Invisible characters unwanted
-
Also, if you want one command to do the normal
Show All Charactersplus showing these four Zero Width characters,# script = Show All Characters (including ZeroWidth) editor.setRepresentation(u'\u200B', "ZWS") editor.setRepresentation(u'\u200C', "ZWNJ") editor.setRepresentation(u'\u200D', "ZWJ") editor.setRepresentation(u'\uFEFF', "ZWNBSP") # if you want to _also_ show all characters with this script, # first pick a different View > Show Symbols option, # then pick this one (each is a toggle, so don't want to accidentally hide all characters if show-all was already selected) notepad.menuCommand(MENUCOMMAND.VIEW_EOL) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS)And similarly to un-set
Show All Charactersas well as clearing the four Zero Width representations:# script = Don'tShow All Characters (including ZeroWidth) editor.clearRepresentation(u'\u200B') editor.clearRepresentation(u'\u200C') editor.clearRepresentation(u'\u200D') editor.clearRepresentation(u'\uFEFF') # if you want to _also_ hide all characters with this script, # first pick a different View > Show Symbols option, # then pick this one twice (each is a toggle, so don't want to accidentally show all characters if show-all was already cleared) notepad.menuCommand(MENUCOMMAND.VIEW_EOL) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS)As explained in my comments, I use the VIEW_EOL to change out of VIEW_ALL_CHARACTERS, no matter what the state of the VIEW_ALL_CHARACTERS toggle is; then I use VIEW_ALL_CHARACTERS once to set it or twice to clear it. If, instead, you’d like your DontShowAllCharacters to revert to “Show EOL” or “Show Whitespace and Tab”, then instead of VIEW_EOL/VIEW_ALL_CHARACTERS/VIEW_ALL_CHARACTERS sequence of three, you could just use VIEW_EOL (a sequence of one to show EOL) or VIEW_TAB_SPACE. (Though, to be safe, you might want a two-sequence of VIEW_ALL_CHARACTERS/VIEW_EOL or VIEW_ALL_CHARACTERS/VIEW_TAB_SPACE. It would be easier if there were a notepad.getMenuCommandState() or similar command that reads back the current state of a toggled menu command.)
-
thx,
there are editor.getViewEOL() and editor.getViewWS() functions available
to retrieve current state. But instead of using setView… I would recommend using
notepad.menuCommand(MENUCOMMAND…) to be in sync with notepad++ itself.Cheers
Claudia -
I’ve noticed that after doing an
editor.setRepresentation()it shows the new character representation in the currently active tab, but if I switch tabs to one which also has characters that should be shown by this, they aren’t shown. Switching back to the tab I started in, the representation I set has also disappeared.I think I know why this is (well, kinda, :-) ), but I’m surprised it wasn’t mentioned before in this thread.
-
@Alan-Kilborn said in Invisible characters unwanted:
I’ve noticed that after doing an editor.setRepresentation() it shows the new character representation in the currently active tab, but if I switch tabs to one which also has characters that should be shown by this, they aren’t shown. Switching back to the tab I started in, the representation I set has also disappeared.
Here’s a little script to avoid that problem, I call it
SetRepresentationForSpecialCharacters.py:# -*- coding: utf-8 -*- from Npp import editor, notepad, NOTIFICATION class SRFSC(object): def __init__(self): notepad.callback(self.callback_npp_BUFFERACTIVATED, [NOTIFICATION.BUFFERACTIVATED]) self.callback_npp_BUFFERACTIVATED(None) def callback_npp_BUFFERACTIVATED(self, args): editor.setRepresentation(u'\u200B', "ZWS") editor.setRepresentation(u'\u200C', "ZWNJ") editor.setRepresentation(u'\u200D', "ZWJ") editor.setRepresentation(u'\u200E', "LTR") # left-to-right mark editor.setRepresentation(u'\uFEFF', "ZWNBSP")I run it from my
startup.pywith this segment of code:import SetRepresentationForSpecialCharacters SetRepresentationForSpecialCharacters.SRFSC() -
@Alan-Kilborn said in Invisible characters unwanted:
editor.setRepresentation(u'\u200E', "LTR") # left-to-right mark`Apparently this LTR issue is really annoying to you. :-)
Looking at http://www.fileformat.info/info/unicode/block/general_punctuation/images.htm, there are other control characters in that block, so if your data is more varied, I might expand that to:
# zero width in name editor.setRepresentation(u'\u200B', "ZWS") editor.setRepresentation(u'\u200C', "ZWNJ") editor.setRepresentation(u'\u200D', "ZWJ") editor.setRepresentation(u'\uFEFF', "ZWNBSP") # also zero width editor.setRepresentation(u'\u2060', "WJ") # word joiner (separate from ZWJ, but still claims zero width) # directional controls and other toggles editor.setRepresentation(u'\u200E', "LTR") # left-to-right mark editor.setRepresentation(u'\u200F', "RTL") # right-to-left mark editor.setRepresentation(u'\u202A', "EMBL") # left-to-right embedding editor.setRepresentation(u'\u202B', "EMBR") # right-to-left embedding editor.setRepresentation(u'\u202C', "EMBP") # pop directional formatting editor.setRepresentation(u'\u202A', "OVRL") # left-to-right override editor.setRepresentation(u'\u202B', "OVRR") # right-to-left override editor.setRepresentation(u'\u2066', "ISOL") # left-to-right isolate editor.setRepresentation(u'\u2067', "ISOR") # right-to-left isolate editor.setRepresentation(u'\u2068', "ISO1") # first strong isolate editor.setRepresentation(u'\u2069', "ISOP") # pop directional isolate editor.setRepresentation(u'\u206A', "SYMI") # inhibit symmetric swapping editor.setRepresentation(u'\u206B', "SYMA") # activate symmetric swapping editor.setRepresentation(u'\u206C', "ARAI") # inhibit arabic form shaping editor.setRepresentation(u'\u206D', "ARAA") # activate arabic form shaping editor.setRepresentation(u'\u206E', "SHNA") # national digit shapes editor.setRepresentation(u'\u206E', "SHNO") # nominal digit shapesBut, most important is to include the characters that you, as the user of the script, might run across.
