Exporting pages from Hits?
-
I’m really unclear on exactly what you want here.
Maybe someone else will understand and offer you some good advice. -
@rjm5959 ,
One thing that’s not clear: is a page a separate file? or is it just a small section of the same file? Because if that’s the case, Notepad++ has no way to know what you define as a page. (And since you told us nothing about how you define a “page”, we cannot be certain, either.)
To be able to do something like that, you’d need to be able to derive (on your own) a regular expression that matches an entire page that contains the given text.
For example, if you were lucky enough to have
START PAGEat the start of each page, andEND PAGEat the end of each page, then you could do something like(?s)START PAGE.*?United Bank.*?END PAGE… Actually, it would probably get more complicated than that…(?s)START PAGE((?!END PAGE).)*?United Bank.*?END PAGE(which makes sure there is no END PAGE before theUnited Bankmatch, so it doesn’t do two pages)with
START PAGE END PAGE START PAGE United Bank END PAGE START PAGE END PAGE… that second expression will just find
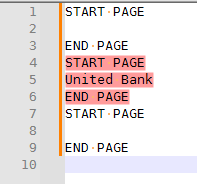
You could then use the Mark tab’s, and then once you had marked each of those pages, you could Copy Marked Text to get each of those pages in the clipboard, and then you could paste them into your new file.
As a second example, if each page ends with a
FF(form feed) character (or the end of the file), you could use a similar idea:blah first page won't match blah [FF] blah second page United Bank will match blah [FF] blah third page won't match blah [FF] blah last page United Bank will match blah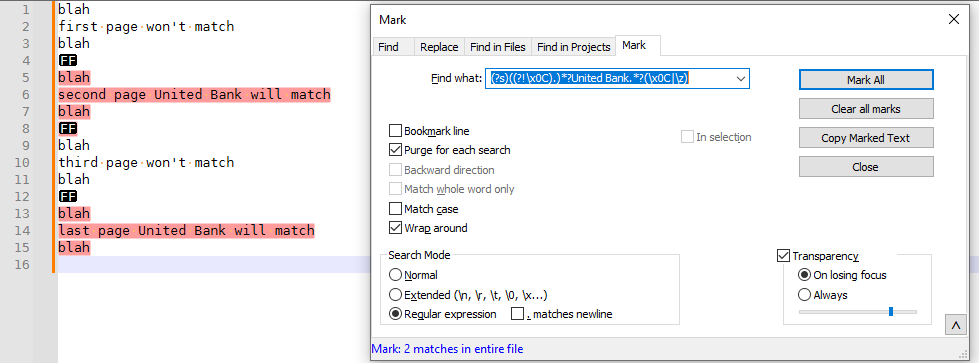
Hopefully that helps. If not, you are going to have to do a much better job of explaining yourself.
-—
Useful References
-
Thanks for the responses. I’ll see if I can do something with what was provided. Basically I’m searching for a string in 1 giant txt file. Below I’m searching United Bank and found 3 hits and each is on a page. Line 59 is on Page 2 as defined in the report with a FormFeed and the data in line 2. For United Bank, it’s easy. There’s 3 entries in the monster report. For Nationstar bank, there’s 89,984 scattered throughout 100’s of thousands of pages. Each Page is 57 lines and I need to extract those 57 lines for each page. Hope this helps. Sorry for the confusion!


-
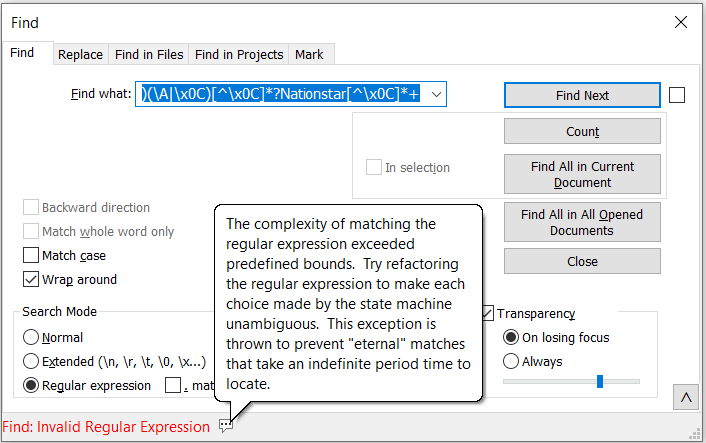
@rjm5959 I tried the below and get the below message. I know that \x0C is for the FormFeed. What am I missing?
