UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?
-
Maybe this (changing my UI text) makes me feel better too:
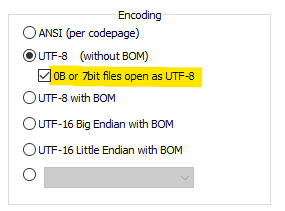
-
Interesting idea. That works for someone who understands basic encoding ideas (like you). But a newbie wouldn’t be expected to know what a “7bit file” is.
Regarding UI: I might be tempted to move the … MISC > Autodetect character encoding option to the New Document page, and rename that page Encodings / Line Endings or something – maybe File Interpretation ? I don’t know what’s the best phrasing.
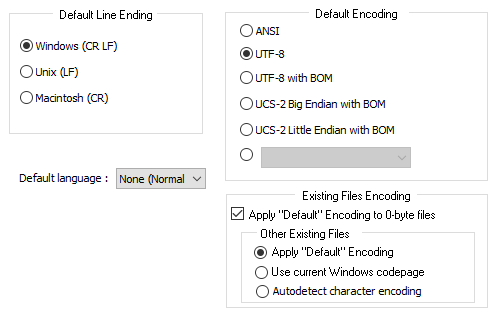
I don’t know. UI Design is hard.
-
@PeterJones said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
That works for someone who understands basic encoding ideas (like you). But a newbie wouldn’t be expected to know what a “7bit file” is.
This is true, and it DOES help me, because in about a week (or perhaps less) I will forget again what Apply to opened ANSI files means. :-) Joys of being “old”.
BTW, I said “changing MY UI text”. I wasn’t suggesting it as a change to Notepad++.
-
@Ekopalypse said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Afaik this is the point where
apply to opened ANSI filescomes into play.Yes but I don’t want to “upgrade” an existing files if they are already in ANSI, only for new 0 byte files, when again, are not really anything yet.
I like @PeterJones mockup UI, or at least those options makes more sense to me, ie. Default Encoding: UTF8 / Apply “Default” Encoding to 0-byte files / but use ANSI if the existing file is already encoded in ANSI.
-
@ImSpecial said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
I don’t want to “upgrade” an existing files if they are already in ANSI
It shouldn’t happen.
Try this test with the UTF-8 radio button chosen and the checkbox ticked.Create a disk file containing only
abcand perhaps a line-ending.
Open the file in N++.
It should be UTF-8. Why? Because there is nothing about its contents that indicate ANSI–and in a modern world this is how it should be.
You can call it “upgraded” if you want, but I wouldn’t.Create another disk file containing
abcfollowed by a byte with value 255. May want to use a hex editor to do this.
Open the file in N++.
Notepad++ should indicate ANSI.
Nothing was “upgraded”.Do you have a different scenario in mind where this Notepad++ behavior would give you trouble?
-
@Alan-Kilborn said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Create another disk file containing abc followed by a byte with value 255. May want to use a hex editor to do this.
BTW, I tried to create this file within N++ by making sure my status bar said “ANSI” and then double-clicking the 255 line in the Character Panel to insert the character. Unexpectedly (to me at least) what I actually achieved was two
Fcharacters inserted into my file, instead of one byte with value 255. -
@Alan-Kilborn said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Unexpectedly (to me at least) what I actually achieved was two F characters inserted into my file, instead of one byte with value 255.
Where you click in that panel determines what you get. If you click on FF, you get FF. If you click on ÿ, you get ÿ. If you click on ÿ, you get ÿ

-
@PeterJones said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Where you click in that panel determines what you get.
Ha. Amazing. I never knew that.
Of course, I have never used this panel before today.
I have very close to zero use for “ANSI”; that’s probably the reason.
Thanks for the good info!
:-) -
Hello, @alan-kilborn, @imspecial, @ekopalypse, @peterjones and All,
Alan, I think that, in your post, the term
7 Bitis not appropriate asANSIencoded files use a1-byteencoding, i.e. a8-bitencoding !Eventually, it would be better to change the phrase
Apply to opened ANSI filesin sectionSettings > Preferences... > New Document > Encodingwith :Encode, in UTF-8, any ANSI file, with ASCII characters only (NO char > \x7F)
Best Regards
guy038
-
the term 7 Bit is not appropriate as ANSI encoded files use a 1-byte encoding, i.e. a 8-bit encoding !
We are really talking about how N++ works to “classify” a file it is loading. When I mentioned “7 bit” I meant, at the point in the classification process, N++ has seen a file that contains only bytes with no most-significant-bits set, i.e., only 7-bit data.
Here’s the relevant piece of code:
So in my mind, the checkbox we are talking about comes into play when we have either of these situations:
- zero-byte file
- file with bytes with only 7-bit data
That was my rationale in using the term “7 bit”.
It doesn’t mean that the file would never contain characters from 128-255, just at the current time, no characters in the files meet that criterion.
Does it make sense? -
Hello , @alan-kilborn,
OK, I understand what you mean and, actually, my formulation
(NO char > \x7F)and yours7 bit filesdo mean the same thing, namely that the eighth bit is not used ( so =0) in existingANSIfiles which are automaticaly encoded inUTF-8on opening, if the squared box is ticked !
Now, I think that my formulation, of my previous post, should be improved as :
Encode, in UTF-8, any opened ANSI file, with ASCII characters only (NO char > \x7F)
Best Regards,
guy038
-
@guy038 said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Encode, in UTF-8, any opened ANSI file, with ASCII characters only (NO char > \x7F)
One problem is, that text is very long.
For UI text, that is.(NO char > \x7F) and yours 7 bit files do mean the same thing
Yes! I thought this, I just didn’t type it. :-)
-
@Alan-Kilborn said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
Do you have a different scenario in mind where this Notepad++ behavior would give you trouble?
My concern with upgrading files other then 0 byte ones, is that I very often will have my own copy of something and like to compare it against the original, which might be in ANSI, and when doing compares with the notepad++'s Compare plugin, it will complain that the encodings are different when doing so.
-
@ImSpecial said in UTF-8 encoding for new documents - This a bug, an oversight or intended behavior?:
My concern with upgrading files other then 0 byte ones, is that I very often will have my own copy of something and like to compare it against the original, which might be in ANSI, and when doing compares with the notepad++'s Compare plugin, it will complain that the encodings are different when doing so.
So, again, this “upgrade” will only take place if there are no characters in the file that would make the file ANSI. Meaning, there are no characters with byte values from 128 to 255.
If you intentionally work in ANSI most of the time, presumably your files WILL contain characters with byte values from 128 to 255 (because otherwise, why work in ANSI).
Thus, with your “compare” scenario, your fears probably aren’t realized, as you pull the first (base) file in, it is detected and shown as ANSI. Same thing when you pull the second (changed) file in. So when you go to do the compare there is no encoding difference.
Perhaps that’s not the reality of it, but that’s how I see it. :-)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login