-
Hello, @peterjones, @alan-kilborn and All,
From these two links :
https://www.unicode.org/charts/PDF/U2000.pdf
https://www.unicode.org/charts/PDF/UFE70.pdf
I just rewrote these
26special characters :-
By increasing Unicode code-point order
-
With their exact code-points ( some typos corrected )
-
With their normalized Unicode character representation
So, here is a new version of the @alan-kilborn’s
SetRepresentationForSpecialCharacters.pyfile, with the merged lines from the @peterjones’s script, without using thestartup.pyfile :# -*- coding: utf-8 -*- from Npp import editor, notepad, NOTIFICATION class SRFSC(object): def __init__(self): notepad.callback(self.callback_npp_BUFFERACTIVATED, [NOTIFICATION.BUFFERACTIVATED]) self.callback_npp_BUFFERACTIVATED(None) def callback_npp_BUFFERACTIVATED(self, args): # FORMAT chars editor.setRepresentation(u'\u200B', "ZWSP") # zero width space editor.setRepresentation(u'\u200C', "ZWNJ") # zero width non-joiner editor.setRepresentation(u'\u200D', "ZWJ") # zero width joiner editor.setRepresentation(u'\u200E', "LRM") # left-to-right mark editor.setRepresentation(u'\u200F', "RLM") # right-to-left mark editor.setRepresentation(u'\u202A', "LRE") # left-to-right embedding editor.setRepresentation(u'\u202B', "RLE") # right-to-left embedding editor.setRepresentation(u'\u202C', "PDF") # pop directional formatting editor.setRepresentation(u'\u202D', "LRO") # left-to-right override editor.setRepresentation(u'\u202E', "RLO") # right-to-left override editor.setRepresentation(u'\u2060', "WJ") # word joiner ( zero width no-break space ) # INVISIBLE chars editor.setRepresentation(u'\u2061', "FA") # function application editor.setRepresentation(u'\u2062', "IT") # invisible times editor.setRepresentation(u'\u2063', "IS") # invisible separator editor.setRepresentation(u'\u2064', "IP") # invisible plus # FORMAT chars editor.setRepresentation(u'\u2066', "LRI") # left-to-right isolate editor.setRepresentation(u'\u2067', "RLI") # right-to-left isolate editor.setRepresentation(u'\u2068', "FSI") # first strong isolate editor.setRepresentation(u'\u2069', "PDI") # pop directional isolate # DEPRECATED chars editor.setRepresentation(u'\u206A', "ISS") # inhibit symmetric swapping editor.setRepresentation(u'\u206B', "ASS") # activate symmetric swapping editor.setRepresentation(u'\u206C', "IAFS") # inhibit arabic form shaping editor.setRepresentation(u'\u206D', "AAFS") # activate arabic form shaping editor.setRepresentation(u'\u206E', "NADS") # national digit shapes editor.setRepresentation(u'\u206F', "NODS") # nominal digit shapes # SPECIAL char editor.setRepresentation(u'\uFEFF', "BOM") # byte order mark ( zero width no-break space : deprecated, see U+2060 ) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS) SRFSC()
-
On the other hand, you may quickly verify if some special characters exist in current file, using the
Markdialog :- MARK
[\x{200B}-\x{200F}\x{202A}-\x{202E}\x{2060}-\x{2064}\x{2066}-\x{206F}\x{FEFF}]
- MARK
=> You should see some thin
redmarks and , since thev7.9.2N++ version, you can copy all these chars in a new tab, for further examination, with theCopy Marked Textbutton !-
A third solution could be to perform a regex S/R ( which can be recorded as a macro) to replace any of these special characters with their Unicode representation :
-
SEARCH
(\x{200B})|(\x{200C})|(\x{200D})|(\x{200E})|(\x{200F})|(\x{202A})|(\x{202B})|(\x{202C})|(\x{202D})|(\x{202E})|(\x{2060})|(\x{2061})|(\x{2062})|(\x{2063})|(\x{2064})|(\x{2066})|(\x{2067})|(\x{2068})|(\x{2069})|(\x{206A})|(\x{206B})|(\x{206C})|(\x{206D})|(\x{206E})|(\x{206F})|(\x{FEFF}) -
REPLACE
(?1[ZWSP])(?2[ZWNJ])(?3[ZWJ])(?4[LRM])(?5[RLM])(?6[LRE])(?7[RLE])(?8[PDF])(?9[LRO])(?10[RLO])(?11[WJ])(?12[FA])(?13[IT])(?14[IS])(?15[IP])(?16[LRI])(?17[RLI])(?18[FSI])(?19[PDI])(?20[ISS])(?21[ASS])(?22[IAFS])(?23[AAFS])(?24[NADS])(?25[NODS])(?26[BOM]) -
Once the characters have been noted and/or the lines bookmarked, for further analyze, then just undo the replacements with
Ctrl + Z
-
Best Regards,
guy038
-
-
Is it your intent with your last posting to say that, with the PDFs from unicode.org, we now have a “complete” list of invisible characters, and a script can be made that covers them all, using correct abbreviations in their N++ representations?
