Marked text manipulation
-
@dail , @Claudia-Frank :
Thanks for your inputs, I used the basic ideas but came up with my own Pythonscript version that is much faster than my original PS version on large files, and seems to correctly handle the oddities of the editor.indicatorEnd() function previously mentioned.
So here is RedmarkedTextToClipboard2.py:
def RTTC2__main(): SCE_UNIVERSAL_FOUND_STYLE = 31 # N++ red-"mark" feature highlighting style indicator number ind_end_ret_vals_list = [] ierv = 0 while True: ierv = editor.indicatorEnd(SCE_UNIVERSAL_FOUND_STYLE, ierv) # editor.indicatorEnd() returns 0 if no redmarked text exists # editor.indicatorEnd() returns last pos in file if no more redmarked text beyond the 'ierv' argument value if ierv == 0 or len(ind_end_ret_vals_list) > 0 and ierv == ind_end_ret_vals_list[-1]: break ind_end_ret_vals_list.append(ierv) if len(ind_end_ret_vals_list) > 0: if editor.indicatorValueAt(SCE_UNIVERSAL_FOUND_STYLE, 0) == 1: # compensate for weirdness with editor.indicatorEnd() when a match starts at the zero position zero = 0; ind_end_ret_vals_list.insert(0, zero) # insert at BEGINNING of list if editor.indicatorValueAt(SCE_UNIVERSAL_FOUND_STYLE, ind_end_ret_vals_list[-1]) == 0: # remove end-of-file position unless it is part of the match ind_end_ret_vals_list.pop() start_end_pos_tup_list = zip(*[iter(ind_end_ret_vals_list)]*2) # see https://stackoverflow.com/questions/14902686/turn-flat-list-into-two-tuples accum_text = '' for (start_pos, end_pos) in start_end_pos_tup_list: accum_text += editor.getTextRange(start_pos, end_pos) + '\r\n' if len(accum_text) > 0: editor.copyText(accum_text) # put results in clipboard RTTC2__main() -
Hi Scott,
a nice one - good performance improvement. :-)If you are still looking for performance increase,
a general suggestion would be to use as less global objects as possible within a loop as
the cost of loading global is expensive.
Cache global objects at the beginning of the script.
Creating the tuple list from the beginning should be faster than creating from a flat list.
Meaning do your two indicatorEnd calls and create a tuple from the results which than
gets added to a list.
Maybe a list comprehension to create the accum_text is faster as well - but not really sure
as it would need to call the global object.
All in all I assume this might make it faster up to 3-5%, not sure if it is worth thinking about it.Cheers
Claudia -
not sure if it is worth thinking about it.
I should have posted my before-and-after timing, but really, the “before” was “forever” on my 70MB data file! The “after” was extremely quick, certainly on par with how long it took Notepad++'s Mark feature to redmark my desired text. Therefore performance was rated “very acceptable” for the new version. And that’s really all the performance I care about, so further optimizations aren’t worth it to me. Probably some of those optimizations you suggest would make the code less readable, too, so I’m definitely not wanting to go there (although now I leave myself open to comments on how readable/unreadable the existing code is). :-D
I probably would have written this better the first time around if how these “indicator” functions worked was better documented!
Until Notepad++ natively allows a non-destructive (@guy038’s regex method is destructive…but there is UNDO…hmmm) copy of all regex-matched text, this little script will serve me nicely, now on all files big and small.
-
I have read almost all post but i did not know exactly, what was the problem … however i am continue read this forum and know the new things …[Dissertation Proposal Writing Service](LINK REMOVED)
-
I am in the same situation but regular expression method is not working for me to copy match text.