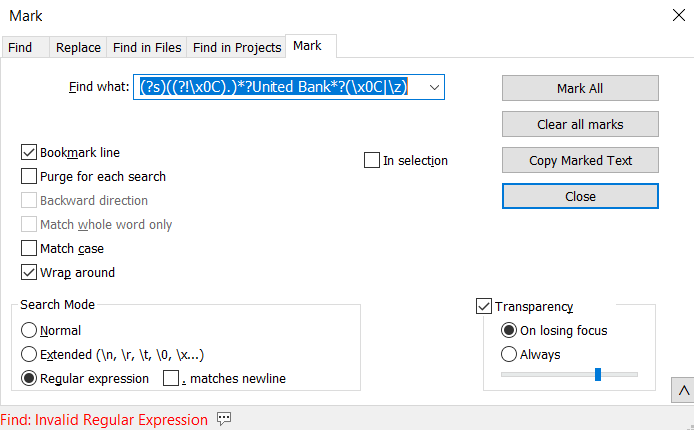
-
@rjm5959 I missed the . in the above. Now it searches ok. I was able to mark and copy the entire page for United Bank using this to Mark: (?s)((?!\x0C).)?United Bank.?(\x0C|\z)
When I use the same thing for Nationstar, I get the below message. What am I missing? Sorry for all the posts. Getting this to work will eliminate a massive headache!!! (?s)((?!\x0C).)?Nationstar.?(\x0C|\z)
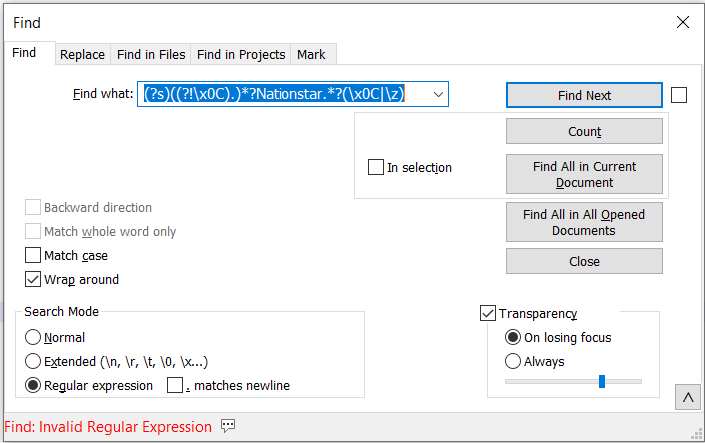
-
@rjm5959 Nationstar pages start with this

-
@rjm5959 said in Exporting pages from Hits?:
@rjm5959 I missed the . in the above. Now it searches ok. I was able to mark and copy the entire page for United Bank using this to Mark: (?s)((?!\x0C).)?United Bank.?(\x0C|\z)
When I use the same thing for Nationstar, I get the below message. What am I missing? Sorry for all the posts. Getting this to work will eliminate a massive headache!!! (?s)((?!\x0C).)?Nationstar.?(\x0C|\z)
If you hover over the callout icon with the three dots to the right of “Find: Invalid Regular Expression” you’ll see a popup that will give more details about the error.
I suspect those details will be words to the effect of “the expression is too complex.” That happens when the routine trying to match the expression to the text determines that it’s taking a great deal of time going over the same text repeatedly, and it might never reach the end.
