Proposed FAQ explaining why you shouldn't parse JSON with regex

-
It seems like there are a lot of people who want to use regular expressions to parse JSON. This is a dangerous trap for reasons that I will explain below, and we could use an FAQ to warn about this.
Here’s my first draft of this FAQ, below the two lines.
You are likely reading this FAQ because you are trying to use regular expressions to work with JSON, and someone wants to explain why this is a bad idea to you. And it is a very bad idea to parse JSON with regular expressions, as you may have already discovered at the cost of hours of frustration and dead-ends. A normal programming language (e.g., Python, JavaScript) is the proper way to work with JSON.
Before I begin the FAQ, I should probably dispense with perhaps the most common objection to using anything other than regex to parse JSON.
But I’m not a programmer, and I don’t want to become one!
Fair enough. But whether you like it or not, JSON was designed by programmers for programmers, and if you’re working with JSON, it behooves you to learn to think like a programmer.
Python and JavaScript are both easier than you might think, and both languages are excellent tools for working with JSON. You don’t need to become an expert to get a lot of benefit from knowing programming.
But I’m not smart enough to become a programmer!
Oh really? Look at this regular expression below to get a feel for what a relatively simple (not to mention easily broken) regular expression for parsing JSON looks like.
(?-i)(?:(?<group1>(?-s).+)(?<group2>(?s).+?-{10}.+?"name" : )"[^"]+")|(?:\R+-{10}\R)If you are smart enough to understand the above regular expression, you are almost certainly smart enough to understand simple programs in Python or JavaScript.
I personally took much longer to get comfortable enough with regular expressions to understand that regex than I took to get comfortable enough with Python to write a program that could solve the same problem that the regex above was trying to solve. If you can understand this regex and modify it to your needs after only a few hours of reading, congratulations, you’re likely smarter than Mark Olson, the writer of this FAQ.
Even though I’m smart enough to learn how to program, I (don’t want to/don’t have time to/have some other reason)
Fair enough. You can still stick around for the rest of the FAQ if you want, but it’s not really directed at you.
Some terminology:
[1, 2, 3]is an array.- the numbers in this array are interchangeably referred to as its elements or its children.
{"foo": 1, "bar": 2}is an object.fooandbarare the keys and1and2are the values.- For simplicity, the child of key
keyin an object is also referred to as thekeyfield of that object.
For other terminology, see the official JSON specification.
Beginning of the reasons why you shouldn’t parse JSON with regex
For the purposes of this tutorial/rant/discussion, I will be working with this simple JSON document.
[ { "department": 1, "name": "foo", "employees": [ {"age": 23.5, "name": "Bob", "favorite_ascii_chars": "A{\""}, {"age": 41.75, "favorite_ascii_chars": "Q]\\", "name": "Amy"} ] }, { "department": 2, "employees": [{"name": "Mike", "age": 46.0, "favorite_ascii_chars": "}*:"}], "name": "bar" }, { "employees": [ {"age": 25.0, "favorite_ascii_chars": "\\h'", "name": "Alex"}, {"age": 24.0, "favorite_ascii_chars": "b\\\"", "name": "Sam"} ], "department": 3, "name": "baz" } ]and the question we want to answer is what are the names and departments of the employees whose names begin with a letter before
Min the alphabet?By the way, this is not a challenge for the regex gurus out there. If you really want to try to solve this problem using regex, then fine. But I am explicitly urging you not to do this.
All whitespace (except inside strings) is insignificant
Self-explanatory. But it means that your regex needs to be littered with
\s*to deal with this fact.The order of keys in a JSON object is not syntactically important, but regular expressions care quite a lot.
You may notice that this document’s
employeeobjects (children of theemployeesfield of thedepartmentobjects) all have three keys:age, a number.name, a string.favorite_ascii_chars, a string.
You may also notice that these two employee objects have the keys in different orders
{"age": 23.5, "name": "Bob", "favorite_ascii_chars": "A{\""}
{"age": 41.75, "favorite_ascii_chars": "Q]\\", "name": "Amy"}Pretty much every JSON parser under the sun does not care about the order of these keys, so your regular expression needs to work whether the key you care about is in the beginning, middle, or end of the object.
JSON strings are trickier to parse with regular expressions than you think
I speak from experience.
