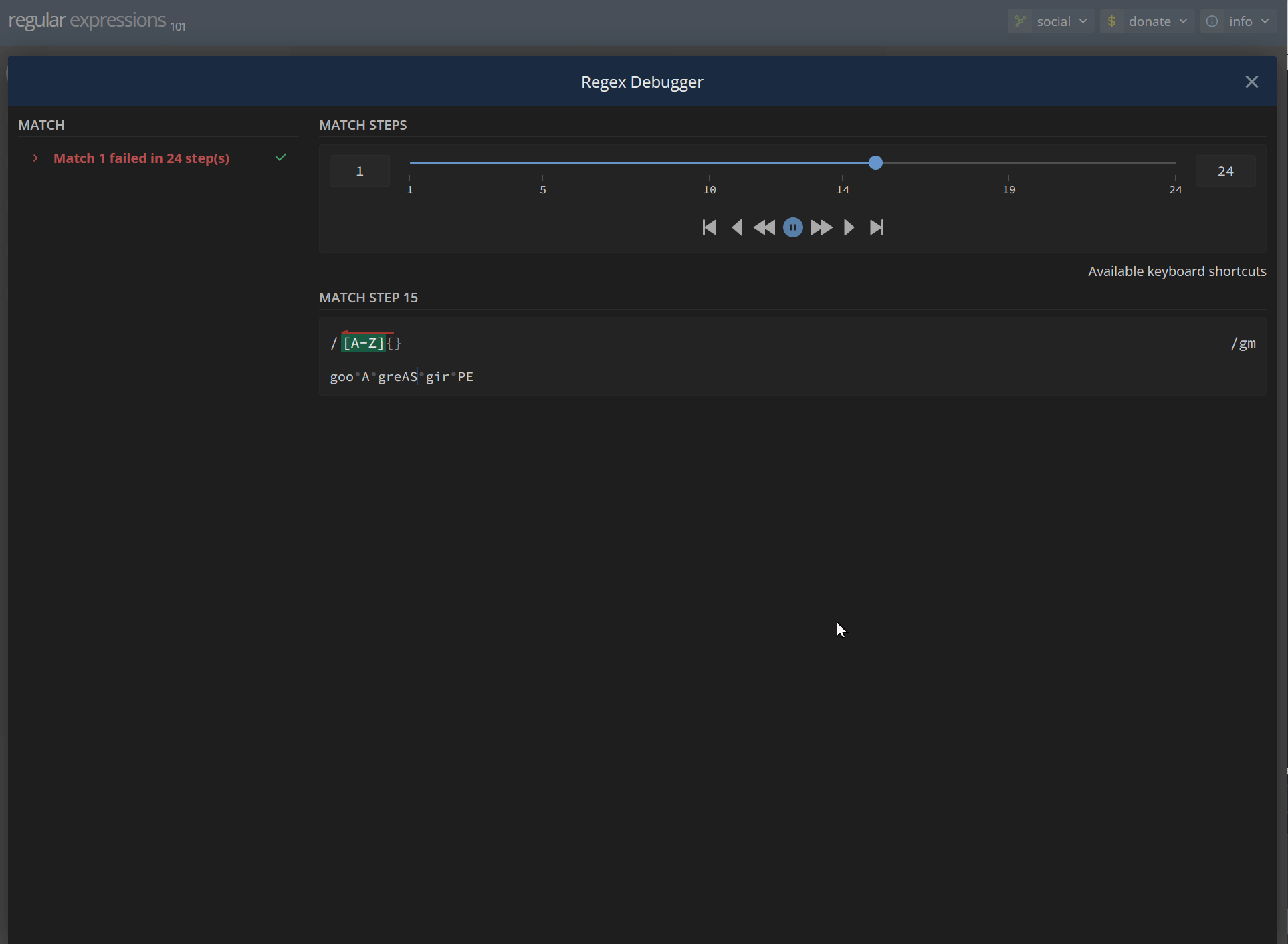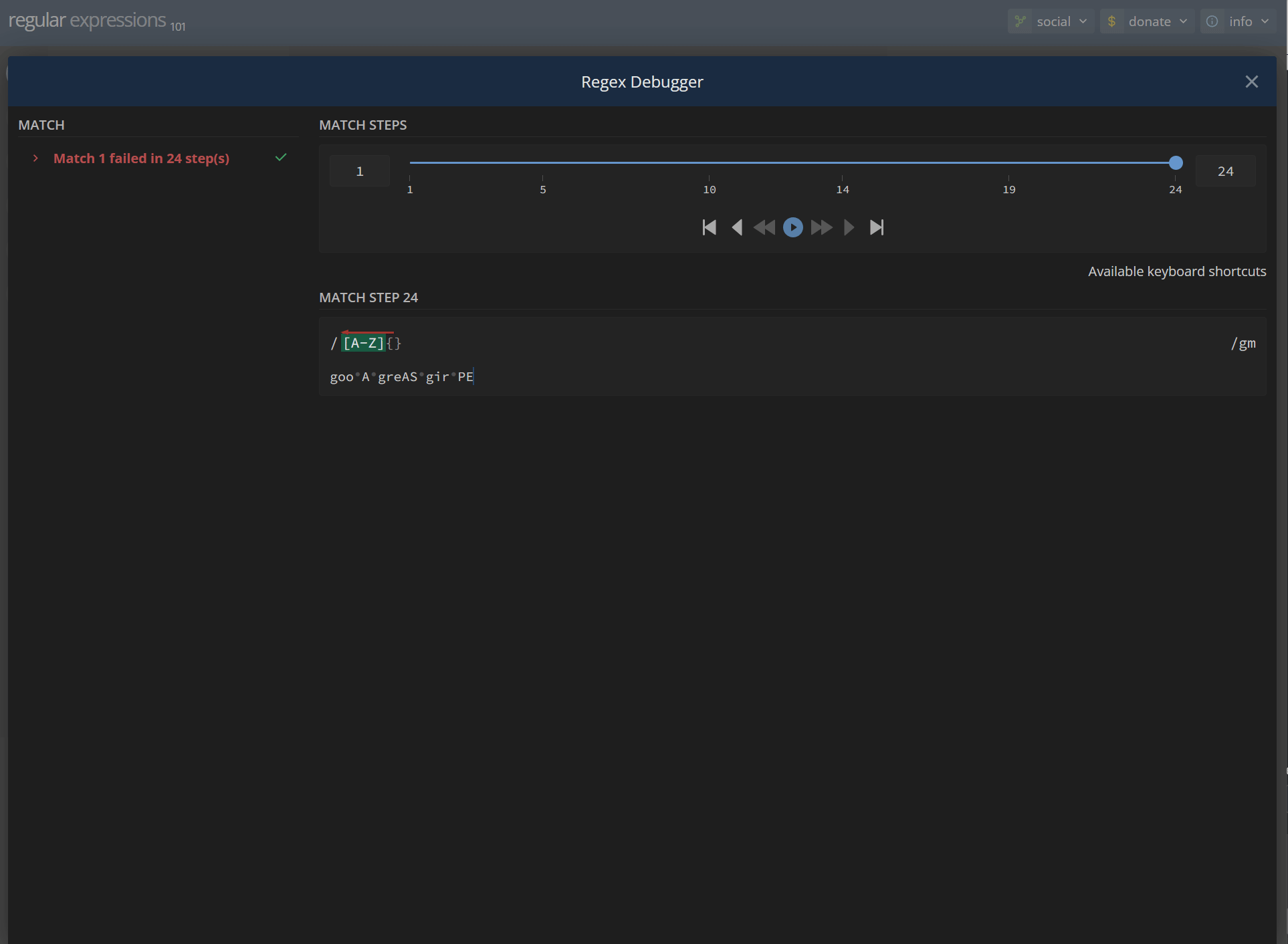
[A-Z]{} goo A greAS gir PEhttps://regex101.com/r/CtqQ0D/1
/ [A-Z]{} / gm Match a single character present in the list below [A-Z] A-Z matches a single character