Instead of
(?s)((?!\x0C).)*?Nationstar.*?(\x0C|\z)try(\A|\x0C)[^\x0C]*?Nationstar[^\x0C]*+and see if that is any better. -
@Coises I get the same thing. This is what that message shows. It’s a massive file. When I do a search to find the first hit of just the word ‘Nationstar’ and then start from the line just before the top of page with ‘FF’ with the commands above, it finds the hit. I can only go 1 find at a time though using ‘Find Next’. I can’t do a massive search. Is there a max limit defined somewhere?
-
@rjm5959 The file I’m searching has 7.7 million lines…
-
@rjm5959 said in Exporting pages from Hits?:
Is there a max limit defined somewhere?
Yes, but not in a way that is useful to end users. Notepad++ relies on the Boost regular expression library. Within that code there is a limit, but it’s expressed in terms of internal data structures meaningful only to that code. It doesn’t translate into anything you can use to guess how much is “too much.”
It’s possible that I or someone else (@guy038, where are you?) will think of a way to write the regular expression that won’t trigger this error, or another way to approach the problem.
-
@Coises Thanks Coises. Appreciate the help!
-
@rjm5959 This might work…
Do this on a copy of your file. Don’t use the original. Something might go wrong.
Find some character that doesn’t appear in your file. Do a search to make sure. Below, I’ll use
@.Using the Replace tab, replace every occurrence of
Nationstarwith@Nationstar. Do that for every string for which you want to save containing pages.Now use the Replace tab to replace every occurrence of
\x0C[^@\x0C]++(?=\x0C)with nothing. That should remove all the pages you don’t want (except the first and last pages — determine if either of those is wanted and if not, delete by hand — I’m keeping the expression as simple as possible, so not allowing for those).Finally, Replace All
@with nothing.You should be left with only the pages of interest.
-
@Coises Thanks. Didn’t seem to work though? I only found that the character ~ was not in the file. All the others were in there? LOL! Ridiculous. I did a replace all and it worked. Hit all 89,984 hits. I did the 2nd replace and it said 84,510 were replaced, but I checked and didn’t look like any were actually replaced? Still had 89,984 with ~Nationstar. Also, I want everything for Nationstar so not sure why I would be removing all those hits?
Also, unfortunately, I need to turn this over to non tech people on a team that will use this every month end on these massive files so I need something fairly simple that they can use. From meetings with them, they were only familiar with Notepad and I had them install Notepad++ which is far better for this type of searching and extracting…
-
@rjm5959 ,
I checked and didn’t look like any were actually replaced? Still had 89,984 with ~Nationstar.
Right, that was the point of @Coises sequence: you make a copy of the file, then you use his sequence to remove everything but the ~Nationstar pages. So all the ~Nationstar instances should be there, but nothing else.
If you’re not sure what’s going on, start with a smaller file (like one that has just 5 Nationstar and 3 United Bank). Once you understand how it’s working (or have a small enough example that you can understand what’s going wrong), then you can move forward (or better be able to debug).
team that will use this every month end on these massive files
You’re trying to use the wrong tool for the job. Instead of trying to post-process the text-file output of whatever database is generating the report that you’re filtering, you should really ask whoever is generating the report to generate it in the right format, so that they can just pass the relevant information to the “team that will use this every month end”. It should never be part of one’s monthly process to take a report from a database and try to filter it further. Databases are great for filtering and generating reports with filtered data; on the other hand, as you’ve seen, it is non-trivial to take the textual report from a database and filter it after the report has already been generated.
However, if you cannot convince your management or the database team to do it the right way…
I need something fairly simple that they can use
If it were searching for just one thing – like “Nationstar” – then I would have suggested a macro, because you can do the whole multi-step search/replace/search/replace/… in one macro, which would be dead simple. Unfortunately, a Macro doesn’t allow input. If there’s a handful of banks to search for, then you could just have a handful of macros that would do it. If there are dozens or hundreds of different filters they need to apply, then beg and plead with management to get the right tools to do your job. If that’s still denied, then the next suggestion would be to write up a script in the PythonScript or similar scripting plugin that would prompt for user input, then perform the search/replace. (But a scripting solution would be harder to get installed for each team member, because you’d have to install the plugin and script for each user… and if you cannot even get the support necessary to have data in the right format to start with, I find it hard to believe you’d be able to easily get the plugin and script installed for each team member.) So if you’ve got a lot of different filters you need to apply, I’m not sure you have a good solution available. Sorry.
