Type of duplicate lines
-
Hello, @sarah-duong, @Terry-r and All,
First of all, thanks for posting a real example of your text. However, I noticed that the very last line is :
idrzewicz@icloud.com:w0Re72Ht```And I suppose that the correct line is rather :
idrzewicz@icloud.com:w0Re72Ht
- Regarding your question
2, to delete line with an unique colon char, the Terry’s regex S/R is NOT :
SEARCH ^: \ R REPLACE Leave EMPTYbut, indeed :
SEARCH ^:\R REPLACE Leave EMPTYAssuming your example, after clicking on the
Replace Allbutton,6lines, with an unique:, are deleted !
- Regarding your question
1, to delete duplicates lines, you could use the following regex S/R :
SEARCH
(?-s)^(.+\R)(?=(?s).+?^\1)REPLACE
Leave EMPTYAgain, after clicking on the
Replace Allbutton, from your initial text of623mail addresses, we get, at once, the expected text of152mail addresses, all different !127victor@cox.net: a_nizam2032@yahoo.com: 2emajnllc@gmail.com: aaron.r.cameron@gmail.com: abradbery@gmail.com:q74Xpc0O 1talo@bluewin.ch: a-al-khaledi@hotmail.com: a_cameronsse@hotmail.com:jof6IutH abdullah.al.hajri0001@gmail.co: 4xtrader@tpg.com.au: 10241024simon@gmail.com: ac5.thomas@btinternet.com: a.tworowski@o2.pl:sXOa61Dq agaskill@maalnet.com: adgrant6180@yahoo.com.au: adelaideairportshuttles@gmail.: advanced80@xtra.co.nz: agarwalgaura@gmail.com: abrahamvthomas@hotmail.com: aaaerealty@yahoo.com: afoto@optonline.net: aj0312@my.bristol.ac.uk: aipunts@yahoo.co.uk:pul8OBa4 AccountingQB@brilloco.com: agilbert@hixworks.com: alagha.ahmad@gmail.com: ajurkovic@iinet.net.au: ageorgiev86@yandex.ru:dIYk0ONb alamrozek@interia.eu: akolanupaka@gmail.com: Albert.Lau@eastwestbank.com: alain_delongchamp@yahoo.com: Alemannia@gmx.com: akisa5577@gmail.com: alektron@aol.com: albertrodriguez28@yahoo.com: amendol1@verizon.net: abrarahmed325@yahoo.com: AMERAHMED19@GMAIL.COM: andreas.toerpel@web.de alert@infoplasticsurgery.com: alizenel@outlook.com: aldis@hostnet.lv: althielman@live.com: ALJOAMAYA@GMAIL.COM: alan.james68@icloud.com: alfred.kum@gmail.com: andreaszerbes@gmail.com: altumbabicnahid@gmail.com: andrew.chaveriat@gmail.com: aman.di@hotmail.com: andreas.toerpel@web.de: anisessaid5@gmail.com: andpanagiotop@gmail.com: ascrowe@wyoming.com: arash@42uag.com: anuvu@ymail.com: andrew.harnaga@hotmail.com: andrewdonnellyjr@aol.com:qu48OcaN argoman@hotmail.co.uk: alexrossouw196@gmail.com: andrzej.wencel@yahoo.com: arolaxinvestor@gmail.com: antuzla@outlook.com: asmoonlight@yandex.ru: atinton@hotmail.com: arkadyokrezna@gmail.com: anglinpaul@hotmail.com: balsara@icloud.com: antydoe@gmail.com: alistair@hexcollective.co.uk: ashley.brown@hushmail.com: axel@aadaum.de: azeezb22@gmail.com: artallison@aol.com: Badykshanov@gmail.com: andrew@ezestream.com.au: attention109@yahoo.com: ash-1989-@hotmail.com: barnettos@yahoo.com:e38Ldp5C bartekkuchnik@gmail.com: b.costin23@gmail.com: azyk1@yahoo.com: b.rowsell@bell.net: avysotsky@ukr.net: Berganphoto@aol.com: banksdw@slu.edu: BBJMcorp@aol.com: banking5151@gmail.com: bddoliveiro@gmail.com: bartir@hotmail.com: bcteo@pegasus-it.com.sg: arunasaste@gmail.com: blansford@LAMTexas.trade: BEDONEISM@HOTMAIL.COM: bimleshkumar@live.in: bengel1975@msn.com: blberger9@comcast.net: bobrabcd@frontier.com: baratina@gmx.net: bigblckdg@aol.com: bleda2_ju21@hotmail.com: bertfrigo@gmail.com: billsilk@ozemail.com.au: bobmedanovic@yahoo.com: bohetsj@gmail.com: