[UDL] Labels highlight In Custom Batch Doesn't Work As Expected
-
Hello Everyone,
I’m making my own UDL for Batch scripts (*.bat) files,
The out of the box syntax highlighting works and does what it is supposed to do, but I need some things I commonly use to be highlighted, (certain texts, functions etc);
I’ve modified the default langs.xml and removed the “bat” so that my UDL will become default when I open a batch script.
These are the items in my UDL,
[Folder & Default] Empty [Keywords] 1st group : call break some normal crap etc etc 2nd group: echo 8th group: echo. [Comment & Number] Allow Anywhere = Selected Comment Line = Open = REM Close = ((EOL)) Comment Style Open = :: Close = ((EOL)) [Operators & Delimiters] 1st @ = == 2nd & Delimiter 1 Open = % Close = % Delimiter 2 Open = ( Close = ) Delimiter 3 Open = " Close = " Delimiter 4 Open = : Close = ((EOF))The problem with this setup is, the “:” from delimiter 4 highlights labels in batch script, but it also highlights colons which are written for questions and other stuff.
I want the highlight to be done only if the colon is at the beginning of the line and ignore other colons,
I do understand that we can use colon on comment setting with force at the beginning, but I already have comment highlighters there and I use two colours for with two style in :: and REM.Can you please tell me if there is a way I can make the UDL highlight the line only if : is present at the beginning of the line and ignore others?
Thanks in advance.
-
@Vin-dickator said in [UDL] Labels highlight In Custom Batch Doesn't Work As Expected:
Delimiter 4 Open = : Close = ((EOF))I assume you actually meant
((EOL))there, because otherwise it just highlights from the label to the end.Can you please tell me if there is a way I can make the UDL highlight the line only if : is present at the beginning of the line and ignore others?
UDL does not have full regex capability. As far as I know, the only builtin way for anchoring a match to the beginning of the line is using the Comment Line Style, which you have already rejected. Personally, if I were using
::as an alternate comment syntax, as many batch authors do, I would want them highlighted the same whether it’sREMor::based; but you are allowed to define your own spec.Although you cannot do it in pure UDL, if you are willing to install the PythonScript plugin, there is a way: you can add extra highlighting to a UDL language using regexes via the script
EnhanceUDLLexer.pythat @Ekopalypse shares in this linked post. You would remove Delimiter 4 from your UDL, and instead define a regex in the script that was something like^:.*$and set your label highlighting colors in the script rather than in UDL. -
@Vin-dickator said in [UDL] Labels highlight In Custom Batch Doesn't Work As Expected:
I’m making my own UDL for Batch scripts (*.bat) files,
This statement strikes fear into the heart of any UDL writer.
Batch syntax is crazy.
Coupling that with UDL…shudder, shudder! :-) -
@PeterJones
Yes, that is ((EOL)), guess I made a typo there…
Thanks for the pointer on pythonscript, will check that out -
@Ekopalypse
Could you please spare some time to help me out here?Thanks to Peter’s link and direction, I have installed the PythonScript plugin and am using your script from the interface…
I tried modifying the py to fit my requirements following the in-code instructions, but it doesn’t seem to do anything even If I run it manually; For diagnosis if the PythonScript works naturally I tried enabling and disabling the virtual space option and it works…
Can you please check and let me know which part I’m missing here because the syntax highlighting is not working.
