Function List and PL/SQL packages
-
I still had to split (first part)
import time # ----------------------------------------------------------------------------- import re from ctypes import windll, byref, wintypes, WINFUNCTYPE, Structure, sizeof # ----------------------------------------------------------------------------- # You need to indicate, in the TEMP_FILE_NAME variable, below, the # fully qualified file name of the TEXT file containing the REGEX(ES) to test ! # # Note : DOUBLE backslash is needed ( e.g. D:\\tests\\RegexTests.txt ) # # The COMMENT_CHAR can be changed, if needed, but keep in mind that, if your regex # begins with a COMMENT_CHAR, you must escape it, to make the whole regex working. # ( For instance the regex \#.* colors all the comments of a python file ) # # If you do not want to be informed, by coloring the current regex, that it didn't match # set the INFORM_ABOUT_NO_MATCHES flag to False # # 2 shortcuts can be configured: # - JUMP_FORWARD_SHORTCUT = to jump to matches in forward mode, # - JUMP_BACKWARD_SHORTCUT = for backward mode, # # IMPORTANT: # If using modifiers (SHIFT, CTRL and ALT) the ordering is critical. # A shortcut is defined as a python string using the plus sign to # separate modifiers from letters and function keys. # # E.g. 'SHIFT+CTRL+O' means you have to press SHIFT, CTRL and the literal O together. # As already said, if you would define 'CTRL+SHIFT+O' it won't work as the script # expects that SHIFT is the first modifier, if used, followed by CTRL and then ALT key. # # One can only define shortcuts which aren't used by notepad, scintilla # and plugins already. Meaning, you cannot define a shortcut 'CTRL+F' # as this is already used to show the file dialog # # The possible function keys are listed in dictionary FUNC_KEYS. # Basically, the keys are ESC and F1 to F12 # ---------------------------- <CONFIGURATION AREA> --------------------------- TEMP_FILE_NAME = 'C:\\RegexTester.txt' COMMENT_CHAR = '#' INFORM_ABOUT_NO_MATCHES = True JUMP_FORWARD_SHORTCUT = 'F9' JUMP_BACKWARD_SHORTCUT = 'SHIFT+F9' # ORDERING IS CRITICAL!! SHIFT CTRL ALT DEBUG_ON = True # ---------------------------- </CONFIGURATION AREA> --------------------------- FUNC_KEYS = {0x1B:'ESC', 0x70:'F1', 0x71:'F2', 0x72:'F3', 0x73:'F4', 0x74:'F5', 0x75:'F6', 0x76:'F7', 0x77:'F8', 0x78:'F9', 0x79:'F10', 0x7A:'F11', 0x7B:'F12',} # ----------------------------------------------------------------------------- # winapi constants - used by ctypes WM_KEYDOWN = 0x0100 WM_KEYUP = 0x0101 WM_SYSKEYDOWN = 0x104 WM_SYSKEYUP = 0x105 WM_SETFOUCS = 0x07 WM_KILLFOUCS = 0x08 VK_SHIFT = 0x10 VK_CONTROL = 0x11 VK_MENU = VK_ALT = 0x12 VK_UP = 0x26 VK_DOWN = 0x28 WndProcType = WINFUNCTYPE(wintypes.LONG, wintypes.HWND, wintypes.UINT, wintypes.WPARAM, wintypes.LPARAM) GWL_WNDPROC = -4 # ----------------------------------------------------------------------------- _g = globals() REGEX_TESTER_IS_RUNNING = _g.get('REGEX_TESTER_IS_RUNNING', False) OLD_WND_PROC = _g.get('OLD_WND_PROC', None) REGEX_TESTER_HWND = _g.get('REGEX_TESTER_HWND', None) REGEX_TESTER_INPUT_TAB = _g.get('REGEX_TESTER_INPUT_TAB', 0) COLORED_DOCS_LIST = _g.get('COLORED_DOCS_LIST', []) TIME_REGEX = False USE_PYTHON_ENGINE = False # ----------------------------------------------------------------------------- editor1.indicSetStyle(8,INDICATORSTYLE.CONTAINER) editor1.indicSetFore(8,(100,215,100)) editor1.indicSetAlpha(8,55) editor1.indicSetOutlineAlpha(8,255) editor1.indicSetUnder(8,True) editor1.indicSetStyle(9,INDICATORSTYLE.ROUNDBOX) editor1.indicSetFore(9,(195,215,184)) editor1.indicSetAlpha(9,55) editor1.indicSetOutlineAlpha(9,255) editor1.indicSetUnder(9,True) editor1.indicSetStyle(10,INDICATORSTYLE.ROUNDBOX) editor1.indicSetFore(10,(95,215,184)) editor1.indicSetAlpha(10,55) editor1.indicSetOutlineAlpha(10,255) editor1.indicSetUnder(10,True) editor2.indicSetStyle(11,INDICATORSTYLE.STRAIGHTBOX) editor2.indicSetFore(11,(255,0,0)) # (192,192,192) (255,0,0) editor2.indicSetAlpha(11,155) editor2.indicSetOutlineAlpha(11,255) editor2.indicSetUnder(11,True) editor2.indicSetStyle(12,INDICATORSTYLE.STRAIGHTBOX) editor2.indicSetFore(12,(0,255, 