RegEx problems
-
I have it like this:
abc
1
2
3It should look like this:
abc 123I want to find quotation marks:
"
How to apply these markings:
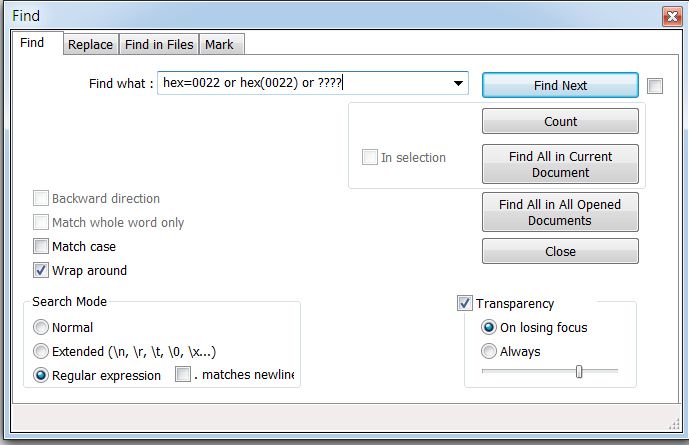
0022 or (0x22) -
@Pan-Jan ,
You neglected the
</>button in your post on your example before and after data. You know better.You have occasionally shown that you understand some regex concepts. But then you ask a question like this, where you appear to have no idea what syntax is available. I will re-quote my generic regex help guide at the end. Please read and understand what is there.
If you want to join lines in a regex: first, grab two (or more) groups with
\r\nin between. Second, use the group substitutions$1$2without the\r\nbetween.I assume your quotation mark question is completely unrelated to your merge question. I do not know what you mean by “how to I apply these markings”. Do you want to convert the literal text
"into the literal text0x22? If so, that’s so simple that you don’t even need regex: search =", replace =0x22.-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as plain text using the
</>toolbar button or manual Markdown syntax. Screenshots can be pasted from the clipbpard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get… Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
I have it like this:
abc 1 2 3It should look like this:
abc 123 -
I want to find quotation marks:
"Can I search for 0022 or (0x22) instead
"
e.g
that you understand some regex conceptsI agree… some.
I’ve been practicing for about 3 weeks -
\x22 -
@Pan-Jan said in RegEx problems:
I have it like this:
abc 1 2 3It should look like this:
abc 123- FIND =
(?-s)^(.*)\R(.*)\R(.*)\R(.*)$ - REPLACE =
$1\x20$2$3$4
- FIND =
-
ABC 1 2 3 4 5ABC 12345ZNAJDŹ =
(?-s)^(.*)\R(.*)\R(.*)\R(.*)\R(.*)\R(.*)\R(.*)$
REPLACE =$1\x20$2$3$4$5$6And when there are more than 5?
-
@Alan-Kilborn
Thanks
in fact, I’ve seen\x20many times but didn’t associate it. -
@Pan-Jan said in RegEx problems:
And when there are more than 5?
As far as I know, you have to keep on adding more groups.
There may be some regex that would allow finding one line, followed by one or more lines; join with a space between the first two, and join without space on any additional lines. But I don’t know what it would be, and our resident regex magician is on holiday this month. But maybe one of the other gurus has some ideas.
-
@PeterJones
I tried((.*)\R){6}instead(.*)\R(.*)\R(.*)\R(.*)\R(.*)\R(.*)\R
but nothing works. -
@Thomas-2020 said in RegEx problems:
And when there are more than 5?
Actually there is a regex which will work regardless of how many numbers appear on the following lines in 1 pass.
Using the Replace function we have:
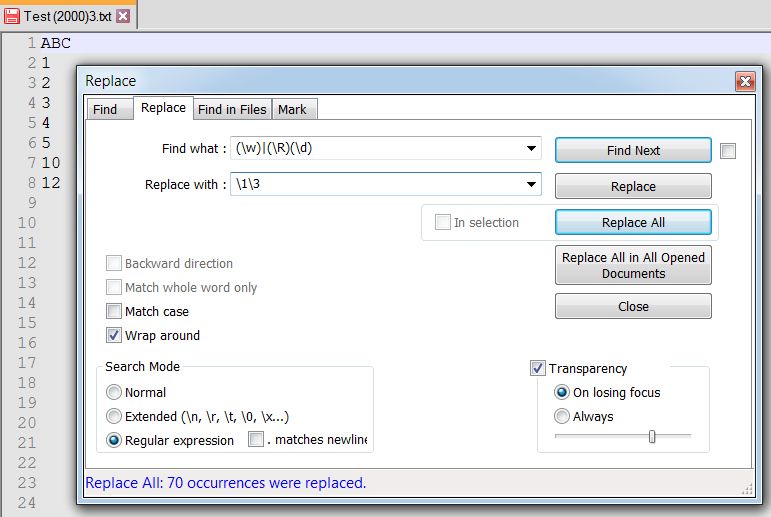
Find What:(\w+$)|(\R(\d+))
Replace With:(?1\1\x20)(?2\3)So by using “alternation” we either have a word line or a number line. Each is dealt with in a different manner. the word line is re-written with a following space (\x20) and the number line has the preceding line feed/carriage return removed.
There is a proviso though. As this just lumps the numbers together, once you get to 10, how do you identify each of the “separate” numbers in the group. See my example below.
