Build boost::regex with ICU support
-
ICU allows boost::regex to correctly parse
utf8, utf16 and utf32 encoded text. -
@Ekopalypse said in Build boost::regex with ICU support:
ICU allows boost::regex to correctly parse
Pretty important then! :-)
-
Yes, very important :)
-
Wouldn’t N++ and Pythonscript be building boost with that enabled? Can’t you follow their models for getting it built?
-
PS seems to do its own utf8 parsing - I try to avoid it if boost has a native way of doing it. But maybe I have to do it.
The same seems to be the case how npp handles this. -
Hello, @ekopalypse, @alan-kilborn and All,
As Alan said, I do think that the
ICUproject, of the Unicode consortium, is really very important !May be, you could examine the improved Beta N++ regex code of François-R Boyer. Probably, it’s not related at all with the present discussion. But, who knows ! You may find out some valuable information ;-))
To that matter, just follow my road map, at the end of the post, below, in the remark section :
https://community.notepad-plus-plus.org/topic/15765/faq-desk-where-to-find-regex-documentation
Briefly :
-
Download a portable N++
v6.9.0release -
Install it in any location, different from Windows common folders
-
Rename the
SciLexer.dll, whatever you want -
Download the
SciLexer.dllversion of François-R Boyer, at the same location -
Start N++
v6.9.0
Of course, if, from the examination of this old modified
SciLexer.dllfile, you could understand and apply the Boyer’s improvements to our presentSciLexer.dllfile, a big step would have been taken ! Sure that you would deserve many packs of beer, as a reward ;-))Cheers, … by advance,
guy038
-
-
Okay, quick information.
To compile boost::regex with ICU support the trick is to find
both, the release builds and the debug builds of ICU.
More about this here. -
I was reading your REMARK from the above mentioned link.
May I ask you for a favor?
Can you provide me a few regex examples from that section
to see if my implementation works as expected?
For the range:\x{0} to \x{7FFFFFFF}, is it ok if I would create
each code point on the fly and do a search to see if it matches?
Or is it needed to have multiple bytes of those values to be really
sure it is working??
Means, is each code point an entity of its own or
might it be that multiple code points form to one entity? -
Hi, @ekopalypse,
Just a first and quick anwwer, regarding the
readme.txtof François-R Boyer… on2013-03-27!
This folder contains my latest regex code (as of may 2013) for Notepad++ which is not yet in the release version.
The SciLexer.dll can directly replace the one from latest version of Notepad++ but not all features are accessible since the user interface has not been updated to support some new features.
It passes all automated tests that were done for the “new regex code” which is in current release, plus:
- correctly supports code points outside BPM (search is done with 32 bit codepoints instead of UTF-16);
- both search and replace strings can contain embedded null characters and/or escape sequences for null characters;
- lookbehinds are correctly handled in search and replace, even those overlapping with end of previous match;
- a new [[:inval:]] character class, to find invalid UTF-8 sequences;
- invalid UTF-8 characters can be kept in replace (e.g. replacing “(.*)” by “ab\1cd” will keep invalid UTF-8 sequences);
The following new features are not accessible in current Notepad++ user interface:
- a new SCFIND_REGEXP_LOCALEORDER option, to have character ranges in locale order instead of code point order (‘à’ is between ‘a’ and ‘b’ at least in French locale order, but is after in code point order, thus [a-b] will match also ‘à’ and other characters that would be between ‘a’ and ‘b’ in a dictionary);
- the error message can now be known when the regex is invalid (e.g. regex “(” will report an “Unmatched marking parenthesis”, while current Notepad++ only knows it is an “Invalid regular expression”);
Source: readme.txt, updated 2013-05-27
Now, @ekopalypse, I’ll try, these next days, to collect a bunch of regexes, which :
-
Does not work with our present implementation of The Boost Regex library
-
Does work properly with the François-R Boyer implementation
BR
guy038
-
@guy038 - thank you very much but take your time, no hurry.
I stay away from PC on weekends anyway and
there is still some open task for implementing ICU.
