find two letters between quotes in lang tag
-
Hi, @pouemes44 and All,
Not really difficult !
SEARCH / MARK
(?-i)(?<=\x20lang=")\l{2}(?=">)Notes :
-
This regex searches for
2lowercase letters\l{2}but ONLY IF :-
It is preceded with a space char and the string
lang=", with this exact case, due to the look-behind(?<=\x20lang=") -
It is followed with the string
">, due to the look-ahead structure(?=">)
-
Best Regards,
guy038
-
-
@guy038 said in find two letters between quotes in lang tag:
SEARCH / MARK (?-i)(?<=\x20lang=“)\l{2}(?=”>)
It seems overly restrictive to me.
OP mentions nothing about uppercase versus lowercase.
OP mentions “tags” but how are we to know what this really means for them?
Based upon OP’s specification, I would try:(?-i)lang="[[:alpha:]]{2}"Of course, still vague is the type of double-quotes we are talking about.
-
thanks to you
guy38 it seems to work perfectly but i i have lang=“fr” in all my page
how to exclude from the search lang=“fr”
Alan it took tag with 3 letters -
@Pouemes44 said in find two letters between quotes in lang tag:
Alan it took tag with 3 letters
Hmmm. Really not sure how you could get that result, reference:
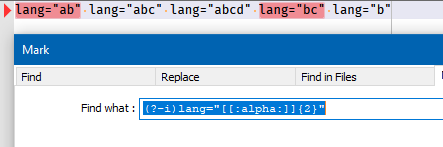
Even though you didn’t have luck with mine, here’s how I’d change mine to exclude matching
fr:(?-i)lang="(?!fr)[[:alpha:]]{2}" -
thanks Alan yes work like this
perhaps firt time i forget the last quote, that why it was not correct
a great thanks -
@Pouemes44 said in find two letters between quotes in lang tag:
how to exclude from the search lang=“fr”
Try this instead:
(?-i)(?<=\x20lang=")(?!fr)\l{2}(?=">)Take care and have fun!
-
Hi, @pouemes44, @alan-kilborn, @astrosofista and All,
Alan, Hum…, interesting ! I assume, since my last post, that @pouemes44 was talking about the HTML
langattribute. So, I dug out a bit on Net !And, from these links :
We can deduce that :
-
Language codes have always
2or3lowercase characters ( ReferISO 639-2from Wikipedia ) -
Country codes have always
2uppercase characters, ( ReferISO 3166-1 alpha-2 codelist, from Wikipedia ) -
A Language code stands by itself OR may be followed with a dash
-and a country code OR a script code ( ReferISO Language CodeTable ) -
Generally, Language tags are lowercase, alphabetic region subtags are uppercase, and script tags begin with an initial capital ( Refer https://www.w3.org/International/articles/language-tags/#rfc )
So from the main list, below ( Refer http://www.lingoes.net/en/translator/langcode.htm ), with
241items :af Afrikaans af-ZA Afrikaans (South Africa) ar Arabic ar-AE Arabic (U.A.E.) ar-BH Arabic (Bahrain) ar-DZ Arabic (Algeria) ar-EG Arabic (Egypt) ar-IQ Arabic (Iraq) ar-JO Arabic (Jordan) ar-KW Arabic (Kuwait) ar-LB Arabic (Lebanon) ar-LY Arabic (Libya) ar-MA Arabic (Morocco) ar-OM Arabic (Oman) ar-QA Arabic (Qatar) ar-SA Arabic (Saudi Arabia) ar-SY Arabic (Syria) ar-TN Arabic (Tunisia) ar-YE Arabic (Yemen) az Azeri (Latin) az-AZ Azeri (Latin) (Azerbaijan) az-AZ Azeri (Cyrillic) (Azerbaijan) be Belarusian be-BY Belarusian (Belarus) bg Bulgarian bg-BG Bulgarian (Bulgaria) bs-BA Bosnian (Bosnia and Herzegovina) ca Catalan ca-ES Catalan (Spain) cs Czech cs-CZ Czech (Czech Republic) cy Welsh cy-GB Welsh (United Kingdom) da Danish da-DK Danish (Denmark) de German de-AT German (Austria) de-CH German (Switzerland) de-DE German (Germany) de-LI German (Liechtenstein) de-LU German (Luxembourg) dv Divehi dv-MV Divehi (Maldives) el Greek el-GR Greek (Greece) en English en-AU English (Australia) en-BZ English (Belize) en-CA English (Canada) en-CB English (Caribbean) en-GB English (United Kingdom) en-IE English (Ireland) en-JM English (Jamaica) en-NZ English (New Zealand) en-PH English (Republic of the Philippines) en-TT English (Trinidad and Tobago) en-US English (United States) en-ZA English (South