Find - Replace
-
First, to solve your problem:
I can replicate your problem by using the same options:
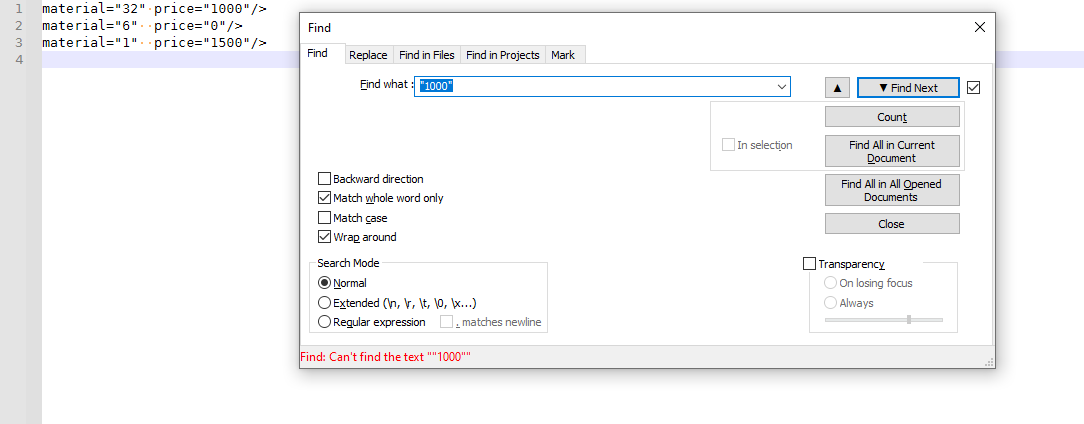
But if I turn off “match whole words only”, then it finds it easily:
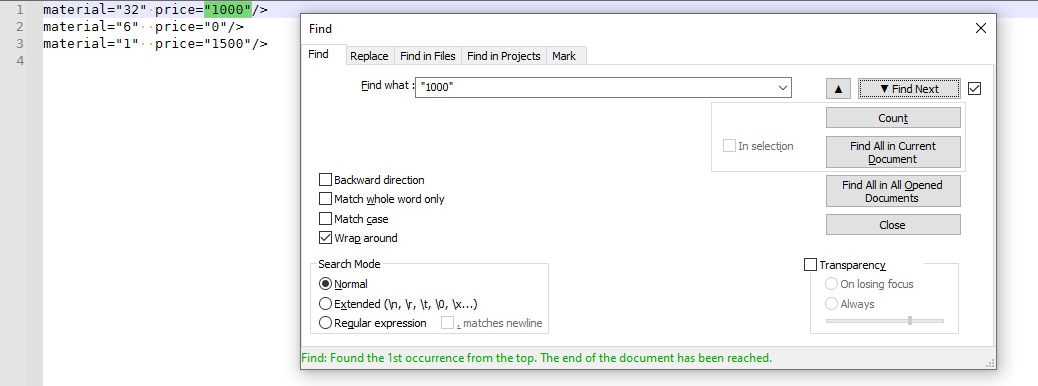
This is because
"1000"is not the “whole word”;price="1000"/>is the “whole word”.the error at the bottom is showing double quotes?
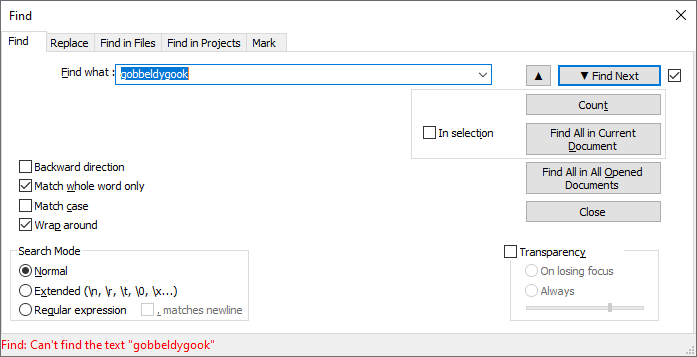
Because that error bar takes whatever is in the FIND box and puts it between quotes to display the text. If you had said Find What:
gobbeldygook, the error message would sayFind: Can't find the text "gobbeldygook", as shown here:
To reiterate the main solution: the reason your search did not work is because you told it to match whole words only, but then were trying to match against text that wasn’t a “whole word”.
