Is it possible...?
-
Dear Members
sorry Im not a professional.
I have a topic and searching for solutions:I have a bunch of saved html files and want to search for a keyword + a variable e.g. “password:” and the word behind " …" . The word behind would be the one I would ike to extract.
Is this possible?
Thanks a lot -
Possible? yes.
From the simplistic end, you are looking for
(password: \S+), which would be a sub-expression of the regex. However, you need more than that (I’ll come back to this later).Once you had the full regular expression for both the search term and the replace term, I would do the following:
- Copy all the files to a new location (don’t work with your original data)
- Search > Find In Files
- Specify the right Directory for the new location of the files
- Set the Find What and Replace with
- Replace all
Back to the regular expression: I spend about 10 minutes trying to craft one master regex which would do it all. I failed. I was attempting to do something akin to
^.*?(password: (\S+?))?.*(\R|\Z)?, replacing with(?{2}$1$3|), which I got to from saying to myself “if a line doesn’t havepassword: \S+, replace the whole line including the newline with nothing; if it is found, replace it with justpassword: ...and a newline”. Unfortunately, neither that, nor any variant I tried before or after worked.It might make it easier if you could guarantee that there aren’t any lines in the files that don’t contain
password: ...somewhere in the line.@guy038 is going to have to jump in to do it in one fell swoop. Barring that (he may be busy, or away, or not interested in this one), I would do a multistep sequence in the Find in Files. First, I would try to find any text on a given line that precedes
password: \S+, and delete it. Then I would do something that would delete anything after that sub-expression. Then I would look for any lines that don’t contain that, and delete them (including newline). What remains would be just the prefix/value pairs.Maybe if you could confirm things about your data, like: do all lines have passwords, or just some? do you care if there are blank lines left in the resulting file, or do we have to delete all lines that don’t contain passwords? is there a limit as to what text can come before
password? is there a space (or any number of spaces) between thepassword:prefix and the value, or can it be either space or no space? Can anything come after the password field on the line, or can anything afterpassword:be considered the password values; if things can come after the password field, are there characters that cannot be part of the password, or a character that’s guaranteed to be a separator character? Anything else that would help us not require a turing-complete program to determine if there’s a password on the line or not?The more you give us, the better. Also read my boilerplate below.
-----
Please Read And Understand This
FYI: I often add this to my response in regex threads, unless I am sure the original poster has seen it before. Here is some helpful information for finding out more about regular expressions, and for formatting posts in this forum (especially quoting data) so that we can fully understand what you’re trying to ask:
This forum is formatted using Markdown. Fortunately, it has a formatting toolbar above the edit window, and a preview window to the right; make use of those. The
</>button formats text as “code”, so that the text you format with that button will come through literally; use that formatting for example text that you want to make sure comes through literally, no matter what characters you use in the text (otherwise, the forum might interpret your example text as Markdown, with unexpected-for-you results, giving us a bad indication of what your data really is). Images can be pasted directly into your post, or you can hit the image button. (For more about how to manually use Markdown in this forum, please see @Scott-Sumner’s post in the “how to markdown code on this forum” topic, and my updates near the end.) Please use the preview window on the right to confirm that your text looks right before hitting SUBMIT. If you want to clearly communicate your text data to us, you need to properly format it.If you have further search-and-replace (“matching”, “marking”, “bookmarking”, regular expression, “regex”) needs, study the official Notepad++ searching using regular-expressions docs, as well as this forum’s FAQ and the documentation it points to. Before asking a new regex question, understand that for future requests, many of us will expect you to show what data you have (exactly), what data you want (exactly), what regex you already tried (to show that you’re showing effort), why you thought that regex would work (to prove it wasn’t just something randomly typed), and what data you’re getting with an explanation of why that result is wrong. When you show that effort, you’ll see us bend over backward to get things working for you. If you need help formatting, see the paragraph above.
Please note that for all regex and related queries, it is best if you are explicit about what needs to match, and what shouldn’t match, and have multiple examples of both in your example dataset. Often, what shouldn’t match helps define the regular expression as much or more than what should match.
Here is the way I usually break down trying to figure out a regex (whether it’s for myself or for helping someone in the forum):
- Compare what portions of each line I want to match is identical to every other one (“constants”), and what parts do I want to allow to be different in each line (“variables”) but still be part of the match.
- Look at both the variables and constants, and see what portions of each I’ll want to keep or move around, vs which parts get thrown away completely. Each sub-component that I want to keep will be put in a regex group. Anything that gets completely thrown away doesn’t need to be in a group, though sometimes I put it in a numbered
(___)or unnumbered(?:___)group anyway, if I have a good reason for it. Anything that needs to be split apart, I break into multiple groups, instead of having it as one group.