ABC 1 2 3 4 5 ABC 1 2 3 4 5 6 7 8 9 10 11 ABC 1 2 3 ABC 1 2 3 4 5 6 7 8 9 10 11 12and now we have:
ABC 12345 ABC 1234567891011 ABC 123 ABC 123456789101112Not a pretty number sequence anymore!
Terry
-
Thanks, it works great.
I mainly learn from examples.
the written explanation after translation is usually “bla” “bla” “bla”
I have a request to show me a specific example,
when is it necessary to use this (?1)
So far, everything works without this pattern.
e.g
(?1\1)(?2\3) -> \1\3 -
@Pan-Jan said in RegEx problems:
when is it necessary to use this
(?1)That is the “conditional replacement” notation, described at https://npp-user-manual.org/docs/searching/#substitution-conditionals
Basically, @Terry-R’s replacement regex says
(?1\1\x20)= if group1 (the\w+$subpattern) matched, then include the contents of group1 followed by a space in the replacement(?2\3)= if group2 (the newline followed by one or more digits) matched, then include the contents of group3 (just the digits from inside group2) in the replacement
Your replacement
\1\3will strip out the newlines, but it will not put a space after theabcand before the123. If that’s okay with you (even though it violates the original), then your simpler regex will work. But @Terry-R’s regex actually matches the behavior you claimed you wanted. -
-
Posting screenshots without text describing them isn’t going to get you very far.
I think we need to “draw the line” and put a stop to Community members using this forum as a means to “learn regular expressions”.
It isn’t what this site is for.
Sure, asking questions about the “peculiarities” of the N++ regex engine is certainly welcome here, as are general questions of “how to transform data” by noobs that may never even heard of the regular expression concept are also welcome.
But to blatantly use this site as a continual Q-and-A, back-and-forth discussion of common regex concepts is, well, annoying. There are far better places for that type of discussion.
-
This post is deleted! -
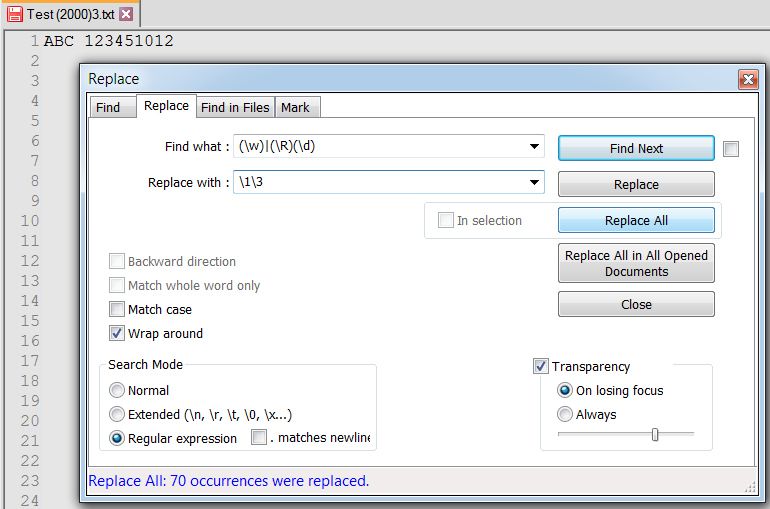
Your replacement \1\3 will strip out the newlines, but it will not put a space after the abc and before the 123.
I showed there is a space between ABC and 123451012.Sure, asking questions about the “peculiarities” of the N++ regex engine is certainly welcome here
I think we need to “draw the line” and put a stop to Community members using this forum as a means to “learn regular expressions”.
No comment -
Hello, @pan-jan, @alan-kilborn, @peterjones and All,
Two years ago, about, I said :
By answering, for the most part, to questions, related to regular expressions, ( for years ! ), am I distorting the true purpose of this forum, which should remain, I agree, focused on the features, improvements and bugs of Notepad++ ?
Refer to :
https://notepad-plus-plus.org/community/topic/16509/regex-select-all-from-row-except/16
So, I totally agree with Alan’s assertion ! There are plenty of sites, devoted to regex’s learning :-)) So, @pan-jan, just have a look to this FAQ :
https://notepad-plus-plus.org/community/topic/15765/faq-desk-where-to-find-regex-documentation/1
To my mind, one needs
2weeks, about, to get the basics of regular expressions and, let’s say, between1to3months to fully understand all the subtleties of this pseudo-language ;-))Cheers,
guy038
-
I wrote above that reading texts in a foreign language in such matters does not make sense.
I know Polish and German.For me, what matters is a specific answer.
Then I will analyze and verify it.
If it’s okay, I’ll try to remember it.For me, the lack of a specific answer means that my version is correct.
Simple logic.it works:
Replace With:(?1\1\x20)(?2\3)correct:
Replace With:\1\3Cheers, Thomas 2020.
Chers translated into Polish means the same as: “Your health”
This is what people say when they toast with a glass of vodka in their hands.Unfortunately, that’s how translators work.
Maybe in 20 years it will be better. -
Ok, überzeuge mich das ich es nicht mit einem Troll zu tun habe.
Was ist die Frage, was hast Du gemacht, was war das Resultat und
was hättest Du erwartet?Übrigens, cheers bedeutet im englischen auch Prost,
wird aber auch als Grußwort benutzt.Ok, convince me I’m not dealing with a troll.
What is the question, what did you do, what was the result and
what did you expect?By the way, cheers in English means Prost,
but is also used as a greeting word.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login