Search with quantifier failed
-
@PeterJones said in Search with quantifier failed:
It needs the dagger, and all the \o, \d, and \x need examples and expansion. Sheesh; who was the usermanual editor who let that section stand as-is. ;-(
What’s the “dagger”?
Personally I don’t mind that that manual section is not well-rounded-out. In my mind Extended mode has always been a crippled mode I never use. I would guess the history is that it was a poor-man’s regex mode before regex mode was implemented.
-
Dagger
†U+2020 as seen in the Extended Mode Docs:

It may be a crippled mode, but it should still be correctly documented. The docs as written don’t clarify well enough that
\drequires three decimal digits, nor that it is not the same as the\dfrom regex mode. Other entries in the list use the dagger notation to reference the note about being different from the regex syntax that looks similar. -
@Alan-Kilborn I use the extended mode for hexadecimal search (\x), so for me it is still useful in some cases.
-
@datatraveller1 said in Search with quantifier failed:
I use the extended mode for hexadecimal search (\x), so for me it is still useful in some cases.
For the most part, you can also use Regular expression mode for that. But, as I’ve recently cautioned another poster, if you find you are searching for hex sequences often, you are probably doing something wrong with how you are approaching text editing. Of course, that’s said with no info about what you are doing.
-
Firstly, apologies to @Dr-N for possibly steering the posts in a wrong direction.
Secondly, sorry to the rest of you. I had not actually tested the Extended mode (wasn’t on a PC when I posted), rather just read from the manual (which has been verified as missing important information). It also appeared (on the surface) to explain the OP’s issue.
I have never used Extended because of the same reasoning as @Alan-Kilborn. I’m even more convinced now that it is a rubbish mode. If it’s intended to give users a leg up to full blown regex then (I believe) it completely misses the mark.
Given the manual didn’t fully explain the use and if someone new was to try it, the meta characters, being so closely resembling regex code will only serve to confuse users of that mode. I cannot see a reason for retaining this mode.
My 2c worth
Terry -
@Terry-R said in Search with quantifier failed:
My 2c worth
So here’s my take on it.
The history: Notepad++, pre version 6.0, had no regex search/replace mode. The author wanted to give some capability, and didn’t want to tackle a regex implementation himself (fun fact: in truth it was done by the author of the PythonScript plugin and some others). Thus “extended” mode was born.
When regex mode DID come along, “extended” mode really wasn’t necessary, but features aren’t usually removed, because someone may be using them (and complain). Thus, it lives. And maybe some still cling to it because regular expressions terrify them. :-)
-
@Alan-Kilborn I rarely use the hexadecimal search, e.g. to search for the annoying character “Non-breaking space, HEX A0, DEC 160”.
-> Notepad++, extended search for\xA0
… but you are right, this also works with the regular expression mode.BTW, I was a bit confused by the \X paragraph in the manual
https://npp-user-manual.org/docs/searching:
“For example, the letter ǭ̳̚, with four combining characters after the o, can be found either with the regex (?-i)o\x{0304}\x{0328}\x{031a}\x{0333} or with the shorter regex \X.” -> I miss the example for the shorter regex \X? -
@datatraveller1 said in Search with quantifier failed:
I miss the example for the shorter regex \X
The entire regex is
\X– it matches one letter plus all the combining characters that come after, hence it would match the o and the four shown combining-characterd -
Hello @dr-n, @alan-kilborn, @terry-r, @peterjones, @datatraveller1 and All,
I tried to merge the two posts below, in order to get a complete summary of the
Extendedsearch mode feature !https://community.notepad-plus-plus.org/post/45753
https://community.notepad-plus-plus.org/post/24236
I hope I have not forgotten anything important !
Peter, if you get some spare time, just check here and see if some points of this post could be added / improved !