Africa) en-ZW English (Zimbabwe) eo Esperanto es Spanish es-AR Spanish (Argentina) es-BO Spanish (Bolivia) es-CL Spanish (Chile) es-CO Spanish (Colombia) es-CR Spanish (Costa Rica) es-DO Spanish (Dominican Republic) es-EC Spanish (Ecuador) es-ES Spanish (Castilian) es-ES Spanish (Spain) es-GT Spanish (Guatemala) es-HN Spanish (Honduras) es-MX Spanish (Mexico) es-NI Spanish (Nicaragua) es-PA Spanish (Panama) es-PE Spanish (Peru) es-PR Spanish (Puerto Rico) es-PY Spanish (Paraguay) es-SV Spanish (El Salvador) es-UY Spanish (Uruguay) es-VE Spanish (Venezuela) et Estonian et-EE Estonian (Estonia) eu Basque eu-ES Basque (Spain) fa Farsi fa-IR Farsi (Iran) fi Finnish fi-FI Finnish (Finland) fo Faroese fo-FO Faroese (Faroe Islands) fr French fr-BE French (Belgium) fr-CA French (Canada) fr-CH French (Switzerland) fr-FR French (France) fr-LU French (Luxembourg) fr-MC French (Principality of Monaco) gl Galician gl-ES Galician (Spain) gu Gujarati gu-IN Gujarati (India) he Hebrew he-IL Hebrew (Israel) hi Hindi hi-IN Hindi (India) hr Croatian hr-BA Croatian (Bosnia and Herzegovina) hr-HR Croatian (Croatia) hu Hungarian hu-HU Hungarian (Hungary) hy Armenian hy-AM Armenian (Armenia) id Indonesian id-ID Indonesian (Indonesia) is Icelandic is-IS Icelandic (Iceland) it Italian it-CH Italian (Switzerland) it-IT Italian (Italy) ja Japanese ja-JP Japanese (Japan) ka Georgian ka-GE Georgian (Georgia) kk Kazakh kk-KZ Kazakh (Kazakhstan) kn Kannada kn-IN Kannada (India) ko Korean ko-KR Korean (Korea) kok Konkani kok-IN Konkani (India) ky Kyrgyz ky-KG Kyrgyz (Kyrgyzstan) lt Lithuanian lt-LT Lithuanian (Lithuania) lv Latvian lv-LV Latvian (Latvia) mi Maori mi-NZ Maori (New Zealand) mk FYRO Macedonian mk-MK FYRO Macedonian (Former Yugoslav Republic of Macedonia) mn Mongolian mn-MN Mongolian (Mongolia) mr Marathi mr-IN Marathi (India) ms Malay ms-BN Malay (Brunei Darussalam) ms-MY Malay (Malaysia) mt Maltese mt-MT Maltese (Malta) nb Norwegian (Bokm?l) nb-NO Norwegian (Bokm?l) (Norway) nl Dutch nl-BE Dutch (Belgium) nl-NL Dutch (Netherlands) nn-NO Norwegian (Nynorsk) (Norway) ns Northern Sotho ns-ZA Northern Sotho (South Africa) pa Punjabi pa-IN Punjabi (India) pl Polish pl-PL Polish (Poland) ps Pashto ps-AR Pashto (Afghanistan) pt Portuguese pt-BR Portuguese (Brazil) pt-PT Portuguese (Portugal) qu Quechua qu-BO Quechua (Bolivia) qu-EC Quechua (Ecuador) qu-PE Quechua (Peru) ro Romanian ro-RO Romanian (Romania) ru Russian ru-RU Russian (Russia) sa Sanskrit sa-IN Sanskrit (India) se Sami (Northern) se-FI Sami (Northern) (Finland) se-FI Sami (Skolt) (Finland) se-FI Sami (Inari) (Finland) se-NO Sami (Northern) (Norway) se-NO Sami (Lule) (Norway) se-NO Sami (Southern) (Norway) se-SE Sami (Northern) (Sweden) se-SE Sami (Lule) (Sweden) se-SE Sami (Southern) (Sweden) sk Slovak sk-SK Slovak (Slovakia) sl Slovenian sl-SI Slovenian (Slovenia) sq Albanian sq-AL Albanian (Albania) sr-BA Serbian (Latin) (Bosnia and Herzegovina) sr-BA Serbian (Cyrillic) (Bosnia and Herzegovina) sr-SP Serbian (Latin) (Serbia and Montenegro) sr-SP Serbian (Cyrillic) (Serbia and Montenegro) sv Swedish sv-FI Swedish (Finland) sv-SE Swedish (Sweden) sw Swahili sw-KE Swahili (Kenya) syr Syriac syr-SY Syriac (Syria) ta Tamil ta-IN Tamil (India) te Telugu te-IN Telugu (India) th Thai th-TH Thai (Thailand) tl Tagalog tl-PH Tagalog (Philippines) tn Tswana tn-ZA Tswana (South Africa) tr Turkish tr-TR Turkish (Turkey) tt Tatar tt-RU Tatar (Russia) ts Tsonga uk Ukrainian uk-UA Ukrainian (Ukraine) ur Urdu ur-PK Urdu (Islamic Republic of Pakistan) uz Uzbek (Latin) uz-UZ Uzbek (Latin) (Uzbekistan) uz-UZ Uzbek (Cyrillic) (Uzbekistan) vi Vietnamese vi-VN Vietnamese (Viet Nam) xh Xhosa xh-ZA Xhosa (South Africa) zh Chinese zh-CN Chinese (State) zh-Hans Chinese (Simplified Han Script) zh-Hant Chinese (Traditional Han Script) zh-HK Chinese (Hong Kong) zh-MO Chinese (Macau) zh-SG Chinese (Singapore) zh-TW Chinese (Taiwan) zu Zulu zu-ZA Zulu (South Africa)This new regex version matches all the possible language codes :
