How i can sort number from largest to smallest on notepad++
-
@guy038
I should know better than to ever count out our resident regex wizard… -
@Mark-Olson,
I was thinking of taking a crack at it late this morning myself, but realized quickly…I’m not up to that kind of manipulation yet. :) -
@zweafw said in How i can sort number from largest to smallest on notepad++:
I’m new on Notepad++ and I want to know how can sort number from largest to smallest.
click on edit --> line operation–> sort lines as Integer descending
-
@ling-danyelle
Yes, that would work in the specific case where the line starts with integers.
But if the line doesn’t start with integers, as in the user’s example data, it will not work. That’s why we went to all this trouble to pre-process the text. -
@Mark-Olson said:
I’m contemplating turning this script into a general-purpose thing to sort lines by the numeric or text value of any regex search result in that line.
Apologies to Mark for a possible upstaging, but I took this idea and ran with it, producing the following script called
SortLinesWithRegexGroup1AsSortKey.py:# -*- coding: utf-8 -*- from __future__ import print_function ######################################### # # SortLinesWithRegexGroup1AsSortKey (SLWRG1ASK) # ######################################### # references: # https://community.notepad-plus-plus.org/topic/24325 #------------------------------------------------------------------------------- from Npp import * import inspect import os import re import threading import SendKeys as sk #------------------------------------------------------------------------------- class SLWRG1ASK(object): def __init__(self): self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] self.key_and_line_content_tup_list = [] self.key_did_not_match_specified_type__ERROR = False self.user_did_not_specify_group1__ERROR = False self.not_all_lines_matched__ERROR = False self.last_matched_line_num = None self.user_line_num_of_error = None self.zero_matches_for_regex = True self.key_type__int_float_str = None self.do_descending_sort = False self.each_line_must_have_regex_group1_key_match = True self.remove_lines_that_dont_match_regex = False rect_sel_mode = editor.getSelectionMode() in [ SELECTIONMODE.RECTANGLE, SELECTIONMODE.THIN ] if rect_sel_mode or editor.getSelections() > 1: self.mb('Cannot operate on a column selection or multiple selections; aborting!') return if len(editor.getSelText()) == 0: if not self.mb_ok_cancel('No selection active; confirm desire to sort entire file by pressing OK.'): return (search_start_line, search_end_line) = editor.getUserLineSelection() if editor.positionFromLine(search_end_line) == editor.getSelectionEnd(): search_end_line -= 1 num_lines_in_user_sel = search_end_line - search_start_line + 1 if num_lines_in_user_sel < 2: return # if selection only on 1 line, nothing to do; already sorted! user_regex_with_group_1 = '' while True: user_regex_with_group_1 = self.prompt('Enter regex with group 1 being the sort key', user_regex_with_group_1) if user_regex_with_group_1 is None: return # user cancel if len(user_regex_with_group_1.strip()) == 0: self.mb('Cannot specify an empty regex! Try again.') continue if '(' not in user_regex_with_group_1: self.mb('Need to specify capture group 1 (as the sort key) in the regex! Try again.') continue regex_err_msg = self.search_regex_is_invalid_error_msg(user_regex_with_group_1) if len(regex_err_msg) > 0: self.mb('Bad regular expression!\r\n\r\n{e}\r\n\r\nTry again.'.format(e=regex_err_msg)) continue break while True: threading.Timer(0.25, lambda : sk.SendKeys("{RIGHT}")).start() # clear auto-selection of prompt text when box appears user_options = self.prompt( ' Regex specified: {r}\r\n' 'Choose options by placing 1 x in each group (no need to x to get DEFAULT choice)'.format(r=user_regex_with_group_1), '\r\n'.join([ 'Group 1 data type: [ ]Integer(DEFAULT) [ ]Decimal [ ]String', 'Sort order: [ ]Ascending(DEFAULT) [ ]Descending', 'Other:', '[ ]Sort-only-if-all-lines-have-group-1-match(DEFAULT)', '[ ]Remove-non-matching-lines', ]) ) if user_options is None: return # user cancel if len(user_options.strip()) == 0: self.mb('Cannot specify empty options! Try again.') continue if self.option_check(user_options, 'String'): self.key_type__int_float_str = str elif self.option_check(user_options, 'Decimal'): self.key_type__int_float_str = float else: self.key_type__int_float_str = int self.do_descending_sort = self.option_check(user_options, 'Descending') self.each_line_must_have_regex_group1_key_match = self.option_check(user_options, 'Sort-only-if-all-lines-have-group-1-match') self.remove_lines_that_dont_match_regex = self.option_check(user_options, 'Remove-non-matching-lines') if not self.remove_lines_that_dont_match_regex: self.each_line_must_have_regex_group1_key_match = True if self.each_line_must_have_regex_group1_key_match and self.remove_lines_that_dont_match_regex: self.mb('Incorrect options checkmarked! Try again!') continue break # enforce single-line matching and only get the FIRST match on each line: user_regex_with_group_1 = '(?-s)' + user_regex_with_group_1 + '.*' search_start_pos = editor.positionFromLine(search_start_line) search_end_pos = editor.getLineEndPosition(search_end_line) # special "seeding", in case the very first line of the selection isn't hit: self.last_matched_line_num = search_start_line - 1 editor.research(user_regex_with_group_1, lambda m: self.match_found(m), 0, search_start_pos, search_end_pos) if self.zero_matches_for_regex: self.mb('No lines matched the regex; aborting!') return if self.user_did_not_specify_group1__ERROR: self.mb('No sort key specified (via using capture group 1) in the regex; aborting!') return if self.key_did_not_match_specified_type__ERROR: self.mb('Key data did not match specified type ({t}) on line {L}; aborting!'