I want to grab all occurrences in configuration file where first line starts from ‘object’ and immediately second line starts with ‘nat’
object network obj_any
nat (inside,outside) dynamic interface
object network obj-test
nat (DMZ1,outside) static 10.206.49.180
object network obj-192.168.236.200
nat (DMZ1,outside) static 10.206.74.60
object network obj-192.168.236.8
nat (DMZ1,outside) static 10.206.49.183 tcp 8080 80
object network obj-192.168.236.9
nat (DMZ1,outside) static 10.206.49.178 tcp 1002 22
object network obj-192.168.236.10
nat (DMZ1,outside) static 10.206.49.178 tcp 8080 80
object network obj-192.168.236.13
nat (DMZ1,outside) static 10.206.74.58 dnsI wrote regular expression ^object.\R\snat.* to grab both lines
starting with ‘object’ and with ‘nat’ but when I am replacing it with
(?1\1), it is deleting the matched lines. Any dea what could be the correct replace string to keep only matced two lines -
Not sure exactly what you are asking but on your data this seems to work to match it:
Find-what zone:
(?-s)^object.*\Rnat.*But what’s this about replacement? This thread is just talking about matching text, redmarking it, and copying it…so I’m confused about what you want to do…
-
@Scott-Sumner sorry for the confusion. What I want, whatever my regular expression matches, it is two line match (first line starts with ‘object’ and second line starts with ‘nat’). So like my regular expression will catch 100 instances of two lines below in huge file with other data as well and I want to copy that multi-line match.
object network obj-192.168.236.13
nat (DMZ1,outside) static 10.206.74.58 dns‘mark’ is marking all lines but ‘bookmark’ is only bookmarking first line, not second line so I cannot copy through bookmark.
So question is how to copy all instances of multi-line match by regular expression?
-
Have you actually read this thread from top to bottom? If so, have you tried setting up and using
RedmarkedTextToClipboard2.pyabove? If I’m understanding your need correctly (still have my doubts) it seems as if that would solve the problem… -
@Scott-Sumner I will try this script. But without script, is it possible to copy multiple instances of matched result (that is multi-line) by regex in a text file?
-
Ummmm, well…No…that’s why the script was developed in the first place…seems like this should be obvious from the earlier postings in this thread…
-
Hey all,
I know this topic is quite old, anyway decided to share solution I’ve discovered (I’m not so technical, so Python script isn’t the option for me). So, long story short, I’ve extracted a long JSON response and needed to copy 95 URLs from it only and ignore everything else. Like in @Suncatcher’s case, everything was stored in a single line.
So, I did the following:
-
Search for
https://site.com/project/(.*?)regexp and replace all matches with\r\nhttps://site.com/project/$1\r\nso URLs were moved to separate lines; -
Afterward, switch to “Mark” tool, check “Bookmark line” option and mark all
https://site.com/project/(.*?)
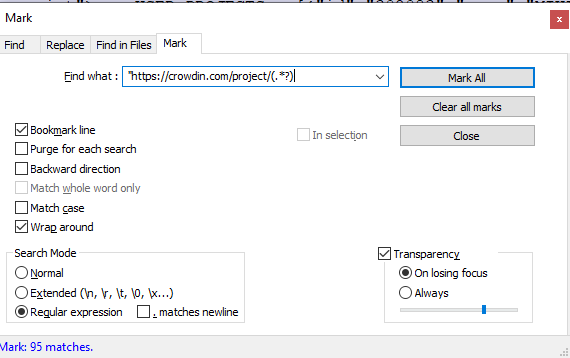
-
Finally, click “Search” menu => Bookmark => Remove unmarked lines
That’s it, list of necessary items only (URLs in my case) was created 🎉 My case is easier comparing to topic’s author, anyway hope this will be helpful for someone in the future, cheers!
