How to replace text at a special place in special rows?
-
from the given example I assume the following will do what you want to achieve.
find what:
(?<=projectID:1234}).*(?<=pf2).*?\K11(?=.*pf3)
replace with:22And you must press replace all until npp reports that no more matches are found.
-
@ErwinSchmidt17 said in How to replace text at a special place in special rows?:
So how can this been done
Building on @Ekopalypse solution I’d extend the regex slightly to change both occurances of the 11 at the same time if the conditions are met. Thus my Replace function would be
Find What:(?-s)^((.+)?projectID:1234(.+)?pf2:\{[^}]+?)11([^}]+?)11
Replace With:\122\422From your example it would appear the 11 will ALWAYS occur twice in the “pf2” section (between { and }) if it does exist at all. So my regex prevents running into the next section “pf3” with the use of
[^}]. This means take any characters as long as they are NOT the}. So you will only need to press the “Replace All” button once to have all the occurances replaced.If unsure of my regex you can also use it to bookmark the lines containing the conditions. Then you could step through the lines to confirm. Alternatively you could use the “Replace” button to change 1 line at a time. Use the "Find button at the start, then the replace button from there on and you will see each line selected in turn.
Another method of achieving the same result, but taking more steps to do so are:
- add a line number (with leading zeroes) at the start of each line (Edit, Column editor)
- Bookmark the lines containing the first condition.
- Cut these lines out and insert into another empty file.
- Continue with editing these lines based on the second condition.
- Copy these lines back to the original file and sort numerically, thus the line number at start puts them back into the correct sequence.
- Remove the line numbers at the start of a line.
- Finished. You see, by breaking down the problem into several smaller steps you can achieve the desired result.
Terry
-
I recently found out that there is a difference in handling when using \1 vs. $1.
In this example \122 the 22 to would be added to the captured text from \1 but $122 wouldn’t work.
I assume it treats this as the 122nd capturing group.
Any idea why this is so? -
@Ekopalypse said in How to replace text at a special place in special rows?:
$122 wouldn’t work
From the little I have read I would think the
\means take “as few numbers following as possible”, whereas the $ might be "more greedy, sort of like the*and+quantifiers within regex. I think it did see that we can also use(and)to force the system to recognise what we actually want.This might be another case of becoming a bit more particular such as the
(?-s)which I admit is still something I HAVE to think about, otherwise I forget. Especially as I know my own environment and rarely use it “at home”.Perhaps @guy038 can supply the “answer”?
Terry
-
@Terry-R , @Ekopalypse , and all interested parties:
From my understanding (as reflected in the Searching: capture groups and backreferences and substitutions docs), the
\ℕnotation only accepts single-digit. In the search string, you can use one of the more verbose backreferences (\gℕ,\g{ℕ},\g<ℕ>,\g'ℕ',\kℕ,\k{ℕ},\k<ℕ>or\k'ℕ').The Boost 1.70 docs confirm: back references says that in the
\ℕform,ℕmust be in the range 1-9; the\g-variants (especially with\g{ℕ}allow for higherℕvalues (the\k-variants are supposed to be for named groups, but they also work for numbered groups at last experimentation). The Boost replacement: placeholder sequences only mentions$ℕand${ℕ}, and do not mention\ℕ-notation at all in the substitution/replacement syntax.My rule of thumb is to exclusively use
$ℕor${ℕ}in replacements, and I use the${ℕ}more often, because it is 100% unambiguous for reading (even though it is harder to type on my keyboard). -
I’m fairly certain it works like this:
\122--> group 1 and then a literal22$122--> group 12 and then a literal2${122}--> group 122Obviously, the group numbers need to exist for it to work.
The good habit to get into is to always use the curly brace syntax, so, for example from the current discussion:
${1}22 -
@Alan-Kilborn said in How to replace text at a special place in special rows?:
I’m fairly certain it works like this:
I don’t think so.