.format(L=self.user_line_num_of_error, t={ int : 'Integer', float : 'Decimal', str : 'String' }[self.key_type__int_float_str])) return if self.each_line_must_have_regex_group1_key_match and self.not_all_lines_matched__ERROR: self.mb('Not every line in the source data matched the specified regex (first non-matching line was {L}); aborting!'.format(L=self.user_line_num_of_error)) return if len(self.key_and_line_content_tup_list) < 2: self.mb('Nothing (reasonable) found to sort; aborting!') return sorted_line_list = list(zip(*sorted(self.key_and_line_content_tup_list, reverse=self.do_descending_sort)))[1] eol = ['\r\n', '\r', '\n'][editor.getEOLMode()] doc_len_before = editor.getLength() editor.setSelection(search_end_pos, search_start_pos) editor.replaceSel(eol.join(sorted_line_list)) doc_len_delta = editor.getLength() - doc_len_before # leave sorted text selected: editor.setSelection(search_end_pos + doc_len_delta, search_start_pos) def match_found(self, m): self.zero_matches_for_regex = False # we're already corrupt; don't bother processing further matches after the one where we found the problem if self.user_did_not_specify_group1__ERROR: return if self.key_did_not_match_specified_type__ERROR: return if self.not_all_lines_matched__ERROR: return (start_pos_of_match, end_pos_of_match) = m.span(0) line_num_of_match = editor.lineFromPosition(start_pos_of_match) if self.each_line_must_have_regex_group1_key_match: if line_num_of_match != self.last_matched_line_num + 1: self.not_all_lines_matched__ERROR = True system_line_num_of_err = self.last_matched_line_num + 1 self.user_line_num_of_error = system_line_num_of_err + 1 return self.last_matched_line_num = line_num_of_match try: g1_str = m.group(1) except IndexError: self.user_did_not_specify_group1__ERROR = True return try: key_with_correct_type = self.key_type__int_float_str(g1_str) except ValueError: self.key_did_not_match_specified_type__ERROR = True self.user_line_num_of_error = line_num_of_match + 1 return line_content = editor.getLine(line_num_of_match).rstrip('\n\r') tup = (key_with_correct_type, line_content) self.key_and_line_content_tup_list.append(tup) def option_check(self, input_text, option_text): m = re.search(r'\[([^]]+)\] ?{opt}'.format(opt=option_text), input_text) retval = True if m and m.group(1) != ' ' * len(m.group(1)) else False return retval def search_regex_is_invalid_error_msg(self, test_regex): try: # test test_regex for validity editor.research(test_regex, lambda _: None) except RuntimeError as r: return str(r) return '' def mb(self, msg, flags=0, title=''): # a message-box function return notepad.messageBox(msg, title if title else self.this_script_name, flags) def mb_ok_cancel(self, msg, title=''): # returns True(OK) or False(Cancel) okay = notepad.messageBox(msg, title if title else self.this_script_name, MESSAGEBOXFLAGS.OKCANCEL) == MESSAGEBOXFLAGS.RESULTOK return okay def prompt(self, prompt_text, default_text=''): if '\n' not in prompt_text: prompt_text = '\r\n' + prompt_text prompt_text += ':' return notepad.prompt(prompt_text, self.this_script_name, default_text) #------------------------------------------------------------------------------- if __name__ == '__main__': SLWRG1ASK()Let’s walk thru using it on @guy038’s data:
This is a| 43 points random | 82 points Text to | 82 points See how it works | 153 pointsPut those lines in a tab and select them and run the script.
You get prompted:
Enter
\| (\d+) pointsas this regex matches the desired sort key and places it in capture group 1: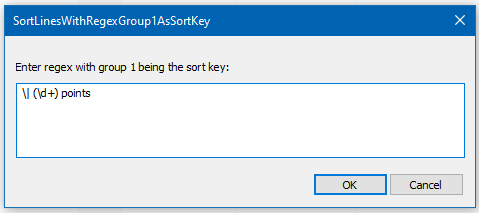
and press OK/Enter.
The next prompt is:
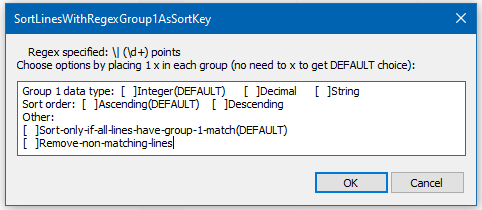
(Yep, my ever-so-cheesy-UI)
Since we desire a high-to-low sort, “tick” the box for a Descending sort:
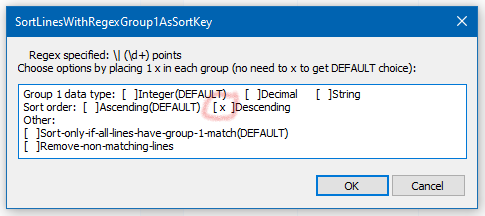
and press OK/Enter (accepting all the other “defaults” without needing to “tick” their boxes).
Then the originally selected lines change to this data, the result of the specified sort:
See how it works | 153 points random | 82 points Text to | 82 points This is a| 43 points--
Moderator EDIT (2024-Jan-14): The author of the script has found a fairly serious bug with the code published here for those that use Mac-style or Linux-style line-endings in their files. The logic for Mac and Linux was reversed, and thus if the script was used on one type of file, the line-endings for the opposite type of file could end up in the file after the script is run. This is insidious, because unless one works with visible line-endings turned on, this is likely not noticed. Some detail on the problem is HERE. The script above has been corrected per that instruction. -
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
@Alan-Kilborn
Awesome! I don’t mind being upstaged at all, and it has all the features I would have wanted. I’ll play around with this and see if I can come up with improvements. -
@Alan-Kilborn said in How i can sort number from largest to smallest on notepad++:
(Yep, my ever-so-cheesy-UI)
Nice of you to acknowledge this. 🤓
-
OK, I’ve added two new options: lowercase culture-insensitive (Python can do that, it’s just rather obscure) and sorting unmatched lines to bottom.
