Every time I start notepad++, the encoding of some files will be changed
-
Every time I start notepad++, the encoding of some files will be changed, which causes me great trouble in using it.
My encoding settings are as follows:
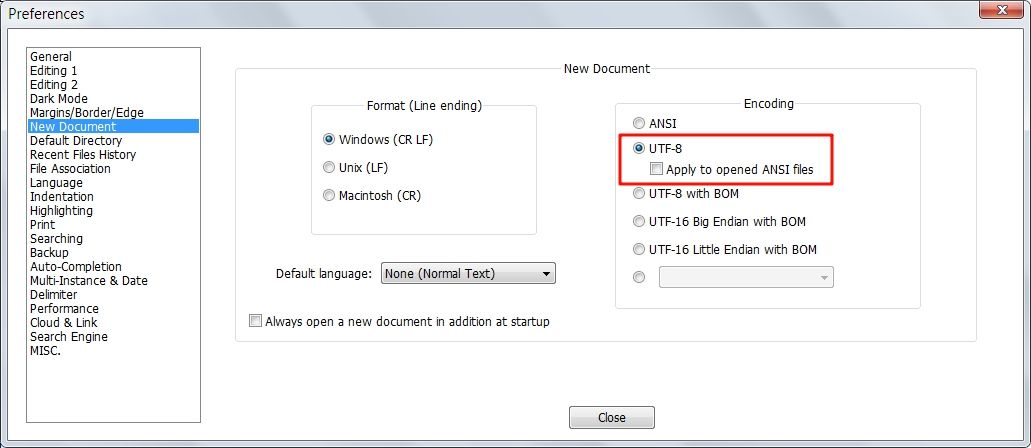
EX: But it was still From utf8 to ansi
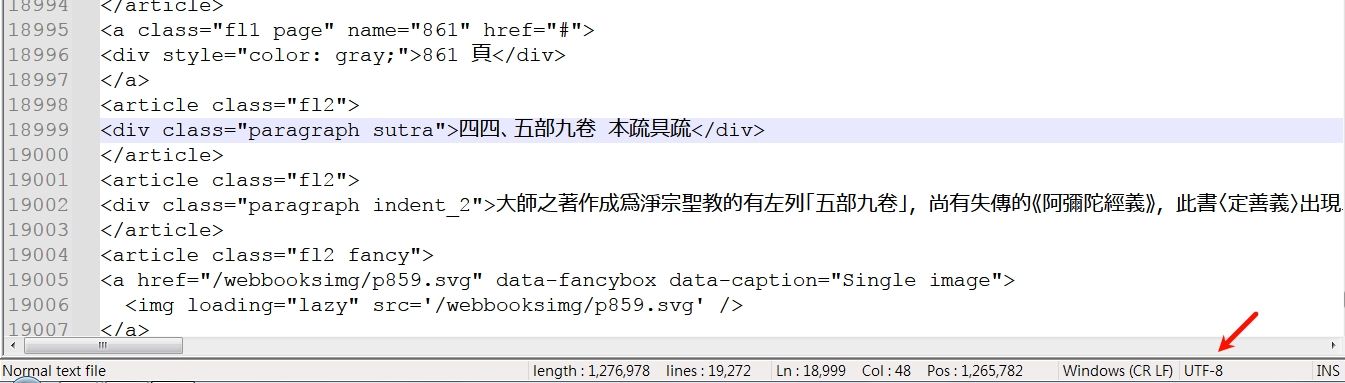
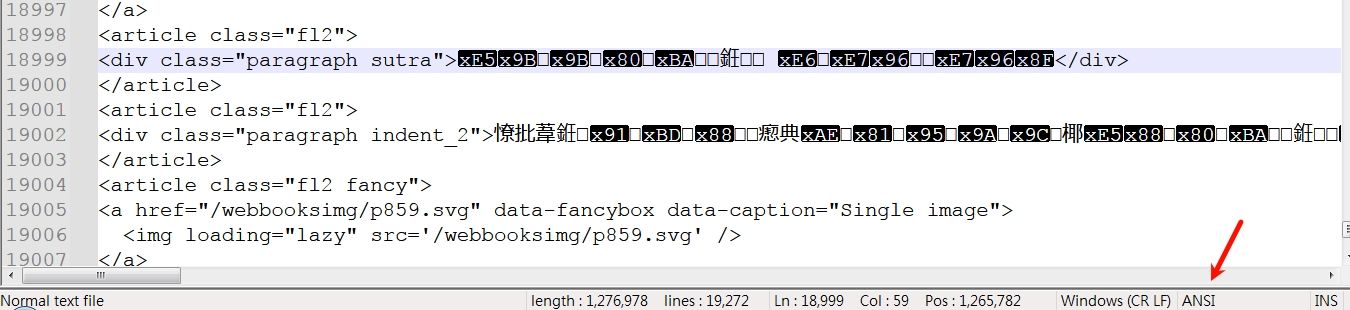
Notepad++ v8.7 (64-bit)
-
@Freya-Smith:
Have you tried checking UTF-8 | Apply to opened ANSI files in the New document screen?I know it doesn’t sound like it should be relevant, but I think it will help.