Having the text0123456789ABCDEFand doing
find what:(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)
replace with:$122
doesn’t result inB2
but
replace with:$12 2
results inB 2 -
what we could do in addition is
replace with:($12)2 -
I can’t seem to get the \g notation to work either.
replace with:\g{12}2
results ing{12}2 -
@Ekopalypse said in How to replace text at a special place in special rows?:
what we could do in addition is
replace with:($12)2Equivalently: replace with:
${12}2I can’t seem to get the \g notation to work either.
replace with:\g{12}2In Boost,
\g-notation is only listed in the SEARCH section, not in the REPLACE section (fixed typo). -
@Ekopalypse said in How to replace text at a special place in special rows?:
\g notation
To confirm: I can successfully search
0123456789ABCDEFBusing the regex(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)(.)\g12, and it matches (because the 17th character matches the 12th backref) -
Haha, well, that’s why I said “fairly” certain.
Actually, I cheated: Long ago I read about RegexBuddy here on the Community (at least I think it was here), and purchased a license. It has proved invaluable.
Here’s what it told me for this case:
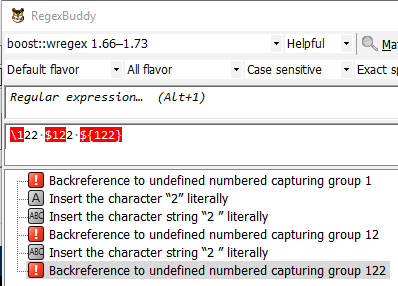
I should have cited RB a few minutes ago when I posted, but I wanted to see if there was agreement/disagreement first.
Very rarely have I found any discrepancies between RB and N++, but this may be one of those cases.
It is interesting that RB doesn’t say “Insert the character string 22 literally” in the second and third lines of its output, but breaks it into 2 parts…hmmm…
-
maybe that is implementation detail (!?)
-
Thank you for all your answers.
-
Hello, @ErwinSchmidt17, @terry-r, @ekopalypse, @peterjones, @alan-kilborn and All,
Sorry, to be late as I’m on a family vacation right now, for the better part of August ;-))
Quickly, about solutions to @ErwinSchmidt17’s problem, I would say :
SEARCH
(?-s)(^.+projectID:1234.+pf2|\G).*?\K11(?=.*pf3)REPLACE
22Thus, the test data, below, containing
4names 11.png, in thepf2section :{name:11.png,filename:c:\img\11\11.png,projectID:1234},pf1:{spname:11.png,spfilename:11.png},pf2:{spname:11.png,spfilename:11.png,bla_blah:11.png,test:11.png},pf3:{spname:11.png,spfilename:11.png},pf4:{...}would be changed as :
{name:11.png,filename:c:\img\11\11.png,projectID:1234},pf1:{spname:11.png,spfilename:11.png},pf2:{spname:22.png,spfilename:22.png,bla_blah:22.png,test:22.png},pf3:{spname:11.png,spfilename:11.png},pf4:{...}
Now, about the different syntaxes, related to groups, back-references and subroutine calls, I did some tests and here are my conclusions, not definitive, of course :
In search regexes, the possible syntaxes, with
Boostregex library, are :-
Unnamed
groupis defined with surrounding parentheses :(.....) -
Named
groupis defined with the one of the syntaxes :-
(?<Name>.....) -
(?'Name'.....)