0)) editor2.indicSetAlpha(12,155) editor2.indicSetOutlineAlpha(12,255) editor2.indicSetUnder(12,True) editor1.indicSetStyle(13,INDICATORSTYLE.STRAIGHTBOX) editor1.indicSetFore(13,(0, 0, 255)) # (192,192,192) (0, 0, 255) editor1.indicSetAlpha(13,155) editor1.indicSetOutlineAlpha(13,55) editor1.indicSetUnder(13,True) editor2.indicSetStyle(14,INDICATORSTYLE.STRAIGHTBOX) editor2.indicSetFore(14,(255,120,0)) # (192,192,192) (255,0,0) editor2.indicSetAlpha(14,155) editor2.indicSetOutlineAlpha(14,255) editor2.indicSetUnder(14,True) # ----------------------------------------------------------------------------- IS_ODD = False PREVIOUS_REGEX = {} # POS_FIRST_OCCURANCE = None # POS_LAST_OCCURANCE = None NO_MATCH_FOUND = True MATCH_POSITIONS = {} CURRENT_BUFFER_ID = None LAST_POSITION = -1 FORWARD_SEARCH = 0 BACKWARD_SEARCH = 1 REGEX_LINE_CLEAR = 0 REGEX_LINE_NO_MATCH = 1 REGEX_LINE_INVALID = -1 # ----------------------------------------------------------------------------- class GUITHREADINFO(Structure): _fields_ = [ ('cbSize', wintypes.DWORD), ('flags', wintypes.DWORD), ('hwndActive', wintypes.HWND), ('hwndFocus', wintypes.HWND), ('hwndCapture', wintypes.HWND), ('hwndMenuOwner', wintypes.HWND), ('hwndMoveSize', wintypes.HWND), ('hwndCaret', wintypes.HWND), ('rcCaret', wintypes.RECT) ] def get_focused_window(): guiThreadInfo = GUITHREADINFO(cbSize=sizeof(GUITHREADINFO)) windll.user32.GetGUIThreadInfo(0, byref(guiThreadInfo)) return guiThreadInfo.hwndFocus # ----------------------------------------------------------------------------- def signature(func, args, kwargs, result): func = func.__name__ result = unicode(result) try: return u'{}({}, {}) -> {}'.format(func, unicode(args), unicode(kwargs), result) except: return u'{}(...) -> {}'.format(func, result) # ----------------------------------------------------------------------------- def time_function(func): def inner(*args, **kwargs): start = time.time() result = func(*args, **kwargs) stop = time.time() re_engine = u'python' if USE_PYTHON_ENGINE else u'boost' call_signature = signature(func, args, kwargs, result) console.write(u'{} took {} seconds using {} re engine\n'.format(call_signature, stop-start, re_engine)) return result return inner # ----------------------------------------------------------------------------- def match_found(m): global IS_ODD # global POS_FIRST_OCCURANCE # global POS_LAST_OCCURANCE global MATCH_POSITIONS global NO_MATCH_FOUND _match_positions = [] if DEBUG_ON: _m = m.span() console.write(u'Match:{} = {}\n'.format(_m, editor1.getTextRange(*_m))) if m.lastindex > 0: editor1.setIndicatorCurrent(8) editor1.indicatorFillRange(m.span(0)[0], m.span(0)[1] - m.span(0)[0]) _match_positions.append(m.span()) for i in range(1, m.lastindex + 1): if (m.span(i)[0] != m.span(0)[0]) or (m.span(i)[1] != m.span(0)[1]): editor1.setIndicatorCurrent(9 if IS_ODD else 10) editor1.indicatorFillRange(m.span(i)[0], m.span(i)[1] - m.span(i)[0]) IS_ODD = False if IS_ODD else True # POS_LAST_OCCURANCE = m.span(i) else: editor1.setIndicatorCurrent(9 if IS_ODD else 10) editor1.indicatorFillRange(m.span(0)[0], m.span(0)[1] - m.span(0)[0]) IS_ODD = False if IS_ODD else True # POS_LAST_OCCURANCE = m.span(0) _match_positions.append(m.span()) MATCH_POSITIONS[CURRENT_BUFFER_ID].extend(_match_positions) # if POS_FIRST_OCCURANCE == None: # POS_FIRST_OCCURANCE = m.span(0) NO_MATCH_FOUND = False # ----------------------------------------------------------------------------- def set_current_buffer_id(): global CURRENT_BUFFER_ID doc_idx = notepad.getCurrentDocIndex(0) CURRENT_BUFFER_ID = notepad.getFiles()[doc_idx][1] # ----------------------------------------------------------------------------- def track_document(): global COLORED_DOCS_LIST set_current_buffer_id() if not CURRENT_BUFFER_ID in COLORED_DOCS_LIST: COLORED_DOCS_LIST.append(CURRENT_BUFFER_ID) # ----------------------------------------------------------------------------- def clear_indicator(): for i in [8,9,10,13]: editor1.setIndicatorCurrent(i) editor1.indicatorClearRange(0,editor1.getTextLength()) # ----------------------------------------------------------------------------- def get_regex_flags(): global TIME_REGEX global USE_PYTHON_ENGINE TIME_REGEX = False USE_PYTHON_ENGINE = False flags = 0 flag_line = editor2.getLine(0) for char in range(flag_line.find('[')+1,flag_line.find(']')): if flag_line[char].upper() == 'I': flags |= re.IGNORECASE elif flag_line[char].upper() == 'L': flags |= re.LOCALE elif flag_line[char].upper() == 'M': flags |= re.MULTILINE elif flag_line[char].upper() == 'S': flags |= re.DOTALL elif flag_line[char].upper() == 'U': flags |= re.UNICODE elif flag_line[char].upper() == 'X': flags |= re.VERBOSE elif flag_line[char].upper() == 'T': TIME_REGEX = True elif flag_line[char].upper() == 'P': USE_PYTHON_ENGINE = True return flags # ----------------------------------------------------------------------------- @time_function def regex_exec(pattern, flags): try: for i in range(1): # editor1.research(pattern, lambda m: m, flags) editor1.research(pattern, match_found, flags) return True except: return False def regex(): # global POS_FIRST_OCCURANCE global PREVIOUS_REGEX global NO_MATCH_FOUND global MATCH_POSITIONS global IS_ODD IS_ODD = False MATCH_POSITIONS[CURRENT_BUFFER_ID] = [] clear_indicator() pattern = u'' if (editor2.getSelections() == 1) and (editor2.getSelectionEmpty() == False): start = editor2.lineFromPosition(editor2.getSelectionNStart(0)) end = editor2.lineFromPosition(editor2.getSelectionNEnd(0)) for i in range(start,end+1): pattern += editor2.getLine(i).rstrip('\r\n') else: pattern = current_regex() PREVIOUS_REGEX[CURRENT_BUFFER_ID] = pattern NO_MATCH_FOUND = True if (pattern != '' and pattern != '.' and pattern != '()' and not pattern.startswith(COMMENT_CHAR) and not pattern.isspace() and editor2.lineFromPosition(editor2.getCurrentPos()) > 0): # POS_FIRST_OCCURANCE = None regex_flag = get_regex_flags() if TIME_REGEX: if regex_exec(pattern,regex_flag): track_document() else: NO_MATCH_FOUND = None else: try: if USE_PYTHON_ENGINE: txt = editor1.getText() for m in re.finditer(pattern, txt, regex_flag): match_found(m) else: editor1.research(pattern, match_found, regex_flag) track_document() except: NO_MATCH_FOUND = None else: NO_MATCH_FOUND = None # ----------------------------------------------------------------------------- -
second part
def current_regex(): return editor2.getCurLine().rstrip() # ----------------------------------------------------------------------------- def regex_tester_doc_is_current_doc(): return REGEX_TESTER_INPUT_TAB == notepad.getCurrentBufferID() # ----------------------------------------------------------------------------- def scroll_to_position(_position): if _position is not None: start_pos, end_pos = _position editor1.setIndicatorCurrent(13) editor1.indicatorFillRange(start_pos, end_pos-start_pos) current_line = editor1.lineFromPosition(start_pos) editor1.ensureVisible(current_line) editor1.gotoPos(start_pos) editor1.verticalCentreCaret() editor1.setXCaretPolicy(CARETPOLICY.EVEN|CARETPOLICY.JUMPS,10) editor1.scrollCaret() # ----------------------------------------------------------------------------- def