Your first instinct is probably to do something like
"[^"]*"but this is wrong, because you need to consider literal quote characters (which are escaped with\), and it also forgets that you can’t include CR or LF in strings.So you try
"(?:\\"|[^"\r\n])*"but this is also wrong, because it doesn’t correctly reflect the fact that the opening and closing quotes can’t be escaped.So now you try
(?<!\\)"(?:\\"|[^"\r\n])*(?<!\\)"but even this is wrong, because you forgot the possibility of literal\just before the close"of the string. That delightful little corner case is in my example, on the 7th line.Long story short, the only regular expression I think is reasonably close to correct is
(?<!(?<!\\)\\)"(?:\\\\|\\"|[^"\r\n])*(?<!(?<!\\)\\)"and I hope you’ll agree that the fact that our regular expression already contains a negative lookbehind inside a negative lookbehind does not bode well for our project of parsing JSON with regular expressions.By the way, even that regular expression doesn’t cover other even more obnoxious corner cases, and I have better things to do than enhance it to cover them.
You will forget at least one of the above rules at some point, and it will come back to bite you.
If you perfectly internalize every rule you ever learn, and you never forget to apply them where it’s appropriate, then congratulations, you are a much better programmer than I am.
Even before considering the corner cases discussed above, JSON-parsing regular expressions tend to be ugly as sin
Even if you could parse JSON with regular expressions, it is (usually) more efficient to use a JSON parser (warning: technical details ahead)
JSON parsers only need to read a JSON file once to correctly parse it, and while they read some characters multiple times, the amount of time required to parse a file should exhibit linear growth.
By contrast, regular expressions have the potential to read the same text many times, and sometimes the number of times the regex engine reads the document is proportional to the size of the document. This can lead to very bad performance on large documents.
Once a JSON file is parsed, most languages store objects using a data structure called a hashmap, which allows retrieval of the value associated with a key in an amount of time that usually does not depend on the number of keys in the object.
Similarly, parsed arrays allow for random access to elements in an amount of time that does not depend on where the element is in the array. If you do enough random lookups, the time savings can be significant. By contrast, a regular expression needs to scan starting at the top of the array every time it wants to find an element.
-
A good explanation; just one thing missing:
tl;dr: OK, I believe you. I shouldn’t use regular expressions to search or edit JSON. What can I use instead?
I know you said, “a regular programming language,” but probably you could direct readers to JSON Tools, with a quick explanation of where to look for the functions that would do what a person would be trying to do with regular expressions. I haven’t had occasion to use that plugin yet, so I don’t know what the options are, but I’m pretty sure you’ve heard of it. ;-)
-
@Coises
Good suggestion!Here’s my second draft of the FAQ.
It’s mostly the same, except for the
TL;DRsection I added at the beginning and aSpoiler: how to solve the above problem using PythonScript or JsonToolssection at the end.One thing I did in the
Spoiler->PythonScript Solutionsubsection towards the end that I’m not sure about: I deliberately left the actual implementation of the solution in Python blank, because I don’t necessarily want to set a precedent of spoon-feeding solutions to Python scripting problems in this forum. But maybe it’s fine, and I should just include the answer anyway.
You are likely reading this FAQ because you are trying to use regular expressions to work with JSON, and someone wants to explain why this is a bad idea to you. And it is a very bad idea to parse JSON with regular expressions, as you may have already discovered at the cost of hours of frustration and dead-ends. A normal programming language (e.g., Python, JavaScript) is the proper way to work with JSON.
TL;DR: OK, I believe you. I shouldn’t use regex to search in or edit JSON. What can I use instead?
- Python
- Overview: Python is an easy-to-learn language, and its json module makes it easy to work with JSON.
- Plugins: In addition, the PythonScript plugin allows you to run Python scripts inside of Notepad++.
- For example, here is how to parse the current document as JSON, and pretty-print it:
# Npp gives us access to the editor component, which manages # the text, selections, and styling of the current document from Npp import editor # json is the Python standard library module for working with json import json # get the text of the current document text = editor.getText() # try to parse the current document as json (you might get an error here) js = json.loads(text) # display the json in the PythonScript console print(js) # set the text of the current file to the pretty-printed version of the JSON editor.setText(json.dumps(js, indent=4)) - JavaScript
- Overview: JavaScript is another very popular language, but I don’t know as much about it TBH. The
JSON.parseandJSON.stringifyfunctions let you work with JSON. - Plugins: jN (JavaScript for Notepad++) is another plugin, but I know essentially nothing about it
- Overview: JavaScript is another very popular language, but I don’t know as much about it TBH. The
- JsonTools
- Overview: this is a plugin that I wrote. It includes a bunch of stuff, including:
- a scripting tool for editing and viewing JSON
- commands for pretty-printing and compressing JSON
- a parser that can handle JSON with comments and many kinds of errors
- I recommend you read the documentation if you are interested.