So have nice weekend to everyone. :) -
@Ekopalypse said in Build boost::regex with ICU support:
there is still some open task for implementing ICU.
Extreme necro, I know… this just turned up in a search.
There’s a nice, clean header-only implementation of boost::regex, but it doesn’t work properly for Unicode without ICU. I use boost::regex in my plugin, but I gave up trying to make sense of how to statically link whatever parts of ICU are needed by boost::regex so as to wind up with a single GitHub project / MSVC solution that compiles into one dll that works.
Did you ever figure it out?
Alternatively, did you find another source for the information needed to implement a traits class on Windows for UTF-32 as
char32_t? I think getting those “traits” is the main hurdle, and why boost::regex uses ICU4C to implement Unicode. -
Yes, as far as I remember I was able to compile everything into a “huge” static library, but then had a problem using it with nim which made me give up, but I don’t remember exactly what steps I took back then.
No, I’m pretty sure I never looked for utf32 trait classes because I didn’t even understand the basics of cpp back then.
I’m not home at the moment, but when I get back I’ll take a look at the project to see if I left some notes for my future self.
-
Sorry, apart from my Nim test code I haven’t found anything else.
import std/[os] when not defined(cpp): {.error: "This projects needs to be compiled with cpp backend as it uses the boost::regex library.".} {.passC: "-std=gnu++17 -ID:\\Repositories\\vcpkg\\installed\\x64-windows\\include".} {.push header: "boost/regex.hpp".} type StdString {.importcpp: "std::string".} = object RegEx {.importcpp: "boost::regex".} = object Match {.importcpp: "boost::smatch".} = object SubMatch {.importcpp: "boost::ssub_match".} = object RegexError {.importcpp: "boost::regex_error".} = object {.pop.} # char compatible proc regexSearch(s: StdString, w: Match, e: RegEx): bool {.importcpp: "boost::regex_search(@)".} proc initStdString(s: cstring): StdString {.constructor, importcpp: "std::string(@)".} proc initRegEx(s: cstring): RegEx {.constructor, importcpp: "boost::regex(@)".} proc initMatch(): Match {.constructor, importcpp: "boost::smatch()".} proc size(self: Match): int {.importcpp: "size".} proc position(self: Match, i: int): int {.importcpp: "position".} proc length(self: Match, i: int): int {.importcpp: "length".} proc `[]`(self: Match, i: int32): SubMatch {.importcpp: "#[#]".} proc str(self: SubMatch): StdString {.importcpp: "str".} proc cStr(self: StdString): cstring {.importcpp: "(char *)#.c_str()".} proc what(err: RegexError): cstring {.importcpp: "(char *)#.what()".} proc position(self: RegexError): int {.importcpp: "position".} # https://www.boost.org/doc/libs/1_80_0/libs/regex/doc/html/boost_regex/ref/match_results.html # https://www.boost.org/doc/libs/1_80_0/libs/regex/doc/html/boost_regex/ref/sub_match.html when isMainModule: try: var s = initStdString("Boost Libraries Test".cstring) # std::string s = "Boost Libraries"; var e = initRegEx("(\\w+)\\s(\\w+)".cstring) # boost::regex expr{"(\\w+)\\s(\\w+)"}; var w = initMatch() # boost::smatch what; if regexSearch(s, w, e): # if (boost::regex_search(s, what, expr)) { echo(w[0].str().cStr()) # std::cout << what[0] << '\n'; echo(w[1].str().cStr(), "_", w[2].str().cStr()) # std::cout << what[1] << "_" << what[2] << '\n'; } for i in 0 ..< w.size(): let pos = w.position(i) echo(pos, "-", pos + w.length(i) - 1, " ", w[int32(i)].str().cStr()) else: echo(":-(") except RegexError as e: echo "Error in regex found at position:", e.position() # echo e.what() except: echo repr(getCurrentException()) -
@Ekopalypse said in Build boost::regex with ICU support:
Yes, as far as I remember I was able to compile everything into a “huge” static library, but then had a problem using it with nim which made me give up, but I don’t remember exactly what steps I took back then.
