Getting "Invalid Regular Expression" for an extremely simple expression
-
@Coises correctly pointed out that using regular expressions to search JSON is almost always a bad idea.
I’m sure that some bash guru around here would probably recommend some solution like the
jqcommand line tool, or I might also recommend using Python (not PythonScript, just Python) instead, and of course if you used such a tool, further advice on its use is outside the scope of this forum.@Coises also correctly pointed out that JsonTools does have some utility here; you might check out the JSON from files and APIs form (which I will just call the grepper form). I don’t use this form that much TBH, but here’s an illustration of how you might use it:
- Open the grepper form (
Plugins->JsonTools->Get JSON from files and APIsfrom the main plugin menu). - Click the
Choose directory...button in the middle of the form, and choose your directory. You may also wish to check theSearch in subdirectories?option if you want to recursively search all subdirectories of the chosen directory, and you may also wish to customize the search patterns.
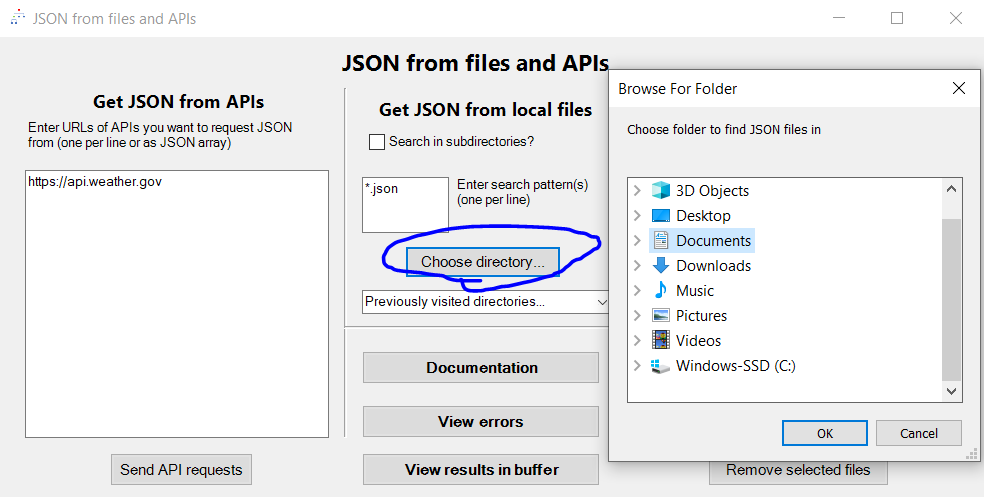
- When you select a directory, every JSON file that could be parsed will pop up. You can click the
View results in bufferbutton when you’re ready.
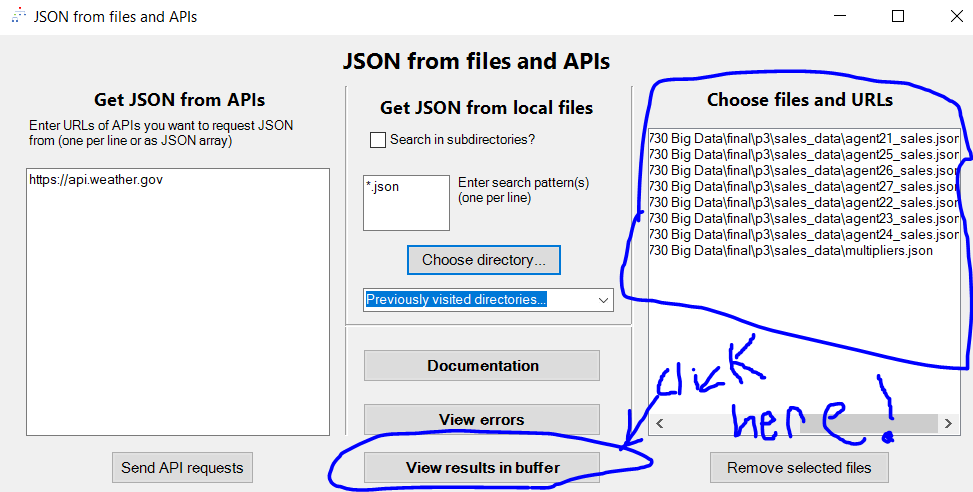
- An object mapping file names to the contents of files will pop up in a new buffer, with a tree view to the right.