My UDL is named “BatchNew”
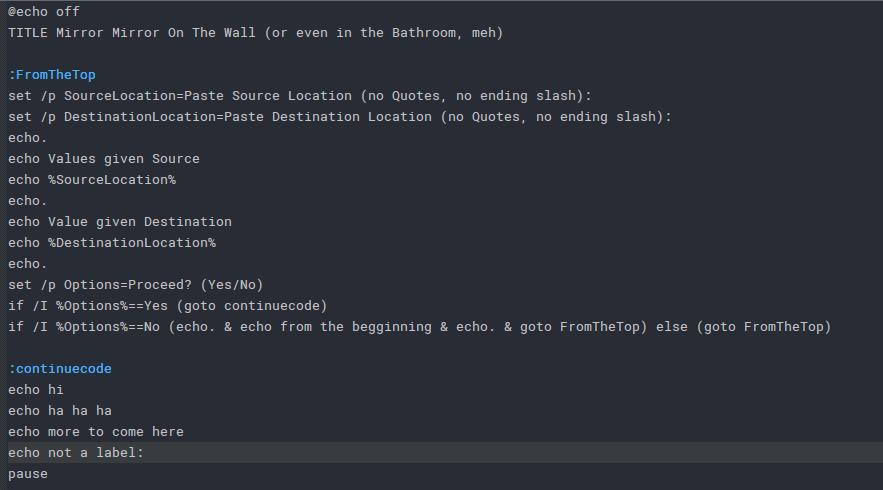
lexer_name = 'BatchNew' regexes[(0, (252, 173, 67))] = ('^:.*$', 19) excluded_styles = [1, 2, 16, 17, 18, 20, 21, 22, 23]Test.bat
@echo off TITLE Mirror Mirror On The Wall (or even in the Bathroom, meh) :FromTheTop set /p SourceLocation=Paste Source Location (no Quotes, no ending slash): set /p DestinationLocation=Paste Destination Location (no Quotes, no ending slash): echo. echo Values given Source echo %SourceLocation% echo. echo Value given Destination echo %DestinationLocation% echo. set /p Options=Proceed? (Yes/No) if /I %Options%==Yes (goto continuecode) if /I %Options%==No (echo. & echo from the begginning & echo. & goto FromTheTop) else (goto FromTheTop) :continuecode echo hi echo ha ha ha echo more to come here echo not a label: pauseFullCode of EnhanceUDLLexer.py
<Spoiler># -*- coding: utf-8 -*- from Npp import editor, editor1, editor2, notepad, NOTIFICATION, SCINTILLANOTIFICATION, INDICATORSTYLE import ctypes import ctypes.wintypes as wintypes from collections import OrderedDict regexes = OrderedDict() # ------------------------------------------------- configuration area --------------------------------------------------- # # Define the lexer name exactly as it can be found in the Language menu lexer_name = 'BatchNew' # Definition of colors and regular expressions # Note, the order in which regular expressions will be processed # is determined by its creation, that is, the first definition is processed first, then the 2nd, and so on # # The basic structure always looks like this # # regexes[(a, b)] = (c, d) # # regexes = an ordered dictionary which ensures that the regular expressions are always processed in the same order # a = a unique number - suggestion, start with 0 and always increase by one # b = color in the form of (r,g,b) such as (255,0,0) for the color red # c = raw byte string, describes the regular expression. Example r'\w+' # d = number of the match group to be used # Examples: # All found words which may consist of letter, numbers and the underscore, # with the exception of those that begin with fn, are displayed in a blue-like color. # The results from match group 1 should be used for this. # regexes[(0, (79, 175, 239))] = (r'fn\w+\$|(\w+\$)', 20) # All numbers are to be displayed in an orange-like color, the results from # matchgroup 0, the standard matchgroup, should be used for this. # regexes[(1, (252, 173, 67))] = (r'\d', 0) regexes[(0, (252, 173, 67))] = ('^:.*$', 19) # Definition of which area should not be styled # 1 = comment style # 2 = comment line style # 16 = delimiter1 # ... # 23 = delimiter8 excluded_styles = [1, 2, 16, 17, 18, 20, 21, 22, 23] # ------------------------------------------------ /configuration area --------------------------------------------------- try: EnhanceUDLLexer().main() except NameError: user32 = wintypes.WinDLL('user32') WM_USER = 1024 NPPMSG = WM_USER+1000 NPPM_GETLANGUAGEDESC = NPPMSG+84 SC_INDICVALUEBIT = 0x1000000 SC_INDICFLAG_VALUEFORE = 1 class SingletonEnhanceUDLLexer(type): ''' Ensures, more or less, that only one instance of the main class can be instantiated ''' _instance = None def __call__(cls, *args, **kwargs): if cls._instance is None: cls._instance = super(SingletonEnhanceUDLLexer, cls).__call__(*args, **kwargs) return cls._instance class EnhanceUDLLexer(object): ''' Provides additional color options and should be used in conjunction with the built-in UDL function. An indicator is used to avoid style collisions. Although the Scintilla documentation states that indicators 0-7 are reserved for the lexers, indicator 0 is used because UDL uses none internally. Even when using more than one regex, it is not necessary to define more than one indicator because the class uses the flag SC_INDICFLAG_VALUEFORE. See https://www.scintilla.org/ScintillaDoc.html#Indicators for more information on that topic ''' __metaclass__ = SingletonEnhanceUDLLexer def __init__(self): ''' Instantiated the class, because of __metaclass__ = ... usage, is called once