get_current_regex_position_and_length(): current_line = editor2.lineFromPosition(editor2.getCurrentPos()) if current_line != 0 and not editor2.getLine(current_line).startswith(COMMENT_CHAR): lenght_line = editor2.lineLength(current_line) position = editor2.positionFromLine(current_line) return position, lenght_line return None, None # ----------------------------------------------------------------------------- def mark_regex_line(match_indicator): position, lenght = get_current_regex_position_and_length() if position: if match_indicator == REGEX_LINE_NO_MATCH: editor2.setIndicatorCurrent(14) editor2.indicatorFillRange(position, lenght) elif match_indicator == REGEX_LINE_INVALID: editor2.setIndicatorCurrent(11) editor2.indicatorFillRange(position, lenght) else: for i in [11,14]: editor2.setIndicatorCurrent(i) editor2.indicatorClearRange(0, editor2.getTextLength()) # ----------------------------------------------------------------------------- def regex_tester_updateui_callback(args): if (regex_tester_doc_is_current_doc() and PREVIOUS_REGEX.get(CURRENT_BUFFER_ID, '') != current_regex()): mark_regex_line(REGEX_LINE_CLEAR) regex() if NO_MATCH_FOUND and INFORM_ABOUT_NO_MATCHES: mark_regex_line(REGEX_LINE_NO_MATCH) elif NO_MATCH_FOUND is None: mark_regex_line(REGEX_LINE_INVALID) # else: # scroll_to_position(POS_FIRST_OCCURANCE) # ----------------------------------------------------------------------------- def regex_tester_file_before_close_callback(args): if (args['bufferID'] == REGEX_TESTER_INPUT_TAB): stop_regex_tester() # ----------------------------------------------------------------------------- def regex_tester_buffer_activated_callback(args): global PREVIOUS_REGEX set_current_buffer_id() if not PREVIOUS_REGEX.has_key(CURRENT_BUFFER_ID): PREVIOUS_REGEX[CURRENT_BUFFER_ID] = '' if not REGEX_TESTER_IS_RUNNING: global COLORED_DOCS_LIST if args['bufferID'] in COLORED_DOCS_LIST: clear_indicator() COLORED_DOCS_LIST.remove(args['bufferID']) if len(COLORED_DOCS_LIST) == 0: notepad.clearCallbacks([NOTIFICATION.BUFFERACTIVATED]) # ----------------------------------------------------------------------------- def jump_through_matches(search_direction): global MATCH_POSITIONS global LAST_POSITION if MATCH_POSITIONS.has_key(CURRENT_BUFFER_ID): editor1.setIndicatorCurrent(13) editor1.indicatorClearRange(0,editor1.getTextLength()) match_count = len(MATCH_POSITIONS[CURRENT_BUFFER_ID]) if match_count == 0: return elif match_count == 1: _position = MATCH_POSITIONS[CURRENT_BUFFER_ID][0] else: current_position = editor1.getCurrentPos() if search_direction == 0: while True: _position = MATCH_POSITIONS[CURRENT_BUFFER_ID].pop(0) MATCH_POSITIONS[CURRENT_BUFFER_ID].append(_position) if _position[0] != LAST_POSITION: break else: while True: _position = MATCH_POSITIONS[CURRENT_BUFFER_ID].pop() MATCH_POSITIONS[CURRENT_BUFFER_ID].insert(0, _position) if _position[0] != LAST_POSITION: break LAST_POSITION = _position[0] scroll_to_position(_position) # ----------------------------------------------------------------------------- def regex_tester_doc_already_exists(): files = notepad.getFiles() f = [i[1][1] for i in enumerate(files) if i[1][0].upper() == TEMP_FILE_NAME.upper()] if f: return f[0] else: return 0 # ----------------------------------------------------------------------------- def color_regex_tester_status(): status_line = editor2.getLine(0) if REGEX_TESTER_IS_RUNNING: start = status_line.find('[') stop = status_line.find(']')+1 editor2.setIndicatorCurrent(12) editor2.indicatorFillRange(0,20) editor2.setIndicatorCurrent(12) editor2.indicatorFillRange(start,stop-start) else: editor2.setIndicatorCurrent(12) editor2.indicatorClearRange(0,len(status_line)) # ----------------------------------------------------------------------------- def start_regex_tester(): if TEMP_FILE_NAME == '': notepad.messageBox('You need to indicate, in the TEMP_FILE_NAME variable,\n' + 'the fully qualified file name of the TEXT file containing ' + 'the REGEX(ES) to test', 'TEMP_FILE_NAME is not set') return False current_document = 0 if notepad.getCurrentView() == 1 else notepad.getCurrentBufferID() global REGEX_TESTER_INPUT_TAB REGEX_TESTER_INPUT_TAB = regex_tester_doc_already_exists() if REGEX_TESTER_INPUT_TAB == 0 : notepad.open(TEMP_FILE_NAME) if notepad.getCurrentFilename().upper() == TEMP_FILE_NAME.upper(): REGEX_TESTER_INPUT_TAB = notepad.getCurrentBufferID() else: notepad.messageBox('Could not open specified file\n' + '{0}'.format(TEMP_FILE_NAME), 'Regex Tester Startup Failed', 0) return False else: notepad.activateBufferID(REGEX_TESTER_INPUT_TAB) if notepad.getCurrentView() != 1: notepad.menuCommand(MENUCOMMAND.VIEW_GOTO_ANOTHER_VIEW) STATUS_LINE = 'RegexTester isActive [] flags:sitp, ' STATUS_LINE += 'fwd:{} bwd:{}\r\n'.format(JUMP_FORWARD_SHORTCUT, JUMP_BACKWARD_SHORTCUT,) current_status_line = editor2.getLine(0) if 'RegexTester' in current_status_line: editor2.replace('RegexTester inActive', 'RegexTester isActive') else: editor2.insertText(0, STATUS_LINE) global REGEX_TESTER_IS_RUNNING REGEX_TESTER_IS_RUNNING = True color_regex_tester_status() set_current_buffer_id() global PREVIOUS_REGEX PREVIOUS_REGEX[CURRENT_BUFFER_ID] = '' editor.callbackSync(regex_tester_updateui_callback, [SCINTILLANOTIFICATION.UPDATEUI]) if current_document != 0: notepad.activateBufferID(current_document) editor2.setFocus(True) editor2.gotoLine(0) notepad.save() global REGEX_TESTER_HWND REGEX_TESTER_HWND = get_focused_window() notepad.callback(regex_tester_file_before_close_callback, [NOTIFICATION.FILEBEFORECLOSE]) notepad.callback(regex_tester_buffer_activated_callback, [NOTIFICATION.BUFFERACTIVATED]) return True # ----------------------------------------------------------------------------- def stop_regex_tester(): editor.clearCallbacks([SCINTILLANOTIFICATION.UPDATEUI]) notepad.clearCallbacks([NOTIFICATION.FILEBEFORECLOSE]) notepad.activateBufferID(REGEX_TESTER_INPUT_TAB) if regex_tester_doc_is_current_doc(): editor2.replace('RegexTester isActive', 'RegexTester inActive') notepad.save() global REGEX_TESTER_IS_RUNNING REGEX_TESTER_IS_RUNNING = False clear_indicator() color_regex_tester_status() mark_regex_line(0) global MATCH_POSITIONS MATCH_POSITIONS = {} _hook.unregister() editor1.setFocus(True) # ----------------------------------------------------------------------------- class Hook(): def __init__(self): self.nppHandle = windll.user32.FindWindowA('Notepad++',None) self.oldWndProc = None self.SHIFT_PRESSED = False self.CTRL_PRESSED = False self.ALT_PRESSED = False def register(self): if REGEX_TESTER_HWND: self.new_wnd_proc = WndProcType(self.sciWndProc) windll.kernel32.SetLastError(0) self.oldWndProc = windll.user32.SetWindowLongA(REGEX_TESTER_HWND, GWL_WNDPROC, self.new_wnd_proc) if self.oldWndProc: global OLD_WND_PROC OLD_WND_PROC = self.oldWndProc else: _err = 'GetLastError:{}'.format(windll.kernel32.GetLastError()) notepad.messageBox('Could not register hook:\n{}\n'.format(_err) + 'Shortcuts won\'t work', 'Register Hook Failure', 0) def unregister(self): if OLD_WND_PROC: self.oldWndProc = OLD_WND_PROC windll.kernel32.SetLastError(0) dummy = windll.user32.SetWindowLongA(REGEX_TESTER_HWND, GWL_WNDPROC, self.oldWndProc) if not dummy: _err = 'GetLastError:{}'.format(windll.kernel32.GetLastError()) notepad.messageBox('Could not unregister hook:\n{}\n'.format(_err) + 'It is recommended