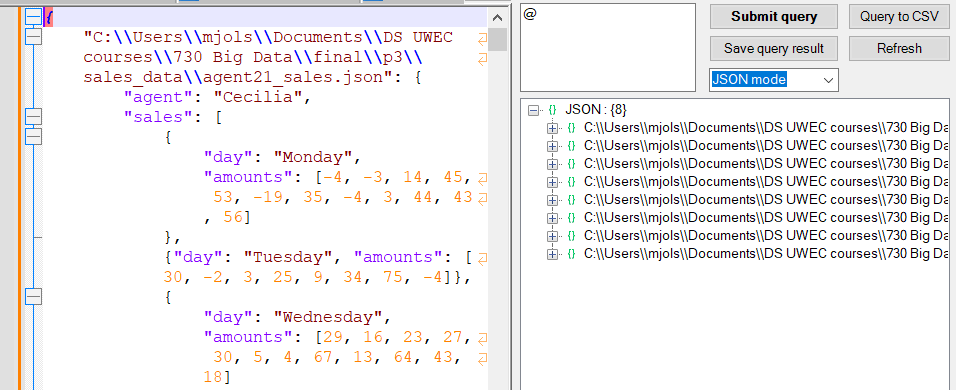
- Just for illustrative purposes, I’m going to search for the children of the
amountskey using theFind/replace in JSONform (open with the `Find/replace button at the bottom of the tree view. By studying the settings of that form, you can see how I did this:
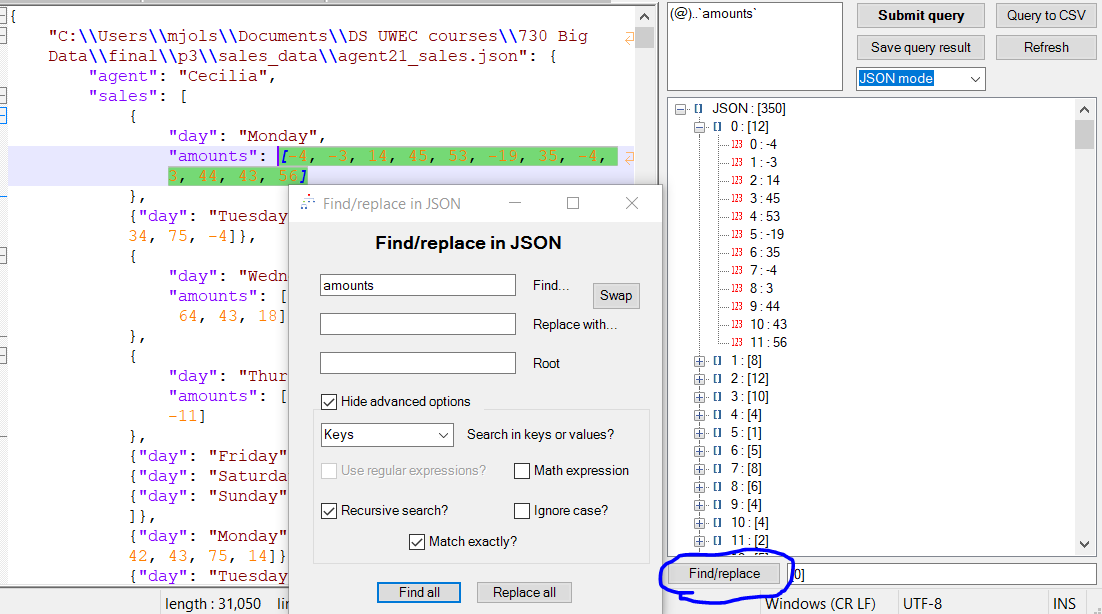
There are a whole bunch of other things you can do with JsonTools, and the best place to learn about them is in the README.
- Open the grepper form (
-
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
“.*employeeId”
Did the expression have the double quotes, or did you just add them for the sake of your explanation?
The double quotes were part of the regular expression. I was searching for string constants that ended in employeeId.
-
@Mark-Olson I appreciate the suggestion, I have several tools that allow me to search the contents of files. I was reporting a bug in NP++.
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
I was trying to find a regular expression in a set of files. The expression was very simple, only one wildcard, no capture groups, etc.
“.*employeeId”And it runs for a minute and then the dialog comes back with “Invalid Regular Expression” with a tooltip of “The complexity of matching the regular expression exceeded predefined bounds. Try refactoring…” which seems a little silly given the simplicity of my RE.
This might or might not help resolve the error… but it is unlikely that that expression does what you think it does.
You probably want something more like:
"[^"\r\n]*employeeId"
(see the difference?).I would also consider looking into @Mark-Olson’s JsonTools
While I appreciate the help, my point coming here was not to get help with regular expressions, which I’ve been using for decades, it was to report a bug in NP++ RE search.
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed.
-
@mkupper I was very literal in exactly what caused the bug in NP++. The regular expression I was searching for is the exact string on the second line of my post, including the quotes (I was searching for quoted constant strings ending in “employeeId” in all JSON files recursively within my projects folder).