- Overview: this is a plugin that I wrote. It includes a bunch of stuff, including:
Please remember that while questions about JsonTools are appropriate for this forum (because it is a Notepad++ plugin), questions about Python or JavaScript should be asked elsewhere (e.g. StackOverflow) unless they are about the PythonScript or jN plugins specifically.
A common objection
Before I begin the FAQ, I should probably dispense with perhaps the most common objection to using anything other than regex to parse JSON.
But I’m not a programmer, and I don’t want to become one!
Fair enough. But whether you like it or not, JSON was designed by programmers for programmers, and if you’re working with JSON, it behooves you to learn to think like a programmer.
Python and JavaScript are both easier than you might think, and both languages are excellent tools for working with JSON. You don’t need to become an expert to get a lot of benefit from knowing programming.
But I’m not smart enough to become a programmer!
Oh really? Look at this regular expression below to get a feel for what a relatively simple (not to mention easily broken) regular expression for parsing JSON looks like.
(?-i)(?:(?<group1>(?-s).+)(?<group2>(?s).+?-{10}.+?"name" : )"[^"]+")|(?:\R+-{10}\R)If you are smart enough to understand the above regular expression, you are almost certainly smart enough to understand simple programs in Python or JavaScript.
I personally took much longer to get comfortable enough with regular expressions to understand that regex than I took to get comfortable enough with Python to write a program that could solve the same problem that the regex above was trying to solve. If you can understand this regex and modify it to your needs after only a few hours of reading, congratulations, you’re likely smarter than Mark Olson, the writer of this FAQ.
Even though I’m smart enough to learn how to program, I (don’t want to/don’t have time to/have some other reason)
Fair enough. You can still stick around for the rest of the FAQ if you want, but it’s not really directed at you.
Some terminology:
[1, 2, 3]is an array.- the numbers in this array are interchangeably referred to as its elements or its children.
{"foo": 1, "bar": 2}is an object.fooandbarare the keys and1and2are the values.- For simplicity, the child of key
keyin an object is also referred to as thekeyfield of that object.
For other terminology, see the official JSON specification.
Beginning of the reasons why you shouldn’t parse JSON with regex
For the purposes of this tutorial/rant/discussion, I will be working with this simple JSON document.
[ { "department": 1, "name": "foo", "employees": [ {"age": 23.5, "name": "Bob", "favorite_ascii_chars": "A{\""}, {"age": 41.75, "favorite_ascii_chars": "Q]\\", "name": "Amy"} ] }, { "department": 2, "employees": [{"name": "Mike", "age": 46.0, "favorite_ascii_chars": "}*:"}], "name": "bar" }, { "employees": [ {"age": 25.0, "favorite_ascii_chars": "\\h'", "name": "Alex"}, {"age": 24.0, "favorite_ascii_chars": "b\\\"", "name": "Sam"} ], "department": 3, "name": "baz" } ]and the question we want to answer is what are the names and departments of the employees whose names begin with a letter before
Min the alphabet?By the way, this is not a challenge for the regex gurus out there. If you really want to try to solve this problem using regex, then fine. But I am explicitly urging you not to do this.
All whitespace (except inside strings) is insignificant
Self-explanatory. But it means that your regex needs to be littered with
\s*to deal with this fact.The order of keys in a JSON object is not syntactically important, but regular expressions care quite a lot.
You may notice that this document’s
employeeobjects (children of theemployeesfield of thedepartmentobjects) all have three keys:age, a number.name, a string.favorite_ascii_chars, a string.
You may also notice that these two employee objects have the keys in different orders
{"age": 23.5, "name": "Bob", "favorite_ascii_chars": "A{\""}
{"age": 41.75, "favorite_ascii_chars": "Q]\\", "name": "Amy"}Pretty much every JSON parser under the sun does not care about the order of these keys, so your regular expression needs to work whether the key you care about is in the beginning, middle, or end of the object.
