move everything on a line after the occurrance of a string to a fixed column
-
Hi, I have no doubt this has been asked before, but I cant find the question…
I have a file, ( 4000+ entries )QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEIn which I want everything after the first space to start in column 32, using spaces, not tabs
QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEWhat regex expression should I using to achieve this goal?
-
Personally(*), I would accomplish this task in two steps: first, make sure everything has at least 32 spaces after the first word; second, reduce those so that there are only 32 characters in the left section.
-
make sure everything has at least 32 spaces after the first word
- FIND =
(?-s)^(.*?)\x20 - REPLACE =
${1}\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20(that’s 32 of the\x20character to encode a space - Search Mode = regular expression
- FIND =
-
reduce those so that there are only 32 characters in the left section
- FIND =
(?-s)^(.{32})\x20* - REPLACE =
${1} - Search Mode = regular expression
- FIND =
Based on your definition of “start in column 32”, I may be off by 1-2 chars in where the final placement is; change the
{32}by +/- 1-2 if it’s note quite right; you might also want a few extra\x20in the first replacementI gave that caveat because I would call your example text having the second word start in column 34:
123456789x123456789x123456789x123456789x QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEIf that space at the beginning was real, then we might need to tweak that first expression to ignore a space in the first column.
123456789x123456789x123456789x123456789x QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEThis should give you a starting point. If it doesn’t work, explain how it was wrong (including numerical rulers, if necessary)
*: some would craft a single regex to do it. I have been known to try that, even in this forum. But really, for practical regex, it’s best to stick with what’s logical and most efficient – and with what you can easily think of and understand. It’s usually more efficient to do something like this in multiple steps, because the time spent in crafting a super-fancy regex might make it more fragile (less able to handle slight changes) than step-by-step ones.
-
-
I would call your example text having the second word start in column 34
Based on that same definition, I would actually call my result “start in 33” rather than “start in 32”.
Yours would’ve been “start in 33” in a 0-based, which is what would be required for mine to be “start in 32”.
This should give you a starting point. If it doesn’t work, explain how it was wrong (including numerical rulers, if necessary)
I apparently never finished that thought. I meant to go on and say:
But before asking us for more help, try to tweak what I gave you to get closer to your goal. If you try, but still cannot get it quite right, show us what you tried, and we can help you tweak it more.
-
@PeterJones Thanks!! It worked like a charm.
I notice you use ${1}
I generally use \1
is ${1} the preferred method for labels now?FYI… The number 32 was just a guess, based on a small sample. Given some of the tags I just saw, it’ll be around 60.