-
@PeterJones I’ll try with a smaller piece of the file. Unfortunately there’s no way to get the files filtered from the source. They come from ICE/Black Knight and have 100’s of thousands of entries for many many financial institutions and is used by many teams EOM. Every month there’s several reports and is a different list of Institutions that data is pulled for by this team. If it was the same institutions every month that would be great! I could request that from ICE and be done with this. We ingest the reports into a program called Synergy Reporting. We are able to search quickly and find the data in a few minutes, but exporting all the pages takes many many hours for each institution. Nationstar took 6 hours for just 1 report. Takes about 8 hours total to filter through 4 reports and export. I decided to have ICE send us the reports separately so we can download them to a location and search manually via Notepad, Notepad++, etc…
So much fun!
-
@rjm5959 said in Exporting pages from Hits?:
Also, unfortunately, I need to turn this over to non tech people on a team that will use this every month end on these massive files so I need something fairly simple that they can use. From meetings with them, they were only familiar with Notepad and I had them install Notepad++ which is far better for this type of searching and extracting…
Then — as Peter Jones already said in a different reply — Notepad++ is the wrong tool.
I had assumed this was a one-off, “personal” task. If this is something done by multiple people every month as part of an organization, there is no way around this:
You need to enlist a programmer to automate this task for you. This is not a job for end-users to do with off-the-shelf tools.
The good news is, it’s an easy — almost trivial — programming task. You won’t need a team, or a highly-experienced senior programmer; any competent coder should be able to do this, possibly in a single afternoon. Just be sure you’re clear on what you need and what you want (best to write it down as a requirements document), and that you have one or more real source files available for the programmer to use, before you start.
Then it will take moments of your people’s time, instead of hours, every month. Also, consider this: If you and your organization are willing to spend that much of people’s time every month to do this, it must be important. Doing this manually, repeatedly, will be error-prone. A custom-coded program will let the computer do the repetitive, time-consuming and error-prone part.
-
@Coises said in Exporting pages from Hits?:
lso, consider this: If you and your organization are willing to spend that much of people’s time every month to do this, it must be important.
Moreover, since it was taking at least 8 hours per month, total, then paying a contractor for up to 1 week of time to write the program and make sure it’s working for you would be a net win after a year or less.
-
Thanks guys. I will look into having someone create something for this. They weren’t very receptive when I brought this up previously and that’s why I had the vendor split out these reports separately to download and use. A big part of the issue with slow extraction from Synergy is that Synergy was moved from On Prem to the Azure cloud so that increased the time it takes to extract substantially. I was able to make some changes within Synergy to make the search much faster, but the extraction is still very slow. Not much improvement there. I have a case open for that also. Probably not much that can be done for that either. I was hoping there was a way to get around the limit…
-
Hello @rjm5959, @alan-kilborn, @peterjones, @coises and All,
@coises, you said :
It’s possible that I or someone else (@guy038, where are you?) will think of a way to write the regular expression …
Well, I’m not very far from my laptops ! But these last days, I was searching for an [ on-line ] tool which could extract the color triplets ( RxGxBx) of all pixels of an JPG image, without success :-(( The best I could find was an interesting on-line tool :
https://onlinejpgtools.com/find-dominant-jpg-colors
which give a fair estimation of the main colors of any .jpg image uploaded. However, although you can choose the number of individual colors in the palette, it cannot list all the pixels, of course !
Thus, I’ll probably e-mail @alan-kilborn about a Python solution !
Let’s go back to @rjm5959’s goals ! However, from the last posts, I suppose that you gave up the N++ way !