only. ''' editor.callbackSync(self.on_updateui, [SCINTILLANOTIFICATION.UPDATEUI]) notepad.callback(self.on_langchanged, [NOTIFICATION.LANGCHANGED]) notepad.callback(self.on_bufferactivated, [NOTIFICATION.BUFFERACTIVATED]) self.doc_is_of_interest = False self.lexer_name = None self.npp_hwnd = user32.FindWindowW(u'Notepad++', None) self.configure() @staticmethod def rgb(r, g, b): ''' Helper function Retrieves rgb color triple and converts it into its integer representation Args: r = integer, red color value in range of 0-255 g = integer, green color value in range of 0-255 b = integer, blue color value in range of 0-255 Returns: integer ''' return (b << 16) + (g << 8) + r @staticmethod def paint_it(color, pos, length): ''' This is where the actual coloring takes place. Color, the position of the first character and the length of the text to be colored must be provided. Coloring occurs only if the position is not within the excluded range. Args: color = integer, expected in range of 0-16777215 pos = integer, denotes the start position length = integer, denotes how many chars need to be colored. Returns: None ''' if pos < 0 or editor.getStyleAt(pos) in excluded_styles: return editor.setIndicatorCurrent(0) editor.setIndicatorValue(color) editor.indicatorFillRange(pos, length) def style(self): ''' Calculates the text area to be searched for in the current document. Calls up the regexes to find the position and calculates the length of the text to be colored. Deletes the old indicators before setting new ones. Args: None Returns: None ''' start_line = editor.docLineFromVisible(editor.getFirstVisibleLine()) end_line = editor.docLineFromVisible(start_line + editor.linesOnScreen()) start_position = editor.positionFromLine(start_line) end_position = editor.getLineEndPosition(end_line) editor.setIndicatorCurrent(0) editor.indicatorClearRange(0, editor.getTextLength()) for color, regex in self.regexes.items(): editor.research(regex[0], lambda m: self.paint_it(color[1], m.span(regex[1])[0], m.span(regex[1])[1] - m.span(regex[1])[0]), 0, start_position, end_position) def configure(self): ''' Define basic indicator settings, the needed regexes as well as the lexer name. Args: None Returns: None ''' editor1.indicSetStyle(0, INDICATORSTYLE.TEXTFORE) editor1.indicSetFlags(0, SC_INDICFLAG_VALUEFORE) editor2.indicSetStyle(0, INDICATORSTYLE.TEXTFORE) editor2.indicSetFlags(0, SC_INDICFLAG_VALUEFORE) self.regexes = OrderedDict([ ((k[0], self.rgb(*k[1]) | SC_INDICVALUEBIT), v) for k, v in regexes.items() ]) self.lexer_name = u'User Defined language file - %s' % lexer_name def check_lexer(self): ''' Checks if the current document is of interest and sets the flag accordingly Args: None Returns: None ''' language = notepad.getLangType() length = user32.SendMessageW(self.npp_hwnd, NPPM_GETLANGUAGEDESC, language, None) buffer = ctypes.create_unicode_buffer(u' ' * length) user32.SendMessageW(self.npp_hwnd, NPPM_GETLANGUAGEDESC, language, ctypes.byref(buffer)) self.doc_is_of_interest = True if buffer.value == self.lexer_name else False def on_bufferactivated(self, args): ''' Callback which gets called every time one switches a document. Triggers the check if the document is of interest. Args: provided by notepad object but none are of interest Returns: None ''' self.check_lexer() def on_updateui(self, args): ''' Callback which gets called every time scintilla (aka the editor) changed something within the document. Triggers the styling function if the document is of interest. Args: provided by scintilla but none are of interest Returns: None ''' if self.doc_is_of_interest: self.style() def on_langchanged(self, args): ''' Callback gets called every time one uses the Language menu to set a lexer Triggers the check if the document is of interest Args: provided by notepad object but none are of interest Returns: None ''' self.check_lexer() def main(self): ''' Main function entry point. Simulates two events to enforce detection of current document and potential styling. Args: None Returns: None ''' self.on_bufferactivated(None) self.on_updateui(None) EnhanceUDLLexer().main()</Spoiler>
PS: I thought i’d be rude to disturb an old thread which you posted to, that’s the reason I’m pulling you here if you don’t mind.