In Windows, the encoding of a file is not stored anywhere. Since “ANSI” means the default non-Unicode interpretation of a file in the current locale, there is no such thing as a file that can’t be ANSI. There is no way to look at a UTF-8 file and tell for certain that it is UTF-8 and not ANSI. (However, the presence of a byte order mark at the beginning of an ANSI file is so unlikely that it is assumed to indicate Unicode.)
The reverse is sometimes possible. Some ANSI files contain character sequences which cannot be UTF-8. Checking that box will cause files that cannot be UTF-8 to be opened as ANSI; files that could be either will be opened as UTF-8.
-
@Coises said in Every time I start notepad++, the encoding of some files will be changed:
Apply to opened ANSI files
My recollection of what this checkbox (when checkmarked) does is:
- if a file has no content (it’s 0 bytes on disk), open it as UTF-8
- if a file’s entire content is “7-bit ASCII” (no bytes with highest bit set), open it as UTF-8
This “recollection” was found in some notes I had.
The USER MANUAL is “light” on detail on this feature, saying only “If you open an ANSI file, this allows it to be “upgraded” to UTF-8.”
-
@Alan-Kilborn said in Every time I start notepad++, the encoding of some files will be changed:
@Coises said in Every time I start notepad++, the encoding of some files will be changed:
Apply to opened ANSI files
My recollection of what this checkbox (when checkmarked) does is:
- if a file has no content (it’s 0 bytes on disk), open it as UTF-8
- if a file’s entire content is “7-bit ASCII” (no bytes with highest bit set), open it as UTF-8
This “recollection” was found in some notes I had.
After doing my best to follow the code, I believe you are correct. The relevant routines appear to be:
FileManager::setLoadedBufferEncodingAndEol
and
Utf8_16_Read::utf8_7bits_8bitswhich appear to come into play when there is no byte order mark and the file is not HTML or XML with a detected character set specification. First, utf8_7bits_8bits decides that if a file contains a null, it’s 8-bit ANSI; if it contains only bytes from 1-127, it’s 7 bit ANSI; otherwise, if it contains only character sequences that are legal UTF-8, it’s UTF-8; otherwise, it’s 8-bit ANSI. Then setLoadedBufferEncodingAndEol uses the New Document | UTF-8 | Apply to opened ANSI files to determine whether existing files that are empty or contain 7-bit ANSI should be opened as UTF-8.
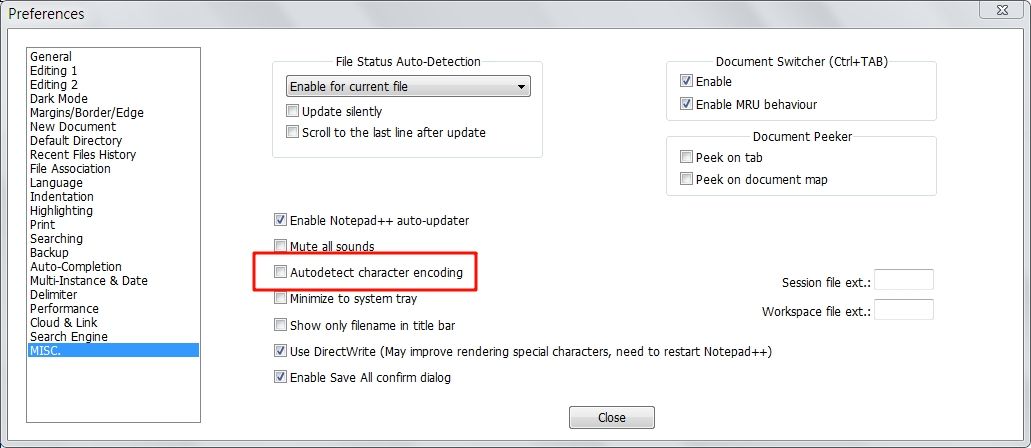
It looks like MISC | Autodetect character encoding tries to detect ANSI codepages that are not the default (corresponding to an Encoding | Character sets submenu selection, rather than Encoding | ANSI), but I haven’t attempted to follow that all the way through. I’m not sure where that fits into the sequence of decisions and how it interacts with the Apply to opened ANSI files setting.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login