- For each group, I do a mental “how would I describe to my son how to correctly match these characters?” – which should hopefully give me a simple, foolproof algorithm of characters that must match or must not match; then I ask, “how would I translate those instructions into regex sequences?” If I don’t know the answer to the second, I read documentation, or ask a specific question.
- try it, debug, iterate.
-
Im really sorry. I did not read the article in advance as I unfortunately not understand the content really good. I hope you could help me with a function code which Is not very hard to customize as I just began learning of programming.
I understand what you mean, you would filter the content out step by step to have finaly just the search expression.I try to explain better:
The “…” I just used as placeholders
My file is looking like the following
It also contains lines without the word “password”
also possible are spaces or other signs between “password” and the “target word”
but if this wil be also extracted , it would be not too big problem
I would “free” the output file again manually,no problem.
Just deletting 95% of the other signs would be suitable.Line1: bla bla bla bla "Password “1"” bla bla bla
Line2: bla bla bla bla bla bla bla bla bla bla bla
Line3: bla "Password “2"” bla bla bla bla bla bla
Line4: bla bla bla bla bla bla bla bla bla bla bla
Line5: bla bla bla bla bla bla bla bla bla bla bla
Line6: bla bla bla bla bla bla "Password “3"” bla
…My aim would be to extract 1 and 2 and 3 and a following strings which a situated after the word “password”
This is a original line of the file:
/><br />password<br />target</div>
I would need the variable which I have called “target”
Could you please help me ?:(
Really appreciate!! -
@dipsi7772 said in Is it possible...?:
want to search for a keyword + a variable
I used both examples you provided in an attempt to extract JUST the “variable” you seek. I have succeeded insofar as the examples. My concern is that you probably have NOT provided clear enough examples, so in the “real” world situation you may find it does NOT work as expected.
In the examples you provided the “variable” seems to be surrounded by quotes (of some type, there are many), and in another part of the example it has the “>” and “<” surrounding it. So in the absence of any further information I have had to assume that the “variable” is composed of numbers and letters, thus 0-9 and a-z (upper or lower case) ONLY!
So see the first code block below showing what I tested my regex on and in the second block what running the regex produced.
So the regex is (Search mode must be Regular expression and wrap around ticked):
Find What:(?i-s)(^.+?password(.+)?[“>]+([0-9a-z]+).+?(\R|\z))|(.+\R|\z)
Replace With:\3\4So as a description of the regex:
(?i-s) these will set “match case and “. matches newline” to required settings. This prevents your Replace settings possibly preventing my regex from functioning correctly.
Then we start searching from the start of a line for the word “password” (case insensitive), so “Password” and passwoRD” would also work.
After finding that string we continue so long as we do not encounter a quote and a “>” symbol. That’s where I’ve had to make some assumptions.
Next we pass over those special symbols (quote and >)
Then we start reading the “variable” portion (hopefully). Again, an assumption that it is comprised of ONLY letters and numbers.
Then we continue reading to the end of the line (including the EOL character or end of file).
Immediately after this search pattern we have a “|”. This denotes an alternate path we can take. So in the situation where the line does NOT contain a “password” string we use this alternate path.
Finally we come to the replacement text. In this case we want the 3rd group (variable) and the 4th group (EOL or end of file). We send these back into the file. Everything else has been erased.As I stated earlier I am concerned that the limited examples you provided will likely mean this regex will fail. Because of this (and just beacuse you should when testing something new), I would strongly suggest running my regex on a COPY of your files, and then afterwards doing some spot checks.
Terry
Line1: bla bla bla bla "Password “1"” bla bla bla Line2: bla bla bla bla bla bla bla bla bla bla bla Line3: bla "Password “22"” bla bla bla bla bla bla Line4: bla bla bla bla bla bla bla bla bla bla bla Line5: bla bla bla bla bla bla bla bla bla bla bla Line6: bla bla bla bla bla bla "Password “3"” bla /><br />password<br />target1</div> /><br />word<br />target</div> /><br />pass<br />target</div> /><br />password<br />target2</div>1 22 3 target1 target2 -
Hello, @dipsi7772, @peterjones, @terry-r and All,
First, Peter said :
@guy038 is going to have to jump in to do it in one fell swoop. Barring that (he may be busy, or away, or not interested in this one)
Indeed, I was away for a long week-end !