At first look, it seems that anything in those docs that is shown inside a “dashed box”, e.g.:

is a good candidate for a new representation being assigned in a N++ script like the ones above?
If this is the case, I’m surprised that in the script you presented, not all of the seemingly invisible characters from the documents are in the script.
EDIT: Hmm, not sure now about the “dashed box” as I just noticed some dashed boxes in the doc containing things like
,and+, so probably the dashed box does not truly identify something as an “invisible character”. -
Hi, @alan-kilborn, @peterjones and All,
From the
UnicodeData.txtfile https://www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txtI just extract the lines relative to any character which has a General Category property
CforZs(3rdfield of the list ), i.e. theFormat_ControlandSpace_Separatorcharacters. Indeed, depending of the current font used, these characters may be :-
Not displayed at all ( Invisible )
-
Displayed as a question mark, inside a square or lozenge
-
Displayed as a white square box
-
Displayed with a wrong width ( case of a space char )
As a remainder, below, here is a table, giving all values of the Unicode
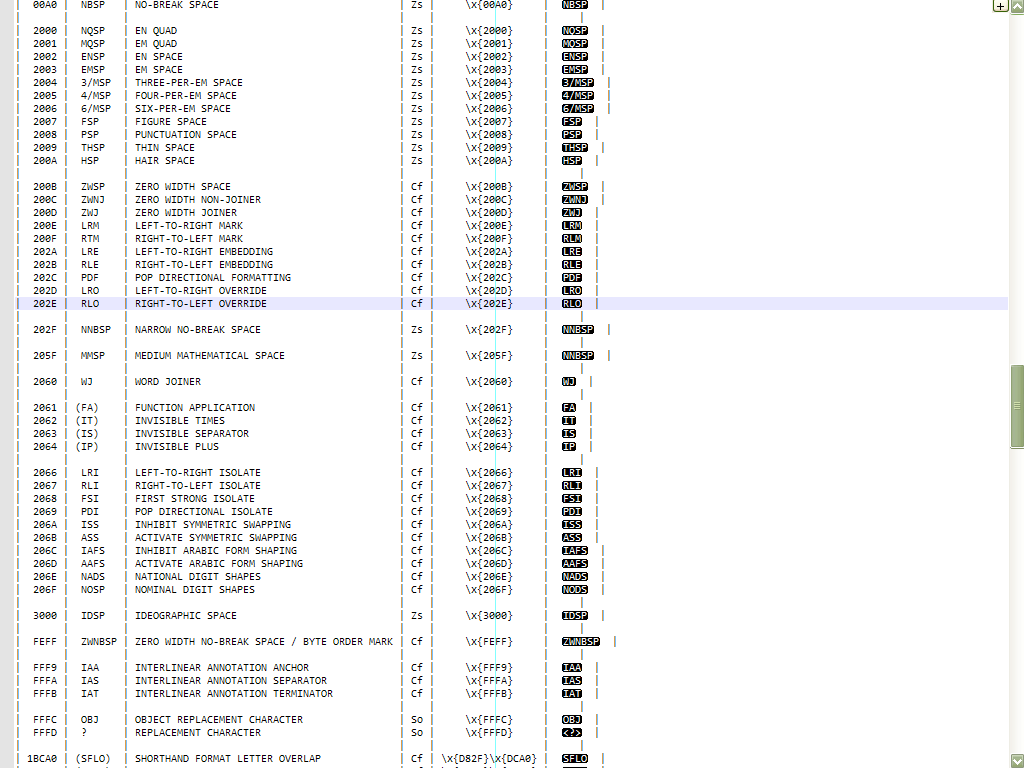
General Categoryproperty :GENERAL_CATEGORY Values : •----•-----------------------•------------------------------------------------------ | Abv| Value | Description •----•-----------------------•------------------------------------------------------ | Lu | Uppercase_Letter | an UPPERCASE letter | Ll | Lowercase_Letter | a LOWERCASE letter | Lt | Titlecase_Letter | A DI-GRAPHIC character, with first part UPPERCASE | | | | LC | Cased_Letter | Lu | Ll | Lt | | | | Lm | Modifier_Letter | A MODIFIER letter | Lo | Other_Letter | Other letters, including SYLLABLES and IDEOGRAPHS | | | | L | Letter | Lu | Ll | Lt | Lm | Lo | | | | Mn | Nonspacing_Mark | A NON-SPACING COMBINING mark (zero advance width) | Mc | Spacing_Mark | A SPACING COMBINING mark (positive advance width) | Me | Enclosing_Mark | An ENCLOSING COMBINING mark | | | | M | Mark | Mn | Mc | Me | | | | Nd | Decimal_Number | A DECIMAL digit | Nl | Letter_Number | A LETTERLIKE numeric character | No | Other_Number | A NUMERIC character of other type | | | | N | Number | Nd | Nl | No | | | | Pc | Connector_Punctuation | A CONNECTING PUNCTUATION mark, like a tie | Pd | Dash_Punctuation | A DASH or HYPHEN punctuation mark | Ps | Open_Punctuation | An OPENING PUNCTUATION mark (of a pair) | Pe | Close_Punctuation | A CLOSING PUNCTUATION mark (of a pair) | Pi | Initial_Punctuation | An INITIAL QUOTATION mark | Pf | Final_Punctuation | A FINAL QUOTATION mark | Po | Other_Punctuation | A PUNCTUATION mark of other type | | | | P | Punctuation | Pc | Pd | Ps | Pe | Pi | Pf | Po | | | | Sm | Math_Symbol | A symbol of MATHEMATICAL use | Sc | Currency_Symbol | A CURRENCY sign | Sk | Modifier_Symbol | A NON-LETTERLIKE MODIFIER symbol | So | Other_Symbol | A SYMBOL of other type | | | | S | Symbol | Sm | Sc | Sk | So | | | | Zs | Space_Separator | A SPACE character ( of various NON-ZERO width ) | Zl | Line_Separator | U+2028 LINE SEPARATOR only | Zp | Paragraph_Separator | U+2029 PARAGRAPH SEPARATOR only | | | | Z | Separator | Zs | Zl | Zp | | | | Cc | Control | A C0 or C1 CONTROL code | Cf | Format | A FORMAT CONTROL character | Cs | Surrogate | A SURROGATE code point | Co | Private_Use | A PRIVATE-USE character | Cn | Unassigned | A reserved UNASSIGNED code point or a NON-CHARACTER | | | | C | Other | Cc | Cf | Cs | Co | Cn •----•-----------------------•------------------------------------------------------