to save data and restart npp to prevent data loss', 'Unregister Hook Failure', 0) def sciWndProc(self, hWnd, msg, wParam, lParam): if msg in [WM_KEYDOWN, WM_SYSKEYDOWN]: if wParam == VK_SHIFT: self.SHIFT_PRESSED = True elif wParam == VK_CONTROL: self.CTRL_PRESSED = True elif wParam == VK_ALT: self.ALT_PRESSED = True elif msg in [WM_KEYUP,WM_SYSKEYUP]: if wParam == VK_SHIFT: self.SHIFT_PRESSED = False elif wParam == VK_CONTROL: self.CTRL_PRESSED = False elif wParam == VK_ALT: self.ALT_PRESSED = False else: modifier = 'SHIFT+' if self.SHIFT_PRESSED else '' modifier += 'CTRL+' if self.CTRL_PRESSED else '' modifier += 'ALT+' if self.ALT_PRESSED else '' if wParam in FUNC_KEYS: key_combo = '{}{}'.format(modifier,FUNC_KEYS[wParam]) else: key_combo = '{}{}'.format(modifier,chr(wParam)) func = dict_func.get(key_combo, None) if func: func() elif msg == WM_KILLFOUCS: self.SHIFT_PRESSED = False self.CTRL_PRESSED = False self.ALT_PRESSED = False return windll.user32.CallWindowProcA (self.oldWndProc, hWnd, msg, wParam, lParam) # ----------------------------------------------------------------------------- def main(): if REGEX_TESTER_IS_RUNNING: stop_regex_tester() else: if start_regex_tester(): _hook.register() # ----------------------------------------------------------------------------- dict_func={JUMP_FORWARD_SHORTCUT : lambda: jump_through_matches(FORWARD_SEARCH), JUMP_BACKWARD_SHORTCUT : lambda: jump_through_matches(BACKWARD_SEARCH),} # JUMP_TO_FIRST_SHORTCUT : lambda: scroll_to_position(POS_FIRST_OCCURANCE), # JUMP_TO_LAST_SHORTCUT : lambda: scroll_to_position(POS_LAST_OCCURANCE)} _hook = Hook() main() -
Thanx!
Will give it a try. -
one other thing.
The script doesn’t rerun the same regexes. Meaning,
if one line has^def.*()and the next line also and you move the cursor from the first to the next line
it doesn’t trigger another research. There must be a difference within the regexes.Cheers
Claudia -
One thing I forgot to mention,
special thanks to Scott and Guy which provided
a lot of information and doing beta testing.
Without there patient it wouldn’t be what it is.THANK YOU!!
Claudia -
@MAPJe71 said:
Although my regular expressions work in RegexBuddy I’m not able to get them to show any packages in Notepad++ Function List.
This needs more investigation, sorry I can’t give you a solution any time soon :(I’m not surprised since my regular expression worked too outside Function List.
Anyway, thank you very much for trying. -
@Jean-Marc-Malmedy after using @Claudia-Frank 's (thanks Claudia, awesome script!) script I was able to create a working parser. Needs some fine tuning/cleaning though.
-
@Jean-Marc-Malmedy could you try this one:
<parser displayName="SQL-mehods" id ="sql_syntax" commentExpr="(?x) # Utilize inline comments (see `RegEx - Pattern Modifiers`) (?s:\x2F\x2A.*?\x2A\x2F) # Multi Line Comment | (?m-s:-{2}.*$) # Single Line Comment " > <classRange mainExpr ="(?x) # Utilize inline comments (see `RegEx - Pattern Modifiers`) (?mi) # case insensitive ^\h* # optional leading blanks CREATE\s+(?:OR\s+REPLACE\s+)?PACKAGE\s+(?:BODY\s+)? # start-of-package indicator (?:\w+\.)? # schema name, optional (?'PACKAGE_ID'\w+) # package name (?s:.*?) # whatever, until... ^\h*END(?:\s+\k'PACKAGE_ID')?\s*; # ...end-of-package indicator " > <className> <nameExpr expr="(?i:PACKAGE\s+(?:BODY\s+)?)\K(?:\w+\.)?\w+" /> </className> <function mainExpr="^\h*(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*\([^()]*\)" > <functionName> <funcNameExpr expr="\w+" /> </functionName> </function> </classRange> <function mainExpr="^\h*(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*\([^()]*\)" > <functionName> <nameExpr expr="\w+" /> </functionName> </function> </parser> -
Wonderful, it works.