JSON strings are trickier to parse with regular expressions than you think
I speak from experience.
Your first instinct is probably to do something like
"[^"]*"but this is wrong, because you need to consider literal quote characters (which are escaped with\), and it also forgets that you can’t include CR or LF in strings.So you try
"(?:\\"|[^"\r\n])*"but this is also wrong, because it doesn’t correctly reflect the fact that the opening and closing quotes can’t be escaped.So now you try
(?<!\\)"(?:\\"|[^"\r\n])*(?<!\\)"but even this is wrong, because you forgot the possibility of literal\just before the close"of the string. That delightful little corner case is in my example, on the 7th line.Long story short, the only regular expression I think is reasonably close to correct is
(?<!(?<!\\)\\)"(?:\\\\|\\"|[^"\r\n])*(?<!(?<!\\)\\)"and I hope you’ll agree that the fact that our regular expression already contains a negative lookbehind inside a negative lookbehind does not bode well for our project of parsing JSON with regular expressions.By the way, even that regular expression doesn’t cover other even more obnoxious corner cases, and I have better things to do than enhance it to cover them.
You will forget at least one of the above rules at some point, and it will come back to bite you.
If you perfectly internalize every rule you ever learn, and you never forget to apply them where it’s appropriate, then congratulations, you are a much better programmer than I am.
Even before considering the corner cases discussed above, JSON-parsing regular expressions tend to be ugly as sin
Even if you could parse JSON with regular expressions, it is (usually) more efficient to use a JSON parser (warning: technical details ahead)
JSON parsers only need to read a JSON file once to correctly parse it, and while they read some characters multiple times, the amount of time required to parse a file should exhibit linear growth.
By contrast, regular expressions have the potential to read the same text many times, and sometimes the number of times the regex engine reads the document is proportional to the size of the document. This can lead to very bad performance on large documents.
Once a JSON file is parsed, most languages store objects using a data structure called a hashmap, which allows retrieval of the value associated with a key in an amount of time that usually does not depend on the number of keys in the object.
Similarly, parsed arrays allow for random access to elements in an amount of time that does not depend on where the element is in the array. If you do enough random lookups, the time savings can be significant. By contrast, a regular expression needs to scan starting at the top of the array every time it wants to find an element.
Spoiler: how to solve the above problem using PythonScript or JsonTools
One way to answer this problem using JSON is as follows:
[ {"dept": 1, "emp_names": ["Bob", "Amy"]}, {"dept": 2, "emp_names": []}, {"dept": 3, "emp_names": ["Alex"]} ]Essentially, we get an array of objects where the
deptfield is a department number and theemp_namesfield is a list of names of employees in that department whose names begin with a letter beforeMin the alphabet.Solution using PythonScript
- save the following script in the
%AppData%\Roaming\Notepad++\plugins\config\PythonScript\scriptsfolder. Call itdont_parse_json_with_regex_FAQ.py.
# get access to the editor (text of current doc) and notepad (file manager) from Npp import editor, notepad # get the standard Python JSON library (https://docs.python.org/3/library/json.html) import json # get the standard Python regex library (https://docs.python.org/3/library/re.html) import re # TODO (not shown here because it is not Notepad++ - specific) # 1. read the documentation for json and re # 2. figure out how to solve this problem # 3. Save the answer to a variable named dept_empnames # create a new file notepad.new() # dump the pretty-printed json in the new file new_json_str = json.dumps(dept_empnames, indent=4) editor.setText(new_json_str)- open the file containing the JSON example above.
- Click on
Plugins->PythonScript->scripts->dont_parse_json_with_regex_FAQ - A new file will open containing the JSON answer shown above (formatted a bit differently)
Solution using JsonTools
- go to
Plugins->JsonTools->Open JSON tree viewerand a tree view will appear for the document. Explore it to get a feel for how it works. - Enter the query
@[:]{dept: @.department, emp_names: @.employees[:].name[@ =~ `^(?i)[A-L]`]}in the text box above the tree view.- See the RemesPath docs for information about the syntax of this query.
- The key thing to understand about RemesPath is the way the
@symbol represents the “current JSON”. - Initially, the “current JSON” is the document.