banking5150@gmail.com: blansford@lrshouston.com:fKBm16Pd boothmark71@hotmail.com:bFVi84Kx bobsoneau@yahoo.com.au: brumbypat@hotmail.com: bohdarom@sbcglobal.net: bjh@yesyes.net: barakgr@live.com: braykm01@yahoo.com: bru.nico@alice.it: brooksforex1529@yahoo.com: carlo.paniccia@hotmail.com: bobwhite1946@yahoo.com: brianchatting@yahoo.co.uk: brchio@hotmail.com: boonwee.hong@gmail.com: cagoldman2005@yahoo.com: beamugt@yahoo.com: carlcrabill@yahoo.com: bowwybowwy@gmail.com: booner2k@gmail.com: camillopoland@gmail.com: carlplunkett@hotmail.com: cbenjamin@cisolaw.com: bobs114@yahoo.com.au: bstarling@gmx.com: casstlem@yahoo.com.au: botha.qatar@yahoo.com: cary.northup@gmail.com: bsrsolutions10@gmail.com: boss_yuran@mail.ru: ccollins@semo.net:yd72XkjW cemedia@aol.com: cdudek60@gmail.com: cdb07d@gmail.com: cgsinvest@aol.com: huynhngoccuong@gmail.com: info@simmtec.com: ia_sho@abv.bg: haleelg@gmail.com: gratica@att.net:gKb4EQp1 george@georgeharrison1.com:cgw3AMl8 hasco@personainternet.com: Hassamqazi7@gmail.com: ihssass@hotmail.com: idrzewicz@icloud.com:w0Re72Ht
- Regarding your question
3, the Terry’s request seems justified :
Can you answer, what do you want to do with the lines that have characters after the :, that was your #3 question.
Indeed, you said :
3/ How to choose the lines that have characters after “:”?
But, once your lines are “chosen”, what next ?!
Now, it you want to easily point out these specific lines you could use the Mark feature :
-
Click on the
Search > Mark...menu option -
SEARCH
(?-s):.+ -
Tick the
Bookmark line,Purge for earch searchandWrap aroundoptions -
Of course, select the
Regular expressionsearch mode -
Click on the
Mark Allbutton
=> The lines, containing text after the
:char, are bookmarked with a blue circle, and the text matched is highlighted in red !- Then, some operations are possible on these bookmarked lines. Just select the sub-menu
Search > Bookmark
For instance, using the
Copy Bookmark Linesoption, then a paste operation, here is the14-lines list, from the modified text, without duplicate lines :abradbery@gmail.com:q74Xpc0O a_cameronsse@hotmail.com:jof6IutH a.tworowski@o2.pl:sXOa61Dq aipunts@yahoo.co.uk:pul8OBa4 ageorgiev86@yandex.ru:dIYk0ONb andrewdonnellyjr@aol.com:qu48OcaN barnettos@yahoo.com:e38Ldp5C blansford@lrshouston.com:fKBm16Pd boothmark71@hotmail.com:bFVi84Kx ccollins@semo.net:yd72XkjW cgsinvest@aol.com: gratica@att.net:gKb4EQp1 george@georgeharrison1.com:cgw3AMl8 idrzewicz@icloud.com:w0Re72HtBest Regards,
guy038
P.S. :
Once we are sure that your goals are achieved, we can give you some explanations on the regular expressions used ;-))
- Regarding your question
-
@guy038 said in Type of duplicate lines:
Regarding your question 2, to delete line with an unique colon char, the Terry’s regex S/R is NOT :
@Sarah-Duong I think I see a problem you are having with the Regexes. Using Google translator is introducing spaces in any characters not determined to be words. Thus I used your original regexes in your first post and translated from English to Italian and this is what i got:

We can see that the original does NOT contain spaces, the translation does. So you need to be careful copying the regexes back to your language. by all means copy and translate so you can read our words to you. BUT, do not try to do the same for the regexes. Copy those and paste directly into NPP!