And, here is the table of these
178extracted characters :•-------•---------•---------------------------------------------•----•-----------•------------------•------- | Code | Abbrev. | Character Name | Cg | To search | N++ Regex | Char •-------•---------•---------------------------------------------•----•-----------•------------------•------- | 0020 | SP | SPACE | Zs | No | \x{0020} | | | | | | | | | 00A0 | NBSP | NO-BREAK SPACE | Zs | Yes | \x{00A0} | | | | | | | | | 00AD | SHY | SOFT HYPHEN | Cf | Yes | \x{00AD} | | | | | | | | | 0600 | | ARABIC NUMBER SIGN | Cf | No | \x{0600} | | 0601 | | ARABIC SIGN SANAH | Cf | No | \x{0601} | | 0602 | | ARABIC FOOTNOTE MARKER | Cf | No | \x{0602} | | 0603 | | ARABIC SIGN SAFHA | Cf | No | \x{0603} | | 0604 | | ARABIC SIGN SAMVAT | Cf | No | \x{0604} | | 0605 | | ARABIC NUMBER MARK ABOVE | Cf | No | \x{0605} | | 061C | ALM | ARABIC LETTER MARK | Cf | No | \x{061C} | | 06DD | | ARABIC END OF AYAH | Cf | No | \x{06DD} | | | | | | | | | 070F | SAM | SYRIAC ABBREVIATION MARK | Cf | No | \x{070F} | | | | | | | | | 08E2 | | ARABIC DISPUTED END OF AYAH | Cf | No | \x{08E2} | | | | | | | | | 1680 | | OGHAM SPACE MARK | Zs | No | \x{1680} | | | | | | | | | 180E | MVS | MONGOLIAN VOWEL SEPARATOR | Cf | No | \x{180E} | | | | | | | | | 2000 | NQSP | EN QUAD | Zs | Yes | \x{2000} | | 2001 | MQSP | EM QUAD | Zs | Yes | \x{2001} | | 2002 | ENSP | EN SPACE | Zs | Yes | \x{2002} | | 2003 | EMSP | EM SPACE | Zs | Yes | \x{2003} | | 2004 | 3/MSP | THREE-PER-EM SPACE | Zs | Yes | \x{2004} | | 2005 | 4/MSP | FOUR-PER-EM SPACE | Zs | Yes | \x{2005} | | 2006 | 6/MSP | SIX-PER-EM SPACE | Zs | Yes | \x{2006} | | 2007 | FSP | FIGURE SPACE | Zs | Yes | \x{2007} | | 2008 | PSP | PUNCTUATION SPACE | Zs | Yes | \x{2008} | | 2009 | THSP | THIN SPACE | Zs | Yes | \x{2009} | | 200A | HSP | HAIR SPACE | Zs | Yes | \x{200A} | | | | | | | | | 200B | ZWSP | ZERO WIDTH SPACE | Cf | Yes | \x{200B} | | 200C | ZWNJ | ZERO WIDTH NON-JOINER | Cf | Yes | \x{200C} | | 200D | ZWJ | ZERO WIDTH JOINER | Cf | Yes | \x{200D} | | 200E | LRM | LEFT-TO-RIGHT MARK | Cf | Yes | \x{200E} | | 200F | RLM | RIGHT-TO-LEFT MARK | Cf | Yes | \x{200F} | | 202A | LRE | LEFT-TO-RIGHT EMBEDDING | Cf | Yes | \x{202A} | | 202B | RLE | RIGHT-TO-LEFT EMBEDDING | Cf | Yes | \x{202B} | | 202C | PDF | POP DIRECTIONAL FORMATTING | Cf | Yes | \x{202C} | | 202D | LRO | LEFT-TO-RIGHT OVERRIDE | Cf | Yes | \x{202D} | | 202E | RLO | RIGHT-TO-LEFT OVERRIDE | Cf | Yes | \x{202E} | | | | | | | | | 202F | NNBSP | NARROW NO-BREAK SPACE | Zs | Yes | \x{202F} | | | | | | | | | 205F | MMSP | MEDIUM MATHEMATICAL SPACE | Zs | Yes | \x{205F} | | | | | | | | | 2060 | WJ | WORD JOINER | Cf | Yes | \x{2060} | | | | | | | | | 2061 | (FA) | FUNCTION APPLICATION | Cf | Yes | \x{2061} | | 2062 | (IT) | INVISIBLE TIMES | Cf | Yes | \x{2062} | | 2063 | (IS) | INVISIBLE SEPARATOR | Cf | Yes | \x{2063} | | 2064 | (IP) | INVISIBLE PLUS | Cf | Yes | \x{2064} | | | | | | | | | 2066 | LRI | LEFT-TO-RIGHT ISOLATE | Cf | Yes | \x{2066} | | 2067 | RLI | RIGHT-TO-LEFT ISOLATE | Cf | Yes | \x{2067} | | 2068 | FSI | FIRST STRONG ISOLATE | Cf | Yes | \x{2068} | | 2069 | PDI | POP DIRECTIONAL ISOLATE | Cf | Yes | \x{2069} | | 206A | ISS | INHIBIT SYMMETRIC SWAPPING | Cf | Yes | \x{206A} | | 206B | ASS | ACTIVATE SYMMETRIC SWAPPING | Cf | Yes | \x{206B} | | 206C | IAFS | INHIBIT ARABIC FORM SHAPING | Cf | Yes | \x{206C} | | 206D | AAFS | ACTIVATE ARABIC FORM SHAPING | Cf | Yes | \x{206D} | | 206E | NADS | NATIONAL DIGIT SHAPES | Cf | Yes | \x{206E} | | 206F | NOSP | NOMINAL DIGIT SHAPES | Cf | Yes | \x{206F} | | | | | | | | | 