Help Needed with COMPARE plugin..thanks in advance
-
THAT WORKED FANTASTICALLY…YOU SAVED ME “HOURS” OF WORK…
thank you… thank you … thank youUsing that expression got be through the"BKX-xxxxxs" in minutes
I know that expression was made for just that example I gave
How to I learn to make expressions for other track names?
there are hundreds of different naming combinations like
scxxxx-xx , zpcp2024-xx, kv-xxxxx
but the all follow the same format just have different letters and numbers
typically the standard format for all like this…
DISC #(dash)TRACK #(SpaceDashSpace)ARTIST(SpaceDashSpace)TITLE
the artist and title could be ignored if they are sorted by just the DISK & TRACK #sI really need to learn the process of creating an expression if there is no way to make a universal one.
where does one learn how to construct a regex expression?
oh and THANK YOU AGAIN for what you already provided…
-
@ray-Landolfi said in Help Needed with COMPARE plugin..thanks in advance:
where does one learn how to construct a regex expression?
Start HERE.
-
@Alan-Kilborn thank you…
upon reading that I have realized I am not as smart as I previously thought…
I actually feel LESS smart than before…I will have to depend on someone coming up with a universal regex expression based on my follow up as I am no where capable of doing it myself… LOL
-
Hi, @ray-landolfi, @coises, @alan-kilborn and All,*
To begin, I’ll just explain my previous regex. What all this stuff means ?
The search regex
^.+(?=BKD)|\x20-\x20.+$can first be split in two different sub-regexes, separated by the alternative regex char which is the|.-
The part
^.+(?=BKD)searches from beginning of line [^] for a non-zero amount of standard characters [.+] but ONLY IF it’s followed with theBKDstring [(?=BKD)]. The last syntax is called a look-ahead structure which is NEVER part of the regex match, but MUST occur at this location in order that there’s a match. -
The part
\x20-\x20.+$searches for an space char, then a dash and an other space [\x20-\x20] followed, again, with a non-zero amount of standard characters [.+], till the end of line [$]
In other words, if, for example, I use the first line of the
File_B.txt, discussed in my previous post :!beni-Lappy BKD-24733 - Brantley Gilbert - Devil Don't Sleep.zip ::INFO:: 3.6 <----------> <-------------------------------------------------------> ^.+(?=BKD) \x20-\x20.+$As you can see, everything of each line, but
BKD-#####, is matched by this search regex and, thus, will be ignored by theComparePlusplugin during the process !
Remarks :
-
By default for the
ComparePlusplugin, the search is sensible to case -
By default, any dot regex symbol [
.] stands for a standard char, not an EOL char -
The leading in-line modifiers like
(?-i)or(?s)are not taken in account -
Do not insert any line-break [ as
\r,\nor\R] in the regex ( Comparisons is based on a line by line process ! )
Now, @ray-landolfi, I pleased to see that your file seems well structured, like below :
DISC ### - TRACK ### - ARTIST ......... - TITLE .........As you say that, both, the ARTIST and the TITLE could be ignored and that you just bother for the DISC and TRACK entities, then the Ignore regex could be simply as below :
\x20-\x20(?!TRACK).+$DISC ### - TRACK ### - ARTIST ......... - TITLE ......... <--- \x20-\x20(?!TRACK).+$ --------->
However, @ray-landolfi, I suppose that there are a lot of other conditions to respect in your files ! If so, in your reply, just insert your text as raw text, using the
</>icon !Best Regards,
guy038
-
-
@guy038 all of the tracks are formatted the same… OMG how confusing if they didn’t…lol
the length of the “DISK” and “TRACK” selections only vary by character quantity…such as
zoom-1234
misc-12
homemade-0004they always contain the same separators
“dash with no spaces” separating “Disk” & “Track#”
“space dash space” between "TRACK#"and “ARTIST” and again between “ARTIST & TITLE”
example SC1000-15 - Frank Sinatra - My Way.zipThe last code you offered seems to work well…
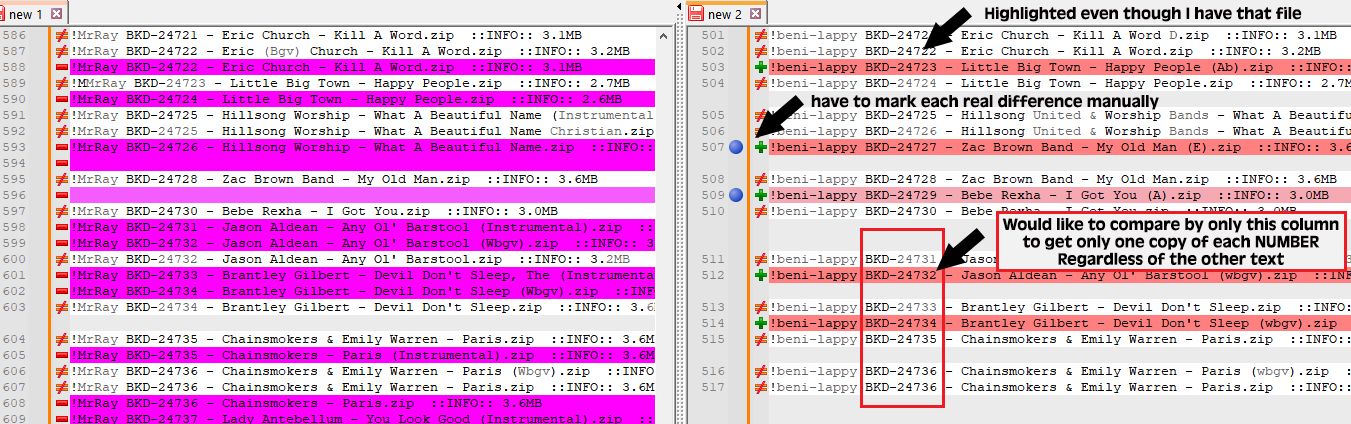
