Line wrap in the current version
-
Maybe this is a bit much to ask, but maybe I’ll lay it down as a challenge to interested parties.
Often I take notes and tab sections over once or twice.
Thus text like this may result in my notes:
After a weekend of emotional honesty at an Esalen-style retreat, Los Angeles sophisticates Bob and Carol Sanders (Robert Culp and Natalie Wood) return home determined to embrace complete openness. They share their enthusiasm and excitement over their new-found philosophy with their more conservative friends Ted and Alice Henderson (Elliott Gould and Dyan Cannon), who remain doubtful. Soon after, filmmaker Bob has an affair with a young production assistant on a film shoot in San Francisco. When he gets home he admits hisliaison to Carol, describing the event as a purely physical act, not an emotional one.I’d find it nice to be able to reformat that text to wrap at a certain column, e.g. 80, and yet keep the leading indentation. Something like this:
After a weekend of emotional honesty at an Esalen-style retreat, Los Angeles sophisticates Bob and Carol Sanders (Robert Culp and Natalie Wood) return home determined to embrace complete openness. They share their enthusiasm and excitement over their new-found philosophy with their more conservative friends Ted and Alice Henderson (Elliott Gould and Dyan Cannon), who remain doubtful. Soon after, filmmaker Bob has an affair with a young production assistant on a film shoot in San Francisco. When he gets home he admits hisliaison to Carol, describing the event as a purely physical act, not an emotional one.Not sure I manually got the reformatted lines absolutely correct, but…you get the idea.
Ok, well, thinking about this a bit more, I guess it really is a bit too much to ask for. :-)
-
@Alan-Kilborn said in Line wrap in the current version:
Maybe this is a bit much to ask, but maybe I’ll lay it down as a challenge to interested parties.
Ok, well, thinking about this a bit more, I guess it really is a bit too much to ask for. :-)
Yea, I don’t have a solution for that one. My NppExec script starts by joining all the highlighted lines into a single line and then does the regex or my super complicated NppExec method do wrap by inserting the carriage returns (based on the file EOL type).
My script follows if it will at all help or give you some ideas to start with. I call it
wrapand so just need to type\wrap helpfrom the NppExec console to get a hint:::wrap NPP_CONSOLE keep // Defaults SET LOCAL WRAP = 80 SET LOCAL REGEX = 0 // command line arguments IF "$(ARGC)"<="1" THEN // get the edge column marker if present SCI_SENDMSG SCI_GETEDGECOLUMN IF $(MSG_RESULT)>0 THEN SET LOCAL WRAP = $(MSG_RESULT) ENDIF ELSE IF "$(ARGC)">="2" THEN IF "$(ARGV[1])"~="help" THEN GOTO USAGE ELSE IF "$(ARGV[1])"~="--regex" THEN SET LOCAL REGEX = 1 IF "$(ARGC)">="3" THEN SET LOCAL WRAP = $(ARGV[2]) ENDIF ELSE SET LOCAL WRAP = $(ARGV[1]) ENDIF ELSE GOTO USAGE ENDIF SET LOCAL WRAPL ~ $(WRAP) - 1 // setup the carriage return / line feed based on current buffer line ending type SET LOCAL CRLF ~ strfromhex 0d 00 0a 00 SET LOCAL OFFSET = 2 SCI_SENDMSG SCI_GETEOLMODE IF $(MSG_RESULT)==1 THEN SET LOCAL CRLF ~ strfromhex 0d 00 SET LOCAL OFFSET = 1 ELSE IF $(MSG_RESULT)==2 THEN SET LOCAL CRLF ~ strfromhex 0a 00 SET LOCAL OFFSET = 1 ENDIF // get start and end of selection and bail out if selection is less than the desired wrap SCI_SENDMSG SCI_GETSELECTIONSTART SET LOCAL START = $(MSG_RESULT) SCI_SENDMSG SCI_GETSELECTIONEND SET LOCAL END = $(MSG_RESULT) SET LOCAL TEST ~ $(START) + $(WRAP) IF $(TEST)>=$(END) GOTO END // join all highlighted lines to a single big long line to start the parsing SCI_SENDMSG SCI_SETTARGETSTART $(START) SCI_SENDMSG SCI_SETTARGETEND $(END) SCI_SENDMSG SCI_LINESJOIN // Reset END after joining lines SCI_SENDMSG SCI_GETSELECTIONEND SET LOCAL END = $(MSG_RESULT) // super elegant way to do it all with a regex IF "$(REGEX)"=="1" THEN // https://community.notepad-plus-plus.org/topic/20008/line-wrap-in-the-current-version/6 ECHO REGEX = $(WRAP) SCI_REPLACE NPE_SF_INSELECTION|NPE_SF_REPLACEALL|NPE_SF_REGEXP "^(?