In the
Extendedsearch mode, in addition to the search/replacement of standard characters and the5specific characters, below :Character Syntax Tabulation \tNew Line \nCarriage Return \rBackslash \\Null \0Within an Unicode encoded file, any single character of code-point
U+xxxx, may be written, in the Find what: and the Replace With: zones, with one of the five syntaxes below :Type From To Character Range Decimal \d000\d999[0-9]Octal \o000\o777[0-7]Binary \b00000000\b11111111[0-1]Hexadecimal \x00\xFF[0-9A-Fa-f]Unicode \u0000\uFFFF[0-9A-Fa-f]Consequence :
The character with the greatest Unicode code-point which can be searched and/or replaced, in
Extendedmode, is :-
\d999, so the Unicode characterϧ( COPTIC SMALL LETTER KHEI ), with code-point =\u03e7, in the decimal representation -
\o777, so the Unicode characterǿ( LATIN SMALL LETTER O WITH STROKE AND ACUTE ), with code-point =\u01ff, in the octal representation -
\b11111111, so the Unicode characterÿ( LATIN SMALL LETTER Y WITH DIAERESIS ), with code-point =\u00ff, in the binary representation -
\xFF, so the Unicode characterÿ( LATIN SMALL LETTER Y WITH DIAERESIS ), with code-point =\u00ff, in the the hexa representation -
\uFFFD, so the Unicode character�( REPLACEMENT CHARACTER ), with code-point =\ufffd, in the Unicode representation
Within an ANSI encoded file, any single character of code-point
U+00xx, may be written, in the Find what: and the Replace With: zones, with one of the four syntaxes below :Type From To Character Range Decimal \d000\d255[0-9]Octal \o000\o377[0-7]Binary \b00000000\b11111111[0-1]Hexadecimal \x00\xFF[0-9A-Fa-f]Remarks :
-
In all cases, the character with the greatest Unicode code-point which can be searched and/or replaced is, either,
\d255or\o377or\b11111111or\xFFwhich refers to the Unicode characterÿ( LATIN SMALL LETTER Y WITH DIAERESIS ) -
An Unicode character, of code-point
U+00xx, can be found ONLY IF xx belongs to the range[00-7F]OR to the range[A0-FF]. When xx lies between80and9F, it generally searches for the question mark (?) as it refers to an Unicode char, whose code-point is not handled by theANSIencoding ! Only, the5charactersU+0081,U+008D,U+008F,U+0090andU+009D, without any glyph, are correctly searched !
Examples ( With the
Match caseoption ticked and theMatch whole word onlyoption UN-ticked ) :-
If you search for the uppercase letter
A, you can choose, either, the syntax\d065or\o101or\b1000001or\x41or\u0041 -
And if you look for the character, with decimal
ASCIIcode 201 (É), type in, either, the syntax\d201or\o311or\b11001001or\xC9or\u00C9 -
Of course, you may mix all these representations, either, in the Search and Replace zones. For instance, the text
\d065\o102\b01000011Z\x44\u0045represents the simple string ABCZDE
Remark : Depending of the End of Line character(s), used in your current file, indicated in the status bar (
\r\nfor a Window file,\nfor an Unix file, and\rfor a Mac file ), you can search and/or replace text, containing line break(s). For instance :- The search, in the Extended or Regular expression search mode, of the string
ABC\r\n123and the replacement by the stringWord\r\nNumber, in a Windows file, would change the two lines :
ABC 123as the text :
Word Number-
This same S/R, in a Unix file, could be performed with the searched string
ABC\n123and the replaced stringWord\nNumber -
With the following Windows file :
Line_1 Line_2 Line_3 Line_4 Line_5 Line_6 Line_7 Line_8 Line_9You could, perfectly, in Extended or Regular expression mode, use the following S/R :
-
SEARCH
Line_1\r\nLine_2\r\nLine_3\r\nLine_4\r\nLine_5\r\nLine_6\r\nLine_7\r\nLine_8\r\nLine_9\r\n -
REPLACE
Modified Line #1\r\nModified Line #2\r\nModified Line #3\r\nModified Line #4\r\nModified Line #5\r\nModified Line #6\r\nModified Line #7\r\nModified Line #8\r\nModified Line #9\r\n
And get the text :
Modified Line #1 Modified Line #2 Modified Line #3 Modified Line #4 Modified Line #5 Modified Line #6 Modified Line #7 Modified Line #8 Modified Line #9
The nice trick, with the search dialog, is that you DON’T need to separate the text of each line, with the End of Line characters
\r\n:-
Select, first, the original 9-lines text
-
Open the Replace dialog (
Ctrl + H)
=> The entire searched text is automatically filled
Unfortunately, you CANNOT use this same work-around, for the replacement dialog -:(( So, you’ll still have to type all the text, below :
Modified Line #1\r\nModified Line #2\r\nModified Line #3\r\nModified Line #4\r\nModified Line #5\r\nModified Line #6\r\nModified Line #7\r\nModified Line #8\r\nModified Line #9\r\n
Note that, WHATEVER the search mode used :
-
Do not exceed 2046 characters for, both, the Search and the Replace zones. Anyway, any surplus character is simply ignored !