It returned the tracks I was missing compared to the other listby highlighting themfor some reason even with “return only diffs” checked off it still only highlighted the diffs…it didn’t just list the differences …but I can live with that…
it basically decides what to show me by simply the differences in the “disc and track#s” and ignores any differences in the “Artist and Title”…so THATS GREATI then bookmark the ones I need manually, clear all non-bookmarked lines and I have a nice list to C&P for my next step of acquiring them from the other persons library…
you have made this process easier and THANK YOU… -
Of course, you are still being overly vague, giving only one example, when even your original screenshots prove that your data is more complicated than you are implying.
!beni-lappy BKD-####shows that - can occur even in the “DISC ####” section, so the regex has to accept even hyphens (the character is an ASCII hyphen, not a dash), and that despite using the # , which means “number sign” in ASCII text, “DISC ####” is not a number, even though for “TRACK ####”, it is a number. Being ultra-loose in your examples like that is why @guy038 was asking for more example data, input using the</>button in the Forum post editor, so that it shows up in a text box, and we know we aren’t missing important characters.But based on a guess as to what you mean – I think you are saying that DISC can have anything, and there is a hyphen separating DISC and TRACK, and track must be a one-or-more-digit number.
Thus, instead of having @guy038’d lookahead of
(?=BKD), which was making the assumption that BKD always came before the DISC-TRACK separating hyphen, you would actually want a lookahead of(?=-\d+)… and if I were you, I would also make the “match-anything” before that.+?instead of.+, so that it will stop at the first-####if there happens to be more than one in a given line. Based on this, my recommendation for a more-generic regex would be^.+?(?=-\d+)|\x20-\x20.+$I actually feel LESS smart than before
Anytime you are learning something new that’s worth learning, you must start with the realization that you have more to learn. Instead of using that as an excuse to give up, you need to use it as motivation. The FAQ gave lots of resources, any one of which would be a good place to start learning. Or just learn what each of the chunks that @guy038 has already shown do, and then start playing around in data that is familiar to you, and see what you can and cannot figure out how to match, and then start looking up terms in the Notepad++ User Manual’s regex section to see if you can figure out how to use the manual to figure out what other syntax does.
But just saying “it looks too hard” and giving up is guaranteed to mean you will never learn, and you’re the one who gets hurt by that decision.
I will have to depend on someone
Well, okay, if you are going to assume that someone else will always do stuff for you when it’s “too hard” for you, any such people that you abuse will also be harmed (or at least saddened) by your decision.
-
Thank you to everyone who helped…
PETER: Its true should learn this and thank you for your advice…
You are correct that the “DISC” field will contain text other than “BKD” as tried to explain in the other examples I shared… and the “TRACK #” will possibly contain more then 1 or 2 digits sometimes as many as 8 or moreThe first string of data is the person’s list I am getting the info from it will vary
The second string will vary in length and characters as well but always be in the same format **“DISK-TRACK”**with no-space between themThank you for pointing out that I may have not explained the naming format fully. I have been working with this format for years and forget it’s new to others.
The following examples will show that the data is different depending on the person the list is from…!celtic KVD-59990 - Luther Vandross - Killing Me Softly.zip
!beni-Lappy BKD-24733 - Brantley Gilbert - Devil Don’t Sleep.zip
!MrRay SC7515-12 - Frank Sinatra - My Way.zipWe can be sure that data to be sorted immediately follows the FIRST SPACE
and ends immediately before the SECOND SPACE.
