File display using multiple fonts simultaneously?
-
Strange. It seems to be a bug only in Windows 7, so it’s probably to do with Windows 7 font-handling for Unicode. Since it’s dependent on the version of Windows, rather than Notepad++, there’s probably not much we can do.
In theory, since Unicode 3.2, using U+FEFF as a zero-width non-breaking space is deprecated, so U+FEFF should only really be used at the beginning of the file. When U+FEFF is at the beginning of a file (as bytes EF BB BF for a UTF-8 file), Notepad++/Scintilla will properly read that file, and you won’t even notice the BOM at the beginning of the file when editing a UTF-8 file. But BOMs don’t really belong in the middle of files.
Ideally, you would fix whatever process is being used that is incorrectly inserting BOMs at strange places in the document, so it doesn’t trigger the Windows 7 font-handling bug. But, as a workaround, you could do a regex-based Replace All in your document, searching for
\x{FEFF}and replacing with nothing (or with something like[!BOM!]so you know where your text-generator is inserting those characters, to help with debug). You can even record a macro of you running that search-and-replace-all, and assign that to a keystroke, so that you can just use a simple keystroke to fix the problem any time it does crop up. -
@PeterJones said in File display using multiple fonts simultaneously?:
…when editing a UTF-8 file. But BOMs don’t really belong in the middle of files.
And for UTF-8 files, they (BOM) don’t really belong anywhere at all.
Hint: “BO” stands for “Byte Order”, and there’s no endian stuff going on in files with this format.I was going to chime in with this earlier, but I didn’t because:
- clearly they were needed to expose the font problem
- I was unsure if we were always talking about UTF-8 files
- hey, who am I to tell people what to put in their data :-)
-
@PeterJones said in File display using multiple fonts simultaneously?:
Ideally, you would fix whatever process is being used that is incorrectly inserting BOMs at strange places in the document
As far as I can tell, the BOMs exist in the ExifTool-exported JSON because they exist in the various metadata fields as originally written by Directory Opus. But that’s for another forum…
Ideally for ME, in the meantime, I’d like to devise an ExifTool command line to search for all BOMs in metadata and replace them with nothing. But if they’re in the metadata, I want to be able to see so in the exported JSONs.
@Alan-Kilborn said in File display using multiple fonts simultaneously?:
Hint: “BO” stands for “Byte Order”
And all this time I thought it stood for “Body Odor”! :-)
Thanks, both of you, for your input.
-
@M-Andre-Z-Eckenrode said
And all this time I thought it stood for “Body Odor”! :-)
My off the cuff comment about what BOM stands for was made because often people don’t have a clue about its meaning. They just hear “this file has to have a BOM” and they go in search of the menu options (for example, in Notepad++) that can give their file one, and then they forget about it, never really understanding what it means, why it is (or isn’t) needed, etc.
But I was intending that for other/future readers, not necessarily for you, who seemed to understand its meaning from the start. Sorry if it seemed to be a jab at you – I didn’t mean it to be.
-
@Alan-Kilborn said in File display using multiple fonts simultaneously?:
hey just hear “this file has to have a BOM”
To be fair, sometimes that’s because another tool expects the BOM, even though it’s meaningless in the UTF-8 environment. As the wiki:BOM article states:
The Unicode Standard permits the BOM in UTF-8, but does not require or recommend its use. Byte order has no meaning in UTF-8, so its only use in UTF-8 is to signal at the start that the text stream is encoded in UTF-8, or that it was converted to UTF-8 from a stream that contained an optional BOM. The standard also does not recommend removing a BOM when it is there, so that round-tripping between encodings does not lose information, and so that code that relies on it continues to work.
So, it can be useful for telling (some) tools that the data stream is, in fact, UTF-8, even though that wasn’t the intended purpose of the Unicode BOM.
-
@M-Andre-Z-Eckenrode said in File display using multiple fonts simultaneously?:
But if they’re in the metadata, I want to be able to see so in the exported JSONs.
Hopefully my suggested SEARCH=
\x{FEFF}, REPLACE=[!BOM!](or whatever you prefer) is sufficient for that need.Again, glad we were able the find the culprit, and good luck interacting with your over-zealous BOM system. :-)
-
@Alan-Kilborn said in File display using multiple fonts simultaneously?:
Sorry if it seemed to be a jab at you — I didn’t mean it to be.
No worries — not at all. I was just trying to inject a little humor.
@PeterJones said in File display using multiple fonts simultaneously?:
Hopefully my suggested SEARCH=
\x{FEFF}, REPLACE=[!BOM!](or whatever you prefer) is sufficient for that need.Unfortunately, that didn’t work in my attempted implementation with ExifTool, but I started a help request topic in their forum. (Here, if you’re interested).
-
Hello, @m-andre-z-eckenrode, @Peterjones, @alan-kilborn and All,
Did you know that it’s very easy to spot invisible characters with the Mark feature ?