-
-
Absolute
back-reference, to an unnamed groupN, is defined with one of the syntaxes :-
\N( with1 <=N<= 9) -
\gN\g{N}\g<N>\g'N'( with1 <=N<= Max) -
\kN\k{N}\k<N>\k'N'( with1 <=N<= Max)
-
-
Relative
back-reference, to an unnamed groupX, is defined with one of the syntaxes :-
\g-X\g{-X}\g<-X>\g'-X'( with1 <X<= Max) -
\k-X\k{-X}\k<-X>\k'-X'( with1 <X<= Max)
-
-
Absolute
subroutine call, to an unnamed groupN, is defined with the syntax :(?N)( with0 <=N< Max)
-
Relative
subroutine call, to an unnamed group of relative numberX, is defined with one of the syntaxes :-
(?-X)( with1 <X<= Max) -
(?+X)( with1 <X<= Max)
-
-
Absolute
back-reference, to a named groupName, is defined with one of the syntaxes :-
\g{Name}\g<Name>\g'Name' -
\k{Name}\k<Name>\k'Name'
-
-
Absolute
subroutine call, to a named groupName, is defined with one of the syntaxes :-
(?&Nom) -
(?P>Nom)
-
Remarks :
-
For all the relative syntaxes above, the
Maxvalue is the greatest group of the overall regex -
For all the absolute syntaxes, I suppose that the
Maxvalue is2,147,483,647, as it’s the same value in replacement, too ! -
The names of named groups are word characters, non beginning with a digit
-
The
(?0)is a subroutine call to the overall regex and is, implicitly, a recursive subroutine call !
Summary example :
To find a four-letters word palindrome, you can use, either, one of these
23syntaxes :\b(\w)(\w)\2\1\b\b(\w)(\w)\g2\g1\b
\b(\w)(\w)\g{2}\g{1}\b
\b(\w)(\w)\g<2>\g<1>\b
\b(\w)(\w)\g'2'\g'1'\b\b(\w)(\w)\k2\k1\b
\b(\w)(\w)\k{2}\k{1}\b
\b(\w)(\w)\k<2>\k<1>\b
\b(\w)(\w)\k'2'\k'1'\b\b(\w)(\w)\g-1\g-2\b
\b(\w)(\w)\g{-1}\g{-2}\b
\b(\w)(\w)\g<-1>\g<-2>\b
\b(\w)(\w)\g'-1'\g'-2'\b\b(\w)(\w)\k-1\k-2\b
\b(\w)(\w)\k{-1}\k{-2}\b
\b(\w)(\w)\k<-1>\k<-2>\b
\b(\w)(\w)\k'-1'\k'-2'\b\b(?<First>\w)(?'Second'\w)\g{Second}\g{First}\b
\b(?<First>\w)(?'Second'\w)\g<Second>\g<First>\b
\b(?<First>\w)(?'Second'\w)\g'Second'\g'First'\b\b(?'First'\w)(?<Second>\w)\k{Second}\k{First}\b
\b(?'First'\w)(?<Second>\w)\k<Second>\k<First>\b
\b(?'First'\w)(?<Second>\w)\k'Second'\k'First'\bTest them against this text :
adda – a type of lizard Adda – a river in Italy; a river in Wales Anna – a girl’s name Beeb – an informal name for the BBC boob – a blunder; a breast deed – various common meanings goog – an egg (Australian slang) immi – a Swiss unit of volume keek – to peep kook – a crazy person naan – a type of Indian bread noon – midday Otto - a proper name peep – various common meanings poop – a raised deck at the stern of a ship; various other meanings toot – the sound made by a horn or whistleNow, as a subroutine call is, basically, a reference to the regex itself, included in a group and NOT the last value of this group like in back-references, the
5following syntaxes are strictly equivalent to the simple regex\b\w{4}\band looks for a four-letters word :\b(\w)(\w)(?2)(?1)\b
\b(\w)(\w)(?-1)(?-2)\b
\b(?+2)(?+1)(\w)(\w)\b\b(?<First>\w)(?'Second'\w)(?&Second)(?&First)\b
\b(?'First'\w)(?<Second>\w)(?P>Second)(?P>First)\bTest them, again, on the same sample text, above !