- However, inside of
{dept: @.department, emp_names: @.employees...},@instead refers to each department object in the original JSON document., because it comes after@[:], which iterates through an array. - Next we get the
employeesfield (@.employees) of the current JSON (which is now a department object) - Next we want to get the
namefield of each employee object in the current JSON (which is now an array of employee objects). This is represented by appending[:].nameto the subquery of step 5. - Next we want to test if each employee name (which is now the current JSON) starts with a letter from A-L (case-insensitive). This is done by appending
[@ =~ `^(?i)[A-L]`]to the subquery of steps 5-6. - So, to combine steps 5-7, if we want to get the
namefield (but only if it starts with a letter from A-L) of each employee object in theemployeesfield of each department object, we have the subquery@.employees[:].name[@ =~ `^(?i)[A-L]`] - The
{dept: <something1>, emp_names: <something2>}syntax creates an object that mapsdepttosomething1(which could be a function of input, a number, or whatever) andemp_namestosomething2(which could also be anything) - Putting it all together, the query we use to get the answer we want is
@[:]{dept: @.department, emp_names: @.employees[:].name[@ =~ `^(?i)[A-L]`]}
- Click the
Save query resultbutton above the tree view. - A new document should appear containing the JSON answer above.
Summary of the different approaches
As you can see, JsonTools and PythonScript offer two very different approaches to this problem.
- PythonScript is an extremely flexible general-purpose tool, and as such it takes a bit more setup to solve this problem with it. However, you can go further in the long run with knowledge of Python.
- JsonTools is a fast, domain-specific and (hopefully) user-friendly tool, and JSON queries written in JsonTools tend to require a lot fewer lines of code than the same query written in Python. However, RemesPath is much more likely to have bugs than Python (please let Mark Olson know if you find one), and its error messages may sometimes be cryptic.
- Python
-
It’s looking good to me.
When you’re ready, you could create a new post in the Blogs section, and then ask me here to move it into the FAQ section for you. Or you could just reply here that you want it as it is in your most-recent post, and I can copy that and create the new Topic in the FAQ section and change the owner to you.
As far as maintaining it goes, you’ll only have edit permission for the same few hours that are allowed with normal posts. So I think the best would be for you to set up a gist on GitHub, or put it in a folder of some other GitHub repo that you control (or any other preferred publically-facing repo system), and then when you update that you could direct-message me, and I could take the contents from there and update the FAQ. Or, if you wanted, I could add a file to the same GitHub repo/directory where I store most of the other active FAQ content – and if you wanted to update the contents, you could do a PR for that file (and me handling the PR would obviously also prompt me to merge the contents into the actual FAQ).
So let me know when you’re ready for it to be added to the FAQ section
-
-
@Mark-Olson said,
Great!
FAQ entry created.
I added a brief corollary (I hope you don’t mind).
update: I have subscribed to that gist, so when you update it, I believe GitHub will notify me automatically; if you make a change to the gist that doesn’t get reflected here within a day or so, you might want to ping me in Chat to make sure I noticed it.
-
Many of the reasons for not using regex to parse JSON also apply to HTML. I don’t know if it would help or hurt to generalize the FAQ entry to include HTML.
One other item for why it’s bad is that Notepad++'s regex is not as graceful or agile at processing Unicode characters U+10000 to U+10FFFF. This region used to be obscure, pretty much never used, or seen, stuff but with the introduction and then expansion of U+1F300 to U+1F5FF Miscellaneous Symbols and Pictographs plus U+1F600 to U+1F64F emoticons these characters are now regularly showing up in HTML and JSON.
-
@mkupper said in Proposed FAQ explaining why you shouldn't parse JSON with regex:
Many of the reasons for not using regex to parse JSON also apply to HTML
Hence my corollary. 😉
-
For what it is worth JSON is an acronym for JavaScript Object Notation. If you have programmed a bit in Javascript, it’s quite easy to understand JSON.
As to why you shouldn’t parse HTML with regex: https://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags#1732454
-
@mkupper said in Proposed FAQ explaining why you shouldn't parse JSON with regex:
Many of the reasons for not using regex to parse JSON also apply to HTML
Strongly agree. For the lulz, I also recommend changing the corollary post to link to this StackOverflow post, which is easily my favorite help forum post of all time.
Wouldn’t hurt to mention the XMLTools plugin in the corollary either.
-
Strongly agree. For the lulz, I also recommend changing the corollary post to link to this StackOverflow post, which is easily my favorite help forum post of all time.