3000 | IDSP | IDEOGRAPHIC SPACE | Zs | Yes | \x{3000} | | | | | | | | | FEFF | ZWNBSP | ZERO WIDTH NO-BREAK SPACE / BYTE ORDER MARK | Cf | Yes | \x{FEFF} | | | | | | | | | FFF9 | IAA | INTERLINEAR ANNOTATION ANCHOR | Cf | Yes | \x{FFF9} | | FFFA | IAS | INTERLINEAR ANNOTATION SEPARATOR | Cf | Yes | \x{FFFA} | | FFFB | IAT | INTERLINEAR ANNOTATION TERMINATOR | Cf | Yes | \x{FFFB} | | | | | | | | | 110BD | (KNS) | KAITHI NUMBER SIGN | Cf | No | \x{D804}\x{DCBD} | | 110CD | (KNSA) | KAITHI NUMBER SIGN ABOVE | Cf | No | \x{D804}\x{DCCD} | | | | | | | | | 13430 | (EHVJ) | EGYPTIAN HIEROGLYPH VERTICAL JOINER | Cf | No | \x{D80D}\x{DC30} | | 13431 | (EHHJ) | EGYPTIAN HIEROGLYPH HORIZONTAL JOINER | Cf | No | \x{D80D}\x{DC31} | | 13432 | (EHITS) | EGYPTIAN HIEROGLYPH INSERT AT TOP START | Cf | No | \x{D80D}\x{DC32} | | 13433 | (EHIBS) | EGYPTIAN HIEROGLYPH INSERT AT BOTTOM START | Cf | No | \x{D80D}\x{DC33} | | 13434 | (EHITE) | EGYPTIAN HIEROGLYPH INSERT AT TOP END | Cf | No | \x{D80D}\x{DC34} | | 13435 | (EHIBE) | EGYPTIAN HIEROGLYPH INSERT AT BOTTOM END | Cf | No | \x{D80D}\x{DC35} | | 13436 | (EHOM) | EGYPTIAN HIEROGLYPH OVERLAY MIDDLE | Cf | No | \x{D80D}\x{DC36} | | 13437 | (EHBS) | EGYPTIAN HIEROGLYPH BEGIN SEGMENT | Cf | No | \x{D80D}\x{DC37} | | 13438 | (EHES) | EGYPTIAN HIEROGLYPH END SEGMENT | Cf | No | \x{D80D}\x{DC38} | | | | | | | | | 1BCA0 | (SFLO) | SHORTHAND FORMAT LETTER OVERLAP | Cf | Yes | \x{D82F}\x{DCA0} | | 1BCA1 | (SFCO) | SHORTHAND FORMAT CONTINUING OVERLAP | Cf | Yes | \x{D82F}\x{DCA1} | | 1BCA2 | (SFDS) | SHORTHAND FORMAT DOWN STEP | Cf | Yes | \x{D82F}\x{DCA2} | | 1BCA3 | (SFUS) | SHORTHAND FORMAT UP STEP | Cf | Yes | \x{D82F}\x{DCA3} | | | | | | | | | 1D173 | (MSBB) | MUSICAL SYMBOL BEGIN BEAM | Cf | No | \x{D834}\x{DD73} | | 1D174 | (MSEB) | MUSICAL SYMBOL END BEAM | Cf | No | \x{D834}\x{DD74} | | 1D175 | (MSBT) | MUSICAL SYMBOL BEGIN TIE | Cf | No | \x{D834}\x{DD75} | | 1D176 | (MSET) | MUSICAL SYMBOL END TIE | Cf | No | \x{D834}\x{DD76} | | 1D177 | (MSBS) | MUSICAL SYMBOL BEGIN SLUR | Cf | No | \x{D834}\x{DD77} | | 1D178 | (MSES) | MUSICAL SYMBOL END SLUR | Cf | No | \x{D834}\x{DD78} | | 1D179 | (MSBP) | MUSICAL SYMBOL BEGIN PHRASE | Cf | No | \x{D834}\x{DD79} | | 1D17A | (MSEP) | MUSICAL SYMBOL END PHRASE | Cf | No | \x{D834}\x{DD7A} | | | | | | | | | E0001 | BEGIN | LANGUAGE TAG | Cf | No | \x{DB40}\x{DC01} | | E0020 | SP | TAG SPACE | Cf | No | \x{DB40}\x{DC20} | | ..... | | ........................................... | .. | No | ................ | . | ..... | | ........................................... | .. | No | ................ | . | ..... | | ........................................... | .. | No | ................ | . | E007E | ~ | TAG TILDE | Cf | No | \x{DB40}\x{DC7E} | | E007F | END | CANCEL TAG | Cf | No | \x{DB40}\x{DC7F} | •-------•---------•---------------------------------------------•----•-----------•------------------•------Continuation on next post !
guy038
-
-
Hi All,
Continuation …
From this last table, we can reasonably ignore :
-
The space and soft hyphen characters
-
Some musical characters
-
All the characters, specific to a language, modern or archaic
-
The tag characters, whose usage is strongly discouraged by the
Unicode consortium.
In other words, all characters with the No indication, in the
To searchcolumn, of the previous table !As a result, we should only take care of this restricted list of
