problem with char encoding for suggested words
-
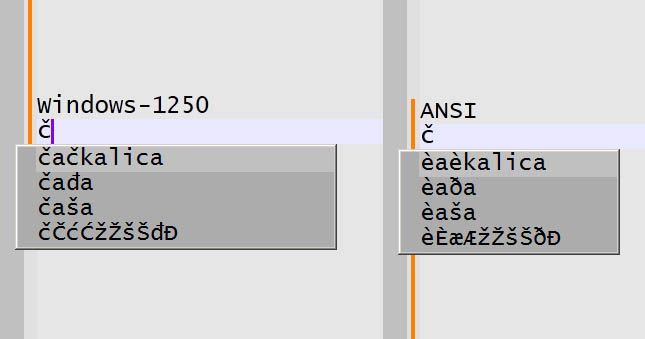
npp.8.7.1 in Windows 7 shows matching word list with the wrong character set. Document is originally written in Windows 1250. When NPP opens it, it opens it as an ANSI. I can normally read and type all needed characters (čČćĆžŽšŠđĐ), and they are correctly saved.
But the suggested list of corresponding words is shown with the wrong character set! Correct is the right and wrong is the left side of the attached illustration.
Only when I manually change character set to the Windows 1250, suggested word list is shown correctly!
If a new document is configured to be created as ANSI, the same problem exists. If it is configured to be created as Windows 1250, all is well for this new document.
When UTF-8 BOM file is open, no problems.
I repeat: body text is always written, shown and saved correctly, in both ANSI and Win1250.
-
NPP does not sort correctly using the above characters. Regardless if UTF-8, ANSI or Windows 1250.
This is the correctly sorted word list as made by Word 2000:
ajde
četiri
ćevap
dva
đurđa
jedan
šest
tri
žužiNPP will sort it wrong as:
ajde
dva
jedan
tri
ćevap
četiri
đurđa
šest
žužiOur letters came after the similar ones without the carets above.
My guess is that the same problem exists in other non-English languages. I would expect NPP to sort correctly if the Word 2000 can.
-
@pilaGit ,
It sounds like you are requesting a change in Notepad++'s codebase.
As our Feature Request / Bug Report FAQ says, this Forum is not where Feature Requests or Bug Reports are tracked. That FAQ explains where to submit an issue so that the developer can be made aware of the problems you have found (making sure you search existing issues to see if it’s already been reported)
-
@pilaGit said in problem with char encoding for suggested words:
NPP does not sort correctly using the above characters. Regardless if UTF-8, ANSI or Windows 1250.
See GitHub issue #13456. (There is an unfortunate amount of vitriol in that discussion, but it is possible to extract from it some sense of what is desired and why it is not a simple fix.)
The underlying cause is that Notepad++ has a notion of character encoding, but it does not have a notion of locale. Aside from the option to ignore case, Notepad++ sorts by the numeric value of the bit patterns that represent characters. Sorting in a way that makes sense within a given language requires knowing and using the proper locale.
The locale sorts in my Columns++ plugin attempt to take this into account. By default, the current system locale is used; it is possible to select a different locale in the custom Sort… dialog.
-
I wanted to check here first, as I understand how complex this sort problem is. It simply may not be feasible. It is very rare to see sorting of our characters working correctly.
The first problem really sounds like a bug, small omission. I have added AutoCodepage and linked it to .txt, not ideal, but useful as a partial solution.
I will check info you have pointed me to, many thanks.
-
@pilaGit The Notepad++ sorting seems to align with the Scintilla library sorting that Notepad++ uses for the autocomplete.
PythonScript example to test:
def main(): def check_order(): order = editor.autoCGetOrder() if order != 1: print('autoCGetOrder:', order) # Scintilla to do the sort order. editor.autoCSetOrder(1) order = editor.autoCGetOrder() print('autoCGetOrder:', order) text = editor.getText() words = text.split() itemList = ' '.join(words) print("py_sorted:", sorted(words, key=str.upper))) print("words:", words) print("itemList:", itemList) check_order() print('autoCShow') editor.autoCShow(0, itemList) main()Document:
četiri dva ajde tri jedan ćevap đurđa žuži šestImage of 1st run showing the autocomplete:
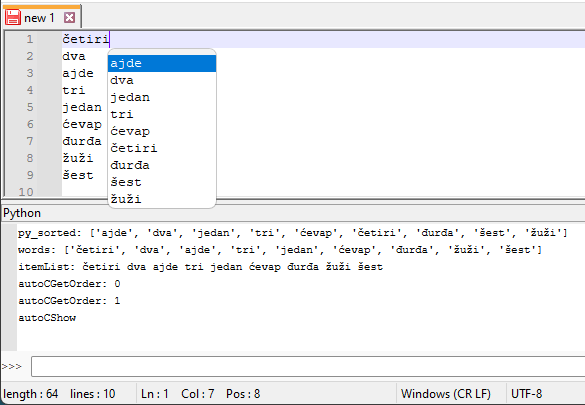
Scintilla internally sorted the autocomplete list instead of Notepad++ in this test.