No, I’m pretty sure I never looked for utf32 trait classes because I didn’t even understand the basics of cpp back then.
I’m not home at the moment, but when I get back I’ll take a look at the project to see if I left some notes for my future self.
Thanks for looking.
Odd… I just came across one of my own older posts which mentioned this code from PythonScript in which they appear to have solved the problem (of creating a traits class, not of using ICU).
Now I can’t remember why I didn’t just copy that approach. There must have been a reason.
-
@Ekopalypse said in Build boost::regex with ICU support:
No, I’m pretty sure I never looked for utf32 trait classes because I didn’t even understand the basics of cpp back then.
I think I have it! I’m using the PythonScript approach of creating a new traits class, but not doing it quite the same way they do — instead I’m “delegating” everything I can to the wchar_t traits, and treating everything over 0xFFFF as opaque: no attempt to recognize word characters or digits or anything else up there… just [:unicode:] but otherwise not parts of any character class and not subject to case transformation. That way I’m pretty confident nothing will be worse than it is with
wchar_t, but it works in Unicode code points with none of the surrogate nonsense.Not ready for public release yet, but it looks like it works. I can search and replace using expressions like
\x{1F809}with no problem;.matches one Unicode code point, including over 0xFFFF.So now my plan is to test this until I’m comfortable including it in a new release of Columns++. If that proves stable, I’ll raise the notion that perhaps Notepad++ could do the same thing.
-
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
Hello, @ekopalypse, @alan-kilborn, @coises and All,
@coises and @ekopalypse, I don’t know if you’ve found the time and/or the inclination to take a look to the François-R Boyer work, just for inspiration !
Of course, this work dates from
2013and a lot of time has passed ! Since this date, some improvements were made to our N++Boostregex engine. In particular :-
The correct behavior of the backward assertions as
\A -
The correct behavior of the `look-behind feature, even in case of overlapping
-
The explanation of an error in case of the
Find Invalid regular expressionmessage
But the highlights of this old build are still :
-
Searches and *replacements are performed in true
32 bitscode-points ( instead ofUTF-16) -
Thus, it can handle ALL the Universal Character Names ( UCN) of the UCS Transformation Format , from
\x{0}to\x{7FFFFFFF}, particularly, all those of code-points over\x{FFFF}, which are outside the BMP ( Basic Multilingual Plane ) -
Both, search and replace strings can contain embedded NUL characters and/or Escape sequences for NUL characters (
\x{0000}) -
Backward regex search, for NON
ANSIfiles, does not stop, anymore, when matching a character with Unicode code-point over\x{007F}. -
A new
[[:inval:]]character class, which allows you to find invalid UTF-8 sequences, which can be kept in replacement, too -
a new
SCFIND_REGEXP_LOCALEORDERoption, to have character ranges in locale order instead of code-point order ('Ã ’ is between ‘a’ and ‘b’ at least in French locale order, but is after in code point order, thus[a-b]will match also 'Ã ’ and other characters that would be between ‘a’ and ‘b’ in a dictionary)
I tried to do some tests, installing the N++
v6.9.0portable release on an USB key and replacing the defaultSciLexer.dllwith the @boyer’sSciLexer. Unfortunately, when inserting this USB key on my Win-10 laptop, most of these tests cannot be performed properly because of important changes in N++ releasev8.0-
The Scilexer.dll did not exist anymore and was included within N++ itself
-
The
UCS-2 BE BOMandUCS-2 LE BOMencodings were changed by theUTF-16 BE BOMandUTF-16 LE BOMencodings
For example, using my
Total_Charsfile, the search of the regex\x{10000}wrongly return65hits, instead of the right1char ). I suppose that if we could use the Boyer implementation with a recent N++ release ( instead ofv6.9), the result would be OK ?I also noticed a strange behavior regarding the backward regex searches, with N++
v6.9and the Boyer build for anUTF-8file : we have to click as many times toShift + F3that the current character is coded with two, three or fourUTF-8bytes !