Wouldn’t hurt to mention the XMLTools plugin in the corollary either.
Done and done. (Like @ThosRTanner , I actually linked to the reply rather than the question on SO, because it’s the important part for the reader to be directed to.)
-
@Mark-Olson said in Proposed FAQ explaining why you shouldn't parse JSON with regex:
It seems like there are a lot of people who want to use regular expressions to parse JSON. This is a dangerous trap for reasons that I will explain below
Following on from the recent post here regarding updating one JSON file with a particular field from another (so a partial merge process) and the resulting question about whether regex was appropriate or a Python (or other programming language) was more appropriate I went in search of an answer that satisfied me, I still haven’t found it. Lots of posts about it “being a bad idea” but I cannot find any substance to back it up. Maybe we’ve been lucky on this forum that the JSON queries are from simply structured JSON files which are likely to come to no harm from using regex, or maybe the OP goes away in disgust at us having wrecked his data (all solutions come with a caveat!), never to darken our (forum) door again.
But what I did find was a number of apps (modules) that have already been created and they are designed to work across many JSON structures. Unfortunately it will still require those who wish to use them a learning curve so they can utilise these apps. Possibly that learning curve is still flatter than learning a new programming language.
An interesting one was this on github, called jsonmerge. It’s a Python module. The licence states it is free for anyone to copy, modify etc etc. Maybe @Mark-Olson might be interested since he’s the author of JSONTools for NPP. Could we possibly see JSONTools enhanced in a new version by incorporating this? I think it is worthy of a look.
Of course there are several other free standing apps, any one of which may also be better than dealing with JSON inside of NPP, but that’s not for this forum to ponder.
food for thought
Terry -
TL;DR: as the FAQ says, if you don’t want to learn a scripting language, you are welcome to ignore the FAQ. Just remember that any approach that doesn’t involve a JSON parser will almost certainly take dozens of times longer and more error-prone than a solution that uses a JSON parser.
Every minute wasted debugging a JSON-parsing regex is a minute that could have been spent learning a scripting language. The difference is that a JSON-parsing regex will not generalize from one task to another, but knowledge of a scripting language can be applied to all manner of tasks.
As I hope the FAQ makes clear, I don’t dislike or feel superior to people who want to parse JSON with regex. I just wish they would try a different approach and stop wasting their time. Lord knows I have wasted plenty of time myself (probably more than most other people in this forum) for similar reasons.
Could we possibly see JSONTools enhanced in a new version by incorporating this [JsonMerge]? I think it is worthy of a look.
No, but thanks for the suggestion. JsonTools was implemented in C#, and JsonMerge is Python, so I would have to reimplement all the algorithms in JsonMerge, and I am not a capable enough programmer to do this well.
Maybe we’ve been lucky on this forum that the JSON queries are from simply structured JSON files which are likely to come to no harm from using regex
Yes, exactly. The only reason your regex solutions “work” is that you are getting away with assuming the format is constant. As I note in the FAQ, every regex solution, including many that are so nightmarishly complicated by corner cases as to be impossible to debug, will most likely fail if the format changes (e.g., pretty-printed, keys of an object sorted).
-
@Terry-R said in Proposed FAQ explaining why you shouldn't parse JSON with regex:
But what I did find was a number of apps (modules) that have already been created and they are designed to work across many JSON structures. Unfortunately it will still require those who wish to use them a learning curve so they can utilise these apps. Possibly that learning curve is still flatter than learning a new programming language.
Yes, there seems to be a no-win situation here for this sort of problem:
- I’m working on something that we planned to deploy quickly, but I’m blocked because I need to change this JSON file.
- The change is conceptually simple (at least, it appears so in my mind), but it happens in dozens of places throughout the file, so doing it manually would be tedious, time-consuming and error-prone.
- I can’t even remember the last time I had to do anything much with a JSON file, and I don’t expect to run into this again anytime soon.
- Did I mention we want this sooner rather than later?
For this person, taking time — a few days? a week? more than that? — to learn a new programming language and then debug a script written in that language is absurd. Getting hung up on a long detour for something that is conceptually simple (“I just need to change all the device names of smart light bulbs from xxx to bulb-xxx!”) would be unreasonable. (Even if you were willing to take the time to learn for future use, you still have this problem that needs a solution now.)