-
the 19th match group should be used??
regexes[(0, (252, 173, 67))] = ('^:.*$', 19)0is an unique id
(252, 173, 67)is the color to be used
'^:.*$'is the regex
19means you want to use the 19th match group but there is none defined at all, I would expect
to see0here. -
@Ekopalypse
I thought, 19 is something to do with Delimiter 4 (since Delimiter8 is 23, guess I mis-understood that)I just tried replacing 19 with 0 and it still doesn’t change the highlight; please see below image
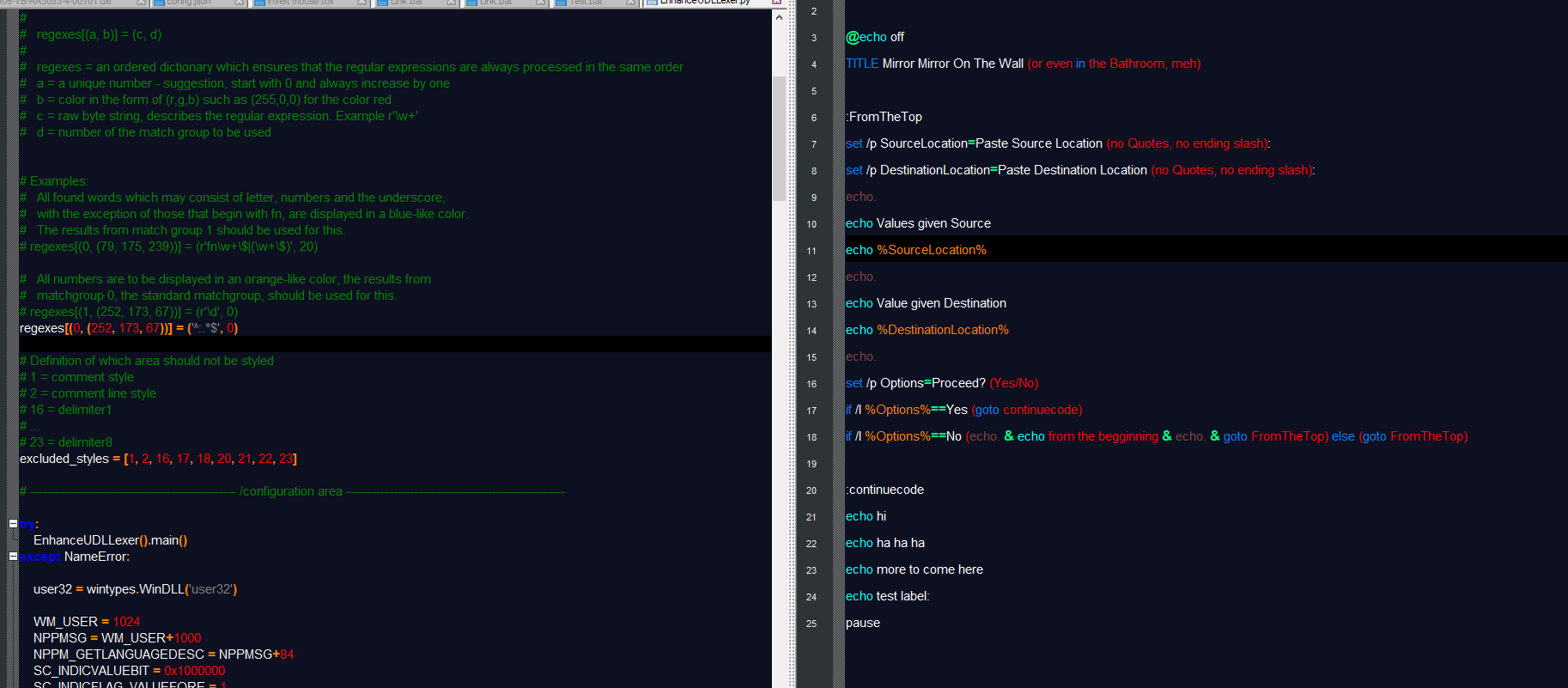
-
-
@Ekopalypse Yes , yes !
Did I miss something in my setup? -
No, I don’t think so - is the name really BatchNew?