@guy038 I like your regex to remove duplicates, I had considered that but as I’ve said before I hate forward lookups due to the issue of it possibly failing completely. As a test I copied the examples (600+ lines) and made lots of copies in the same file. I got up to just shy of 200K lines and still the regex worked, I gave up trying to determine the limit at that point. Perhaps I’m being a bit harsh on that function!
Cheers
Terry -
Hello, @sarah-duong, @Terry-r and All,
Terry, I would like to emphasize, in this post, the importance of choosing the right type of quantifier ( greedy, lazy or atomic ) in a regular expression !
-
From the initial text of @sarah-duong, above, which contains
623lines, I duplicated it325times and I added a final line-break, at the very end of this test file. So, I obtained a file of202,475lines, for5,016,375bytes -
Then, applying the regex S/R, with the lazy quantifier
+?:-
SEARCH
(?-s)^(.+\R)(?=(?s).+?^\1) -
REPLACE
Leave EMPTY
-
against this large text, I did get, after clicking on the
Replace Allbutton and202,323replacements ( In fact, suppressions ! ), in3mn 57s,, on my old XP laptop, the very short expected text, of3,711bytes long, containing the152lines, all different !-
Then, applying the regex S/R, where I changed the lazy quantifier
+?, in the look-ahead, with the usual greedy quantifier+:-
SEARCH
(?-s)^(.+\R)(?=(?s).+^\1) -
REPLACE
Leave EMPTY
-
against this same text, even after a