Secondly, @dipsi7772 said :
This is a original line of the file:
/><br />password<br />target</div>
So I assume that the different targets are characters between the nearest
>and<symbols, after the wordpassword, with this exact case, followed with few characters. In this case, here is a destructive method, which need to be run only on a copy of your bunch of.htmlfilesTo sump up :
-
Copy the directory, containing all your
.htmlfiles, to an other location -
Start Notepad++
-
Open the Search in Files dialog (
Ctrl + Shift + F) -
SEARCH
(?s-i).*?password.+?>(.+?)(?=<)|.+ -
REPLACE
\1\r\n( or\1\nif your files use Unix EOL syntax ) -
FILTERS
*.html -
DIRECTORY The absolute location of the COPY of all your
.htmlfiles ( Do NOT use your original files ) -
Tick the
Wrap aroundbutton -
Select the
Regular expressionsearch mode -
Click on the
Replace in Filesbutton -
Click on the
Yesbutton of the small dialog Are you sure?
=> Each copy, of an original
.htmlfile, should have been drastically decreased and simply contains a list of all passwords, one per line, contained in the original file ;-))Notes :
-
As usual, the
(?s-i)in-line modifiers mean that :-
The dot
.character represents any single character, even EOL chars ((?s)) -
The search is processed in a sensitive to case way (
(?-i))
-
-
Then, The part
.*?password.+?>looks, from beginning of each file, for the shortest range of any character, till the stringpaasword, with this exact case, followed with some characters till the nearest>symbol -
Now, the
(.+?)(?=<)part stores, as group1, all the subsequent characters till the condition contained in the look-around structure is true, i.e. till the nearest<symbol if found -
In replacement, the “value” of each password
\1is simply rewritten, followed with new-line characters (\r\nor\n) -
At the end, if the word
password, with this exact case, cannot be found, the second alternative.+, after the alternation symbol|, selects all the remaining characters of current scanned file and deletes them, because group1is not defined
Remarks :
-
Notice that all quantifiers of the first alternative of the search regex are lazy quantifiers, i. e. it grasps as little chars as possible, though satisfying the subsequent parts of the overall regex
-
When an
.htmlfile do not contain any wordpassword, all its contents are just replaced with a single line-break !
Best Regards,
guy038
-
-
Dear @Terry-R dear @guy038, dear @PeterJones
thank you so much for your support. All of you seem to be very smart people if I read through your thoughts and realize how difficult it is get the target out of the big text.As I dont want to make you guys headache I have checked now several different files of the big bunch to find out a “rule” or a repeated “sign” which is situated around the target.
I found that there is always a </div> directly next to the target. But unfortunately there are also other lines with </div>, but without the target.
So at the end, the only fix mark is the word “pass” or the word “password” before the target. Unfortunately I have to inform about a further issue:
The word “password” is not everytime directly before the target … sometimes there is also letters numbers signs or free spaces between them.
Regarding your question: The target can contain every, sign,letter, special sign …everything you can imagine.So from my unprofessional point of view:
its just possible to extract just the line which contains the strings “pass” “password” and “</div>”.
As I have almost 3000 html files to search, just extract the lines would also help me a lot.Should I try your proposals now or have you any remarks?
I googled but still not sure about the meaning of Unix EOLSearch field should look like this?
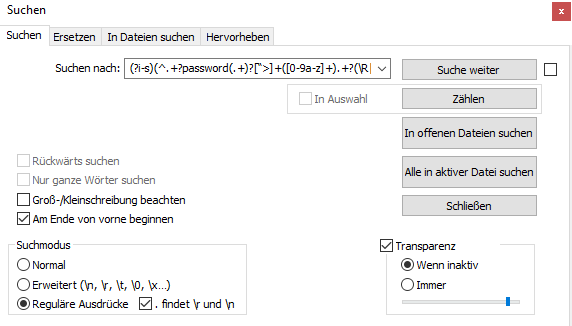
Not sure about the search options you mentioned.
Thanks for all guys!!! -
@dipsi7772 You have the simple search tab open, and you need the following tabs of the search window, replace or find and replace in files
-
Hi, @dipsi7772, @peterjones, @terry-r, @andrecool-68 and All,
@dipsi7772, many thanks for trying to find out some general rules in order to isolate your different target strings more easily !
You said :
1 I found that there is always a </div> directly next to the target. But unfortunately there are also other lines with </div>, but without the target.
2 So at the end, the only fix mark is the word “pass” or the word “password” before the target. Unfortunately I have to inform about a further issue:
3 The word “password” is not everytime directly before the target … sometimes there is also letters numbers signs or free spaces between them.