The text:
foo: tone bar: 27.1 foo: bLue bar: 241.3 foo: taco bar: 66.5 foo: basst bar: 281.7 foo: öyster bar: 144.0 foo: oyster bar: 164.1 foo: Spb bar: 102.1 foo: blüe bar: 203.2 foo: spä bar: 121.2 foo: spb bar: 84.2 foo: blve bar: 183.2 foo: blue bar: 222.2 foo: baßk bar: 261.3 foo: täco bar: 47.3Sorting unmatched lines to bottom (regex
bar: (\d\d)\D, all other options default). Note that the lines with a 3-digit number all stay in the same order.foo: tone bar: 27.1 foo: täco bar: 47.3 foo: taco bar: 66.5 foo: spb bar: 84.2 foo: bLue bar: 241.3 foo: basst bar: 281.7 foo: öyster bar: 144.0 foo: oyster bar: 164.1 foo: Spb bar: 102.1 foo: blüe bar: 203.2 foo: spä bar: 121.2 foo: blve bar: 183.2 foo: blue bar: 222.2 foo: baßk bar: 261.3Ignorecase culture-sensitive (regex
foo: (\w+), all other options default)foo: basst bar: 281.7 foo: baßk bar: 261.3 foo: bLue bar: 241.3 foo: blue bar: 222.2 foo: blüe bar: 203.2 foo: blve bar: 183.2 foo: oyster bar: 164.1 foo: öyster bar: 144.0 foo: spä bar: 121.2 foo: Spb bar: 102.1 foo: spb bar: 84.2 foo: taco bar: 66.5 foo: täco bar: 47.3 foo: tone bar: 27.1And finally, my modification of the script:
# -*- coding: utf-8 -*- from __future__ import print_function ######################################### # # SortLinesWithRegexGroup1AsSortKey (SLWRG1ASK) # ######################################### # references: # https://community.notepad-plus-plus.org/topic/24325 #------------------------------------------------------------------------------- from Npp import * import inspect import os import re import threading import unicodedata import SendKeys as sk #------------------------------------------------------------------------------- def ignorecase_culture_invariant(x): return unicodedata.normalize('NFD', x.lower()) class SLWRG1ASK(object): def __init__(self): self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] self.key_and_line_content_tup_list = [] self.matched_line_numbers = set() self.key_did_not_match_specified_type__ERROR = False self.user_did_not_specify_group1__ERROR = False self.not_all_lines_matched__ERROR = False self.last_matched_line_num = None self.user_line_num_of_error = None self.zero_matches_for_regex = True self.key_transform = None self.do_descending_sort = False self.each_line_must_have_regex_group1_key_match = True self.remove_lines_that_dont_match_regex = False self.sort_lines_that_dont_match_to_bottom = False rect_sel_mode = editor.getSelectionMode() in [ SELECTIONMODE.RECTANGLE, SELECTIONMODE.THIN ] if rect_sel_mode or editor.getSelections() > 1: self.mb('Cannot operate on a column selection or multiple selections; aborting!') return if len(editor.getSelText()) == 0: if not self.mb_ok_cancel('No selection active; confirm desire to sort entire file by pressing OK.'): return (search_start_line, search_end_line) = editor.getUserLineSelection() if editor.positionFromLine(search_end_line) == editor.getSelectionEnd(): search_end_line -= 1 num_lines_in_user_sel = search_end_line - search_start_line + 1 if num_lines_in_user_sel < 2: return # if selection only on 1 line, nothing to do; already sorted! user_regex_with_group_1 = '' while True: user_regex_with_group_1 = self.prompt('Enter regex with group 1 being the sort key', user_regex_with_group_1) if user_regex_with_group_1 is None: return # user cancel if len(user_regex_with_group_1.strip()) == 0: self.mb('Cannot specify an empty regex! Try again.') continue if '(' not in user_regex_with_group_1: self.mb('Need to specify capture group 1 (as the sort key) in the regex! Try again.') continue regex_err_msg = self.search_regex_is_invalid_error_msg(user_regex_with_group_1) if len(regex_err_msg) > 0: self.mb('Bad regular expression!\r\n\r\n{e}\r\n\r\nTry again.'.format(e=regex_err_msg)) continue break while True: threading.Timer(0.25, lambda : sk.SendKeys("{RIGHT}")).start() # clear auto-selection of prompt text when box appears user_options = self.prompt( ' Regex specified: {r}\r\n' 'Choose options by placing 1 x in each group (no need to x to get DEFAULT choice)'.format(r=user_regex_with_group_1), '\r\n'.join([ 'Group 1 transformation: [ ]Integer(DEFAULT) [ ]Decimal [ ]String [ ]Ignorecase-cultural', 'Sort order: [ ]Ascending(DEFAULT) [ ]Descending', 'Other:', '[ ]Sort-only-if-all-lines-have-group-1-match(DEFAULT)', '[ ]Remove-non-matching-lines', '[ ]Sort-non-matching-lines-to-bottom', ]) ) if user_options is None: return # user cancel if len(user_options.strip()) == 0: self.mb('Cannot specify empty options! Try again.') continue if self.option_check(user_options, 'String'): self.key_transform = str elif self.option_check(user_options, 'Decimal'): self.key_transform = float elif self.option_check(user_options, 'Ignorecase-cultural'): self.key_transform = ignorecase_culture_invariant else: self.key_transform = int self.do_descending_sort = self.option_check(user_options, 'Descending') self.each_line_must_have_regex_group1_key_match = self.option_check(user_options, 'Sort-only-if-all-lines-have-group-1-match') self.remove_lines_that_dont_match_regex = self.option_check(user_options, 'Remove-non-matching-lines') self.sort_lines_that_dont_match_to_bottom = self.option_check(user_options, 'Sort-non-matching-lines-to-bottom') if not (self.remove_lines_that_dont_match_regex or self.sort_lines_that_dont_match_to_bottom): self.each_line_must_have_regex_group1_key_match = True if self.each_line_must_have_regex_group1_key_match + self.remove_lines_that_dont_match_regex + self.sort_lines_that_dont_match_to_bottom > 1: self.mb('Can only specify one way of handling unmatched lines! Try again!') continue break # enforce single-line matching and only get the FIRST match on each line: user_regex_with_group_1 = '(?-s)' + user_regex_with_group_1 + '.