-
@PeterJones Thanks!! It worked like a charm.
Glad it works for you.
I notice you use ${1}
I learned regex in Perl, where the
\1notation has been deprecated in favor of$1or${1}for quite some time. It’s what I’m used to. And by using the braces, it always disambiguates between${1}0and${10}, whereas$10or\10always means the former, but looks an awful lot like it means the latter. But it’s just a stylistic choice; they all work. -
Hello, @anthony-bouttell, @peterjones and All,
Like @peterjones, here is an other two-steps method. But:
-
As it seems that each line of your text begins with a space char, I slightly change the first search regex
-
In the second search regex, we skip the first
31characters of each line, then we grasp any non-null range of space chars
So, assuming your initial text :
QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEThis regex S/R :
SEARCH
(?<=\w)\x20.+REPLACE
\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20$0In replacement, note the
$0syntax, after the30consecutive space chars (\x20)gives :
QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEAnd with this second regex S/R
SEARCH
^.{31}\K\x20+REPLACE
Leave EMPTYYou should get the expected data :
QUALIFIEDMORTGAGECODE QUALIFIED MORTGAGE CODE PURCHASEPRICE PURCHASE PRICE PROPERTYVALUEAMOUNT PROPERTY VALUE AMOUNT PROPERTYTYPE PROPERTY TYPEIMPORTANT :
-
Due to the presence of the
(?<=\w)look-behind syntax and the\Ksyntax, you must use theReplace Allbutton, exclusively, for these two S/R ! -
If you need to perform these two regex S/R on a part of your text, only, in order to restrict the scope of the
Replace Allbutton, simply do a selection of the range of text, involved in the S/R, and tick theIn selectionoption ! -
In order that the second regex S/R correctly works, a fair amount of spaces characters must fill up each line. When in doubt, just perform, again, the first regex S/R, to add
30spaces, again, before running the second S/R
Best Regards,
guy038
-
-
Hi @Anthony-Bouttell, @PeterJones, @guy038, All:
For the sake of variety, look at this non-regex solution (it only requires the
BetterMultiSelectionandElastic Tabstopsplugins installed and enabled, which you can download and install viaPlugins Admin):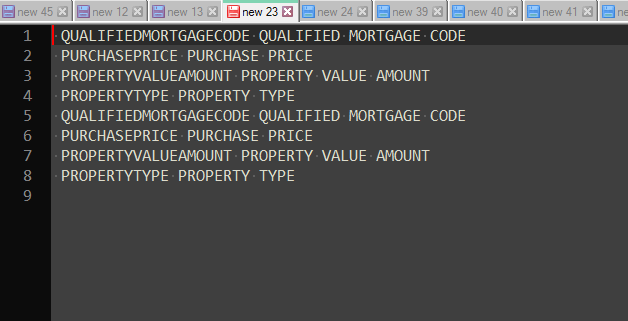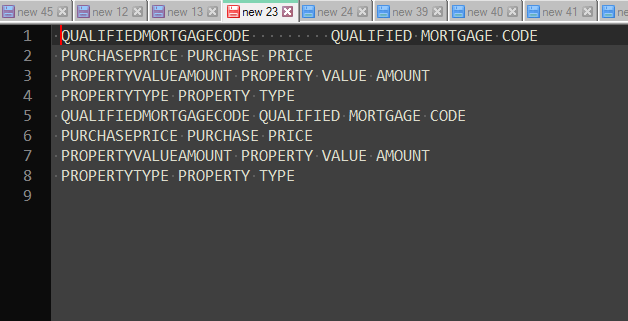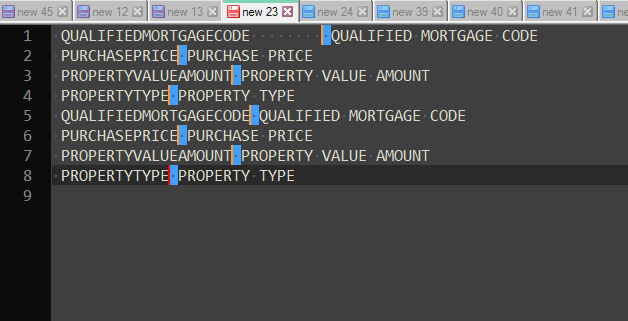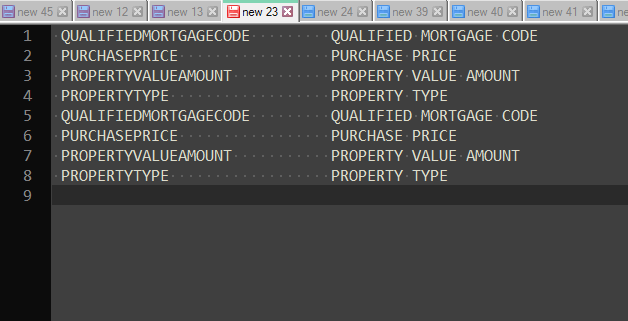
First off, open
Preferences -> Editing, and enable theMulti-Editing Settings.Then, do as the movie shows:
-
Go to the first line and insert the required spaces to move the second word up to column 32.
-
Press
Hometo place the caret at the beginning of this line. -
Press
Shift + Altand move the caret from the top line until the bottom of the list with thearrow down- you will get a giant caret blinking along 8 lines with no characters selected. -
Press
Ctrl + Righttwice. Eight carets will be blinking at the left of each second word. -
Press
Shift + Leftto backward select a space. -
Press
Tabto magically align all the second words. -
Press
Escand thenDownto release the multiselection. -
Select
Plugins -> Elastic Tabstops -> Convert Tabstops to Spaces.
That’s all. Hope you like it.
Have fun!
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login