50characters :•-------•---------•---------------------------------------------•----•------------------•-----• | Code | Abbrev. | Character Name | Cg | N++ Regex | Chr | •-------•---------•---------------------------------------------•----•------------------•-----• | 00A0 | NBSP | NO-BREAK SPACE | Zs | \x{00A0} | | | | | | | | | | 2000 | NQSP | EN QUAD | Zs | \x{2000} | | | 2001 | MQSP | EM QUAD | Zs | \x{2001} | | | 2002 | ENSP | EN SPACE | Zs | \x{2002} | | | 2003 | EMSP | EM SPACE | Zs | \x{2003} | | | 2004 | 3/MSP | THREE-PER-EM SPACE | Zs | \x{2004} | | | 2005 | 4/MSP | FOUR-PER-EM SPACE | Zs | \x{2005} | | | 2006 | 6/MSP | SIX-PER-EM SPACE | Zs | \x{2006} | | | 2007 | FSP | FIGURE SPACE | Zs | \x{2007} | | | 2008 | PSP | PUNCTUATION SPACE | Zs | \x{2008} | | | 2009 | THSP | THIN SPACE | Zs | \x{2009} | | | 200A | HSP | HAIR SPACE | Zs | \x{200A} | | | | | | | | | | 200B | ZWSP | ZERO WIDTH SPACE | Cf | \x{200B} | | | 200C | ZWNJ | ZERO WIDTH NON-JOINER | Cf | \x{200C} | | | 200D | ZWJ | ZERO WIDTH JOINER | Cf | \x{200D} | | | 200E | LRM | LEFT-TO-RIGHT MARK | Cf | \x{200E} | | | 200F | RLM | RIGHT-TO-LEFT MARK | Cf | \x{200F} | | | 202A | LRE | LEFT-TO-RIGHT EMBEDDING | Cf | \x{202A} | | | 202B | RLE | RIGHT-TO-LEFT EMBEDDING | Cf | \x{202B} | | | 202C | PDF | POP DIRECTIONAL FORMATTING | Cf | \x{202C} | | | 202D | LRO | LEFT-TO-RIGHT OVERRIDE | Cf | \x{202D} | | | 202E | RLO | RIGHT-TO-LEFT OVERRIDE | Cf | \x{202E} | | | | | | | | | | 202F | NNBSP | NARROW NO-BREAK SPACE | Zs | \x{202F} | | | | | | | | | | 205F | MMSP | MEDIUM MATHEMATICAL SPACE | Zs | \x{205F} | | | | | | | | | | 2060 | WJ | WORD JOINER | Cf | \x{2060} | | | | | | | | | | 2061 | (FA) | FUNCTION APPLICATION | Cf | \x{2061} | | | 2062 | (IT) | INVISIBLE TIMES | Cf | \x{2062} | | | 2063 | (IS) | INVISIBLE SEPARATOR | Cf | \x{2063} | | | 2064 | (IP) | INVISIBLE PLUS | Cf | \x{2064} | | | | | | | | | | 2066 | LRI | LEFT-TO-RIGHT ISOLATE | Cf | \x{2066} | | | 2067 | RLI | RIGHT-TO-LEFT ISOLATE | Cf | \x{2067} | | | 2068 | FSI | FIRST STRONG ISOLATE | Cf | \x{2068} | | | 2069 | PDI | POP DIRECTIONAL ISOLATE | Cf | \x{2069} | | | 206A | ISS | INHIBIT SYMMETRIC SWAPPING | Cf | \x{206A} | | | 206B | ASS | ACTIVATE SYMMETRIC SWAPPING | Cf | \x{206B} | | | 206C | IAFS | INHIBIT ARABIC FORM SHAPING | Cf | \x{206C} | | | 206D | AAFS | ACTIVATE ARABIC FORM SHAPING | Cf | \x{206D} | | | 206E | NADS | NATIONAL DIGIT SHAPES | Cf | \x{206E} | | | 206F | NOSP | NOMINAL DIGIT SHAPES | Cf | \x{206F} | | | | | | | | | | 3000 | IDSP | IDEOGRAPHIC SPACE | Zs | \x{3000} | | | | | | | | | | FEFF | ZWNBSP | ZERO WIDTH NO-BREAK SPACE / BYTE ORDER MARK | Cf | \x{FEFF} | | | | | | | | | | FFF9 | IAA | INTERLINEAR ANNOTATION ANCHOR | Cf | \x{FFF9} | | | FFFA | IAS | INTERLINEAR ANNOTATION SEPARATOR | Cf | \x{FFFA} | | | FFFB | IAT | INTERLINEAR ANNOTATION TERMINATOR | Cf | \x{FFFB} | | | | | | | | | | FFFC | OBJ | OBJECT REPLACEMENT CHARACTER | So | \x{FFFC} |  | | FFFD | ? | REPLACEMENT CHARACTER | So | \x{FFFD} | � | | | | | | | | | 1BCA0 | (SFLO) | SHORTHAND FORMAT LETTER OVERLAP | Cf | \x{D82F}\x{DCA0} | | | 1BCA1 | (SFCO) | SHORTHAND FORMAT CONTINUING OVERLAP | Cf | \x{D82F}\x{DCA1} | | | 1BCA2 | (SFDS) | SHORTHAND FORMAT DOWN STEP | Cf | \x{D82F}\x{DCA2} | | | 1BCA3 | (SFUS) | SHORTHAND FORMAT UP STEP | Cf | \x{D82F}\x{DCA3} | | •-------•---------•---------------------------------------------•----•------------------•-----•
Remark that I added, to that list, the two characters Object Replacement Character
\x{FFFC}and Replacement Character\x{FFFD}often used in case of encoding problems !
Then the updated
Markregex would be :MARK
[\x{00A0}\x{2000}-\x{200A}\x{200B}-\x{200F}\x{202A}-\x{202E}\x{202F}\x{205F}-\x{206F}\x{3000}\x{FEFF}\x{FFF9}-\x{FFFD}\x{D82F}\x{DCA0}\x{D82F}\x{DCA1}\x{D82F}\x{DCA2}\x{D82F}\x{DCA3}]And the updated