4 Regarding your question: The target can contain every, sign,letter, special sign …everything you can imagine.
If so, I think that the new regex S/R , below, should meet these
4criteria !SEARCH
(?s).*?(?-si:pass(word)?.+?>(.+?)(?=</div>))|.+REPLACE
\2\r\n( or\2\nif your files use Unix EOL syntax )-
The look-around
(?=</div>), as well as the(?-si:pass(word)?...syntax, should satisfy your first criterion -
The part
(?-si:pass(word)?...), which matches the wordpassorpassword, with this exact case, satisfies your second criterion -
Then, the part
.+?>, which matches the shortest range of standard chars, till a>symbol, satisfies your third criterion -
Finally, the part
(.+?), which stores, as group1, any range of standard characters, due to the in-line modifiers(?-si:....), till the nearest string</div>excluded ( located right after all the target characters ), satisfies your fourth criterion
As @andrecool-68 said, use the Find in Files dialog (
Ctrl + Shift + F)Cheers,
guy038
P.S. :
So, except for the SEARCH and REPLACE updated zones, just follow the instructions given in my first post !
-
-
Im soooo happy =) this works … Thank you all!! This made my day :)
You are great !! Thanks so much=) -
Hi, @dipsi7772, @peterjones, @terry-r, @andrecool-68 and All,
@dipsi7772, you said :
I googled but still not sure about the meaning of Unix EOL
I missed that sentence. Refer to the link, below, for general information about new-line definition :
https://en.wikipedia.org/wiki/Newline#Representation
To be rigorous, I’ve made a slight error, in my last proposed search regex ! In order to extract target from lines of that form :
/><br />password>target</div> OR /><br />pass>target</div> ( when NO character exists between the string
pass(word)and>target<)I should have used the following search regex, with a
*, instead of a+, at the indicated place !SEARCH (?s).*?(?-si:pass(word)?.*?>(.+?)(?=</div>))|.+ ▲ │Best Regards,
guy038
-
@guy038 said in Is it possible...?:
OT to the main thread here, but it is interesting from that article that the Mac line-endings (carriage-return only) that Notepad++ still supports are for an OS whose last release was before the first release of N++ (if I have my dates straight).
-
Dear guy038,
thanks for clarification. Your proposal works good. Anyway its still a job to manuallly copy the eexpressions out of the sentences :) but its way better than without the code.
Strange thin is, on some files. just <!doctype html> this is the result.
I would say al files are the same format , so Its mystious.
Anyway whis you a nice xMas all community members and thanks again=) -
Is it maybe possible to implement a rule that avoids duplicate results?
Another thing is, even I choose “Automatischer Zeienumbruch” each line is writte ine ONE line, not in a second one which woud avoid the vertical scrolling.
Best Regards Friends
-
Hi, @dipsi7772 and All,
You said :
Strange thin is, on some files. just <!doctype html> this is the result.
I would say al files are the same format , so Its mystious.It’s not strange and it’s not related to file format at all ! The reason, is that , for files with big size, it may happen that the regex does not work properly and deletes all characters but the first line of your
HTMLfiles. Indeed, as the regex is :(?s).*?(?-si:pass(word)?.*?>(.+?)(?=</div>))|.+The beginning
(?s).*?(?-si:pass(word)?means that the regex engine selects all characters, even displayed on several lines, from current position of the caret till the first wordpassorpassword. In some files, this range of characters can be significative and this fact could explain the non-expected results !If your
HTMLfiles are not important nor confidentiel, simply e-mail me one of these files, which produces errors. I’ll try to find out an other regex which works correctly, in all cases ;-))
Next, you said :
Is it maybe possible to implement a rule that avoids duplicate results?
My question is : In the copied
HTMLfiles, that contains the passwords (1per line ), which is the maximum length of these files ?Depending of this length, a regex solution may be possible… However, if you don’t mind changing the initial order of these passwords, just use, for each copied
HTMLfile, the two menu options, below :-
Edit > Line Operations > Sort Line Lexicographically Ascending -
Edit > Line Operations > Remove Consecutive Duplicate Lines
Finally, you said :
Another thing is, even I choose “Automatischer Zeienumbruch” each line is writte ine ONE line, not in a second one which woud avoid the vertical scrolling.
I’m sorry because I cannot guess what you’re speaking of :-(( Depending on your file ending characters, discussed previously, and using the appropriate Replace regex :
\2\r\nfor Windows filesOR
\2\nfor Unix filesThe
View > Word Wrapoption should work correctly !?Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login