*' search_start_pos = editor.positionFromLine(search_start_line) search_end_pos = editor.getLineEndPosition(search_end_line) # special "seeding", in case the very first line of the selection isn't hit: self.last_matched_line_num = search_start_line - 1 editor.research(user_regex_with_group_1, lambda m: self.match_found(m), 0, search_start_pos, search_end_pos) if self.zero_matches_for_regex: self.mb('No lines matched the regex; aborting!') return if self.user_did_not_specify_group1__ERROR: self.mb('No sort key specified (via using capture group 1) in the regex; aborting!') return if self.key_did_not_match_specified_type__ERROR: self.mb('Key data did not match specified type ({t}) on line {L}; aborting!'.format(L=self.user_line_num_of_error, t={ int : 'Integer', float : 'Decimal', str : 'String', ignorecase_culture_invariant: 'String' }[self.key_transform])) return if self.each_line_must_have_regex_group1_key_match and self.not_all_lines_matched__ERROR: self.mb('Not every line in the source data matched the specified regex (first non-matching line was {L}); aborting!'.format(L=self.user_line_num_of_error)) return if len(self.key_and_line_content_tup_list) < 2: self.mb('Nothing (reasonable) found to sort; aborting!') return sorted_line_list = [tup[1] for tup in sorted(self.key_and_line_content_tup_list, reverse=self.do_descending_sort)] if self.matched_line_numbers: first_unmatched_line = search_start_line + len(self.matched_line_numbers) + 1 self.mb('Line numbers {0}-{1} in sorted text were NOT matched.'.format(first_unmatched_line, search_end_line + 1), title='not all lines matched') for line_num in range(search_start_line, search_end_line + 1): if line_num not in self.matched_line_numbers: unmatched_line = editor.getLine(line_num) sorted_line_list.append(unmatched_line.rstrip('\r\n')) eol = ['\r\n', '\r', '\n'][editor.getEOLMode()] doc_len_before = editor.getLength() editor.setSelection(search_end_pos, search_start_pos) editor.replaceSel(eol.join(sorted_line_list)) doc_len_delta = editor.getLength() - doc_len_before # leave sorted text selected: editor.setSelection(search_end_pos + doc_len_delta, search_start_pos) def match_found(self, m): self.zero_matches_for_regex = False # we're already corrupt; don't bother processing further matches after the one where we found the problem if self.user_did_not_specify_group1__ERROR: return if self.key_did_not_match_specified_type__ERROR: return if self.not_all_lines_matched__ERROR: return (start_pos_of_match, end_pos_of_match) = m.span(0) line_num_of_match = editor.lineFromPosition(start_pos_of_match) if line_num_of_match != self.last_matched_line_num + 1: if self.each_line_must_have_regex_group1_key_match: self.not_all_lines_matched__ERROR = True system_line_num_of_err = self.last_matched_line_num + 1 self.user_line_num_of_error = system_line_num_of_err + 1 return self.last_matched_line_num = line_num_of_match if self.sort_lines_that_dont_match_to_bottom: self.matched_line_numbers.add(line_num_of_match) try: g1_str = m.group(1) except IndexError: self.user_did_not_specify_group1__ERROR = True return try: key_with_correct_type = self.key_transform(g1_str) except ValueError: self.key_did_not_match_specified_type__ERROR = True self.user_line_num_of_error = line_num_of_match + 1 return line_content = editor.getLine(line_num_of_match).rstrip('\n\r') tup = (key_with_correct_type, line_content) self.key_and_line_content_tup_list.append(tup) def option_check(self, input_text, option_text): m = re.search(r'\[([^]]+)\] ?{opt}'.format(opt=option_text), input_text) retval = True if m and m.group(1) != ' ' * len(m.group(1)) else False return retval def search_regex_is_invalid_error_msg(self, test_regex): try: # test test_regex for validity editor.research(test_regex, lambda _: None) except RuntimeError as r: return str(r) return '' def mb(self, msg, flags=0, title=''): # a message-box function return notepad.messageBox(msg, title if title else self.this_script_name, flags) def mb_ok_cancel(self, msg, title=''): # returns True(OK) or False(Cancel) okay = notepad.messageBox(msg, title if title else self.this_script_name, MESSAGEBOXFLAGS.OKCANCEL) == MESSAGEBOXFLAGS.RESULTOK return okay def prompt(self, prompt_text, default_text=''): if '\n' not in prompt_text: prompt_text = '\r\n' + prompt_text prompt_text += ':' return notepad.prompt(prompt_text, self.this_script_name, default_text) #------------------------------------------------------------------------------- if __name__ == '__main__': SLWRG1ASK()Maybe some day I’ll come up with a way to sort by arbitrary rearrangements of multiple groups like
\2\L\1\E, but this is fine for now.EDIT: I suppose that sorting by
\2\L\1\Ecould be accomplished by doing the find/replace with\2\L\1\E🤷🤷$0as replacement, then sort however you want, then find/replace^.*🤷🤷with nothing.--
Moderator EDIT (2024-Jan-14): The author of the script has found a fairly serious bug with the code published here for those that use Mac-style or Linux-style line-endings in their files. The logic for Mac and Linux was reversed, and thus if the script was used on one type of file, the line-endings for the opposite type of file could end up in the file after the script is run. This is insidious, because unless one works with visible line-endings turned on, this is likely not noticed. Some detail on the problem is HERE. The script above has been corrected per that instruction. -
 M Mark Olson referenced this topic on
M Mark Olson referenced this topic on
-
One thing I didn’t get around to doing in the script was making it easier on a user to specify a “decimal” key.
It probably would have been simpler for the user to specify a regex such as
key(DECIMAL)rather than, e.g.,key([-+]?[0-9]*\.?[0-9]+).The script code could scan the user supplied regex for “DECIMAL” and replace with the somewhat hard-to-remember regex.
See HERE for the origins of that decimal-number regex.
-
@Alan-Kilborn
Yep, good idea. I just addedNUMBER_RE = r'([-+]?[0-9]*\.?[0-9]+(?:[eE][-+]?\d+)?)' INT_RE = r'([+-]?[0-9]+)'and
user_regex_with_group_1.replace('(INT)', INT_RE).replace('(DECIMAL)', NUMBER_RE)after the regex is assigned but before it’s used.It’s easy to get the basic structure of integer and decimal regexes, but there are way too many edge cases that are too easily forgotten.