P.S. @guy038 thanks for mentioning Bookmark feature, I’ve never used it before and it’s super helpful
-
-
More old thread revival…
So I recently had a need for what is discussed in this thread, but I needed it embedded in a Pythonscript, and all I really needed was the logic conveyed by @guy038 with this solution:

So I figured out the Your regex to match part for my data; I’ll use
Bob|Tedhere for that for purposes of illustration, and of course some sample data:Alice Carol Alan Bob Ted Ted Bob Bob Carol Ted Ted Carol Alice Carol Alice Bob Bob Alan Carol Alan Alice Bob Carol Alan Alice Bob Ted Alan Alice Ted Alan Ted Ted Alan Alice Carol Bob Ted Alice Carol Bob Alan Alice Carol Alan Bob Ted Alan Carol Ted Alan Bob Alice Carol Ted Alice Bob Alan Alice Bob Carol Bob Carol Bob Ted Alan Alice Alice Ted Alan Carol Alice Carol Alan Alice Bob Ted Carol Ted Alanand I coded up the Pythonscript one-liner for it based on @guy038 's regex:
editor.rereplace(r'(?s)^.*?(Bob|Ted)|(?s).*\z', r'(?1\1\r\n)')and I thought I would end up with a number of lines with either
BoborTedon them. What actually happened was that I ended up with a single-line result ofAlice! Clearly, INCORRECT! Or at least not what I needed.Digging in and working on it a bit, I found a correct way to achieve it in a Pythonscript replacement, and that is:
editor.rereplace(r'(?s)(Bob|Ted)|(?:.+?(?=(?1)))|(?:.+\z)', r'?1\1\r\n')which, for the sample data above, yields the expected:
Bob Ted Ted Bob Bob Ted Ted Bob Bob Bob Bob Ted Ted Ted Ted Bob Ted Bob Bob Ted Ted Bob Ted Bob Bob Bob Bob Ted Ted Bob Ted TedSo, long story LONG, but I wanted to share that if anyone tries this technique using a script, the search regex to use might need to be altered to:
SEARCH
(?s)(Your regex to match)|(?:.+?(?=(?1)))|(?:.+\z)The REPLACE part is unchanged from what @guy038 provided.
Note that I also tested it interactively in Notepad++'s Replace window and it works fine there as well, at least for my sample data.
-
Hello, @alan-kilborn and All,
I’m really sorry, because it’s just my fault and you wouldn’t have had to look for an alternative solution :-( Indeed, the regex S/R, that I gave in my post, below, does contains an error which is not important when using the Notepad++ Replace dialog, but which seems critical when you run a Python script, involving regexes !
https://community.notepad-plus-plus.org/topic/12710/marked-text-manipulation/8
I suppose that this fact should be related to this “small” point, located at the end of the description of the
editor.rereplacehelper method :An small point to note, is that the replacements are first searched, and then all replacements are made. This is done for performance and reliability reasons. Generally this will have no side effects, however there may be cases where it makes a difference. (Author’s note: If you have such a case, please post a note on the forums such that it can be added to the documentation, or corrected).
To understand the problem , let’s just use the beginning of your example text, pasted in a new N++ tab
Alice Carol Alan Bob Ted Ted Bob Bob Carol Ted Ted Carol Alice Carol Alice BobIf my generic regex S/R, below, with your regex choice
(Bob|Ted)is used, against this text :SEARCH
(?s)^.*?(Bob|Ted)|(?s).*\zREPLACE
?1\1\r\nWe get, after a click on the
Replace Allbutton or several clicks on theReplacebutton, and with theWrap aroundoption ticked, the following correct result :Bob Ted Ted Bob Bob Ted Ted BobNote that I use the
^assertion which forces the regex engine to search a range of chars beginning a line. Of course, in case of replacement, no trouble at all ! Indeed, due to the\r\nsyntax, any match\1is rewritten with a line-break. So, the next search, with the(?s)mode, automatically matches right after that line-break, added by the replacement !Now, let’s get back the initial text ( with
Ctrl + Z) and let’s suppose that we just want to trace the different matches of that regex S/R, using theFind Nextbutton only. In that case, we get only2matches !!??- Obviously, the first match is :
Alice Carol Alan BobBut the second and final match is :
Ted Ted Bob Bob Carol Ted Ted Carol Alice Carol Alice BobWhy ? Well, after the first match, the caret location is right after the word Bob of the first line. So, it cannot match the string space + Ted because this string should begin the current line, due to, both, the
^symbol and the grouping parenthesesAs the first alternative
(?s)^.*?(Bob|Ted)cannot match, at this location, the regex engine tries the other alternative(?s).*\z, which, of course, matches all the remaining characters of current file, beginning with space + Ted of the 1st line !!BTW, I don’t understand, Alan why you got a match
Alice. Indeed, when running :editor.rereplace(r'(?s)^.*?(Bob|Ted)|(?s).*\z', r'?1\1\r\n')I personally only get the forename Bob, which is the first word matched of the text !