I don’t know of any other way to describe itGUY: thank you again for your help… The second code you shared seems to be ignoring the person the list is from…that worked
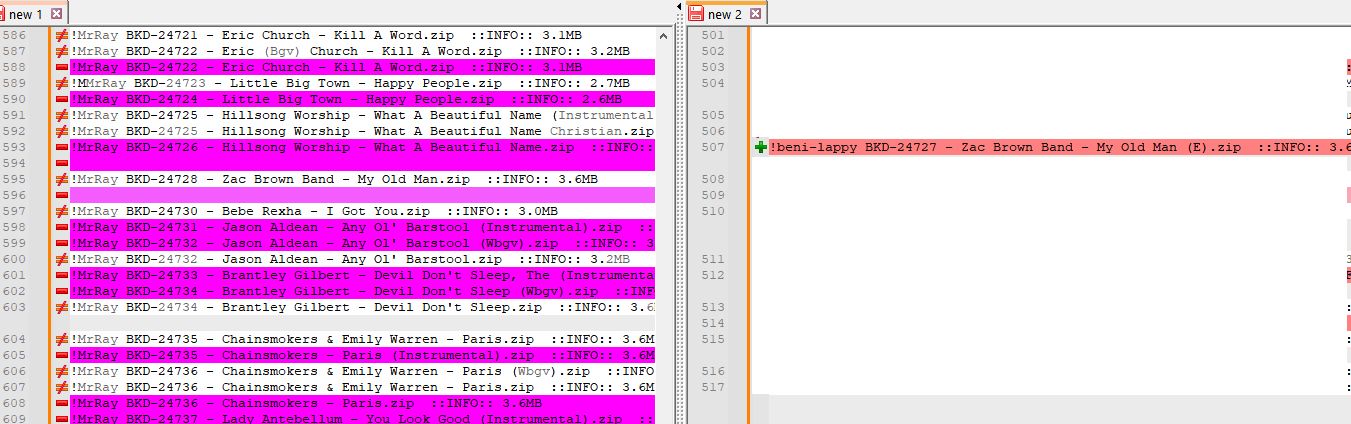
However since I wasn’t specific in explaining that the disk and track could be other than always being BKD I think it is not ignoring the other text after the DISC-TRACK#Here is a screen shot of what I get when I use a list from another person and discs/tracks other than BKD with the same regex code
I don’t want to be a bother or pain in the butt so I will use what I have and no hard feelings…
I will follow up on seeing if I can learn this stuff but it’s going to be from the very start and this could take a while…LOL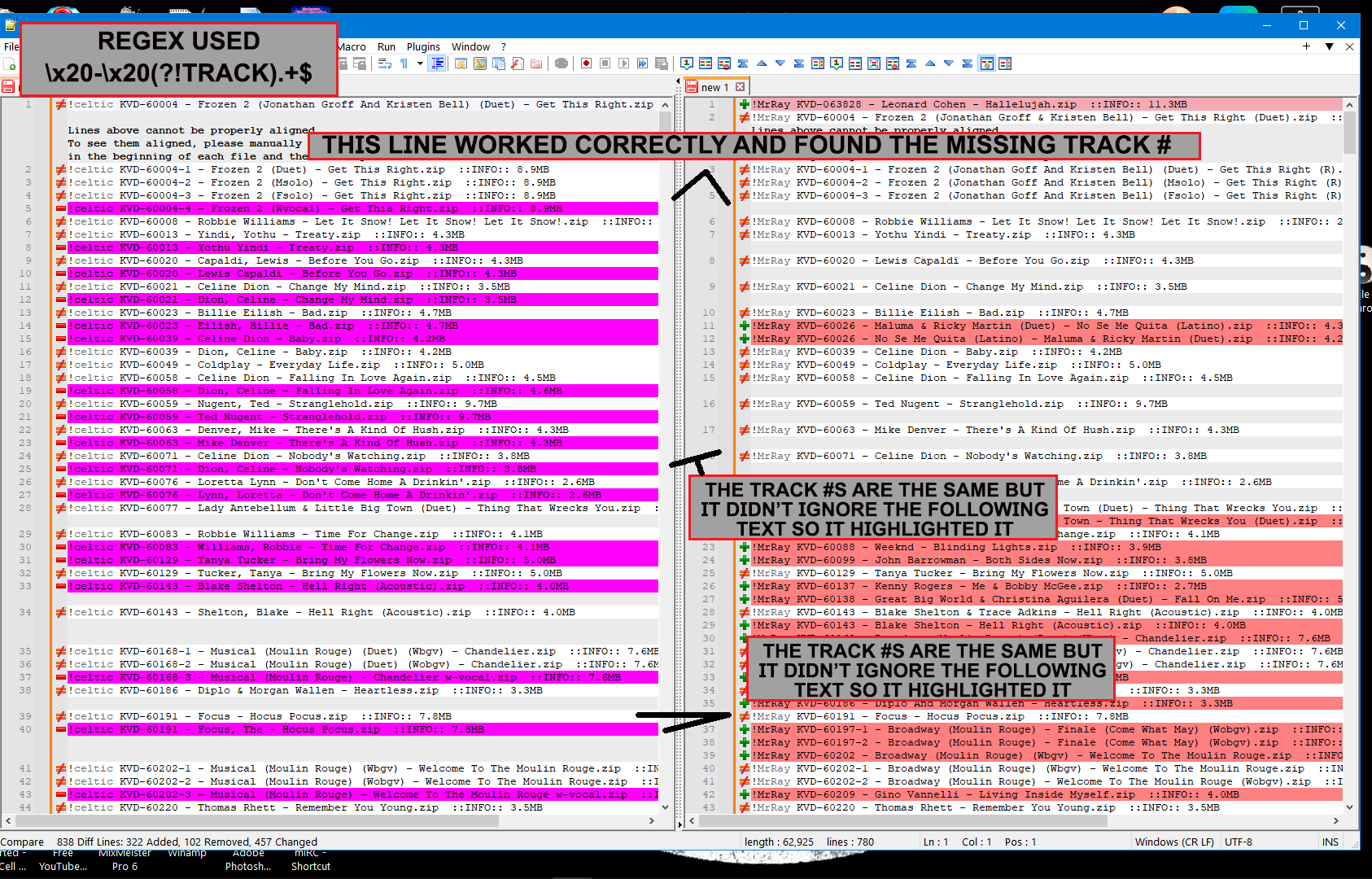
Thanks again guys
-
Hi, @ray-landolfi, @coises, @alan-kilborn and All,
@ray-landolfi, while seeing your picture, I note that the
ComparePlusplugin tell you to add a new empty line at the very beginning of your two files in order to compare them properly. So :-
First, follow this advice and add an empty line on top of each file
-
Secondly, change the Ignore regex and use this new one
^.+?\x20|\x20-\x20.+$ -
Thirdly, re-compare your two files
This time, everything should be OK !
For your information :
- Copy the three lines below, provided in your last post, in a new tab
!celtic KVD-59990 - Luther Vandross - Killing Me Softly.zip ::INFO:: 2.6Mb !beni-Lappy BKD-24733 - Brantley Gilbert - Devil Don’t Sleep.zip !MrRay SC7515-12 - Frank Sinatra - My Way.zip-
Open the Mark dialog of N++ (
Ctrl + M) -
Type in the regex
^.+?\x20|\x20-\x20.+$in the Find what: zone -
Un-check all the box options ( IMPORTANT )
-
Check only the
Wrap aroundoption -
Click on the
Mark Allbutton
=> All text should be highlighted, except for the zones