Important :
-
All the syntaxes, above, are valid in
searchpart ONLY ! -
Because of the multiple equivalent syntaxes, for groups, back-references and subroutine calls, it is useful to define, for
searchregexes, a single, minimal syntax, covering the majority of cases :
Hence, the table, below, with my preferences :
•============================•=============================•===================•====================• | GROUP | REFERENCE | ABSOLUTE number | RELATIVE number | •============================•=============================•===================•====================• | | BACK-REFERENCE | \N or \g{N} | \g{-X} | | (.....) UNNAMED | | | | | | SUBROUTINE CALL | (?N) | (?-X) or (?-X) | •----------------------------•-----------------------------•-------------------•--------------------• | | BACK-REFERENCE | \g<Name> | N/A | | (?<Name>.....) NAMED | | | | | | SUBROUTINE CALL | (?&Name) | N/A | •============================•=============================•===================•====================•
In replacement regexes, , with
Boostregex library, you can use the following syntaxes :-
Absolute
reference, to an unnamed groupN, is defined with either :-
\N( with1 <=N<= 9) -
$N( with0 <=N<= 2,147,483,647) -
${N}( with0 <=N<= 2,147,483,647)
-
-
Absolute
reference, to an named groupName, is defined with the syntax :$+{Name}
Remarks :
-
The
$0or$&syntaxes refer to the overall regex, itself -
If number
Nis superior to the number of back-references, in the search regex, these syntaxes return an empty string -
If a named reference
$+{name}does not exist in search regex, it also returns an empty string -
If, in the replacement regex, a digit follows a
$Nsyntax, it’s preferable to use the${N}form ! -
The
$00...00Nand${00...00N}syntaxes are equivalent to, respectively, the$Nand${N}syntaxes -
So, the single minimal syntaxes, in replacement, seems to be :
•============================•==================•===================• | GROUP | REFERENCE | ABSOLUTE number | •============================•==================•===================• | (.....) UNNAMED | BACK-REFERENCE | ${N} | •----------------------------•------------------•-------------------• | (?<Name>.....) NAMED | BACK-REFERENCE | $+{Name} | •============================•==================•===================•Best Regards,
guy038
-
-
Hi, All,
Out of curiosity, do you know how I could determine that the maximum number of group is
2,147,483,647?Well, I began the test using this simple regex S/R :
SEARCH
(?-s).REPLACE
--${300}--When replacing a single character, it returns the string
----. So, the S/R seemed valid and, as the group300did not exist, it just wrote the empty string as replacement of this group.Then, I, successively, changed the replacement zone with :
-
--${3000}--=>---- -
--${30000}--=>---- -
--${3000000000}--=>--$3000000000}--
As I suspected that the limit should have a relation to powers of
2, I searched for the largest power of2, below3,000,000, which is2^31=2,147,483,647!Indeed :
SEARCH
(?-s).REPLACE
--${2147483647}--=> The
----outputand :
SEARCH
(?-s).REPLACE
--${2147483648}--=> The
--${2147483648}--outputOf course, I do understand that this limit is quite theoretical ! Just imagine a regex containing
2,147,483,647different groups… BrrrrrBest Regards,
guy038
-
-
@guy038 - sounds like a 32bit integer limitation.
-
sounds like a 32bit integer limitation.
Or an implementation detail. ;-)
BTW, trying this in RegexBuddy, it reports “group 2147483647” but if you go one higher it reports “group -2147483648”. -
:-D
-
Hello,@ErwinSchmidt17
Follow this step,To How to replace text at a special place in special rows?
Step 1: Press Ctrl+H to bring up the Find/Replace Dialog.
Step 2: Choose the Regular expression option near the bottom of the dialog.To add a word, such as test, at the beginning of each line:
Step 1: Type ^ in the Find what textbox
Step 2: Type test in the Replace with textbox
Step 3: Place cursor in the first line of the file to ensure all lines are affected
Step 4: Click Replace All buttonTo add a word, such as test, at the end of each line:
Step 1: Type $ in the Find what textbox
Step 2: Type test in the Replace with textbox
Step 3: Place cursor in the first line of the file to ensure all lines are affected
Step 4: Click Replace All buttonI hope this information will be useful.
Thank you.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login