It must be exactly the same as listed in the language menu. -
@Ekopalypse
It’s actually User Defined language file - BatchNew (I tried this too, before checking for just BatchNew)
Please see below image
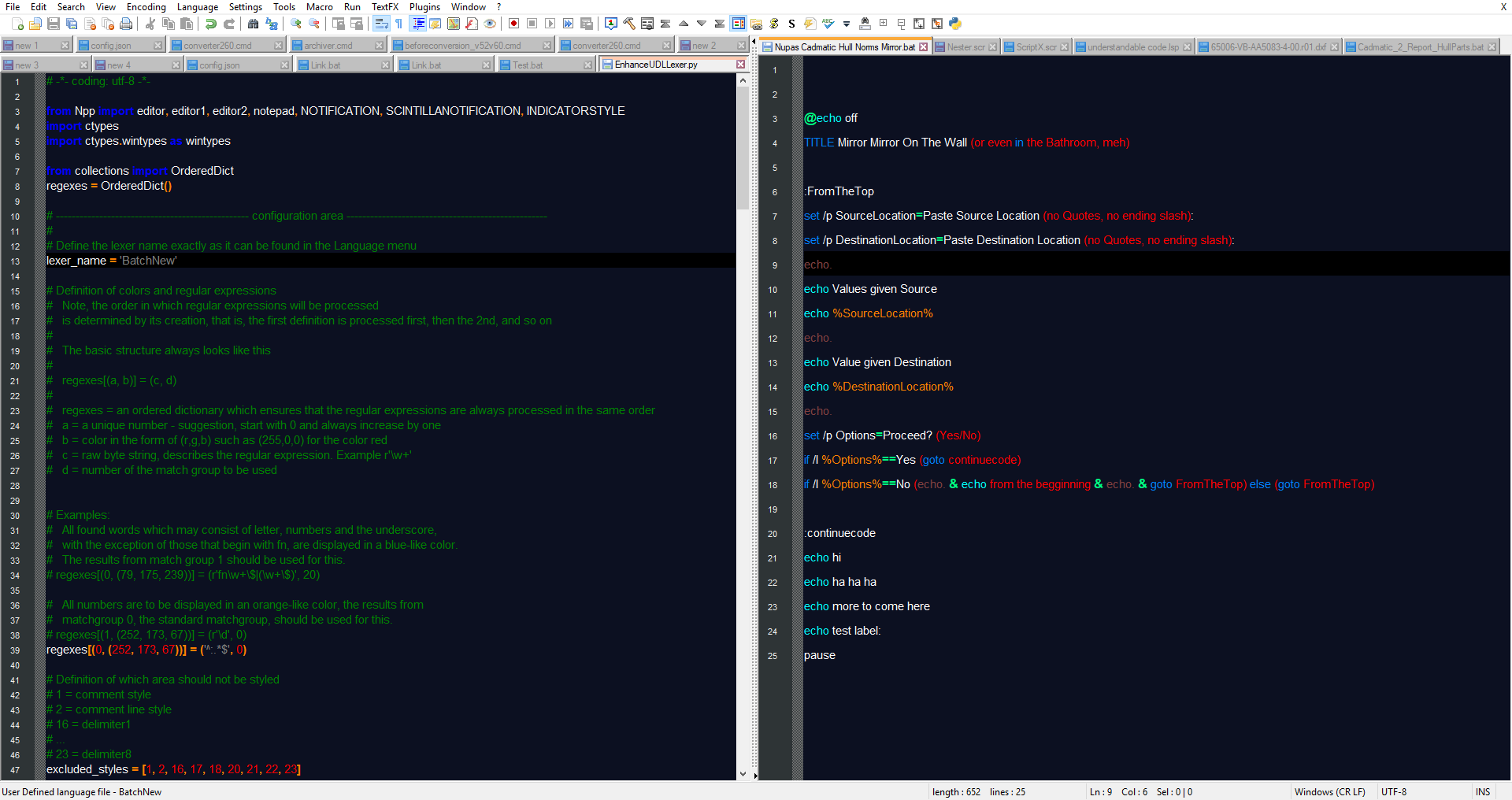
-
OK- then it should be BatchNew, the other stuff gets automatically added.
excluded_styles = [1, 2, 16, 17, 18, 20, 21, 22, 23]this means that regex matches do not get colored if one of the
styles is set to the positions of the match. Maybe you wanna start with
excluded_styles = []to see if there is something set. -
If this doesn’t work, can you post or link to the udl so that I can check this
on my side as well? -
@Ekopalypse
Yes, I kept empty brackets for ‘excluded_styles’, still no change -
gimme a sec to check it.