1-hourprocess about, no result occurred, although Notepad++ did not seem to get stuck !?
So, I decided to run, again, this regex S/R, at
10h45about, expecting a correct result, after some hours, when I was back home ! By chance, the process did stop, in the evening and has correctly deleted202,323lines, giving the expecting final file of3,711bytes long and152lines ;-))In order to know the exact time, used to execute these
202,323replacements, by Notepad++, I simply opened the Process-Hackerv2.39.124utility, double-clicked on the Notepad++ process to get its properties and, then, clicked, in the Threads tab, on the one with start address =notepad++0x12ab7b. See, below :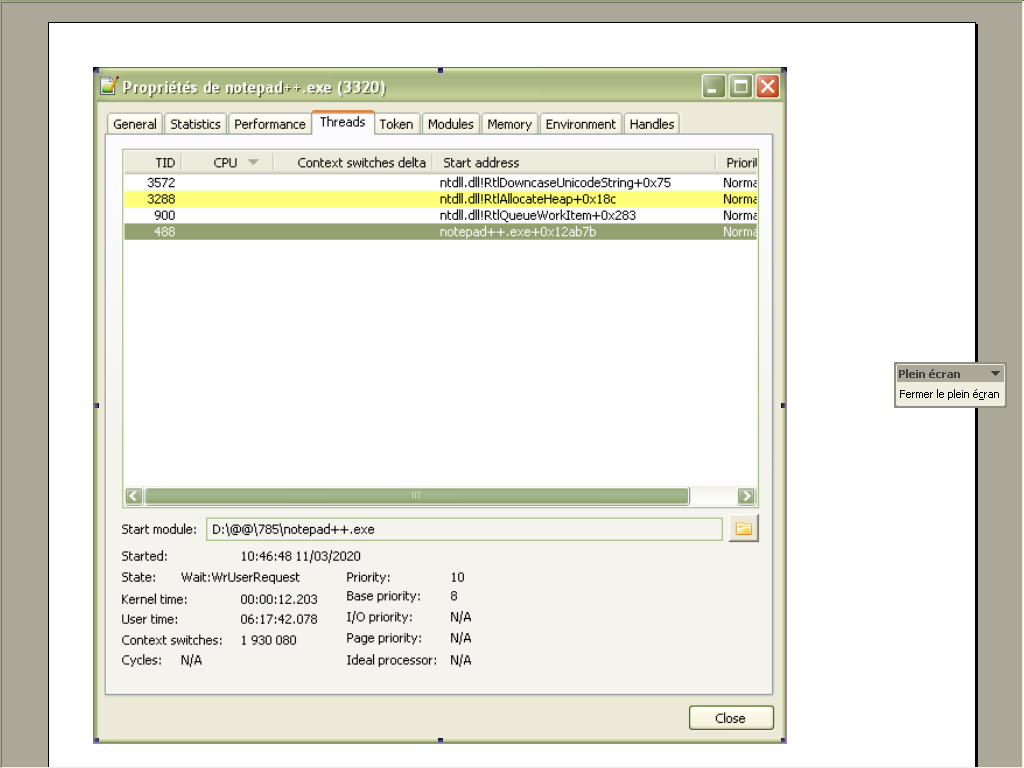
=> The sum of the Kernel and User times, minus
2sabout, due to N++ startup, indicates the time of the S/R :6h 17m 52s!! Compare with the previous time of3m 57s, as shown below ;-))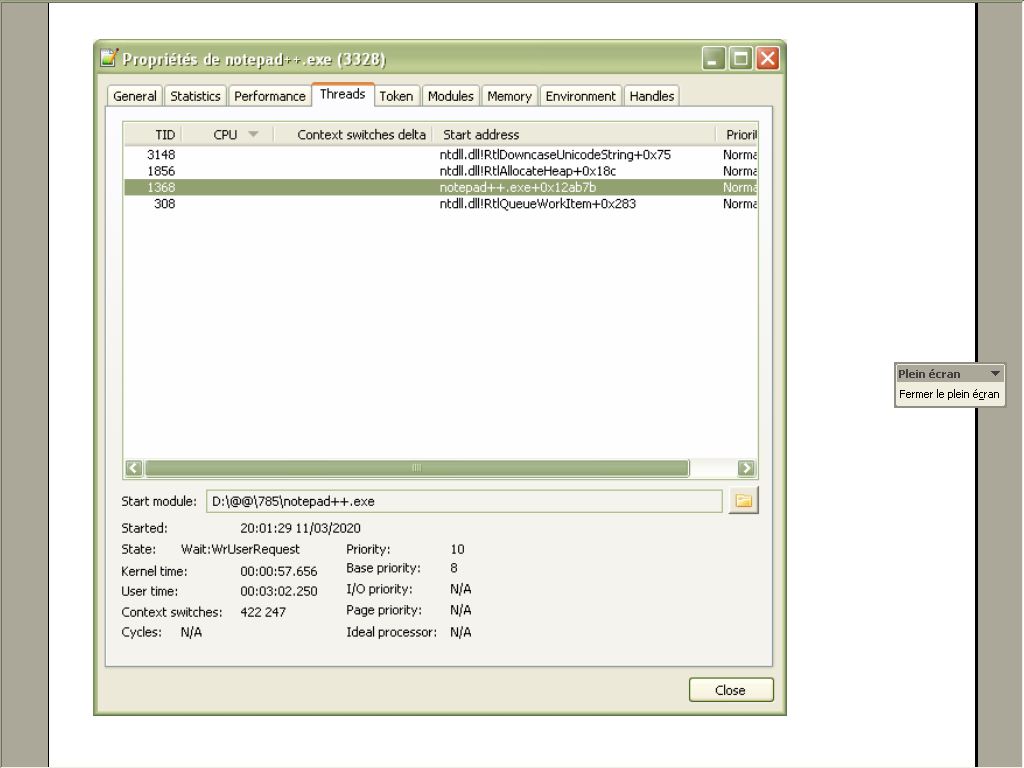
So, guys, could you repeat these two regex S/R, to know, even approximatively, with your configuration and OS, the time to process this
UTF-8test file, containing325times the initial text of @sarah-duong. So, a total of202,475lines and5,016,375bytes ! I quite curious of the results ;-))Best Regards,
guy038
-
-
@guy038 said in Type of duplicate lines:
So, guys, could you repeat these two regex S/R
The PC config I tested on is Windows 10 64bit version 1607 (2016 LTSB) with a Intel i5-8600 and 8GB RAM.