SEARCH / MARK
(?-i)(?<=\x20lang=")(?:zh\-Han(s|t)|\l{2,3}(-\u{2})?)(?=">?)Now, in order to omit the two
"fr"and"fr-FR"languages, only, prefer the regex, below :SEARCH / MARK
(?-i)(?<=\x20lang=")(?:zh\-Han(s|t)|(?!fr(-FR)?">?)\l{2,3}(-\u{2})?)(?=">?)You may test these two regexes against the list above !
Best Regards,
guy038
-
-
thanks to all
yes i am trying to find in my pages the iso with two letters which refer generally to ISO 693-1because i think i havesome mistakes
example lingala
ISO 639-1 ln
ISO 639-2 lin
ISO 639-3 lin
IETF lnnot easy to know which language code
http://www.language-archives.org/language/lin
and
https://www.ethnologue.com/language/linuse ISO 693-3
-
Well… You can read into a poster’s request as much as you want, and go off and research a poster’s problem, again, as much as you want. :-)
I’m sure there might be some interesting “finds” along such a journey.I don’t mind helping with regex requests (except from the “takers”), but I’m sticking to what is asked for, and I’m not going to infer a bunch of stuff. My goal is “get them on their way” quickly. Just my take on it.
Also, if we solve the problem they ask for, and it isn’t the problem they have, perhaps they learn to be better askers?
But, I didn’t exactly solve the problem that was asked for: “find all lines…”. Really then the hit should have consisted of a full line, right? Well, we have some wiggle room here, as a “Find All…” search provides the whole line data requested.
-
Hi, @pouemes44, @alan-kilborn, @astrosofista and All,
@pouemes44, the last regex, of my previous post, finds any language code, of
2or3lowercase letters, optionnally followed with a dash and a country code of two uppercase letters, different from, either,"fr"and"fr-FR"OR finds the specificzh-Hansandzh-HantChinese syntaxes
Now, if we assume, as a matter of principle, that the language codes are all correct, in your files, the search of these language codes are more simple ! Indeed, as no control about syntax is needed, this regex, below, should be enough ( The two language codes
"fr"and"fr-FR"are not taken in account ! )SEARCH / MARK
(?-is)(?<=\x20lang=")(?!fr"|fr-FR").+?(?=">?)
And, as @alan-kilborn said, if you prefer to highlight the entire lines, with their
EOLchars, containing a language code, use that regex :MARK
(?-is)^.*\x20lang="(?!fr"|fr-FR").+\R?Which looks for entire lines, EOL included, containing, at least, a space char, followed by a string
lang", with this case, and followed with a valid language code, different from, either,"fr"and"fr-FR"
Finally, if you just need to bookmark the lines containing a global
HTMLattributelang"..........", containing a valid language code, different from, either,"fr"and"fr-FR", use this final regex :MARK
(?-i)\x20lang="(?!fr"|fr-FR")BR
guy038
-
Great thanks Guy for all you explanations which are precious, and could be precious to next search
Thanks Alan too***Is there someone here who could be able to make a working extention like “toolbucket” able to search and replace in folders… it should be a great extention
-
@Pouemes44 said in find two letters between quotes in lang tag:
Is there someone here who could be able to make a working extention like “toolbucket” able to search and replace in folders… it should be a great extention
Have you tried Replace in Files on the Find in Files tab of the Find window?
-
Hello Alan yes of course
but when i must search and replace multi lines, its not very easy with a sow little windows and must always use regular expresions for lines break, so with and extension it will be super
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login