I just had to make to small modifications:
- making the parenthesis optional for the declaration of function or procedure
- starting the declaration of a function or procedure outside a package with “create or replace”
This is my final version of the parser:
<parser displayName="SQL-mehods" id ="sql_syntax" commentExpr="(?x) # Utilize inline comments (see `RegEx - Pattern Modifiers`) (?s:\x2F\x2A.*?\x2A\x2F) # Multi Line Comment | (?m-s:-{2}.*$) # Single Line Comment " > <classRange mainExpr ="(?x) # Utilize inline comments (see `RegEx - Pattern Modifiers`) (?mi) # case insensitive ^\h* # optional leading blanks CREATE\s+(?:OR\s+REPLACE\s+)?PACKAGE\s+(?:BODY\s+)? # start-of-package indicator (?:\w+\.)? # schema name, optional (?'PACKAGE_ID'\w+) # package name (?s:.*?) # whatever, until... ^\h*END(?:\s+\k'PACKAGE_ID')?\s*; # ...end-of-package indicator " > <className> <nameExpr expr="(?i:PACKAGE\s+(?:BODY\s+)?)\K(?:\w+\.)?\w+" /> </className> <function mainExpr="^\h*(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*(\([^()]*\)){0,1}" > <functionName> <funcNameExpr expr="\w+" /> </functionName> </function> </classRange> <function mainExpr="^\h*CREATE\s+(?:OR\s+REPLACE\s+)?(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*(\([^()]*\)){0,1}" > <functionName> <nameExpr expr="\w+" /> </functionName> </function> </parser>Many many thanks for your help.
Jean-Marc
-
@Jean-Marc-Malmedy FYI:
{0,1}can be replaced with a?. -
Yes, indeed. Thanks for the suggestion.
-
You’re welcome!
-
HI! Wonderful, I came here for this… :D
I have tried his solution, but immediately bumped into a serious problem:
I can see only the first method in my package. :(if i understand correctly, the classRange - mainExpr should match for the whole package body.
I think the problem lies here at the last line:^\h*END(?:\s+\k'PACKAGE_ID')?\s*;this matches the first “end;” in the code.
In a real-world code there is lots of “end;” statements, as we can close methods with it, and even there is unnamed blocks inside them.
Example:
CREATE OR REPLACE PACKAGE BODY sch_001.pck_001 AS PROCEDURE p_proc_001(pn_id PLS_INTEGER) IS sd date; BEGIN -- unnamed block begin: "try-catch" in PL/SQL begin select sysdate into sd from dual; exception when others then sd := null; end; -- do something else END; END pck_001; /Please help me on this.
Unfortunately I’m not really familiar with greedy multi-line regexp statements…For start, it would be OK, if it could end only on the end of file…
It would be a huge help for us! :)
-
@Gábor-Madács
I don’t understand your problem.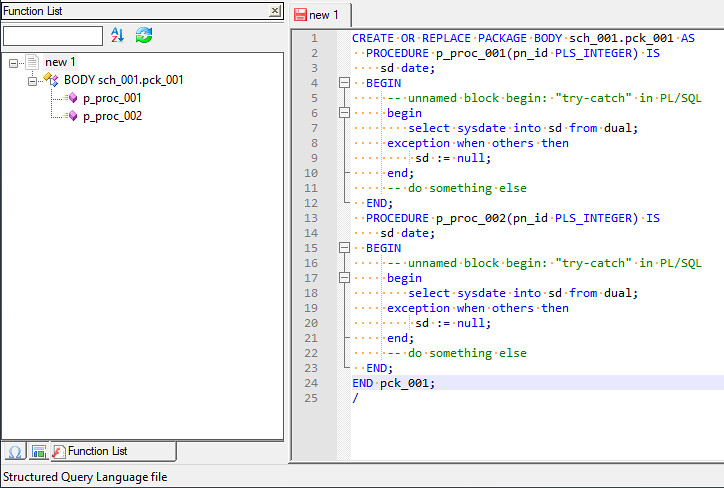
-
Thank you for the quick response!