-
alright this is my final version based on Alan Kilborn’s suggestions. I will restrain myself from posting any other versions until I have any substantial new improvements
# -*- coding: utf-8 -*- from __future__ import print_function ######################################### # # SortLinesWithRegexGroup1AsSortKey (SLWRG1ASK) # ######################################### # references: # https://community.notepad-plus-plus.org/topic/24325 #------------------------------------------------------------------------------- from Npp import * import inspect import os import re import threading import unicodedata import SendKeys as sk #------------------------------------------------------------------------------- NUMBER_RE = r'([-+]?[0-9]*\.?[0-9]+(?:[eE][-+]?\d+)?)' INT_RE = r'([+-]?[0-9]+)' def ignorecase_culture_invariant(x): return unicodedata.normalize('NFD', x.lower()) class SLWRG1ASK(object): def __init__(self): self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] self.key_and_line_content_tup_list = [] self.matched_line_numbers = set() self.key_did_not_match_specified_type__ERROR = False self.user_did_not_specify_group1__ERROR = False self.not_all_lines_matched__ERROR = False self.last_matched_line_num = None self.user_line_num_of_error = None self.zero_matches_for_regex = True self.key_transform = None self.do_descending_sort = False self.each_line_must_have_regex_group1_key_match = True self.remove_lines_that_dont_match_regex = False self.sort_lines_that_dont_match_to_bottom = False rect_sel_mode = editor.getSelectionMode() in [ SELECTIONMODE.RECTANGLE, SELECTIONMODE.THIN ] if rect_sel_mode or editor.getSelections() > 1: self.mb('Cannot operate on a column selection or multiple selections; aborting!') return if len(editor.getSelText()) == 0: if not self.mb_ok_cancel('No selection active; confirm desire to sort entire file by pressing OK.'): return (search_start_line, search_end_line) = editor.getUserLineSelection() if editor.positionFromLine(search_end_line) == editor.getSelectionEnd(): search_end_line -= 1 num_lines_in_user_sel = search_end_line - search_start_line + 1 if num_lines_in_user_sel < 2: return # if selection only on 1 line, nothing to do; already sorted! user_regex_with_group_1 = '' used_DECIMAL_RE = False while True: user_regex_with_group_1 = self.prompt('Enter regex with group 1 being the sort key.\r\nIf you wish, you can use (INT) to capture an integer or (DECIMAL) to capture a decimal', user_regex_with_group_1) if user_regex_with_group_1 is None: return # user cancel if len(user_regex_with_group_1.strip()) == 0: self.mb('Cannot specify an empty regex! Try again.') continue if '(' not in user_regex_with_group_1: self.mb('Need to specify capture group 1 (as the sort key) in the regex! Try again.') continue regex_err_msg = self.search_regex_is_invalid_error_msg(user_regex_with_group_1) if len(regex_err_msg) > 0: self.mb('Bad regular expression!\r\n\r\n{e}\r\n\r\nTry again.'.format(e=regex_err_msg)) continue used_DECIMAL_RE = '(DECIMAL)' in user_regex_with_group_1 user_regex_with_group_1 = user_regex_with_group_1.replace('(INT)', INT_RE).replace('(DECIMAL)', NUMBER_RE) break while True: threading.Timer(0.25, lambda : sk.SendKeys("{RIGHT}")).start() # clear auto-selection of prompt text when box appears user_options = self.prompt( ' Regex specified: {r}\r\n' 'Choose options by placing 1 x in each group (no need to x to get DEFAULT choice)'.format(r=user_regex_with_group_1), '\r\n'.join([ 'Group 1 transformation: [ ]Integer(DEFAULT) [ {0}]Decimal [ ]String [ ]Ignorecase-cultural'.format(' x'[used_DECIMAL_RE]), 'Sort order: [ ]Ascending(DEFAULT) [ ]Descending', 'Other:', '[ ]Sort-only-if-all-lines-have-group-1-match(DEFAULT)', '[ ]Remove-non-matching-lines', '[ ]Sort-non-matching-lines-to-bottom', ]) ) if user_options is None: return # user cancel if len(user_options.strip()) == 0: self.mb('Cannot specify empty options! Try again.') continue if self.option_check(user_options, 'String'): self.key_transform = str elif self.option_check(user_options, 'Decimal'): self.key_transform = float elif self.option_check(user_options, 'Ignorecase-cultural'): self.key_transform = ignorecase_culture_invariant else: self.key_transform = int self.do_descending_sort = self.option_check(user_options, 'Descending') self.each_line_must_have_regex_group1_key_match = self.option_check(user_options, 'Sort-only-if-all-lines-have-group-1-match') self.remove_lines_that_dont_match_regex = self.option_check(user_options, 'Remove-non-matching-lines') self.sort_lines_that_dont_match_to_bottom = self.option_check(user_options, 'Sort-non-matching-lines-to-bottom') if not (self.remove_lines_that_dont_match_regex or self.sort_lines_that_dont_match_to_bottom): self.each_line_must_have_regex_group1_key_match = True if self.each_line_must_have_regex_group1_key_match + self.remove_lines_that_dont_match_regex + self.sort_lines_that_dont_match_to_bottom > 1: self.mb('Can only specify one way of handling unmatched lines! Try again!') continue break # enforce single-line matching and only get the FIRST match on each line: user_regex_with_group_1 = '(?-s)' + user_regex_with_group_1 + '.*' search_start_pos = editor.positionFromLine(search_start_line) search_end_pos = editor.getLineEndPosition(search_end_line) # special "seeding", in case the very first line of the selection isn't hit: self.last_matched_line_num = search_start_line - 1 editor.research(user_regex_with_group_1, lambda m: self.match_found(m), 0, search_start_pos, search_end_pos) if self.zero_matches_for_regex: self.mb('No lines matched the regex; aborting!') return if self.user_did_not_specify_group1__ERROR: self.mb('No sort key specified (via using capture group 1) in the regex; aborting!') return if self.key_did_not_match_specified_type__ERROR: self.mb('Key data did not match specified type ({t}) on line {L}; aborting!'