Now, it’s easy to imagine the correct regex S/R to use : it should not contain any
^assertion and be as below :SEARCH
(?s).*?(Bob|Ted)|(?s).*\zREPLACE
?1\1\r\n( or?1\1\nfor an Unix file )This time, if you click, successively, on the Find Next button, you’ll be able to see the different matches of the search regex !
And, I did verify that the one-line script, below, without the
^symbol, gives the expected text ;-))editor.rereplace(r'(?s).*?(Bob|Ted)|(?s).*\z', r'?1\1\r\n')Best Regards
guy038
Two more points :
- Your new regex S/R :
editor.rereplace(r'(?s)(Bob|Ted)|(?:.+?(?=(?1)))|(?:.+\z)', r'?1\1\r\n')works correctly because it does not contain any
^assertion !but, would you had added the
^symbol, like below :editor.rereplace(r'(?s)(Bob|Ted)|(?:^.+?(?=(?1)))|(?:.+\z)', r'?1\1\r\n')it would had changed all your multi-lines example text as :
Bob- The lesson of that story is :
If you can properly visualize the different matches of a regex expression, as you expect to, when using the
Find Nextbutton, it’s likely that any replacement process, run from within aS/Rscript command, should work nicely, too ;-)) -
Thank you for the further analysis.
I’m really sorry, because it’s just my fault and you wouldn’t have had to look for an alternative solution
No worries at all! :-)
I don’t understand, Alan why you got a match (of only) “Alice”. I personally only get the forename “Bob”
Indeed! I guess “something happened” because if I re-run it now the same way I for sure get “Bob” as well! Sorry for that confusion.
Other comments:
I did not realize (obviously) that it was merely a case of a problem with the
^in the original expression. :-(
I totally jumped in to an almost wholly different solution, based upon something related I was working on.The lesson of that story is…
Nice to know!
-
Hello, @alan-kilborn and All,
So, as the result of our discussion :
This old post https://community.notepad-plus-plus.org/topic/12710/marked-text-manipulation/8
have been updated https://community.notepad-plus-plus.org/topic/19189/need-a-copy-marked-lines-feature/7
Cheers,
guy038
-
Semi-related info:
Part of this current thread is about how to copy text that one has marked via Marking that requires use of a PythonScript.
In a POST in another thread, I provide a script that will select text given conditions specified by user input. That selected text can then be copied.
Similar results thru some different methods; enough to warrant a cross-link, I guess.
-
Can anyone explain quickly how to use the python script? As in which steps I need to do in Notepad++ to run the script.
-
- Install PythonScript using Plugins > Plugins Admin
- Plugins > Python Script > New Script
- Paste the contents and save under
someName(whatever name you want) - Plugins > Python Script > Scripts >
someName - To add a keyboard shortcut for the script:
- Plugins > Python Script > Configuration,
- select the
someNamescript and Add to the menu - Restart Notepad++
someNamewill now be in the main Plugins > Python Script menu, not just in the Scripts submenu- Settings > Shortcut Mapper > Plugin Commands will see the script, and you can assign a keyboard shortcut
-
Peter maybe only made it 99.9999% clear. Perhaps the newbie 0.0001% might still be left wondering…
Peter’s step 4 would be how you actually run the script.
Be advised that in this particular case, you need to have some red-marked text for the script to operate on (hopefully this part is clear).
I think there is an open issue that would make this script’s functionality a native part of Notepad++. I will try to find it…
-
This may be the issue to which I was referring: https://github.com/notepad-plus-plus/notepad-plus-plus/issues/6095
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login