Your results are better than mine… :)
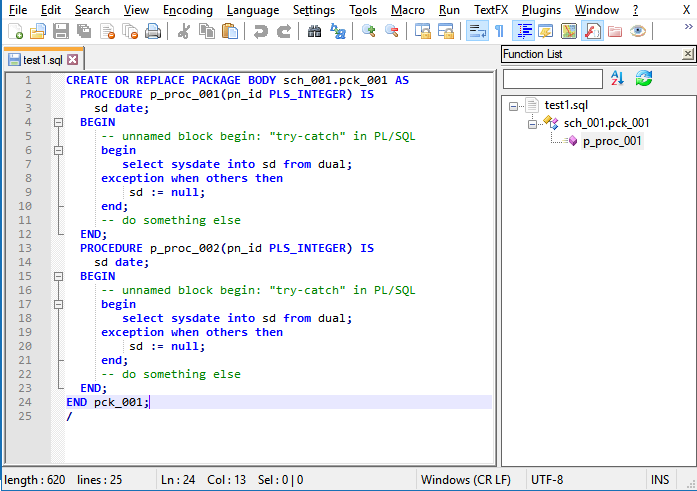
What parser do you use? This is by the one from the last post from Jean-Marc Malmedy.
I have also tried the one before this - posted by you - that is showed the second procedure too, but out of the body.
(That’s because of here no “CREATE” in the procedure name - that is a difference between the two version. “CREATE” is for procedures not in packages.)Please post your fine parser version! :)
Gabor
-
@Gábor-Madács See my post on GitHub.
-
@MAPJe71 Wow… Thank you very much! :D
(May I note, now the “I don’t understand your problem.” seems somewhat unfounded… ;) )Work like a charm! (Looks like a charm, indeed… ;) )
Hope, it will be part of the official NPP distribution!
Thank you again!
Gabor
-
Beautiful work! But i have a little bit problem.
When the procedure or function name is missing after the “end”, it seems the parser consumes the file to the end skipping other functions!Example:
function foo is
Begin
–Todo function logic…
null;
End;function bar is…
In this case function bar (and other functions after it) will be skipped! I know it is not the best practice but it’s pretty common.
although it’s simple to fix that on the source code I will appreciate your help to fix the parser.Thanks in advance!
-
Hi guys, after a few little changes it seems to work now for all my Plsql files…
<?xml version=“1.0” encoding=“UTF-8” ?>
<!-- ==========================================================================\To learn how to make your own language parser, please check the following link: https://npp-user-manual.org/docs/function-list/ |
=========================================================================== -->
<NotepadPlus>
<functionList>
<!-- ========================================================= [ PL/SQL ] -->
<parser
displayName=“SQL-mehods”
id =“sql_syntax”
commentExpr=“(?x) # Utilize inline comments (seeRegEx - Pattern Modifiers)
(?s:\x2F\x2A.?\x2A\x2F) # Multi Line Comment
| (?m-s:-{2}.$) # Single Line Comment
" >
<classRange
mainExpr =”(?x) # Utilize inline comments (seeRegEx - Pattern Modifiers)
(?mi) # case insensitive
^\h* # optional leading blanks
(CREATE\s+(?:OR\s+REPLACE\s+)?)?PACKAGE\s+(?:BODY\s+)? # start-of-package indicator
(?:\w+.)? # schema name, optional
(?‘PACKAGE_ID’\w+) # package name
(?s:.?) # whatever, until…
^\hEND(?:\s+\k’PACKAGE_ID’)\s*; # …end-of-package indicator
" >
<className><nameExpr expr=“(?i:PACKAGE\s+(?:BODY\s+)?)\K(?:\w+.)?\w+” /></className>
<function mainExpr=“^\h*(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*(([^()]))?“>
<functionName><funcNameExpr expr=”\w+" /></functionName>
</function>
</classRange>
<function mainExpr="^\h(CREATE\s+(?:OR\s+REPLACE\s+)?)?(?i:FUNCTION|PROCEDURE)\s+\K\w+\s*(([^()]*))?” >
<functionName><nameExpr expr=“\w+” /></functionName>
</function>
</parser>
</functionList>
</NotepadPlus>I also indented it my own way, sorry for that, enjoy it!