------
see https://npp-user-manual.org/docs/searching/#find-replace-tabs
-
@peterjones said in Find - Replace:
price="1000"/>is the “whole word”.Can you elaborate on why this is?
Aside from “it works”? :-)Reading the fine manual HERE doesn’t really shed light on it, for me.
Note that I know how to use the option, and would never have used it like OP did, but it never hurts to know deeper meanings in things, so that maybe I can use a function better.
-
I don’t have insight into how the non-regex “word” is defined in the code.
However, at least in my brief experimentation, the “normal mode + match whole word only” seems to agree with “regex mode” and
\b.*?\b.For example, because the spot between the
=and the"will not match a word boundary\b, a “whole word only” match will not match if just the"is included, but it will if the match starts with="or if it starts at the1000.Maybe this will show it better: If you are searching the text
price="1000"/>:looking for text regex version normal+whole word matches regex matches notes 1000\b1000\bYES YES the zero-width between "1is a word boundary, as is0""1000\b"1000\bNO NO the zero-width between ="is not a word boundary, so fails="1000\b="1000\bYES YES the zero-width between e=is a boundary="1000"\b="1000"\bYESNO ERROR "/is not a word boundary, so the regex fails, but the normal+whole somehow matchesprice="1000"\bprice="1000"\bNO NO including pricebefore the=seems to change the normal+whole defintion of “whole word”… weird.Unfortunately, with experimentation, my theory broke down. I don’t know enough about the underlying details to explain exactly how it matches – someone with more insight into the source code would need to comment.
But I think a good general rule is, “if it doesn’t also match regex=
\bXXX\b, then normal+word=XXXprobably won’t work, though there are subtle exceptions”. For normal+word, I would stick to words that are obviously word units, like the1000orprice(with no spaces or punctuation), rather than trying to get normal+word to go across words or word boundaries. If you want to search across multiple words, or want mixed words and punctuation, normal+word will not always work as you expect. -
Hello, @kendall-demott, @peterjones, @alan-kilborn ans All,
Well, I would say :
-
For an
ANSIfile :-
If a string of
wordchars is immediately surrounded both, before and after, with one of the characters[\x00 - \x2F],[\x3A - \x40],[\x5B - \x5E],\x60or[ \x7B - \x7F], that string will match when theMatch whole word onlyoption is ticked -
In other words, if a string is immediately surrounded by, at least, one
wordchar, in the strict range[0-9A-Z_a-z]or any char in range[\x80-\xFF], that string will not match when theMatch whole word onlyoption is ticked
-
-
For a
NON-ANSIfile ( so any encoding different fromANSI) :-
If a string of
wordchars is immediately surrounded both, before and after, with a Unicodenon-wordcharacter, recognized by Notepad++, that string will match when theMatch whole word onlyoption is ticked -
In other words, if a string is immediately surrounded by, at least, one Unicode
wordchar, recognized by Notepad++, that string will not match when theMatch whole word onlyoption is ticked
-
Now, regarding the regex
\bzero-width assertion, it represents, either :-
The position between the
very beginningof current file and awordcharacter -
The position between a
non-wordcharacter and awordcharacter -
The position between a
wordcharacter and anon-wordcharacter -
The position between a
wordcharacter and thevery endof current file
Note also that the
\nand/or\rline-endings chars are always considered asnon-wordcharsBest Regards,
guy038
-
-
More on the subject from @guy038 in this old post: https://community.notepad-plus-plus.org/post/20424
Peter, could the user manual be better in this regard?
-
@guy038 said in Find - Replace:
If the string to search for is, itself, surrounded with non-word characters, that string will match when the Match whole word only option is ticked ONLY IF surrounded with the \n or \r chars
That’s not accurate.
If the document is
<a price="1000"/> x <a price="1000"/>xthen FIND =
="1000"/>will match both those lines, even though it’s got aneto the left and either a space or anxto the right.-–
Also, I originally said that
="1000"matched normal+whole word in the documentprice="1000"/>, but it does not… so apparently my test was wrong yesterday. And with NORMAL=="1000"and REGEX=\b="1000"\bactually agreeing that it doesn’t match, I am back to thinking that for a “normal+whole word” FIND=☒☒☒, it is equivalent to a regex FIND=\b☒☒☒\b(or, I should say\b\Q☒☒☒\E\b, because ☒ might be a regex special character, so it needs to be escaped in the regex-equivalent). I haven’t been able to find an exception to this. If anyone can show me different, let me know. -
Peter, Thank You, unticking that box solved my issue.