=.{$(WRAP),})(.{1,$(WRAPL)})\s" "$1$(CRLF)" GOTO DONE ENDIF // super kludge-y way to do it all with NppExec scripting SET LOCAL LOOP = 1 SET LOCAL BACK = 0 :LOOP SET LOCAL POS ~ $(START) + $(WRAP) * $(LOOP) + ( $(OFFSET) * ( $(LOOP) - 1 ) ) - $(BACK) - 1 // ECHO START: $(POS) ( END = $(END) BACK = $(BACK) ) IF $(POS)>=$(END) THEN GOTO DONE ENDIF :INNERLOOP SCI_SENDMSG SCI_GETCHARAT $(POS) IF "$(MSG_RESULT)"!="32" THEN SET LOCAL POS ~ $(POS) - 1 SET LOCAL BACK ~ $(BACK) + 1 // ECHO Backtracking: $(POS) GOTO INNERLOOP ENDIF SET LOCAL POS ~ $(POS) + 1 SCI_SENDMSG SCI_INSERTTEXT $(POS) "$(CRLF)" SET LOCAL END ~ $(END) + $(OFFSET) // ECHO Inserting: $(POS) ( new END = $(END) ) SET LOCAL LOOP ~ $(LOOP) + 1 GOTO LOOP // either method finishes here and sets cursor to start of new wrapped text :DONE SCI_SENDMSG SCI_GOTOPOS $(START) // ECHO END $(END) GOTO END :USAGE ECHO Usage: ECHO Word-wrap by carriage returns selected text into one paragraph. ECHO \$(ARGV[0]) [W] = wrap selected text to EDGE marker, 80 (default) or W ECHO \$(ARGV[0]) [--regex [W]] = Use RegEx implementation with SCI_REPLACE :ENDCheers.
-
Thanks.
It could be a job for a PythonScript, but I’ve never gotten around to finishing that one. Other priorities, I guess. :-) -
@Alan-Kilborn said in Line wrap in the current version:
and yet keep the leading indentation.
I can’t (currently) see a single regex doing this in one pass. The issue is not so much grabbing the leading tabs or spaces on the first line, but when they are “copied” to the next line, now the current position of the regex engine is past that point. Yet those spaces or tabs must count towards the line length.
To make matters worse a tab is defined as a set number of positions (according to NPP preferences) yet isn’t it just 1 character as per the regex engine? So to attempt to say 80 characters wide now becomes an issue, 1 or more might be a “variable” width tab.
More pondering required!
Terry
-
@Terry-R said in Line wrap in the current version:
To make matters worse a tab is defined as a set number of positions (according to NPP preferences) yet isn’t it just 1 character as per the regex engine?
Sane people have the N++ option to replace any tab hits with a certain amount of spaces, not an actual tab character. I’m not so hung up on the count of those spaces, but I use (and showed in the example above), 4.
SIDE NOTE: What happens if you attempt to put tab characters in a code block on this site?
Let’s try:
nothing at start of this line one tab at start two tabs at start nothing at start of this lineEdit: It keeps the tab characters intact!
-
@Alan-Kilborn said in Line wrap in the current version:
It keeps the tab characters intact!
And for me (since I don’t convert to spaces) it will dynamically apply the number that is currently showing (but not ticked). I copied your code, it kept the tabs. When I changed the space from 4 to 3 it moved the blocks but kept the tab character because I can set the number BUT not tick (select) it to convert to spaces…
Terry
-
@Alan-Kilborn said in Line wrap in the current version:
Maybe this is a bit much to ask, but maybe I’ll lay it down as a challenge to interested parties.
Challenge accepted. It’s a bit rough around the edges but seems workable. As I suggested, I did NOT manage to do it in 1 regex, rather it will be 2 regexes followed by an “empty line” elimination step.