-
It could be worth to check the
Match caseoption, in order to differentiate between upper and lower case letters -
I strongly advice you to uncheck the
Match whole word onlyoption, especially when the searched string begins and/or ends with a NON-word character -
The search of individual bytes of an
UTF-8orUCS-2encoded character is not allowed ! -
The replacement zone may contain any char, except for the NUL char (
\0), whatever its representation (\0,\d000,\o000,\b00000000,\x00or\u0000)
Best Regards,
guy038
P.S. :
-
Personally, I think that the only advantage of using the
Extendedmode is when using the\dxxxsyntax, where xxx represents the decimal code of the character :-
Between
000and255( so in rangeU+0000 - U+00FF) within a UTF-8 or UCS-2 encoded file -
Between
000and127or between160and255( so in rangesU+0000 - U+007ForU+00A0 - U+00FF) within an ANSI file
-
In all other cases, just prefer the
Regular expressionsearch mode ;-))
- For information, about the Extended search mode, you may also refer to this old article, in N++ Wiki, via the web.archive site :
- Finally, @peterjones, if you need to refer to the old N++
Wiki, here are some links, via the WayBack Machine site :
https://web.archive.org/web/20190719202854/http://docs.notepad-plus-plus.org/index.php/Main_Page
-
-
@PeterJones said in Search with quantifier failed:
The entire regex is \X – it matches one letter plus all the combining characters that come after, hence it would match the o and the four shown combining-characterd
Sorry, but I still don’t understand the manual text:
“For example, the letter ǭ̳̚, with four combining characters after the o, can be found either with the regex (?-i)o\x{0304}\x{0328}\x{031a}\x{0333} or with the shorter regex \X.”-> \X seems to find any letter but the text implies \X is an alternative to find exactly ǭ̳̚?
… So is \X a better alternative than a dot in a regular expression to find a letter, because a dot finds the four combining characters and \X the one whole letter?
-
Correction: I earlier said from memory,
it matches one letter plus all the combining characters that come after
When i should have said
it matches one character plus all the combining characters that come after
It was evening, I was tired, and I was typing on my phone from memory without the manual or a copy of Notepad++ in front of me.
@datatraveller1 said in Search with quantifier failed:
\X seems to find any letter but the text implies \X is an alternative to find exactly ǭ̳̚?
You read it different than it was intended. The manually literally says “Matches a single non-combining character followed by any number of combining characters” and that’s exactly what it matches. It doesn’t matter whether that character is
ooraorZor whatever. It matches one character, along with all the modifiers that come next. Just like\umatches one uppercase letter, or\lmatches one lowercase letter, or\Rmatches either\ror\nor\r\n, the\Xregex will match a character plus all the combining characters that come next.In this example text, I have o followed by those four modifiers, a followed by those four modifiers, and _ followed by those
ǭ̳̚ ą̳̄̚ _̨̳̄̚ :̨̳̄̚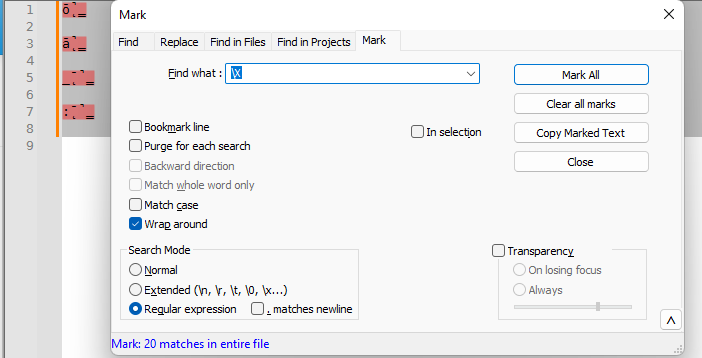
You will see that it matches all four of those sequences.
It says 20, because it also matches each of the bytes of the newlines between, each of which are 1 character followed by 0 modifying characters.
So is \X a better alternative than a dot in a regular expression to find a letter, because a dot finds the four combining characters and \X the one whole letter?
Depending on how one interprets your phrasing, that’s either right, or literally the opposite of what happens: if you mean that
ǭ̳̚with all the modifiers is “one whole letter” and that “dot finds the four combing characters” means that the dot matches each combining character independently with four separate matches, then yes, you are right. If you meant it the way i first read it, where it means “the single dot matches all four combinging characters at once, whereas the\Xjust finds the letter”, then it’s exactly opposite of what happens.Dot matches a single character – this could be the initial character, or any of the four modifiers.
\Xmatches the character plus all the modifiers in one unit. So the screenshot above with the\Xshowed 20 matches, whereas the.will show 36 (one for each character).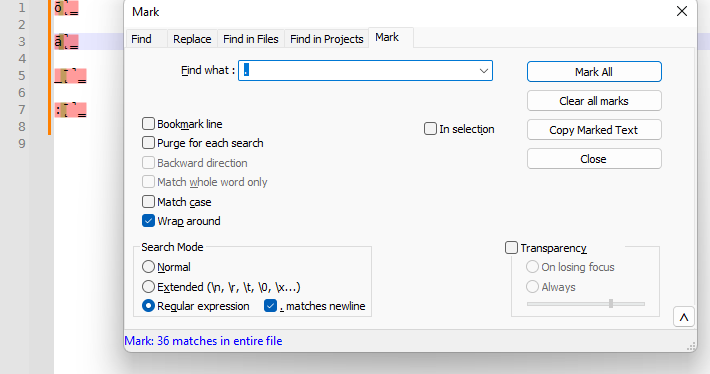
I really didn’t think there was ambiguity in the phrasing, but I will try to clarify it some more.
-
@PeterJones Thank you very much indeed!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login