-
Seems to work for me
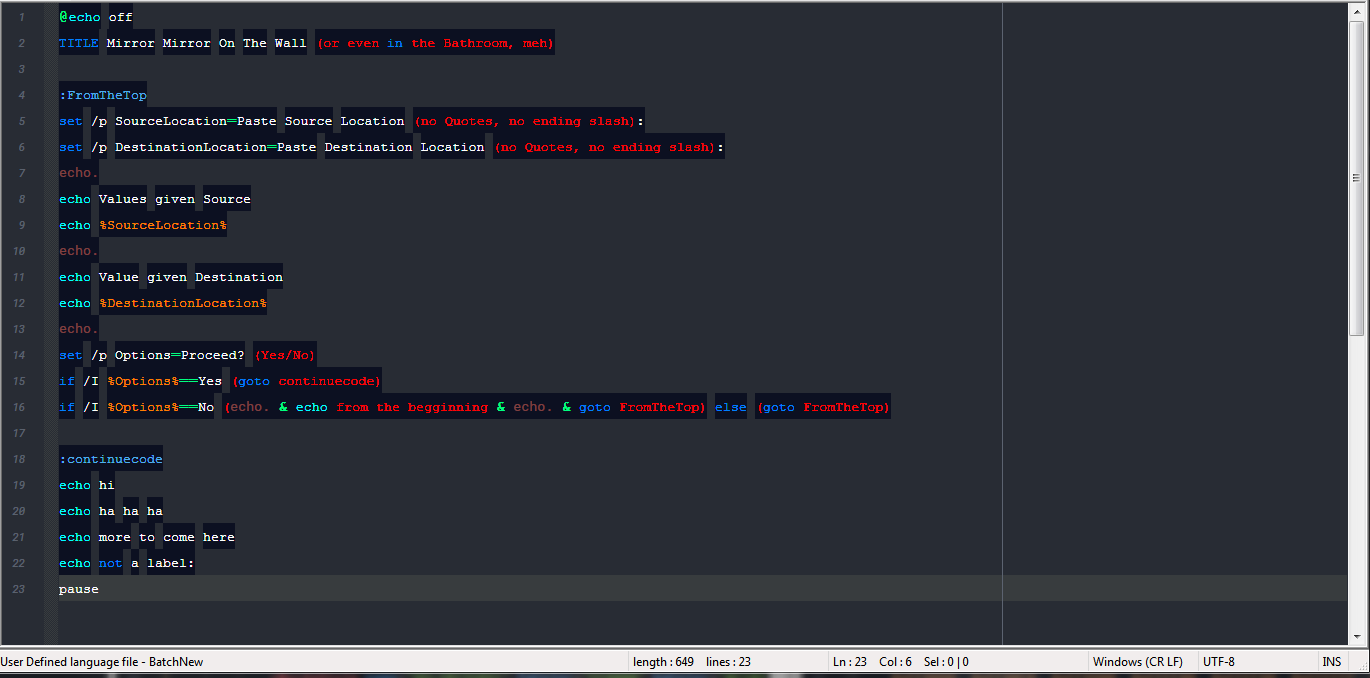
Could it be that you did the changes but haven’t restarted npp?
