Filter the data !!!
-
Hi, @alan-kilborn and All
At the end of my description of the blending process, I made a little mistake. I should have written :
The GENERAL formula, for Red, Green and Blue, is : FINAL Color = CURRENT color + Alpha x ( NEW color - CURRENT Color ) ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ - If NEW color Alpha opacity = 1 => FINAL color = NEW colour => The NEW color is totally OPAQUE - If NEW color Alpha opacity = .5 => FINAL color = ( NEW + CURRENT) / 2 => PERFECT mixing of the TWO colours - If NEW color Alpha opacity = 0 => FINAL color = CURRENT colour => The NEW color is totally TRANSPARENTThis is more rigorous !
Cheers,
guy038
-
@guy038 said in Filter the data !!!:
Personally, after dragging on the right, with the mouse, the Find dialog to its maximum, I’m able to type in up to 100 characters, with the monospaced search font ;-))
That solves quite well one of the problems I pointed out above, but creates another one, as it covers too much space on the only screen of my laptop. It might help in some cases, or if I had another monitor, but I don’t think it’s a long-term solution.
Anyway, thanks for the suggestion.
-
@Alan-Kilborn said in Filter the data !!!:
@astrosofista The Toolbucket plugin provides multiline Find and Replace boxes, maybe that is to your liking. It’s probably been debated before many times that Notepad++ itself should have bigger boxes for these things, but I can’t cite any references.
Will take a look at that plugin and check what it delivers. Thank you.
-
@Ekopalypse said in Filter the data !!!:
If it were multiline search/replace textboxes, then inserting EOLs is possible.
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?No, I wasn’t thinking in that feature, but in a kind of word wrapping.
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?
No worries on my part, I could live with that, as long as I could see the big picture, that is, the whole expression.
Personally, I’d prefer that the incremental search
would be upgraded by regular expressions
To be honest, I have little experience with regex and incremental searching. However, if it were implemented -something under discussion- it would be beneficial, at least from an educational perspective, since the visualization of results and the interaction it provides is very helpful.
automatically adjusts to the window width
Yes.
provides a shortcut to easily switch to the editor and back again
Again, yes.
and, pure optional but really nice to have, a regex-lexer which colors and check my regexes.
Also a larger font size - my aged eyes scream for it - and the ability to apply the usual editing commands, such as delimiters - to deal better with groups an classes - and duplication.
In other words, to feel totally comfortable I would like to have all the facilities of the editor in the search window. Maybe that’s why I compose my regex in the editor and it will probably stay that way for a long time. And I say this because the implementation of @cmeriaux repeats the limitations of the current find dialog. It is a forward step, of course, but it doesn’t resolve the issues that bothers me.
Anyway, I would be happy if only half of all these suggestions were implemented. Thank you.
-
@Alan-Kilborn said in Filter the data !!!:
I’m sure not quite what is being asked for, but here’s a curious little Pythonscript.
That’s right, I wasn’t asking for it, however I am always open to new ideas. Veré si puedo integrarla - me refiero a la versión final - en mi forma de trabajar. Y por lo que veo en las imágenes de los post posteriores, los colores se ajustan a un fondo blanco, no creo que se vean bien en el fondo oscuro. Va a haber que trabajarlo un poco.
-
@astrosofista said :
I would like to have all the facilities of the editor in the search window.
I have some serious doubts that you’ll ever see this in Notepad++:

But it raises a question I’ve always had:
With copy and paste from editor window to Find what box, for other than “simple” encodings, how is the proper encoding maintained so that a search can be done for what the user intends? Is the Find what box as “encoding aware” as a Scintilla editing buffer?
Note: this question goes outside just copying “textually simple” regexes as @astrosofista mentioned.
Font has to play into it as well, right? Maybe not for actual content, but for what you’re visually looking at? The Find what box isn’t very “font flexible”. So do people that use non-basic encodings get stuck looking at odd sequences in the Find what box as they are composing a search term?
I only have occasional use for “non-simple” text in my searches, but I’m just wondering how this all works for those that do the “other kind” of searching on an everyday basis.
-
@astrosofista said in Filter the data !!!:
the colors match a white background, I don’t think they look good on the dark background.
