Replace non-breaking space UTF-8 (C2 A0)
-
Hi,
When I paste my programming code into gmail it replaces the spaces with non-breaking spaces.
When I copy/paste the programming code from gmail to notepad++ i see the non-breaking spaces as C2 A0 in hex view mode. In hex view mode i can replace C2 A0 with 20 (space).How can I replace the non-breaking spaces (C2 A0) without going to hex view mode first?
I tried “\xC2\xA0” in Regular expression search mode but that does not work, it says it can’t find the text “\xC2\xA0”.Thanks,
Bart -
@Bart-Heinsius said in Replace non-breaking space UTF-8 (C2 A0):
\xC2\xA0
Search for
\x{A0}using regular expression mode. You can use the\x{xxxx}style for any 16-but Unicode character. It does not work for characters beyond\x{ffff}such as the newer emoticons. -
Hex editing is a “low-level” operation (encoding-unaware).
Regular expression operations function at a higher-level (encoding-aware).
Note: Encoding turns special strings of low-level bytes into different values of higher-level characters. (That’s the short version).The best way to perform the operation is to get the data you want to replace into the Find what box. You can do this by selecting the character and then pressing Ctrl+f. Replace it with anything you want.
-
@mkupper Searching for \x{A0} finds all my newlines too, I just want the non-breaking spaces (and replace them all with normal spaces).
Searching for \x{C2A0} does not find the non-breaking spaces.
-
@Alan-Kilborn I selected a non-breaking space in the document, copied it into the Find and replace dialog, to replace it with a normal space, but the non-breaking spaces are still in there.
-
@Bart-Heinsius - What language or file extension are you using on the notepad++ side? I tested using plain .txt but you mentioned “programming code” being copied to/from gmail.
What encoding are you using? Click the
Encodingmenu option to see what’s currently selected. I would expectUTF-8orUTF-8 BOM.Can you show the full expression you are using to search? There is a
. matches newlineoption on the search/replace box but\x{A0}by itself should not be matching newlines and does not for me. Likewise, the suggestion to copy/paste from one of the non-breaking spaces you know of into the search box should not result in matching with newlines. -
@Bart-Heinsius said in Replace non-breaking space UTF-8 (C2 A0):
I selected a non-breaking space in the document, copied it into the Find and replace dialog, to replace it with a normal space, but the non-breaking spaces are still in there.
Worked for me to replace non-breaking spaces.
Don’t know what’s truly going on with your situation. -
To help us understand what’s going on for you, could you share a screenshot similar to the following:
I created a file with non-breaking spaces between the words (so there were two of them), and did a Count, which correctly showed the two. My screenshot also includes the current encoding in the status bar:
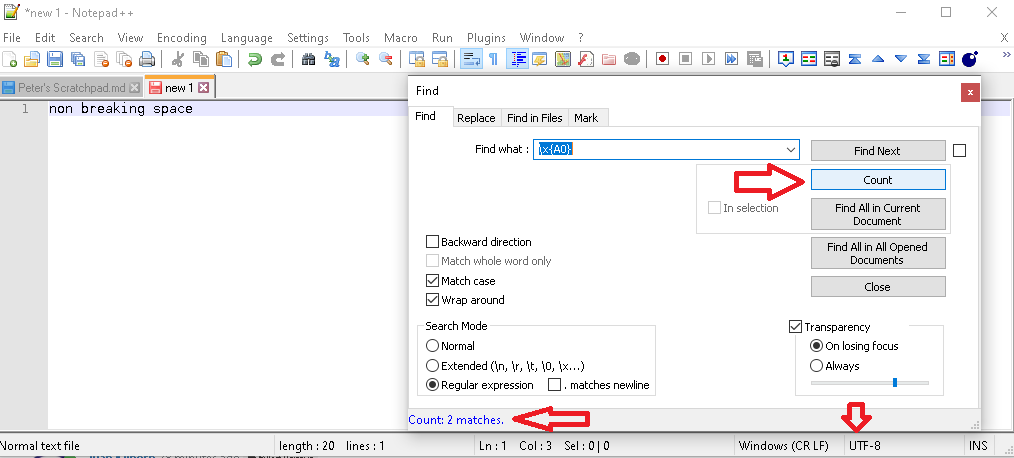
(edit: in case I wasn’t clear, we want the screenshot of your real file, not of a brand new file created to look like mine)
Another thing to do would be for a small snippet from your file, which contains the non-breaking space, select the text, use Plugins > MIME Tools > Base64 Encode, and paste the results here, using the forum’s
</>button to make sure it comes through as real text:bm9uwqBicmVha2luZ8Kgc3BhY2UWith that, we can Base64 Decode and have the same bytes as you for the experiment.
Anything you can do to help us replicate your circumstances will help us help you debug the problem.
(Also, grab ? menu, Debug Info and paste in your reply)
-
@PeterJones I’m sorry, i was mistaking the A0 with newlines (0A).
I thought I needed to replace the C2A0 that I see in hex view.
But replacing just A0 by a space also gets rid of the C2.
Thanks for your time and support. -
Glad it’s working for you now.
In case you are curious,
0xC2 0xA0is the two byte sequence in UTF-8 that represents the single character atU+00A0.As @Alan-Kilborn said, the search-and-replace feature works with the actual character codepoints, hence uses
\x{A0}or\x{00A0}to match that character, whereas the Hex Editor works with the individual bytes, so shows you both the byte 0xC2 and the byte 0xA0.Like the hex editor, The MIME Tools plugin uses the raw bytes, rather than the characters. You can easily see this in my example, which using MIME Tools > URL Encode shows
non%C2%A0breaking%C2%A0space, so you can see%C2and%A0are used to encode the bytes0xC2 0xA0which are used to encode the character atU+00A0.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login