.format(L=self.user_line_num_of_error, t={ int : 'Integer', float : 'Decimal', str : 'String', ignorecase_culture_invariant: 'String' }[self.key_transform])) return if self.each_line_must_have_regex_group1_key_match and self.not_all_lines_matched__ERROR: self.mb('Not every line in the source data matched the specified regex (first non-matching line was {L}); aborting!'.format(L=self.user_line_num_of_error)) return if len(self.key_and_line_content_tup_list) < 2: self.mb('Nothing (reasonable) found to sort; aborting!') return sorted_line_list = [tup[1] for tup in sorted(self.key_and_line_content_tup_list, reverse=self.do_descending_sort)] if self.matched_line_numbers: first_unmatched_line = search_start_line + len(self.matched_line_numbers) + 1 self.mb('Line numbers {0}-{1} in sorted text were NOT matched.'.format(first_unmatched_line, search_end_line + 1), title='not all lines matched') for line_num in range(search_start_line, search_end_line + 1): if line_num not in self.matched_line_numbers: unmatched_line = editor.getLine(line_num) sorted_line_list.append(unmatched_line.rstrip('\r\n')) eol = ['\r\n', '\r', '\n'][editor.getEOLMode()] doc_len_before = editor.getLength() editor.setSelection(search_end_pos, search_start_pos) editor.replaceSel(eol.join(sorted_line_list)) doc_len_delta = editor.getLength() - doc_len_before # leave sorted text selected: editor.setSelection(search_end_pos + doc_len_delta, search_start_pos) def match_found(self, m): self.zero_matches_for_regex = False # we're already corrupt; don't bother processing further matches after the one where we found the problem if self.user_did_not_specify_group1__ERROR: return if self.key_did_not_match_specified_type__ERROR: return if self.not_all_lines_matched__ERROR: return (start_pos_of_match, end_pos_of_match) = m.span(0) line_num_of_match = editor.lineFromPosition(start_pos_of_match) if line_num_of_match != self.last_matched_line_num + 1: if self.each_line_must_have_regex_group1_key_match: self.not_all_lines_matched__ERROR = True system_line_num_of_err = self.last_matched_line_num + 1 self.user_line_num_of_error = system_line_num_of_err + 1 return self.last_matched_line_num = line_num_of_match if self.sort_lines_that_dont_match_to_bottom: self.matched_line_numbers.add(line_num_of_match) try: g1_str = m.group(1) except IndexError: self.user_did_not_specify_group1__ERROR = True return try: key_with_correct_type = self.key_transform(g1_str) except ValueError: self.key_did_not_match_specified_type__ERROR = True self.user_line_num_of_error = line_num_of_match + 1 return line_content = editor.getLine(line_num_of_match).rstrip('\n\r') tup = (key_with_correct_type, line_content) self.key_and_line_content_tup_list.append(tup) def option_check(self, input_text, option_text): m = re.search(r'\[([^]]+)\] ?{opt}'.format(opt=option_text), input_text) retval = True if m and m.group(1) != ' ' * len(m.group(1)) else False return retval def search_regex_is_invalid_error_msg(self, test_regex): try: # test test_regex for validity editor.research(test_regex, lambda _: None) except RuntimeError as r: return str(r) return '' def mb(self, msg, flags=0, title=''): # a message-box function return notepad.messageBox(msg, title if title else self.this_script_name, flags) def mb_ok_cancel(self, msg, title=''): # returns True(OK) or False(Cancel) okay = notepad.messageBox(msg, title if title else self.this_script_name, MESSAGEBOXFLAGS.OKCANCEL) == MESSAGEBOXFLAGS.RESULTOK return okay def prompt(self, prompt_text, default_text=''): if '\n' not in prompt_text: prompt_text = '\r\n' + prompt_text prompt_text += ':' return notepad.prompt(prompt_text, self.this_script_name, default_text) #------------------------------------------------------------------------------- if __name__ == '__main__': SLWRG1ASK()--
Moderator EDIT (2024-Jan-14): The author of the script has found a fairly serious bug with the code published here for those that use Mac-style or Linux-style line-endings in their files. The logic for Mac and Linux was reversed, and thus if the script was used on one type of file, the line-endings for the opposite type of file could end up in the file after the script is run. This is insidious, because unless one works with visible line-endings turned on, this is likely not noticed. Some detail on the problem is HERE. The script above has been corrected per that instruction. -
M Mark Olson referenced this topic on
-
A Alan Kilborn referenced this topic on
-
@Mark-Olson
I discovered that my previous implementation of normalized case-insensitive text wasn’t quite right.I can’t edit my last post, but the function
ignorecase_culture_invariantshould be replaced with this:def ignorecase_culture_invariant(x): return unicodedata.normalize('NFD', x.upper())The previous implementation (using
x.lower()) doesn’t work for German ß, and there are probably some other places where it fails. -
A Alan Kilborn referenced this topic on
-
Well, I said I would wait to post again until I had a significant improvement, and I believe I do.
I have now updated the script so it can sort multi-line blocks, for example, sorting a bunch of multi-line XML elements by some attribute.
Normally the only way to sort multi-line blocks is to do the following:
- use a regex that replaces all the newlines in each block with some delimiter that is not present in the file while preserving newlines outside the block.
- Sort the lines of the document using the above script or one of the built-in sorts
- replace the delimiter with newlines.
This process is annoying, so I decided to automate it.
Behold!