-
Hi, @kendall-demott, @peterjones, @alan-kilborn and All,
I said, in my previous post ( from now on deleted ) :
- If the string to search for is, itself, surrounded with
non-wordcharacters, that string will match when theMatch whole word onlyoption is ticked ONLY IF surrounded with the\nor\rchars
Actually, I really misspoke ! I wanted to mean :
- Any string, containing
wordand/ornon-wordcharacters, at any location, will match, when theMatch whole word onlyoption is ticked, IF this string is surrounded with nothing, a\nchar or a\rchar
Now, Peter, you said in your last post :
I am back to thinking that for a “normal+whole word” FIND=☒☒☒, it is equivalent to a regex FIND=\b☒☒☒\b …
So I created a file, containing all Unicode characters of the
BMP, only ( so63,454characters with code-point< U+FFFF), in the form below :NULabcd¤ SOHabcd¤ ... ... ... abcd¤ �abcd¤And it happens that :
-
The search of the string
abcd, inNormalmode, with theMatch whole word onlyoption ticked, returns12,561matches -
The search of the regex string
\babcd\binRegular expressionmode, returns15,424matches
So, obviously, these two kinds of searches are not equivalent at all !
For instance, let’s insert the string
¼abcd¤in a new tab, whatever its encodingFirst note that, either, the
¼and the¤characters are non-word characters. To be convinced, just look for\winRegular expressionmode. The four letters are matched, only-
However, the search of
abcd, inNormalsearch mode, with theMatch whole word onlyticked, gives : NO match -
Luckily, the search of
\babcd\b, inRegular expressionsearch mode, does give the correct answer : MATCH
Unfortunately, the general template
\bString of Word chars\bis not exact, too, in numerous cases :Let’s consider, for instance :
-
The
ԨUnicode character. It’s the CYRILLIC CAPITAL LETTER EN WITH LEFT HOOK with code-pointU+0528 -
The
ᏹUnicode character. It’s the CHEROKEE SMALL LETTER YI, with code-pointU+13F9 -
The
ⴭUnicode character. It’s the GEORGIAN SMALL LETTER AEN, with code-pointU+2D2D
Despite all these chars are seen as true letters by the Unicode Consortium, they are not considered, yet, as
wordchars by our N++ regex engine :((. Thus, the search of\babcd\b, inRegular expressionmode, will wrongly match the string abcd in the examples below :Ԩabcd¤ ᏹabcd¤ ⴭabcd¤Conclusion :
Although the search of a whole word with the regex
\b....\bseems more accurate and will give correct results with usual chars, it may fail with a lot of non-usual Unicode chars !Best Regards,
guy038
P.S. :
Note that the use of the regex assertion
\bmay give correct but rather surprising results ! For instance, the regex\b\Q^!:/@?$\E\bmatches the part ^!:/@?$, of the string A^!:/@?$Z, because the\bassertion may be the location between awordchar and anon-wordchar ! So, definitively, the use of the\bassertion, in regexes and the optionMatch whole word only, inNormalmode, are not equivalent ! - If the string to search for is, itself, surrounded with
-
@guy038 ,
Thanks for the experiment. Basically, it boils down to “Unicode complicates things for whole word only”. ;-)
The phrasing I am considering for the user manual:
-
For ASCII text
- if the left and right characters of your search string are both “word characters” (letters, numbers, underscore, and optionally additional characters set by your preferences), then “match whole word only” will only allow a match if the characters to the left and right of the match are non-word-characters or spaces or the beginning or ending of the line
- if the left and right characters of your search string are both non-word characters (so not letters, numbers, underscore, and optionally additional characters set by your preferences)
- if the left of your search string is a word character and the right is not (or vice versa), then the characters to the left and right must be of the opposite type, or spaces, or beginning/ending of line.
-
For non-ASCII text, the general concepts are the same; however, some edge cases may behave differently than you expect, and with thousands of possible Unicode characters and millions of combinations of pairs of Unicode characters, this manual cannot contain a full description.
-
Either way, if you want full control of what counts as a “word” or a “word boundary”, use Search Mode = Regular Expression instead of Normal with Match Whole Word Only, which allows you full and precise control of what is allowed before and after what you consider a “whole word”.
And yes, I did verify that Settings > Preferences > Delimiter > add your character as part of a word does affect whether Match whole word only matches.
-
-
The phrasing I am considering for the user manual:
It should be in the next release of the user manual
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login