This is not focusing about how the sort is done that I mention. It’s about the current sort is aligned between the Notepad++ sort and the Scintilla sort. If not aligned then unpredictable bad working behavior occurs with the autocomplete.
For how the sort is done, the change of sort algorithm would require change in both Notepad++ and the Scintilla library to remain aligned for good working behavior. There is a custom sort SC_ORDER_CUSTOM though means extra work to create an index … and extra processing is usually avoided if possible to prevent excessive lag with the editor.
-
Hello, @pilagit, @peterjones, @coises, @mpheath and All,
Not really off-topic but yes, sorting problems are always a nightmare :-(( Just some general remarks about the alphabetical sorting order :
https://en.wikipedia.org/wiki/alphabetical_order
Read, particularly, the section below :
https://en.wikipedia.org/wiki/Alphabetical_order#Language-specific_conventions
Just an example, which, however, concerns two bordering countries :
(for example, the correct lexicographic order is baa, baá, báa, báá, bab, báb, bac, bác, bač, báč [in Czech] and baa, baá, baä, báa, báá, báä, bäa, bäá, bää, bab, báb, bäb, bac, bác, bäc, bač, báč, bäč [in Slovak])
On the other hand, on the Unicode consortium site, take the time to fully read this technical and interesting report :
https://www.unicode.org/reports/tr10/
The beginning of this article says :
Collation is the general term for the process and function of determining the sorting order of strings of characters.
It is a key function in computer systems; whenever a list of strings is presented to users, they are likely to want it
in a sorted order so that they can easily and reliably find individual strings. Thus it is widely used in user interfaces.
It is also crucial for databases, both in sorting records and in selecting sets of records with fields within given bounds.You’ll be stunned by the complexity of the problem !
So, practically, I suppose that anyone, trying to create a sort algorithm, must do a lot of simplifications. Indeed, taking in account all the specifications, for a correct sorting of all languages, seems to be a superhuman task !
Luckily, there’s nothing mysterious about the sort algorithm used by Notepad++ :
If you use the
Edit > Line Operations > Sort lines Lexicographically Ascendingoption, any character is simply sorted by its Unicodecode-point.However, for all code-points over the
BMP( Basic Multilingual Plane ), i.e. with code-point overU + FFFF, they all lie within the surrogates section. So :-
After the
D7FFand previous code-points of theBMP -
Before the
E000and next code-points of theBMP
Thus, a general N++ sorted list, with Unicode
v16.0, is always of this form :U + 0000 NULL character \ ... | ... | ... | Plane 0 : Basic Multilingual Plane ( BMP ) ... | ¯¯¯¯¯¯¯¯ ... | U + D7FB HANGUL JONGSEONG PHIEUPH-THIEUTH character / U + 10000 LINEAR B SYLLABLE B008 A \ ... | ... | ... | Plane 1 : Supplementary Multilingual Plane ( SMP ) ... | ... | U + 1FBF9 SEGMENTED DIGIT NINE / U + 20000 CJK Ideograph Extension B GKX-0075.06 \ ... | ... | ... | Plane 2 : Supplementary Ideographic Plane ( SIP ) ... | ... | U + 2FA1D CJK COMPATIBILITY IDEOGRAPH-2FA1D / U + 30000 CJK Unified Ideographs Extension G UK-02764 \ ... | ... | ... | Plane 3 : Tertiary Ideographic Plane ( TIP ) ... | ... | U + 323AF CJK Unified Ideographs Extension H T13-3D2C / U + E0001 BEGIN LANGUAGE TAG \ ... | ... | ... | Plane 14 : Supplementary Special-purpose Plane ( SSP ) ... | ... | U + E01EF VARIATION SELECTOR-256 / U + F0000 Private Use-A \ ... | ... | ... | Plane 15 : Supplementary Private Use Area A ( SPUA-A ) ... | ... | U + FFFFD Private Use-A / U + 100000 Private Use-B \ ... | ... | ... | Plane 16 : Supplementary Private Use Area B ( SPUA-B ) ... | ... | U + 10FFFD Private Use B / U + E000 Private Use Area \ ... | ... | ... | Plane 0 : Basic Multilingual Plane ( BMP ) ... | ¯¯¯¯¯¯¯¯ ... | U + FFFD REPLACEMENT character /Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login