Personally, I think that the @coises’s regex, in order to delete any page which does not contain any key-word, is quite clever and should work, even with very huge files as it only grabs a page amount of text, at a time !
So, @rjm5959, let’s follow this road map :
-
Do a copy your original file
-
Open this copy in Notepad++
-
First, verify if the first page, ( before a first
FFchar ) contains one of the expressions (United BankorNationstar) -
If it’s true, add a
~character right before the expression -
Secondly, do the same manipulation for the last page of your file ( after the last
FFcharacter ) -
Thirdly, open the Replace dialog (
Ctrl + H) -
SEARCH
(?-i)United Bank|Nationstar
~ REPLACE
~$0-
Check the
Wrap aroundoption -
Select the
Regular expressionoption -
Click on the
Replace Allbutton
=> It should be done quickly and it adds a
~character, right before any keyword (United Bank,Nationstar, … ) which is separated with the alternation symbol|, in the regexNote that I suppose that the search is sensitive to the case. Else, simply use the regex
(?i)United Bank|Nationstarfor a search whatever the case-
Now, we’ll execute this second S/R :
-
SEARCH
\x0C[^~\x0C]+(?=\x0C) -
REPLACE
Leave EMPTY -
Keep the same options
-
Click on the
Replace Allbutton
=> Depending on the size of your copy, it may take a long time before achieving this part ! Be patient ! At the end, you should be left with only :
-
All the pages containing at least one
United Bankexpression -
All the pages containing at least one
Nationstarexpression
BTW, @coises, I don’t think that the atomic structure is necessary , because, anyway, the part
[^~\x0C]+(?=\x0C)concerns a non-null list of characters all different from\x0Cand which must be followed with a\x0Cchar. Thus, the regex engine will always get all chars till a next\x0Cchar. It will never backtrack because it always must be followed with a\x0Cchar !-
Finally, run this trivial search/replace :
-
SEARCH
~ -
REPLACE
Leave EMPTY
If the second search/Replace
\x0C[^~\x0C]+(?=\x0C)is too complex, you could try to slice this copy in several files and retry the method on each part !I, personally, created a file, from the
License.txtfile, with aFFchar every60lines, giving a total of4,335pages, whose1,157contained the~character, Before using the\x0C[^~\x0C]+(?=\x0C)regex, the file had a size of about48 Mo. After replacement,15seconds later, it remained all the pages containing this~char only, so a file of about69,420lines for a total size of13 Mo:-)Best Regards,
guy038
-
-
Hi, @rjm5959, @alan-kilborn, @peterjones, @coises and All,
I must apologize to @coises ! My reasoning about the necessity or not to use an atomic group was completely erroneous :-(( Indeed, I would have been right if the regex would have been :
\x0C[^\x0C]+(?=\x0C)But, the @coises regex is slightly different :
\x0C[^~\x0C]+(?=\x0C)And because the
~character belongs to the negative class character[^.......]too, the fact of using an atomic group or not, for the pages containing the~character, is quite significant ! Indeed :-
The normal regex
\x0C[^~\x0C]+(?=\x0C)would force the regex engine, as soon as a~is found, to backtrack, one char at a time, up to the first character of a page, after\x0C, in all the lines which contain the~character. Then, as the next character is obviously not\x0C, the regex would skip and search for a next\x0Cchar, further on, followed with some standard characters -
Due to the atomic structure, the enhanced regex
\x0C[^~\x0C]++(?=\x0C)would fail right after getting the~character and would force immediately the regex engine to give up the current search and, search, further on, for an other\x0Ccharacter, followed with some standard chars !
Do note that, if the
~character is near the beginning of each page\x0C, you cannot notice any difference !I did verify that using an atomic group reduce the execution time, for huge files ! With a
30 Mofile, containing159,000lines, whose1,325contains the~char, located4,780chars about after the beginning of each page, the difference, in execution, was already about1.5s!!As a conclusion, @rjm5959, the initial @coises’s regex
\x0C[^~\x0C]++(?=\x0C)is the regex to use with files of important size ;-))BR
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login