# -*- coding: utf-8 -*- from __future__ import print_function ######################################### # # SortLinesWithRegexGroup1AsSortKey (SLWRG1ASK) # ######################################### # references: # https://community.notepad-plus-plus.org/topic/24325 #------------------------------------------------------------------------------- from Npp import * import inspect import os import re import threading import unicodedata import SendKeys as sk #------------------------------------------------------------------------------- NUMBER_RE = r'([-+]?[0-9]*\.?[0-9]+(?:[eE][-+]?\d+)?)' INT_RE = r'([+-]?[0-9]+)' def ignorecase_culture_invariant(x): return unicodedata.normalize('NFD', x.upper()) class SLWRG1ASK(object): def __init__(self): self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] self.key_and_line_content_tup_list = [] self.matched_line_numbers = set() self.key_did_not_match_specified_type__ERROR = False self.user_did_not_specify_group1__ERROR = False self.not_all_lines_matched__ERROR = False self.last_matched_line_num = None self.user_line_num_of_error = None self.zero_matches_for_regex = True self.key_transform = None self.do_descending_sort = False self.each_line_must_have_regex_group1_key_match = True self.remove_lines_that_dont_match_regex = False self.sort_lines_that_dont_match_to_bottom = False self.multiline = False self.multiline_block_delim = '' self.eol = [ '\r\n', '\r', '\n' ][ editor.getEOLMode() ] rect_sel_mode = editor.getSelectionMode() in [ SELECTIONMODE.RECTANGLE, SELECTIONMODE.THIN ] if rect_sel_mode or editor.getSelections() > 1: self.mb('Cannot operate on a column selection or multiple selections; aborting!') return if len(editor.getSelText()) == 0: if not self.mb_ok_cancel('No selection active; confirm desire to sort entire file by pressing OK.'): return (search_start_line, search_end_line) = editor.getUserLineSelection() if editor.positionFromLine(search_end_line) == editor.getSelectionEnd(): search_end_line -= 1 num_lines_in_user_sel = search_end_line - search_start_line + 1 if num_lines_in_user_sel < 2: return # if selection only on 1 line, nothing to do; already sorted! user_regex_with_group_1 = '' used_DECIMAL_RE = False while True: user_regex_with_group_1 = self.prompt('Enter regex with group 1 being the sort key.\r\nIf you wish, you can use (INT) to capture an integer or (DECIMAL) to capture a decimal', user_regex_with_group_1) if user_regex_with_group_1 is None: return # user cancel if len(user_regex_with_group_1.strip()) == 0: self.mb('Cannot specify an empty regex! Try again.') continue if '(' not in user_regex_with_group_1: self.mb('Need to specify capture group 1 (as the sort key) in the regex! Try again.') continue regex_err_msg = self.search_regex_is_invalid_error_msg(user_regex_with_group_1) if len(regex_err_msg) > 0: self.mb('Bad regular expression!\r\n\r\n{e}\r\n\r\nTry again.'.format(e=regex_err_msg)) continue used_DECIMAL_RE = '(DECIMAL)' in user_regex_with_group_1 user_regex_with_group_1 = user_regex_with_group_1.replace('(INT)', INT_RE).replace('(DECIMAL)', NUMBER_RE) break while True: threading.Timer(0.25, lambda : sk.SendKeys("{RIGHT}")).start() # clear auto-selection of prompt text when box appears user_options = self.prompt( ' Regex specified: {r}\r\n' 'Choose options by placing 1 x in each group (no need to x to get DEFAULT choice)'.format(r=user_regex_with_group_1), '\r\n'.join([ 'Group 1 transformation: [ ]Integer(DEFAULT) [ {0}]Decimal [ ]String [ ]Ignorecase-cultural'.format(' x'[used_DECIMAL_RE]), 'Sort order: [ ]Ascending(DEFAULT) [ ]Descending', 'Other:', '[ ]Sort-only-if-all-lines-have-group-1-match(DEFAULT)', '[ ]Remove-non-matching-lines', '[ ]Sort-non-matching-lines-to-bottom', '[ ]Multi-line-blocks', ]) ) if user_options is None: return # user cancel if len(user_options.strip()) == 0: self.mb('Cannot specify empty options! Try again.') continue if self.option_check(user_options, 'String'): self.key_transform = str elif self.option_check(user_options, 'Decimal'): self.key_transform = float elif self.option_check(user_options, 'Ignorecase-cultural'): self.key_transform = ignorecase_culture_invariant else: self.key_transform = int self.do_descending_sort = self.option_check(user_options, 'Descending') self.each_line_must_have_regex_group1_key_match = self.option_check(user_options, 'Sort-only-if-all-lines-have-group-1-match') self.remove_lines_that_dont_match_regex = self.option_check(user_options, 'Remove-non-matching-lines') self.sort_lines_that_dont_match_to_bottom = self.option_check(user_options, 'Sort-non-matching-lines-to-bottom') self.multiline = self.option_check(user_options, 'Multi-line') if not (self.remove_lines_that_dont_match_regex or self.sort_lines_that_dont_match_to_bottom): self.each_line_must_have_regex_group1_key_match = True if self.each_line_must_have_regex_group1_key_match + self.remove_lines_that_dont_match_regex + self.sort_lines_that_dont_match_to_bottom > 1: self.mb('Can only specify one way of handling unmatched lines! Try again!') continue break search_start_pos = editor.positionFromLine(search_start_line) search_end_pos = editor.getLineEndPosition(search_end_line) if self.multiline: # find a character (or multi-char sequence) that is not in the document delim = 1 delim_len = 1 allText = editor.getRangePointer(search_start_pos, search_end_pos) while True: # consider only NUL, SOH, STX, ETX, EOT, ENQ, ACK, BEL delim = delim % 8 if delim == 0: delim += 1 delim_str = chr(delim) * delim_len if delim_str not in allText: self.multiline_block_delim = delim_str break else: delim += 1 delim_len += 1 else: # enforce single-line matching and only get the FIRST match on each line: user_regex_with_group_1 = '(?-s)' + user_regex_with_group_1 + '.*' # special "seeding", in case the very first line of the selection isn't hit: self.last_matched_line_num = search_start_line - 1 editor.research(user_regex_with_group_1, lambda m: self.match_found(m), 0, search_start_pos, search_end_pos) if self.zero_matches_for_regex: self.mb('No lines matched the regex; aborting!') return if self.user_did_not_specify_group1__ERROR: self.mb('No sort key specified (via using capture group 1) in the regex; aborting!') return if self.key_did_not_match_specified_type__ERROR: self.mb('Key data did not match specified type ({t}) on line {L}; aborting!'