It could be that the RemesPath language in JsonTools is quick enough to grasp that it’s practical to learn that even for a one-off problem. (I confess I haven’t yet attempted to understand it.) But I suspect most people in this situation would just hack away with a regex and hope for the best.
It’s too bad there isn’t a low-learning-curve solution for applying regex-style logic to structured data like JSON, XML, HTML, etc.; but based on these discussions, I’m led to believe it doesn’t exist.
-
@Coises said in Proposed FAQ explaining why you shouldn't parse JSON with regex:
It could be that the RemesPath language in JsonTools is quick enough to grasp that it’s practical to learn that even for a one-off problem.
Well… sort of. RemesPath probably could be a lot easier to grasp, and I think it is currently held back by confusing error messages.
JsonTools has a find/replace form, which essentially translates questions along the lines of
I want to find all keys in this JSON that mach the regular expression `.*name`into RemesPath queries.This essentially aims to provide training wheels for learning RemesPath, similar to how the GUI in Microsoft Power Query shows the user the M-script it emits.
I guess an example would be, suppose the user wants to find all the values that start with a word containing the substring
AG(case-insensitive) in thenamefield of any object.The workflow with the find/replace form might go as follows:
- the user wants to recursively search for all keys that match
nameexactly, so they:- check the
Show advanced options->Match exactly?box - leaves
Recursive search?checked. - leaves
Ignore case?unchecked - select the
Keysoption from theSearch in keys or values?dropdown - enter
namein theFind...box.
- check the
- The query emitted by the form says
(@)..`name`, so:- the user looks at the treeview (which will snap to the location of each search result) to see if it found the right values.
- the user copies
..`name`into theRootfield of the find/replace form - puts
^\w*AGinto theFind...field - changes the
Search in keys or values?dropdown toValues - checks
Show advanced options->Ignore case? - unchecks
Show advanced options->Match exactly? - checks *
Show advanced options->Use regular expressions?
and this emits the query
(@..`name`)..*[str(@) =~ g`(?i)^\w*AG`], which will find the desired things.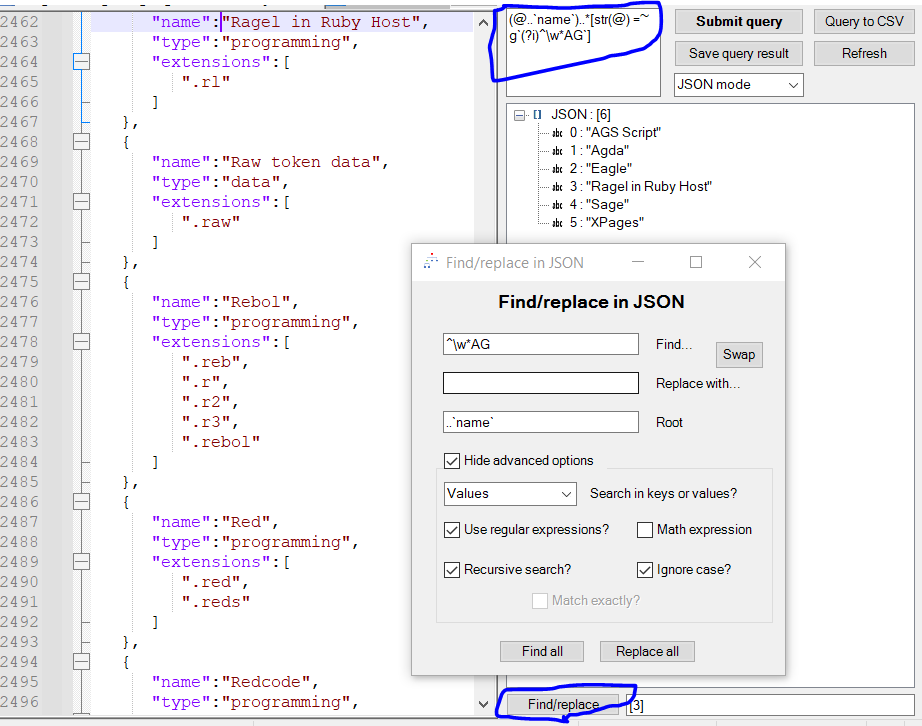
- the user wants to recursively search for all keys that match
-
@Mark-Olson I prefer this quote from 12 Aug 1997:
http://regex.info/blog/2006-09-15/247
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login