-
@Mark-Olson said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Coises correctly pointed out that using regular expressions to search JSON is almost always a bad idea
I don’t know why either you or @Coises would think that it is unreasonable to search JSON files. They are just text files. It obviously isn’t going to get any context for the search, but that’s true of searching through HTML files, C++ files, C# files, etc. There is nothing inherently wrong with using a text search or a RE search against a set of JSON files and it is likely to be leagues faster (barring a bug like the one I’m reporting) to do a simple text search this way than using a JSON tool that has to load the entire file and parse it successfully before it can search it (especially true if there’s any chance some of the files it is searching could have invalid syntax).
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
barring a bug like the one I’m reporting
It is NOT a bug!
It is quite literally the regular expression engine expressing a statement that while working through your expression it would appear that it can finish with a situation where it may never complete. So for example it may find itself in an infinite loop. This is it’s way of protecting from that. If you really wanted to delve more into this, Google it.
As for using a plugin (as suggested above), also see the link provided to a FAQ post (Mark Olson 9 Jul 09:40). Now I don’t fully subscribe to the notion of regex not being able to successfully find text within a JSON file. But obviously in your case it hasn’t been successful. Fine, then either consider the alternate idea of using the plugin, or; as the tooltip suggests; refactor your expression so it doesn’t have this problem.
You can continue to reply to posts here about wanting help with advertising the bug, but I think most will just point you in the direction of refactoring your regex or using the plugin. No-one will help you with your suggestion of “it’s a bug” purely because it isn’t one.
Terry
-
@Terry-R said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
barring a bug like the one I’m reporting
It is NOT a bug!
A regular expression as simple as this one should never trigger an endless loop (without a bug). It has no explicit backtracking and since I did not select “. matches newline” it will always end the search at the end of every line of text, so the longest individual line it should match, or fail to match, is probably measured in bytes, not even kilobytes. So, this RE is going to search a large number of plain text files, logically breaking each file up by Carriage Return, and returning the rows that it found. No different than running this same search on a file loaded into a buffer, just in a loop.
I have run extremely similar searches using NP++ in the past with no issues until recent versions. I ran this exact same search using Visual Studio and while it took a while to complete (I was searching a pretty large haystack) there were no issues otherwise.
So, given all that, I think definitely stating that this is not a bug is unjustified.
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
While I appreciate the help, my point coming here was not to get help with regular expressions, which I’ve been using for decades, it was to report a bug in NP++ RE search.
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed.
We couldn’t know, from your post, your level of sophistication. For example, if someone posted the expression you gave here, they might not understand that if there were multiple quoted strings on a single line and the one ending in employeeId were not the first one, that expression would match everything from the first quote on the line through the string ending in employeeId. Since the expression would try each quote in turn and then scan all the way to the end of the line, if lines were long and contained many quoted strings, that could possibly trigger the matching complexity heuristic.
The heuristic that puts up that message is part of the Boost::Regex package, which Notepad++ uses for regular expressions. Unfortunately, that means it’s a bit of a black box to most of us, even those who know something about the Notepad++ code base.
If your purpose is to post a bug report, rather than to ask for help, this forum is not the right place to do it; Issues for Notepad++ on GitHub is where you would need to do that.
You would need to include a minimal way to reproduce the error message. This one comes up enough to be annoying, so I don’t think it’s unreasonable that someone might take an interest in following what happens in the code and trying to get to the bottom of why this message sometimes appears when it doesn’t seem to make sense. Perhaps it is a bug, or perhaps we could better understand what regular expressions and data cause this error when it is not intuitively expected.
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said:
While I appreciate the help, my point coming here was not to get help with regular expressions, which I’ve been using for decades, it was to report a bug in NP++ RE search.
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed.
We couldn’t know, from your post, your level of sophistication. For example, if someone posted the expression you gave here, they might not understand that if there were multiple quoted strings on a single line and the one ending in employeeId were not the first one, that expression would match everything from the first quote on the line through the string ending in employeeId. Since the expression would try each quote in turn and then scan all the way to the end of the line, if lines were long and contained many quoted strings, that could possibly trigger the matching complexity heuristic.
The heuristic that puts up that message is part of the Boost::Regex package, which Notepad++ uses for regular expressions. Unfortunately, that means it’s a bit of a black box to most of us, even those who know something about the Notepad++ code base.
If your purpose is to post a bug report, rather than to ask for help, this forum is not the right place to do it; Issues for Notepad++ on GitHub is where you would need to do that.