KBD-59990,BKD-24733andSC7515-12So, the highlighted zones are the zones excluded of the comparison by the
ComparePlusplugin. Thus, ONLY the partsKBD-59990,BKD-24733andSC7515-12will be taken in account in the comparison process !Now :
-
Open a real file of yours
-
Repeat the above MARK operation
=> You’ll can verify that everything, but the DISK-TRACK zones, is marked, as you expected to !
Best Regards,
guy038
-
-
I havent tried to sort files in a while and finally came back to check your responses…
Yes that latest regex worked to isolate just the files that were missing solely by the track info… Thank you again…
The added info on marking all those returned files at once however didn’t work… I only resumed the process today and have been marking them by hand… I tried to select all and copy the lines but it copies every line not just the compared lines so its back to individually marking them… it’s not fun but it beats looking through tens of thousands one at a time…
Thanks again for all your help…
If you have the urge to work out the marking issue
feel free…Ray
-
@ray-Landolfi said in Help Needed with COMPARE plugin..thanks in advance:
I tried to select all and copy the lines but it copies every line not just the compared lines so its back to individually marking them…
Check this description (I quote myself from the corresponding issue in ComparePlus repository):
After a compare you switch to the file which differences you want to copy, open the ComparePlus menu and use one of the new Bookmark… commands depending on what type of diffs you want to copy (for example Bookmark All Diffs in Current View). This will add a Notepad++ bookmark on every diff line matching that criteria. Next you can use the Notepad++ functionality to copy all bookmarked lines (you will find it under Search -> Bookmark sub-menu).
BR
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login