in the range between A (index 65) and Z (index 90) (case sensitive) {} matches the characters {} literally (case sensitive) Global pattern flags g modifier: global. All matches (don't return after first match) m modifier: multi line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)Your regular expression does not match the subject string.5 matches:
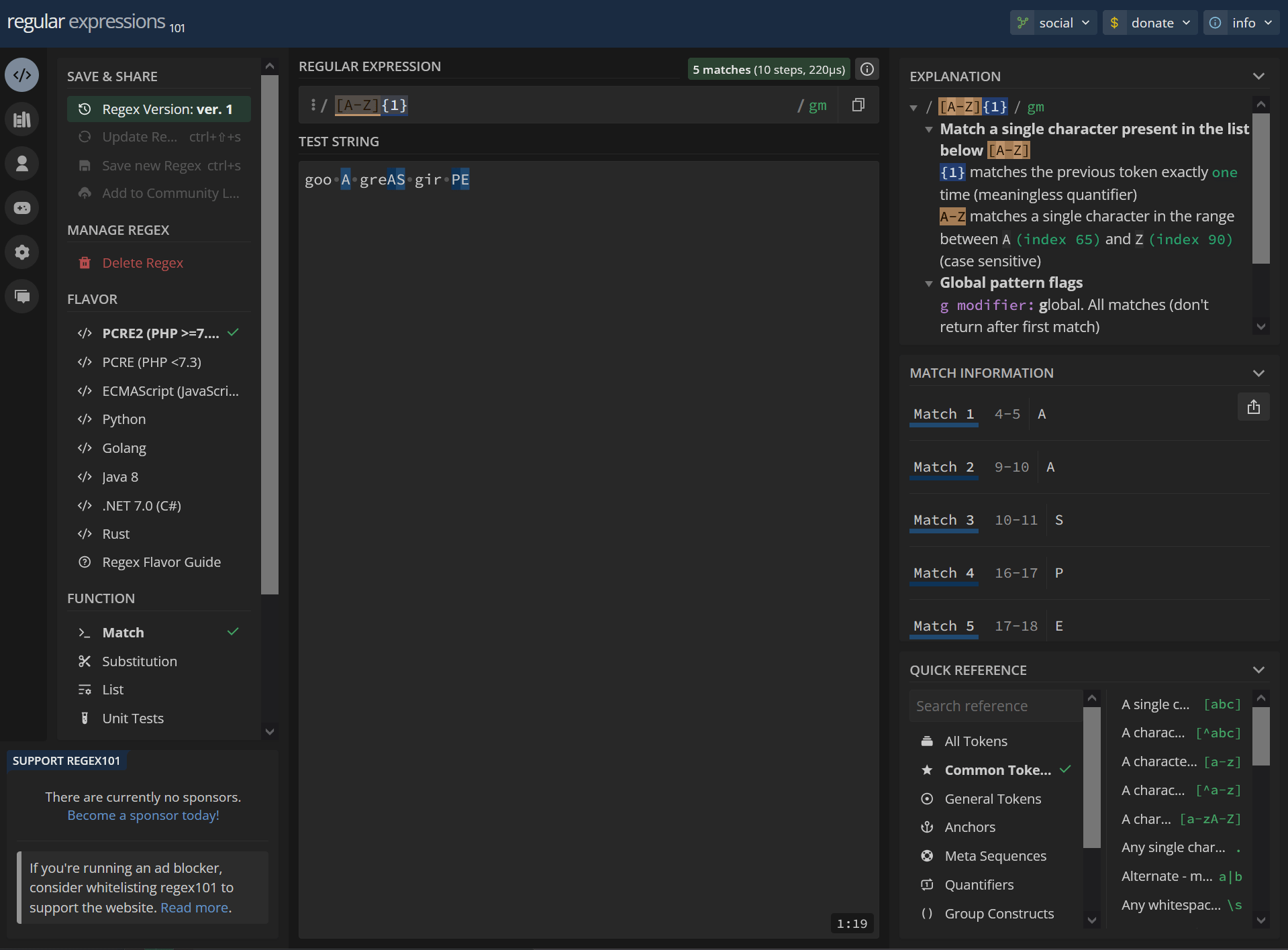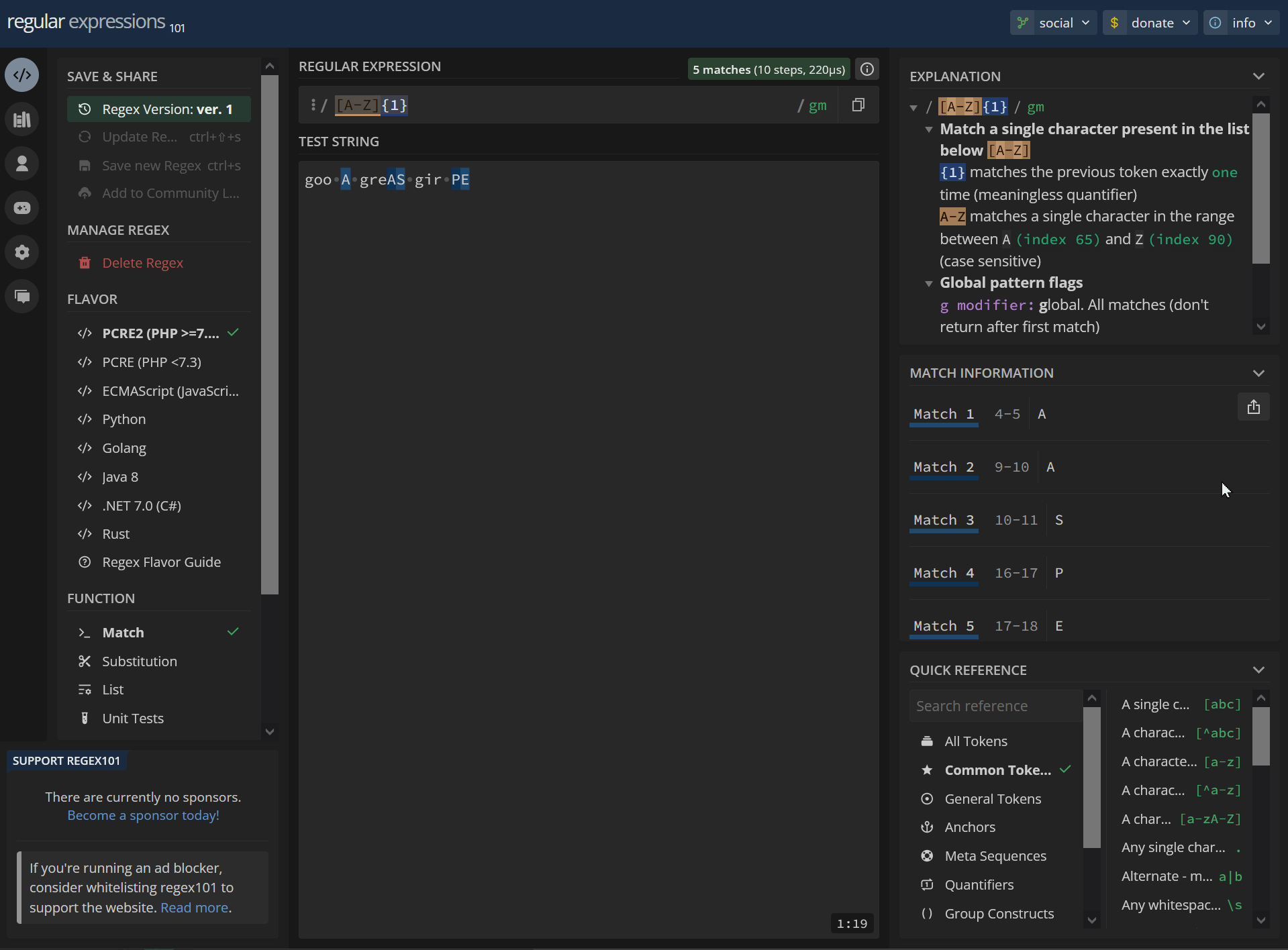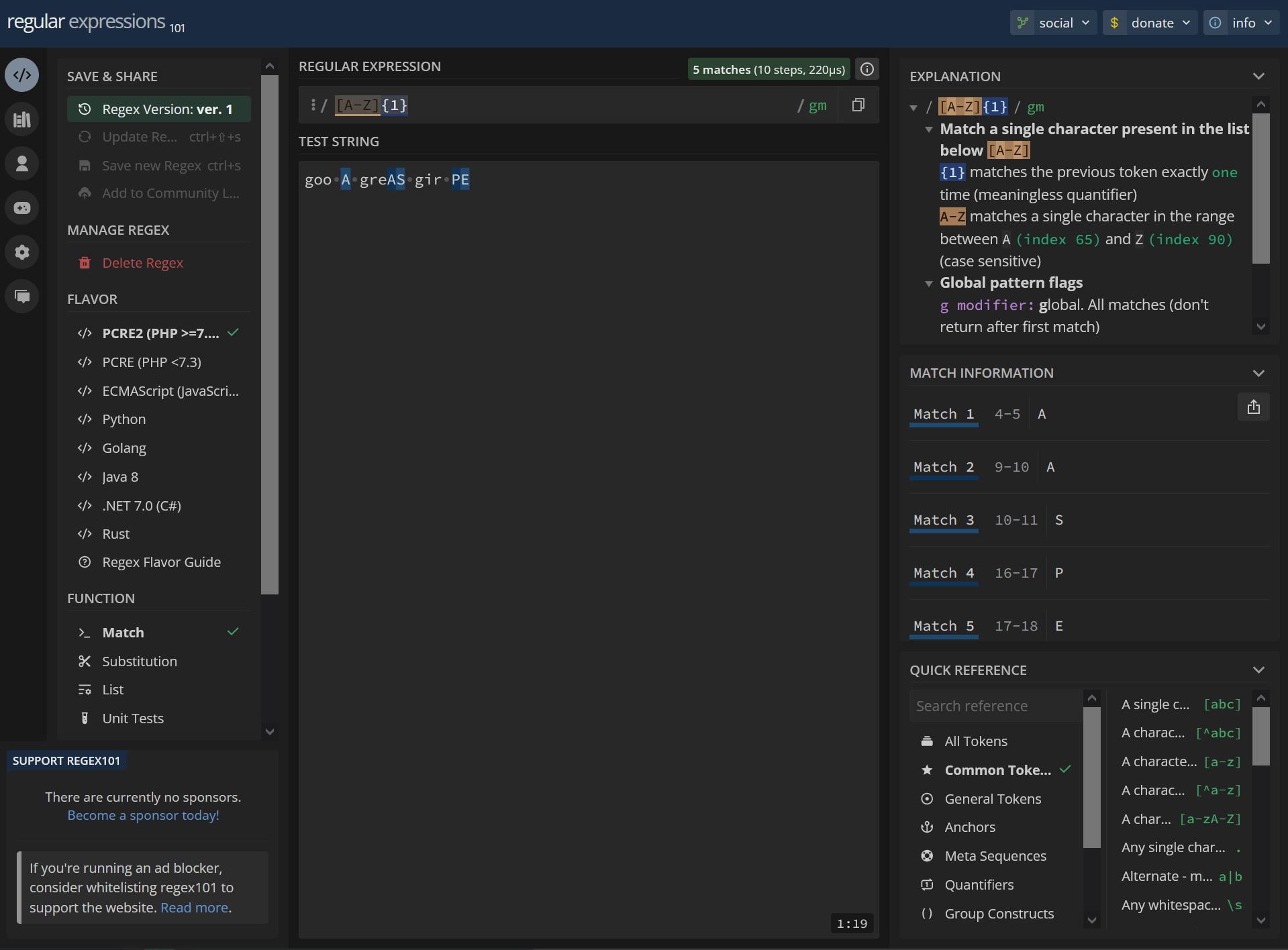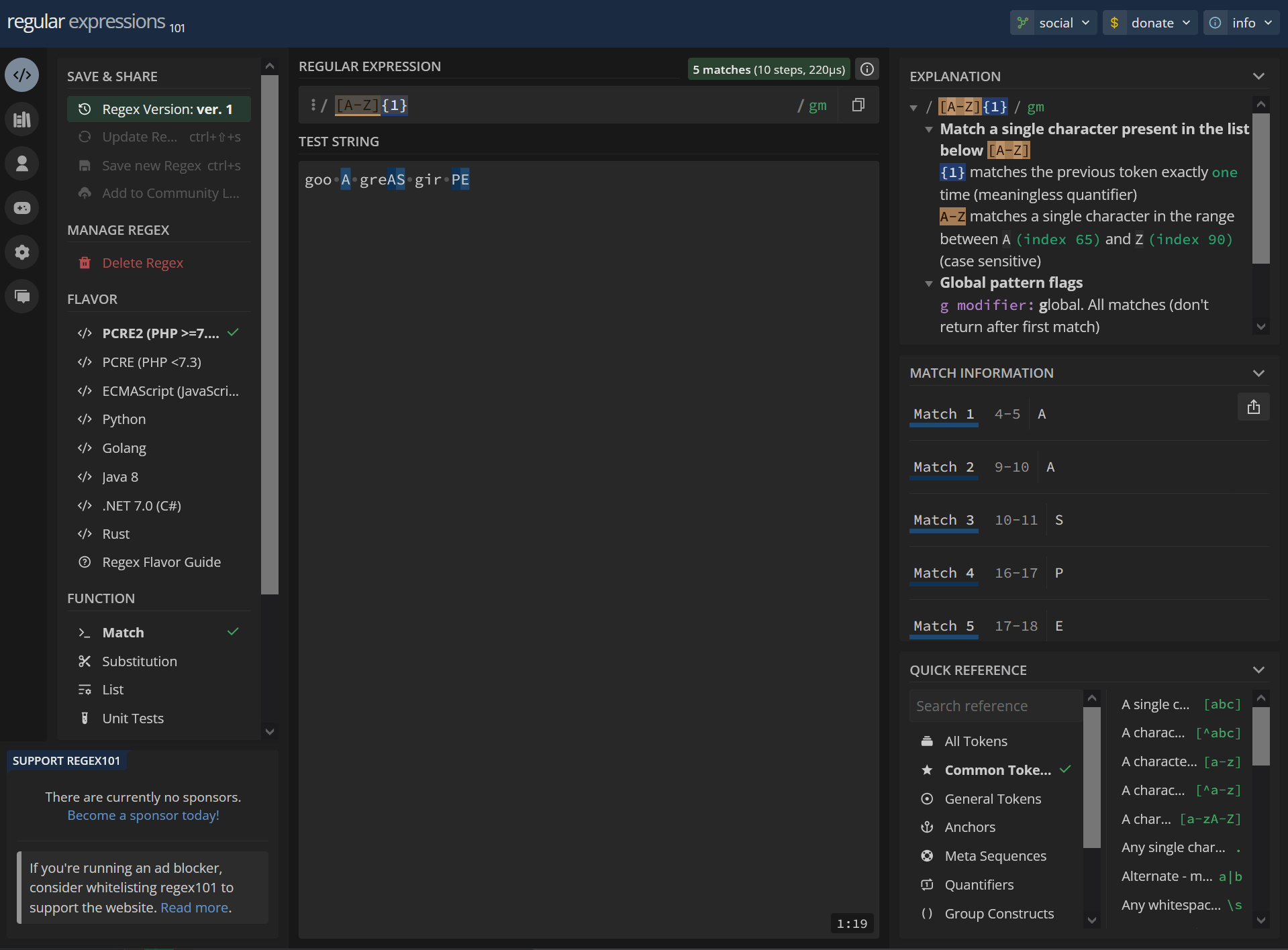