.format(L=self.user_line_num_of_error, t={ int : 'Integer', float : 'Decimal', str : 'String', ignorecase_culture_invariant: 'String' }[self.key_transform])) return if self.each_line_must_have_regex_group1_key_match and self.not_all_lines_matched__ERROR: self.mb('Not every line in the source data matched the specified regex (first non-matching line was {L}) OR there were multiple matches in at least one line; aborting!'.format(L=self.user_line_num_of_error)) return if len(self.key_and_line_content_tup_list) < 2: self.mb('Nothing (reasonable) found to sort; aborting!') return sorted_line_list = [tup[1] for tup in sorted(self.key_and_line_content_tup_list, reverse=self.do_descending_sort)] if self.multiline: sorted_line_list = [x.replace(self.multiline_block_delim, self.eol) for x in sorted_line_list] elif self.matched_line_numbers: first_unmatched_line = search_start_line + len(self.matched_line_numbers) + 1 self.mb('Line numbers {0}-{1} in sorted text were NOT matched.'.format(first_unmatched_line, search_end_line + 1), title='not all lines matched') for line_num in range(search_start_line, search_end_line + 1): if line_num not in self.matched_line_numbers: unmatched_line = editor.getLine(line_num) sorted_line_list.append(unmatched_line.rstrip('\r\n')) doc_len_before = editor.getLength() editor.setSelection(search_end_pos, search_start_pos) editor.replaceSel(self.eol.join(sorted_line_list)) doc_len_delta = editor.getLength() - doc_len_before # leave sorted text selected: editor.setSelection(search_end_pos + doc_len_delta, search_start_pos) def match_found(self, m): self.zero_matches_for_regex = False # we're already corrupt; don't bother processing further matches after the one where we found the problem if self.user_did_not_specify_group1__ERROR: return if self.key_did_not_match_specified_type__ERROR: return if self.not_all_lines_matched__ERROR: return (start_pos_of_match, end_pos_of_match) = m.span(0) line_num_of_match = editor.lineFromPosition(start_pos_of_match) try: g1_str = m.group(1) except IndexError: self.user_did_not_specify_group1__ERROR = True return try: key_with_correct_type = self.key_transform(g1_str) except ValueError: self.key_did_not_match_specified_type__ERROR = True self.user_line_num_of_error = line_num_of_match + 1 return if self.multiline: line_content = m.group(0).rstrip('\n\r').replace(self.eol, self.multiline_block_delim) else: if line_num_of_match != self.last_matched_line_num + 1: if self.each_line_must_have_regex_group1_key_match: self.not_all_lines_matched__ERROR = True system_line_num_of_err = self.last_matched_line_num + 1 self.user_line_num_of_error = system_line_num_of_err + 1 return self.last_matched_line_num = line_num_of_match if self.sort_lines_that_dont_match_to_bottom: self.matched_line_numbers.add(line_num_of_match) line_content = editor.getLine(line_num_of_match).rstrip('\n\r') tup = (key_with_correct_type, line_content) self.key_and_line_content_tup_list.append(tup) def option_check(self, input_text, option_text): m = re.search(r'\\[([^]]+)\\] ?{opt}'.format(opt=option_text), input_text) retval = True if m and m.group(1) != ' ' * len(m.group(1)) else False return retval def search_regex_is_invalid_error_msg(self, test_regex): try: # test test_regex for validity editor.research(test_regex, lambda _: None) except RuntimeError as r: return str(r) return '' def mb(self, msg, flags=0, title=''): # a message-box function return notepad.messageBox(msg, title if title else self.this_script_name, flags) def mb_ok_cancel(self, msg, title=''): # returns True(OK) or False(Cancel) okay = notepad.messageBox(msg, title if title else self.this_script_name, MESSAGEBOXFLAGS.OKCANCEL) == MESSAGEBOXFLAGS.RESULTOK return okay def prompt(self, prompt_text, default_text=''): if '\n' not in prompt_text: prompt_text = '\r\n' + prompt_text prompt_text += ':' return notepad.prompt(prompt_text, self.this_script_name, default_text) #------------------------------------------------------------------------------- if __name__ == '__main__': SLWRG1ASK()EXAMPLE: sorting the functions in a Python file
def foo(a) -> ruon: fdnfoen eorjerjeon if neoren: eorneor for orneor in reiroewh: orneroej def xjorneo(zser): ornero("defoorne") def zargothrax(rinonrururr: int, bozo: float, defrnore: rourno) -> ziiron: oerjjeorno def bar(b, c, d, e): oerneorn erjelrkererei o33n4o3jo3443i3i 043304 343kj3kj def noer(x): fnoerno def uonreorn (x, b, z): ornepronp def barru(rnx): pass def ournoerno (fnorne ): passcan have its functions sorted using the following regex:
(?-si)^def\h+(\w+)\s*\([\w:\s,]+?\)\s*(?:->[^:]+)?:(?:.+$|\h*\R(?:\x20+.*\R?)+)and the following options selected:Group 1 transformation: [ ]Integer(DEFAULT) [ ]Decimal [ ]String [ x]Ignorecase-cultural Sort order: [ ]Ascending(DEFAULT) [ ]Descending Other: [ ]Sort-only-if-all-lines-have-group-1-match(DEFAULT) [ ]Remove-non-matching-lines [ ]Sort-non-matching-lines-to-bottom [ x ]Multi-line-blocks -
M Mark Olson referenced this topic on
-
M Mark Olson referenced this topic on
-
@Mark-Olson said in How i can sort number from largest to smallest on notepad++:
(?-si)^def\h+(\w+)\s*([\w:\s,]+?)\s*(?:->[^:]+)?:(?:.+$|\h*\R(?:\x20+.*\R?)+)
I see that you use
\h,\sand\x20for a space in one and the same regex. Is there a deeper reason for that? Or is it didactic in that you want to point out that there are more possibilities for a space? -
@Paul-Wormer said in How i can sort number from largest to smallest on notepad++:
I see that you use \h, \s and \x20 for a space in one and the same regex. Is there a deeper reason for that?
Yes, there are reasons for all of those decisions:
\hbetweendefand the name of the function because they must be on the same line but (I believe) there can be arbitrary spacing between them\sin the region containing the arguments because the arguments can be separated by arbitrary whitespace\x20because I’m assuming that the function is indented by spaces.
-
@Mark-Olson OK, that is clear. Thank you for the explanation.
-
M Mark Olson referenced this topic on
-
If you’ve used a script in this thread, you might want to double check your copy of it for a bug I’ve discovered.
Look to previous postings in this topic thread where the script has been changed – find the textmoderator edit (2024-Jan-14).
There’s a link there that describes the bug in more detail, and shows what needs to be changed in an old copy (or you can simply grab a copy of the current version).
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login