You would need to include a minimal way to reproduce the error message. This one comes up enough to be annoying, so I don’t think it’s unreasonable that someone might take an interest in following what happens in the code and trying to get to the bottom of why this message sometimes appears when it doesn’t seem to make sense. Perhaps it is a bug, or perhaps we could better understand what regular expressions and data cause this error when it is not intuitively expected.
Thanks @Coises, I thought this was the best first place to post this. Considering the obvious simplicity of the RE and the text of the error, I actually expected others to chime in saying they had seen this as well. I actually can’t imagine that it’s a problem in an underlying RE library, unless they have recently rewritten that library or made some significant change. I kinda assumed this would turn out to be a timeout bug that was masquerading as a bug in the RE library (and I think that’s still the most likely culprit considering how old and well-tested most of the RE standard libraries are).
Given that nobody else chimed in as having seen the bug, I’ll post it to GitHub.
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Given that nobody else chimed in as having seen the bug, I’ll post it to GitHub.
It’s not so much that we haven’t seen that behavior as that if there is anyone who understands the Boost::regex library code deeply enough to distinguish a situation in which issuance of that error is “working as intended” from one in which it is not, that person has not made themselves known.
You mentioned in another post:
I have run extremely similar searches using NP++ in the past with no issues until recent versions.
Since you already have a test case on your machine now… if you could install an older version and demonstrate to yourself that this exact search of these exact files does not cause this error in that version, but does in some later version, that would go a long way toward indicating that it is a bug, and it would give us some idea where to look (either a newer version of Boost::regex or some change in the way it’s incorporated into Notepad++).
A test case we can use to reproduce it would still be almost essential, though.
-
All, maybe @Scott-Gartner is on to something.
On a lark I did a Find in Files for
".*employeeId"in a set of folders with a few thousand text files. It ground away for a while, scanning through files and thenFind: Invalid Regular Expressionpopped up at the bottom of the dialog box. The...button has the complexity message.I’ll skip explaining the trial and error. The line it’s failing on is 40,390 characters long. It’s part of some JavaScript code loading JSON into a variable. It’s a plain text file with no highlighting. If I chop it in half the find hangs unusually long but then says
not found.Maybe one of you can figure out what is happening. I put the file at https://pastebin.com/gYBMQnF8
It also fails on v8.3.3 which is the oldest copy I currently have on the machine. It fails for both x32 and x64 and so that’s not an issue. It fails when running using
-noPluginSurprisingly, it also fails if I try
".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line. -
@mkupper said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe one of you can figure out what is happening. I put the file at https://pastebin.com/gYBMQnF8
Surprisingly, it also fails if I try
".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line.I can confirm that both your expressions fail with the complexity message on that file. (Notepad++ v8.6.8-x64)
I also note that the expression I suggested:
"[^"\r\n]*employeeId"
finds the single occurrence of that expression, in line 2, and does not cause an error.Edit to add:
If for some reason one really did want to match the first quote on a line, the last occurrence of employeeId" on the same line, and everything in between (as the original poster’s expression says), this:
"(.*employeeId"|.*(*SKIP)(*FAIL))
would work. -
@mkupper said in Getting "Invalid Regular Expression" for an extremely simple expression:
Surprisingly, it also fails if I try ".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line.
Either way — shortest first or longest first — the regular expression engine finds a quote, then scans all the way to the end of the line looking for
employeeId". When it doesn’t find it, it moves on to the next quote and tries the same thing again. Apparently there is not enough intelligence, or optimization, or “smarts,” or whatever you want to call it, for the engine to realize that if it didn’t findemployeeIdthe first time it scanned the line, it’s not going to find it when it scans again starting from a later position.The message is, in my opinion, poorly worded. It says, “The complexity of matching the regular expression exceeded predefined bounds.” I think a lot of people misread that as “complexity of the regular expression” instead of “complexity of matching the regular expression.”
Even then, though, it’s not really complexity that triggers the message, it’s inefficiency. When I looked at that code once before, I wasn’t able to follow the details, but I could get the overall sense of it. It’s looking to see how much “work” (measured, I think, as the size of some internal stack) it’s doing relative to how much progress it’s making moving the starting match point forward in the file. When it looks like the amount of text being scanned is growing far faster (worse than proportional to the square, I think) than the amount of text being processed — that is, it’s re-examining the same text again and again and not making much headway — it issues this message.
-
When you have something like
".*employeeId"you are asking the regular expression engine to- Find a double quote.