However, one thing seems to work, as mentioned by François-R Boyer : the search and/or replacement of
NULcharacter(s), whatever its syntax (\x0,\x00,\x{00},\x{000}or\x{0000}). For example :SEARCH
ABC\x00WYZREPLACE
\x0--$0--\x{000}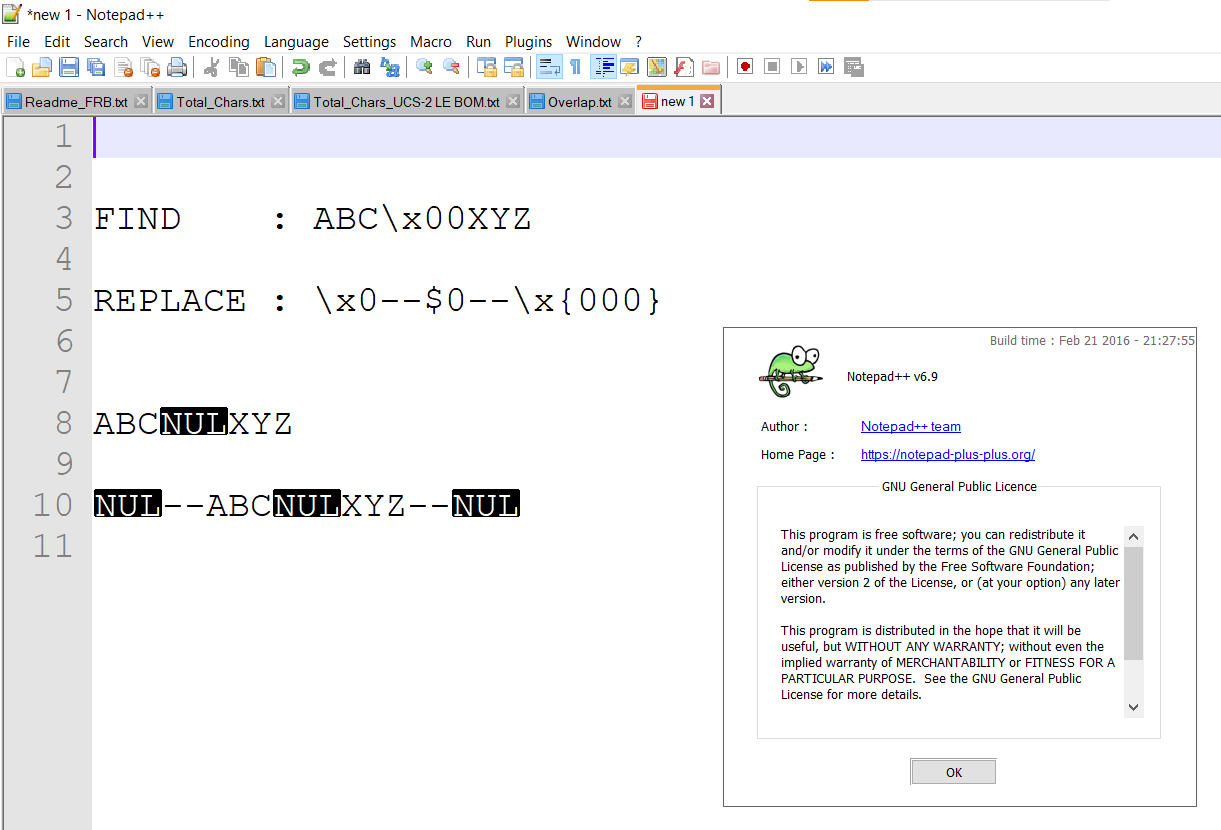
So, I wish you all the best to your quest towards a fully consistent regular expression engine, using
32-bitscode-points with possible local order of characters !Best Regards,
guy038
-
-
To be honest, no, I didn’t look further into boost::regex and Unicode after the problems, probably only caused by my ignorance, occurred with Nim. I admit that an implementation for the EnhanceAnyLexer plugin would be beneficial, but the interaction with cpp code still gives me a stomach ache.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login