The colors used are mostly those defined already for other uses in Notepad++, as I believe @guy038 mentioned. Thus, I’d think they’d already be set to render fairly well for whatever theme you’re using, dark or light. The two that aren’t predefined…it should be easy to change the RGB tuples for them as they are right in the code itself?:

Here’s a nice color picker for you:
https://www.w3schools.com/colors/colors_picker.asp
I’m sure there are many others, maybe better. -
@Alan-Kilborn said in Filter the data !!!:
So do people that use non-basic encodings get stuck looking at odd sequences in the Find what box as they are composing a search term?
I don’t use non-basic encodings but I don’t think that this is an issue
because the system font used, which as far as I know is used by the dialog, handles this, normally. -
Hi, @alan-kilborn and All,
Seemingly, in the
config.xmlfile, all characters above\x{007F}( so non pureASCII) are encoded with the usualXMLsyntax&#x....;, where a dot stands for an hexadecimal digitFor characters, over
\x{FFFF}( so outside the UnicodeBasic Multilingual Plane- BMP ), they are represented with two 16-bit code units called a surrogate pair. Refer to :https://en.wikipedia.org/wiki/Universal_Character_Set_characters#Surrogates
https://en.wikipedia.org/wiki/UTF-16#Code_points_from_U+010000_to_U+10FFFF
An example :
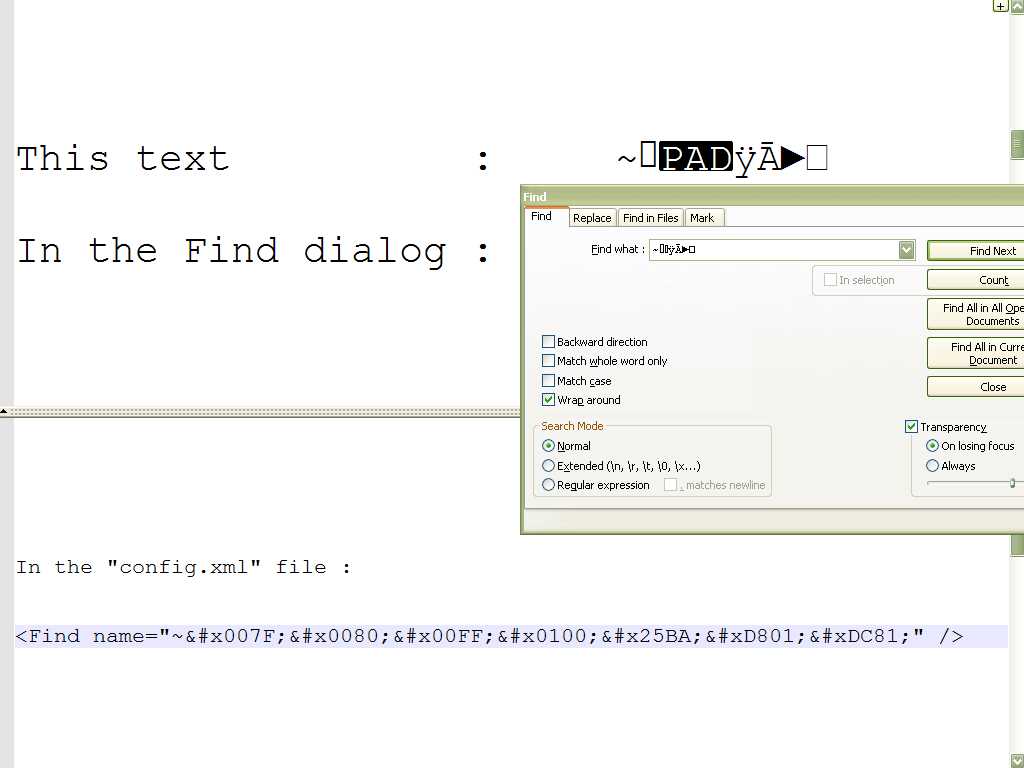
In this example, the last character, displayed by the
Courier Newfont as a small white square box, is the OSMANYA letter BA ( Unicode code-point10481) which can be described with the surrogate pair\x{D801}\x{DC81}, correctly handled and decoded by your OS !Refer http://www.unicode.org/charts/PDF/U10480.pdf
Best Regards,
guy038
-
This is how it looks on your system, but I assume it might look different on a system where OSMANYA is more common.
That is, of course, if there is a localized version of Windows that OSMANYA takes into account.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login