Pythonscript is :# -*- coding: utf-8 -*- from Npp import editor, notepad, NOTIFICATION class SRFSC(object): def __init__(self): notepad.callback(self.callback_npp_BUFFERACTIVATED, [NOTIFICATION.BUFFERACTIVATED]) self.callback_npp_BUFFERACTIVATED(None) def callback_npp_BUFFERACTIVATED(self, args): # SPACE chars ( Zs ) editor.setRepresentation(u'\u00A0', "NBSP") # no-break space editor.setRepresentation(u'\u2000', "NQSP") # EN quad editor.setRepresentation(u'\u2001', "MQSP") # EM quad editor.setRepresentation(u'\u2002', "ENSP") # EN space editor.setRepresentation(u'\u2003', "EMSP") # EN space editor.setRepresentation(u'\u2004', "3/MSP") # three-per-EM space editor.setRepresentation(u'\u2005', "4/MSP") # four-per-EM space editor.setRepresentation(u'\u2006', "6/MSP") # six-per-EM space editor.setRepresentation(u'\u2007', "FSP") # figure space editor.setRepresentation(u'\u2008', "PSP") # punctuation space editor.setRepresentation(u'\u2009', "THSP") # thin space editor.setRepresentation(u'\u200A', "HSP") # hair space # FORMAT chars ( Cf ) editor.setRepresentation(u'\u200B', "ZWSP") # zero width space editor.setRepresentation(u'\u200C', "ZWNJ") # zero width non-joiner editor.setRepresentation(u'\u200D', "ZWJ") # zero width joiner editor.setRepresentation(u'\u200E', "LRM") # left-to-right mark editor.setRepresentation(u'\u200F', "RLM") # right-to-left mark editor.setRepresentation(u'\u202A', "LRE") # left-to-right embedding editor.setRepresentation(u'\u202B', "RLE") # right-to-left embedding editor.setRepresentation(u'\u202C', "PDF") # pop directional formatting editor.setRepresentation(u'\u202D', "LRO") # left-to-right override editor.setRepresentation(u'\u202E', "RLO") # right-to-left override # SPACE chars ( Zs ) editor.setRepresentation(u'\u202F', "NNBSP") # narrow no-break space editor.setRepresentation(u'\u205F', "NNBSP") # medium mathematical space # FORMAT chars ( Cf ) editor.setRepresentation(u'\u2060', "WJ") # word joiner ( zero width no-break space ) editor.setRepresentation(u'\u2061', "FA") # function application editor.setRepresentation(u'\u2062', "IT") # invisible times editor.setRepresentation(u'\u2063', "IS") # invisible separator editor.setRepresentation(u'\u2064', "IP") # invisible plus editor.setRepresentation(u'\u2066', "LRI") # left-to-right isolate editor.setRepresentation(u'\u2067', "RLI") # right-to-left isolate editor.setRepresentation(u'\u2068', "FSI") # first strong isolate editor.setRepresentation(u'\u2069', "PDI") # pop directional isolate # FORMAT chars ( Cf ) DEPRECATED editor.setRepresentation(u'\u206A', "ISS") # inhibit symmetric swapping editor.setRepresentation(u'\u206B', "ASS") # activate symmetric swapping editor.setRepresentation(u'\u206C', "IAFS") # inhibit arabic form shaping editor.setRepresentation(u'\u206D', "AAFS") # activate arabic form shaping editor.setRepresentation(u'\u206E', "NADS") # national digit shapes editor.setRepresentation(u'\u206F', "NODS") # nominal digit shapes # SPACE chars ( Zs ) editor.setRepresentation(u'\u3000', "IDSP") # ideographic space # FORMAT chars ( Cf ) SPECIALS editor.setRepresentation(u'\uFEFF', "ZWNBSP") # zero width no-break space : deprecated ( see U+2060 ) / byte order mark editor.setRepresentation(u'\uFFF9', "IAA") # interlinear annotation anchor editor.setRepresentation(u'\uFFFA', "IAS") # interlinear annotation separator editor.setRepresentation(u'\uFFFB', "IAT") # interlinear annotation terminator # OTHER symbols ( So ) editor.setRepresentation(u'\uFFFC', "OBJ") # object replacement character editor.setRepresentation(u'\uFFFD', "<?