- Skip over any number of characters, it could be billions and those characters can be double quotes, until you find the
e. It ls looking for the last ‘e’ on the line as it first tries for the longest match. - See if the next character is the letter
m. If not back the step 2 scanner for the previous ‘e’ and retry step 3 again. Keep looping and backing up until you either find an ‘e’ followed by ‘m’ or you backed up all the way to the double quote found in step one. The process is known as backtracking. If there were no matches resumes step one to scan for another another double quotes and starts it all over.
The test file I posted has 5205 double quotes and 4007 of the letter e. It’s going to crunch away at that line trying about 20 million starting and ending points before it decided there was no match and moved to the next line.
I thought quick fix was
".*?employeeId"but that only changes in step 2 that it will look for the first e and that work it’s way forwards. It’s still at least 20 million tests as theemployeeId"part does not exist in the line of text.Either way, the regular expression engine decided after a few million attempts to match that it was a waste of time, and blames you for making an expression that was too complicated…
@Coises’
"[^"\r\n]*employeeId"works because his step 2 is[^"\r\n]*ewhich scans forward. for anything that is not a double quote or end of line. It The hunt for theemployeeId"part will abort much faster as it’ll hit the next double quote and then go back to step one. The\r\npart is necessary as the not-a character scanner will cheerfully scan past the end of a line and scan all the way top to the end of the file when it’s hunting. The regular is-a-character scanner stops at the end of the line.Thus @Coises’ version aborts the scan much faster as it is not scanning to nearly the end of a long line over and over. We are making the assumption though that you were not seeking a match that spans from the first double quote on a line and goes past all intervening double quotes on to
employeeId"The “.*?employeeId” expression I proposed would give you the shortest match or"....employeeId"but still did too much scanning.Note that any of the matches proposed will return the wrong match if the data string contains escaped double quotes
"...\"...employeeId". Details such as this are why regular expressions are not a good idea for JSON. -
@Coises said :
The message is, in my opinion, poorly worded. It says, “The complexity of matching the regular expression exceeded predefined bounds.”
I think a lot of people misread that as “complexity of the regular expression” instead of “complexity of matching the regular expression.”
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
-
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
Hmmm… honestly, I’m not sure there is a good way to word that message — the very existence of the message is the problem. The right way (in my oh-so-humble opinion) to handle this would be to pop up a progress dialog when searches take more than a user-configurable amount of time, and let the user decide when it’s been going on too long and should be canceled.
Doing something like that with the search in Columns++ is on my list of potential future enhancements. I think it might require modifying Boost::regex, though; if it does, I will find that idea rather uncomfortable. If I ever do get it done and working right in my plugin, that could serve as a proof-of-concept for doing it in Notepad++.
Or (considering that the problem @mkupper demonstrated would have been avoided if the regex processing recognized that if a fixed string didn’t match from a given position to the end of a line it couldn’t possibly match from a later position in the line to the end of the same line), maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
the very existence of the message is the problem
It’s what Boost provides (apparently).
Enhancements should be pursued through the Boost project, IMO.A sort of obvious statement: Boost is to Notepad++ regex as Scintilla is to Notepad++ editing…and although there are some Notepad++ side hacks to Scintilla, I’d think that Notepad++ hacks to Boost would be more difficult and harder to maintain.
maybe we just need a smarter Regex engine
Replacing the regex engine that Notepad++ uses would likely be a hard sell to the Notepad++ author, but I suppose anything is possible.
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
The
regexPython package is generally considered one of the most capable regex engines out there, but even that package takes quadratic time (in the length of the input) when testing the regular expression".*employeeId"on many repetitions of the string"employeeI"(including a space after the closing quote).As I understand it, some regex implementations (like this one) enable compiling a regex to a DFA, which has no backtracking and thus could never take more than linear time to process any input, but there’s a big issue here:
The Notepad++ regex engine would need to automatically determine when a regular expression can be represented with a DFA (which no engine that I know of can do), because I somehow doubt that the user base would be in favor of a new option that can’t even be understood without studying CS theory.
NOTE: To spare the ambitious among you some trouble, don’t even bother trying to come up with a general algorithm that can determine whether a Boost regex can be represented with a DFA. Such an algorithm is literally impossible for boring pedantic reasons.
-
I was more just surprised that there are (apparently) no optimizing heuristics such as recognizing that if B contains no back-references to A, if A.*B doesn’t match at the first position A matches, it can’t match anywhere in the line (if . does not match line endings) or anywhere at all (if . does match line endings). I would have thought that .*, especially, was so common that simple expressions joined by .* would have more clever processing.
Apparently regular expressions are executed rather literally (like compiling code in debug mode with optimization off). Then again, aside from here, in Notepad++, I guess regular expressions are usually used by fairly “geeky” types who are capable of recognizing what the expressions imply and optimizing them before handing them to the regular expression engine.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login