My first step is to add the “indentation” to a following line. This regex checks that if that “following” line is currently “empty” (only spaces/tabs) then it will NOT create any more. This 1st regex runs ONCE! Then the second step cuts each line at the prescribed column and “appends” it to the following “empty” line and then adds another further “empty” line. This regex needs running until no more changes occur. The 3rd step is to remove blank lines through the “Line Operations” function.
As I say it’s a bit rough, but thought it might be interesting for someone to pickup on and see if it can be tweaked further (note I did use
\t, that probably needs changing to ALL characters that might exist forming part of the indentation), or that it might give food for thought in a different direction. Since the 1st regex can be run multiple times without any problems the 2 could possibly be combined into a macro which is run UNTIL no changes occur.-
Find What:
(?-s)^([\t ]++)(?!$)(.+)(\R)(?!\1\3)
Replace With:\1\2\3\1\3this step ONLY needs running once but will not cause any problem if run more than once. -
Find What:
(?-s)^(?=.{80,})(.{1,79})\s(.+\R)([\t ]++$)
Replace With:$1\r\n$3$2$3this step needs running until no more changes occur. -
“Line Operations”, "Remove Empty Lines (containing blank characters).
Now one issue I did see is that (in my case) the tab character is taking up several positions, but to the regex it’s ONLY 1, the actual final line width can be slightly over the 80 characters visually. So a line with 2 tabs could be over by 4 character positions if the tab to space in Preferences, Language is set to 3, but with it NOT ticked to convert.
I think that would be a minor irritation.
Terry
-
-
@Terry-R said in Line wrap in the current version:
Find What:(?-s)^(?=.{80,})(.{1,79})\s(.+\R)([\t ]++$)
Replace With:$1\r\n$3$2$3 this step needs running until no more changes occur.Step 2 fails on “non-indented” lines. That was possibly also the result with my initial testing but I didn’t notice it at that point. I’ve just completed some more testing, this time using spaces as the indentation and for indented lines using either tab or space the solution works. Now to fix the non-indented lines.
I don’t portray the above steps as a finished/polished solution, rather a work in progress.
A revised step 2 Find What:
(?-s)^(?=.{80,})(.{1,79})\s(.+\R)([\t ]++$)?Terry
-
Hello,@I-neuw
Please follow these steps, To Line wrap in the current versionStep 1:- Open your Notepad++ and then click on the File menu in the menu bar and choose the open option to your document.
Step 2:- Click the View in the menu bar and choose the word wrap option into the list.
Step 3:- This will adjust the lines according to your Notepad++ window size.I hope this information will be useful to you.
Thank you. -
Hi, @i-neuw, @michael-vincent and All,
Have a look, too, at my updated post :
https://community.notepad-plus-plus.org/post/58912
Cheers,
guy038
-
Do you have super-powers enough here to ban the “Makwana Prahlad” bot-user?
-
Many users often noticed that your posts have always no relation with the real problem discussed !
So, although you can explain us why you proceed this way, in a reasonable time, I will be obliged to ban your account. Sorry !
BR
guy038
-
@Michael-Vincent said in Line wrap in the current version:
Regarding ruler in Notepad++
Using the ruler part of the ColumnTools plugin, I notice that it is “off”:
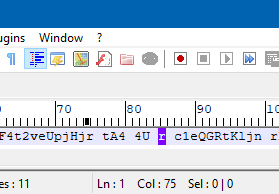
The ruler indicates the correct column number, but I expected it to be better vertially aligned with the caret position.
Does this happen for anyone else?
-
I will be taking an in-depth look at your solution to my “challenge”.
Thanks! -
@Alan-Kilborn said in Line wrap in the current version:
The ruler indicates the correct column number, but I expected it to be better vertially aligned with the caret position.
Does this happen for anyone else?It definitely happens if you have DirectWrite turned on:
Settings => Preferences… => MISC. => Use DirectWrite
It’s a known bug without a known solution :-)
Cheers.
-
@Alan-Kilborn said in Line wrap in the current version:
I will be taking an in-depth look at your solution to my “challenge”.
I had abandoned the previous regex and also the revised one which although supposed to fix a problem with non-indented lines may have actually caused another problem.