[A-Z]{1} goo A greAS gir PEhttps://regex101.com/r/MImsNL/1
/ [A-Z]{1} / gm Match a single character present in the list below [A-Z] {1} matches the previous token exactly one time (meaningless quantifier) A-Z matches a single character in the range between A (index 65) and Z (index 90) (case sensitive) Global pattern flags g modifier: global. All matches (don't return after first match) m modifier: multi line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)4-5 A 9-10 A 10-11 S 16-17 P 17-18 E2 matches:
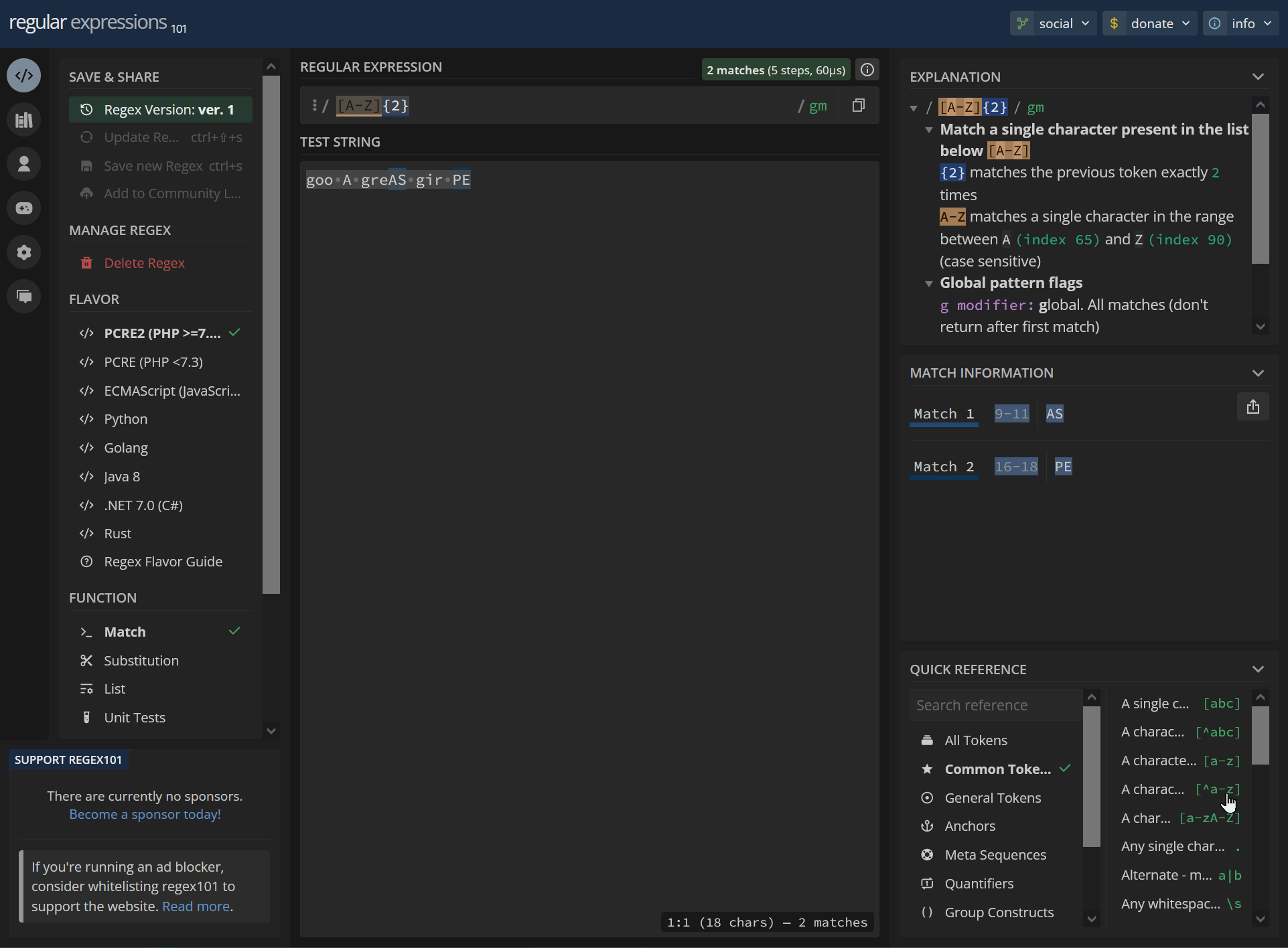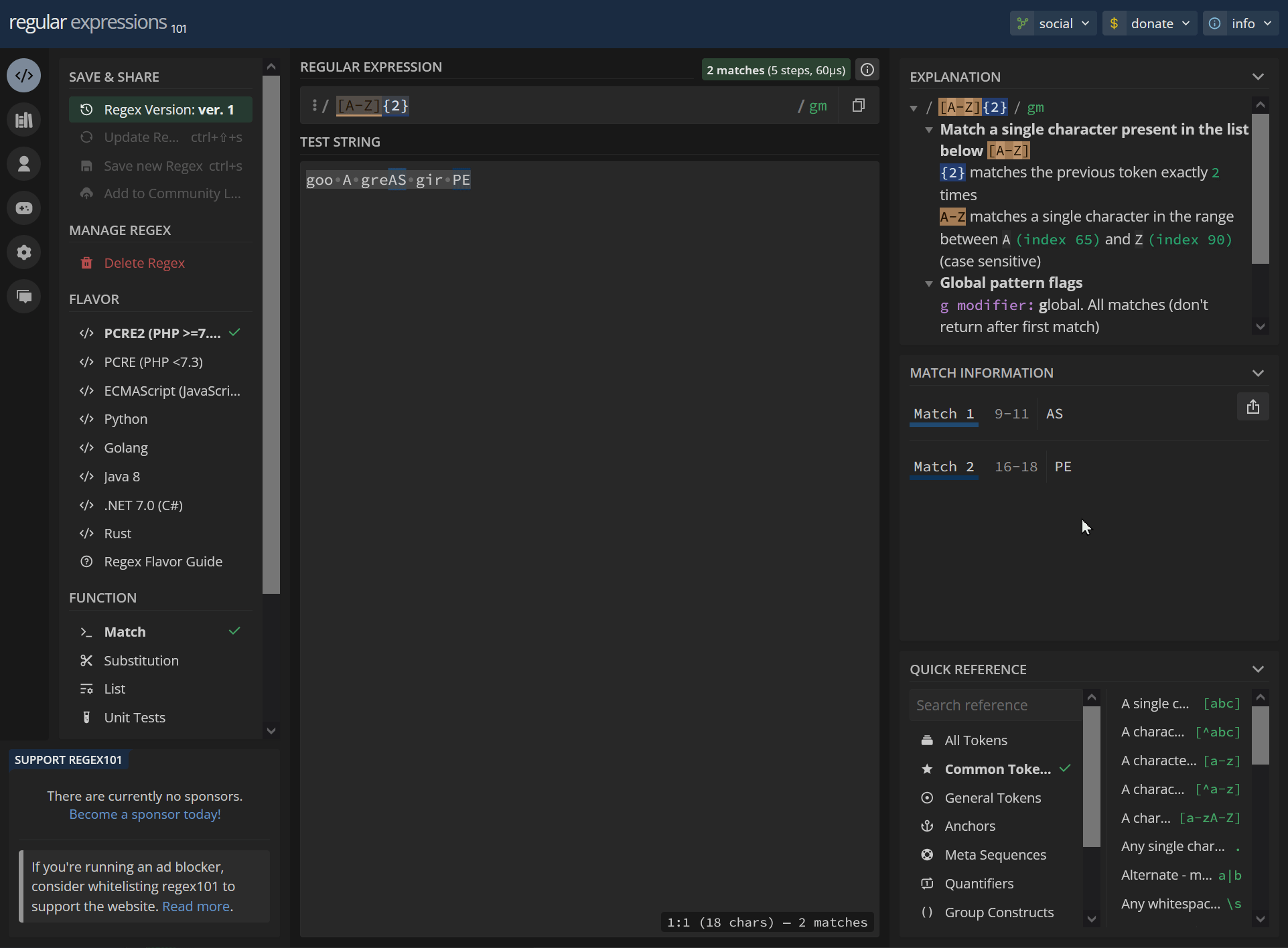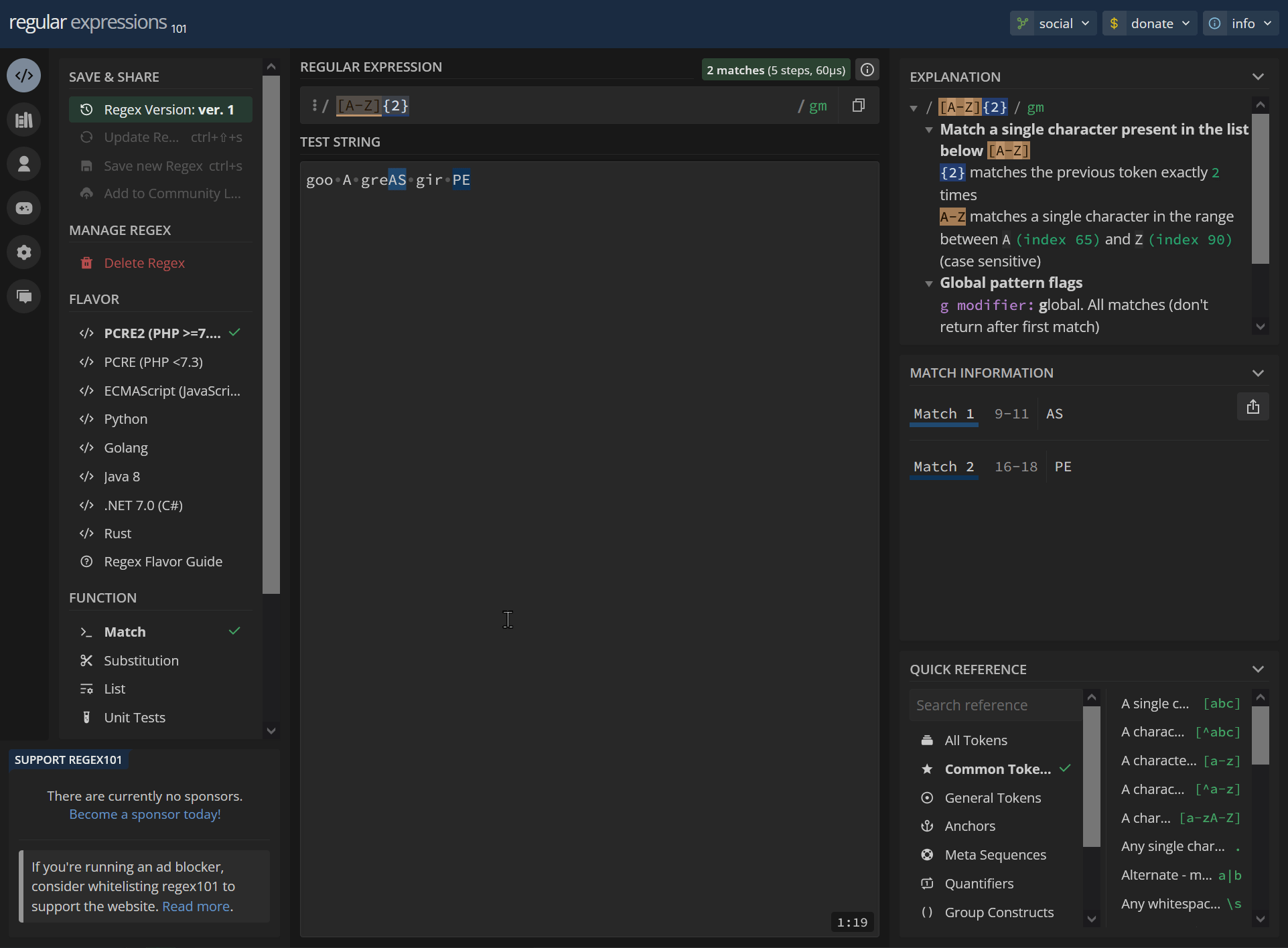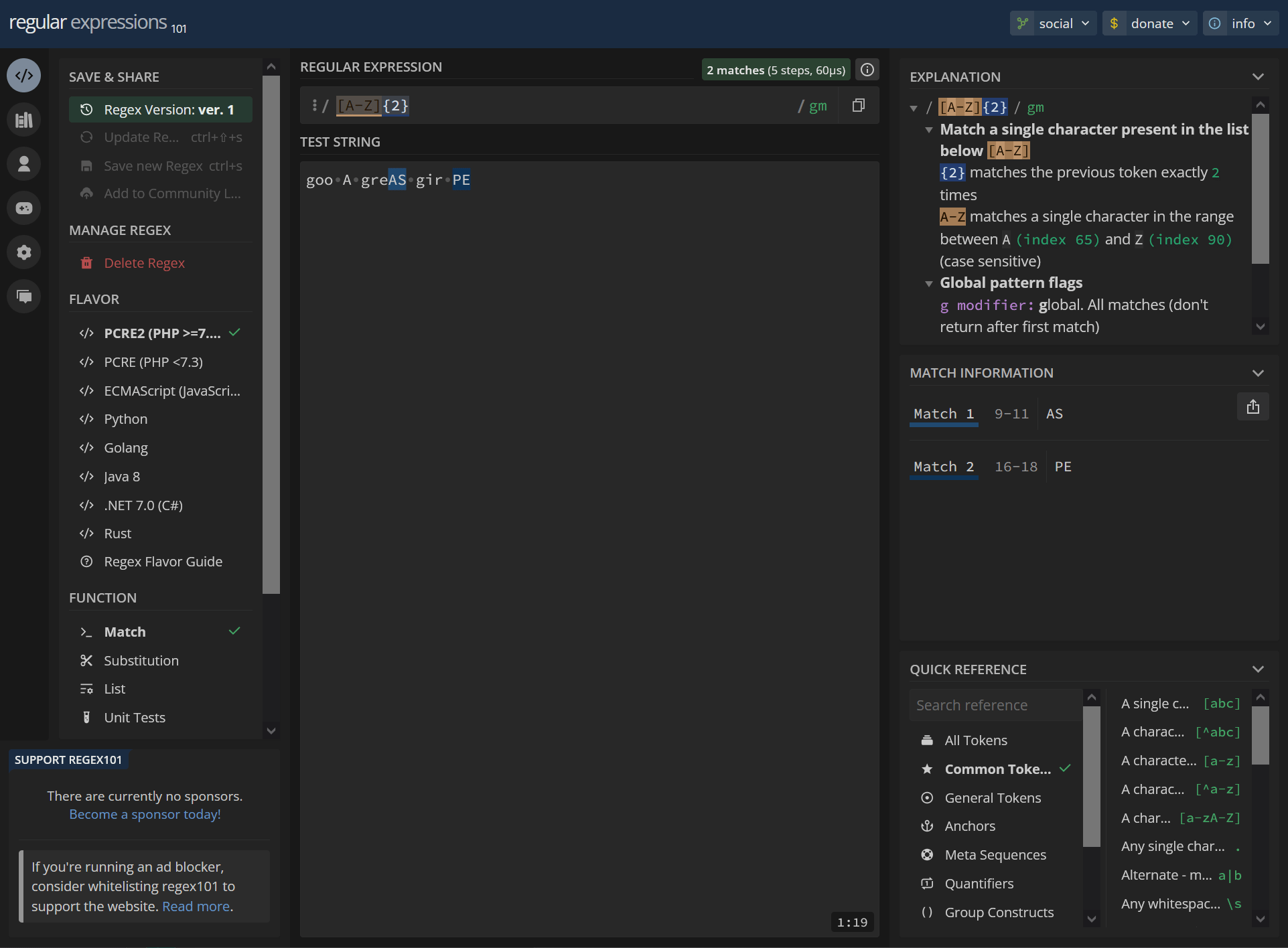
[A-Z]{2} goo A greAS gir PEhttps://regex101.com/r/p1WOWQ/1
/ [A-Z]{2} / gm Match a single character present in the list below [A-Z] {2} matches the previous token exactly 2 times A-Z matches a single character in the range between A (index 65) and Z (index 90) (case sensitive) Global pattern flags g modifier: global. All matches (don't return after first match) m modifier: multi line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)9-11 AS 16-18 PE
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login