>") # replacement character # FORMAT chars ( Cf ) # For characters OVER the BMP, with code > FFFF, we can use, EITHER, the syntaxes : # - editor.setRepresentation(u'\U0001BCA0', "SFLO") TRUE "32-bits" representation # - editor.setRepresentation(u'\uD82F\uDCA0', "SFLO") The 16-bits "SURROGATES PAIR" editor.setRepresentation(u'\uD82F\uDCA0', "SFLO") # shorthand format letter overlap editor.setRepresentation(u'\uD82F\uDCA1', "SFCO") # shorthand format continuing overlap editor.setRepresentation(u'\uD82F\uDCA2', "SFDS") # shorthand format down step editor.setRepresentation(u'\uD82F\uDCA3', "SFUS") # shorthand format up step # Active the character representation notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS) notepad.menuCommand(MENUCOMMAND.VIEW_ALL_CHARACTERS) SRFSC()
I did not investigate in the S/R, because of the number of chars to handle (
50) and because I’m just feeling… lazy for such a task !However with the
Markoperation, which helps you to locate exactly where are these special characters and thePythonscript which clearly identify them, you should be safe with your file’s contents ;-))
Best Regards
guy038
-
-
P PeterJones referenced this topic on
-
-
-
-
 E Ekopalypse referenced this topic on
E Ekopalypse referenced this topic on
-
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
This thread largely talks about making “invisible” characters visible.
Recently I had a need/desire to make characters with a visible component invisible, i.e. “go the other way”.
Example:

So for the above, I’d like to “turn off” the control characters and focus only on the “meat” of the data:

This is only for visualization purposes; I’m not editing this data.
Long story short is I ran into trouble doing this. I found I can change the representation of the characters, using PythonScript, e.g., executing
editor.setRepresentation(u'\u0002', 'startxmit')will then show:
But my guess at what was needed to hide the U+0002 character entirely didn’t work:
editor.setRepresentation(u'\u0002', '')produces:

which is “better” but still has a visual component.
editor.clearRepresentation(u'\u0002')only brings back the default visualizaton ofSTX.Any ideas on how to solve this, i.e., eliminate the visual component of a control character?
-
Adhoc, the only thing I can think of is to give the control chars a style and set the visible property to false.
Practically like the error list lexer does with the ANSI sequences. -
@Ekopalypse said in Invisible characters unwanted:
Adhoc, the only thing I can think of is to give the control chars a style and set the visible property to false.
Practically like the error list lexer does with the ANSI sequences.That sounds like a lot of work, both coding wise and runtime wise. I was hoping that I was misunderstanding some simple thing about how Scintilla does “representation”, but from lack of replies, and direction of the one reply, it appears I am not missing that “simple thing”.
I think it is odd that Scintilla basically forces me to see always see “control characters”, but never shows me certain UTF-8 characters.
-
Someone else found the solution for me:
- set the control character’s representation to the “zero-width space” character (so it has no visual component – but it will have a small “inverse video” artifact on-screen)
- set the representation appearance to plain text (to avoid the inverse video)
Although, to script this (as I tend to do) is difficult as the set-representation-appearance Scintilla command is not yet available as an
editorcommand in the PythonScript versions that are current as of this writing.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login