I used NPP 7.8.5 64bit.
As requested I ran both your “lazy” and the “greedy” regexes. I had the exact same test file as you (same lines and byte size). The lazy S/R produced a time of 1m 23s. The greedy S/R produced the same result with a time of 1hr 54m (accurate to a minute only).
Given your “old XP” system produced the 237s time for lazy and mine 83s, that’s a ratio of 0.35. If I do the same with the greedy S/R, given your time of 6h 17m 52s mine should be around 2hr 12m. My actual time of 1hr 54m is not too dissimiliar from that. So perhaps we can consider the speed of the regexes is “mostly” independent of OS version or even possibly CPU type, possibly little efficiencies in newer OS or CPU builds.
I suppose the testing phase in the lookaheads is what takes the time. For the greedy regex, read all characters until end of file, test then drop 1 character, repeat until a solution found. Whereas the lazy regex just grabs 1 character then tests, continue until a solution found.
As this test file has “at least” 325 copies of each and every “original” line the test is possibly not a very accurate one. Indeed the lookahead is “guaranteed” of finding a match no more than 623 lines ahead. In this situation the lookahead is never going to “fail” as we have seen in bigger files with a sparse number of duplicates.
Terry
-
@Terry-R said in Type of duplicate lines:
So perhaps we can consider the speed of the regexes is “mostly” independent of OS version or even possibly CPU type
I should perhaps elaborate on this statement. I realise that the mere fact that my test results for only about 1/3rd that of @guy038 means there are efficiencies in OS and CPU, but I contend that they are mostly to do with GHz speed of the CPU, rather than microcode efficiencies.
On “old XP” system would likely have a dual core (maybe a quad core) CPU with speed in the low GHz range. The i5-8600 has 6 cores with a speed of 3.1GHz.
Could we suggest that the results have more to do with the number of cores and GHz speed, than efficiencies in microcode or the actual CPU design?
Or is the question irrelevant as the answer to everything is “more speed/horsepower”!
Terry
-
@Terry-R said in Type of duplicate lines:
…results have more to do with the number of cores…
My 2 cents on this (and it could be worth much less) is that “throwing more hardware cores” at a problem does nothing for it unless software is written to utilize that hardware.
Do we know that the regex engine used can “divide and conquer” this type of problem, by assigning pieces to multiple cores to work on, and then stitching together the results?
…GHz speed…
Well, yea, raw speed is going to have an impact, for sure.
everything is “more speed/horsepower”
Yes to the former, perhaps to the latter. :-)
-
I want an example for you to understand:
a_cameronsse@hotmail.com:jof6IutH aipunts@yahoo.co.uk:pul8OBa4 : : abc:bcs:32da : a: :a orowski@o2.pl:sXOa6 : onsse@hotmail.com:jof6 : ,: a.tworowski@o2.pl:sXOa61DqNow I want to get the results:
a_cameronsse@hotmail.com: jof6IutH aipunts@yahoo.co.uk: pul8OBa4 abc: bcs: 32da a: :a orowski@o2.pl:sXOa6 onsse@hotmail.com:jof6 ,: a.tworowski@o2.pl:sXOa61DqWhat do I have to do to get that result? I cannot use expressions instead:
Find = : Replace with =That is the content of my question 3. Currently I have the answer: That is to use the expression:
Find = ^ :
Replace with = leave blank
I have searched every corner of the forum to find this simple answer. Also because the language barrier makes it difficult for me
I really want to convey my ideas to you. Unfortunately, Google translates incorrectly. Causing misunderstandings, or sometimes causing conflicts. Hope you understand me. Sincere thanks all for your interest in my topic -
Find = ^\: Replace with : Leave blankI couldn’t type the punctuation so the sentence I wrote was missing.
-
Hi @Sarah-Duong, All:
If you only need to delete lines with just a colon (“:”), a simple regex like
^:\Rin the find box will do it, and of course leave the replace box empty. -
@astrosofista Yes, that is exactly what I need. It seems that there are some symbols I cannot write . It replaces the color or does not display when accompanied by another symbol.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login