If so, sorry, there is no restart mechanism in the script - maybe I should add one. What I do, normally, is to edit the script, then run another instance of npp to see if the changes are good and if not, close the new instance, reedit, restart a new instance …
Not very user friendly but most of the time I only need one or two shots to make it work and see if the changes are good. -
I actually did restart several times, I suppose I did a faulty installation with the PythonScript… I’ll redo that one more time,
-
you can check if your PS installation is ok by opening the console from
Plugins->Pythonscript->Show Console
and enter something likenotepad.getPluginVersion()in the run box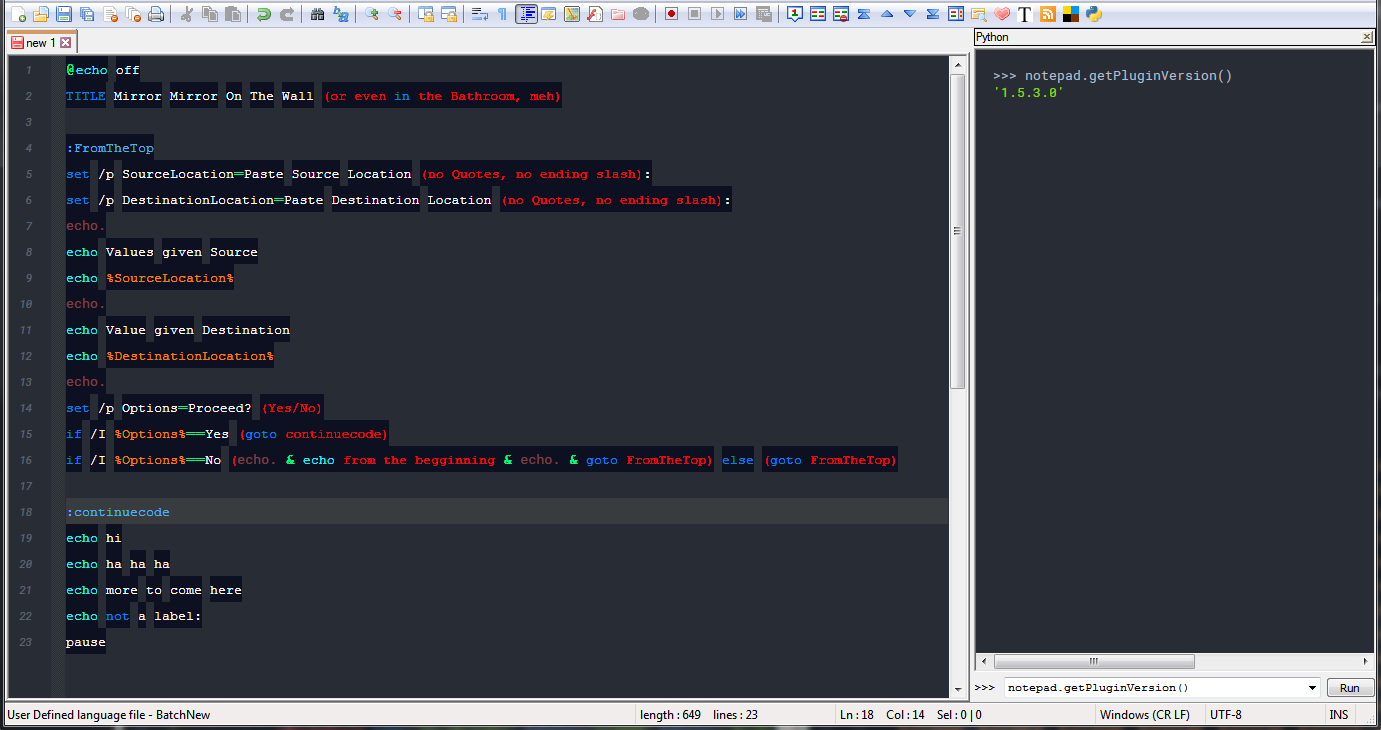
If this works, then installation is ok.
-
I just did a new installation of the PythonScript (last time, manually through zip, this time through msi)
It’s strange, it does return the version, but it also shows other things for me
Python 2.7.6-notepad++ r2 (default, Apr 21 2014, 19:26:54) [MSC v.1600 32 bit (Intel)] Initialisation took 32ms Ready. Traceback (most recent call last): File "C:\K\OD\Stuff\Soft\Notepad++\plugins\PythonScript\scripts\EnhanceUDLLexer.py", line 260, in <module> EnhanceUDLLexer().main() File "C:\K\OD\Stuff\Soft\Notepad++\plugins\PythonScript\scripts\EnhanceUDLLexer.py", line 72, in __call__ cls._instance = super(SingletonEnhanceUDLLexer, cls).__call__(*args, **kwargs) File "C:\K\OD\Stuff\Soft\Notepad++\plugins\PythonScript\scripts\EnhanceUDLLexer.py", line 100, in __init__ self.configure() File "C:\K\OD\Stuff\Soft\Notepad++\plugins\PythonScript\scripts\EnhanceUDLLexer.py", line 179, in configure editor1.indicSetStyle(0, INDICATORSTYLE.TEXTFORE) AttributeError: type object 'INDICATORSTYLE' has no attribute 'TEXTFORE' >>> notepad.getPluginVersion() '1.0.8.0' -
that is actually a very old version. Any particular reason
why you need to use it? What is your npp version?
Can be checked from the ? menu->Debug info.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login