I then started (almost) afresh and finished up with a 4 step process that would ONLY work well in a macro. It entailed:
- coding empty (or blank filled) lines so they weren’t removed
- Breaking up at the first 80 char (or just before) and tagging the next (new) line with a continuation code so it could be prefixed with the “indentation”
- Replacing the continuation code with the indentation of the parent line (that it was cut from).
- Removal of the code to denote an empty (or blank filled) line.
And then repeating these 4 steps, hence the need for a macro to make it easy!
However in my research I stumbled across something I’d forgotten (as never used it) and it can be used to advantage. Hence my latest (and possibly the last) version is:
Find What:^(?=(\h++)?)(?=.{81,})(.{1,79})\h(.+)(\R|\z)
Replace With:\2\r\n\1\3\4So the first capture group is actually within the positive lookahead. Then the search starts AGAIN from the first position in the line, checks for a “long” line and AGAIN restarts at the first position, then it finds the last “blank” before the 80 character position and cuts the remainder of the line off and prefixies it with the “indentation” (AKA 1st capture group). Note that a “TAB” character whilst occupying several spaces on the screen will ONLY occupy 1 position within the regex. So it can be possible that a line will exceed (slightly) the 80 character position if tabs are used within the document (at any position).
Unfortunately as when it writes the new “sub” line it has now gone past the start of that line and cannot process that line on this run, hence the need for multiple runs until the occurrences show
0.Now in my research I realized that the
\hused as a space/blank character ALSO includes the NBSP (non breaking space) character. So currently it could break at that point if one existed, but honestly I don’t see that as being the “end of the world” so I’m happy to live with it as is.So; as far as my testing shows; it will leave any current empty or blank filled line (as long as under 81 char). It works on both indented and NON-indented lines. My (limited) testing cannot show up any issues. Give it a whirl.
So have I managed a “single” regex solution? Well possibly although it must run multiple times.
Terry
-
Hi @Terry-R !
So I never got back to you on this. Sorry. :-(
Having more time over the end-of-year “slowdown”, I took a deeper dive into some things on my “to do” list. This was one of them; also on the list are/were finishing scripts for replace-all-in-any-type-of-selection and replace-all-with-incrementing-count. Perhaps other threads will get updates soon as well! But I digress…
So I started testing your regex.
The “having to run it multiple times” seemed like a deal-breaker, at first, but then while I’m in the middle of playing around with it, N++ 7.9.2 is released with a new feature that seems to help:
What I can do is select the text I want to “reformat” and then run your replacement regex op with the In selection option turned on. This, with the indicated change in 7.9.2, keeps the (post-replacement) selection correct for another run(s) of the replacement. N++ 7.9.1 and earlier does not allow this.
So what I’m thinking is that I can make a macro of this, and edit it to duplicate the replacement action an arbitrarily large (e.g. 10 ?) number of times to cover most of my typical reformatting needs.
More testing to come, but it appears promising.
In hindsight, I’m glad I waited this long to give it a try.
Thank you for your efforts. -
@Terry-R said in Line wrap in the current version:
^(?=(\h++)?)
Terry, one more question for you:
What were the conditions for which you found it necessary to use the possessive (++) qualifier here?
I’m confused as to why the greedy (+) qualifier would not have worked as well – although I’ll admit I just thought about it, I didn’t try things with it. -
@Alan-Kilborn said in Line wrap in the current version:
What were the conditions for which you found it necessary to use the possessive (++) qualifier here?
Looking back at it now there wouldn’t have been any reason to do so. Possibly I had brought that forward from a previous version but as it’s within the lookahead, there will never be a reason for the regex engine to give up any of those characters.
It would seem that it’s safe to just leave it as greedy (
+).Cheers
Terry -
Things are going good with this…
One thing I noted is that sometimes one has a need to reformat lines that are actually shorter than the desired amount, instead of longer.
Running your regular expression is obviously designed to handle longer-than-desired lines (which is OK, since that was the original spec).One would think that you could just use Notepad++'s Join Lines feature first, to give your expression something long enough to work on. However, I noticed when doing that, for any indented lines, when the lines are joined, the leading indent spaces on lines subsequent to the first – how many ever there are – are retained. :-(
So I came up with an In Selection Replace All action that will do the joining of lines and reduce any leading indents down to one space:
find:
(\R\x20+)|(\R\z)|(\R)
repl:(?1\x20)(?3\x20)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login