So, in the table below, you’ll find all the Unicode invisible characters, whatever the font used. All of them have the General Category Unicode property
Cf( for Format Characters ).Note that some of them may change the displaying of the current line, depending of the current font used !
•--------•----•----------------------------------------------------• | Hexa | Ch | Character NAME | •--------•----•----------------------------------------------------• | 200B | | ZERO WIDTH SPACE | | 200C | | ZERO WIDTH NON-JOINER | | 200D | | ZERO WIDTH JOINER | | 200E | | LEFT-TO-RIGHT MARK | | 200F | | RIGHT-TO-LEFT MARK | •--------•----•----------------------------------------------------• | 202A | | LEFT-TO-RIGHT EMBEDDING | | 202B | | RIGHT-TO-LEFT EMBEDDING | | 202C | | POP DIRECTIONAL FORMATTING | | 202D | | LEFT-TO-RIGHT OVERRIDE | | 202E | | RIGHT-TO-LEFT OVERRIDE | •--------•----•----------------------------------------------------• | 206A | | INHIBIT SYMMETRIC SWAPPING | | 206B | | ACTIVATE SYMMETRIC SWAPPING | | 206C | | INHIBIT ARABIC FORM SHAPING | | 206D | | ACTIVATE ARABIC FORM SHAPING | | 206E | | NATIONAL DIGIT SHAPES | | 206F | | NOMINAL DIGIT SHAPES | •--------•----•----------------------------------------------------• | FEFF | | ZERO WIDTH NO-BREAK SPACE - Byte Order Mark (BOM) | •--------•----•----------------------------------------------------•In order to find out all these chars :
- Open the Mark dialog (
Ctrl + M)
SEARCH
[\x{200B}-\x{200F}\x{202A}-\x{202E}\x{206A}-\x{206F}\x{FEFF}]-
Optionally, tick the
Bookmark lineoption -
Choose the
Regular expressionsearch mode -
Click on the
Mark Allbutton
You may also use a macro which will spot all invisible characters in a selection. Here is its code :
<Macro name="Invisible Chars in Selection" Ctrl="no" Alt="no" Shift="no" Key="0"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="[\x{200B}-\x{200F}\x{202A}-\x{202E}\x{206A}-\x{206F}\x{FEFF}]" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1615" sParam="" /> </Macro>If we select your previous example and run the
Invisible Chars in Selectionmacro, against your text :[{ "SourceFile": "./1-NoMeta.png", "XMP:XMPToolkit": "Image::ExifTool 12.00", "XMP:Creator": ["M André Z Eckenrode <authors>"], "XMP:Description": "Prefix; M André Z Eckenrode <description>; Suffix", "XMP:Rights": "© 2020 M André Z Eckenrode <copyright>", "XMP:Subject": ["Prefix; M André Z Eckenrode <subject>; Suffix"], "XMP:Title": "Prefix; M André Z Eckenrode <title>; Suffix", "XMP:UserComment": "Prefix; M André Z Eckenrode <comment>; Suffix", "XMP:Instructions": "M André Z Eckenrode <instructions>", "XMP:CreatorTool": "Éé <software>", "EXIF:ImageDescription": "Prefix; M André Z Eckenrode <description>; Suffix", "EXIF:Software": "Éé <software>", "EXIF:Copyright": "© 2020 M André Z Eckenrode <copyright>", "EXIF:XResolution": 72, "EXIF:YResolution": 72, "EXIF:ResolutionUnit": "inches", "EXIF:YCbCrPositioning": "Centered", "EXIF:ExifVersion": "0232", "EXIF:ComponentsConfiguration": "Y, Cb, Cr, -", "EXIF:UserComment": "Prefix; M André Z Eckenrode <comment>; Suffix", "EXIF:FlashpixVersion": "0100", "EXIF:ColorSpace": "Uncalibrated", "EXIF:XPTitle": "Prefix; M André Z Eckenrode <title>; Suffix", "EXIF:XPComment": "Prefix; M André Z Eckenrode <comment>; Suffix", "EXIF:XPSubject": "Prefix; M André Z Eckenrode <subject>; Suffix", "IPTC:CodedCharacterSet": "UTF8", "IPTC:EnvelopeRecordVersion": 4, "IPTC:By-line": "M André Z Eckenrode <authors>", "IPTC:CopyrightNotice": "© 2020 M André Z Eckenrode <copyright>", "IPTC:Caption-Abstract": "Prefix; M André Z Eckenrode <title>; Suffix", "IPTC:SpecialInstructions": "M André Z Eckenrode <instructions>", "IPTC:ObjectName": "Prefix; M André Z Eckenrode <title>; Suffix", "IPTC:Keywords": ["Andre","Eckenrode","©","Éé"], "IPTC:ApplicationRecordVersion": 4 }]We get
4occurrences :-
Line
4, right before the stringM André Z Eckenrode -
Line
11, right before the stringM André Z Eckenrode -
Line
12, right before the stringÉé <software>" -
Line
13, right before the string© 2020 M André Z Eckenrode
Best Regards,
guy038
- Open the Mark dialog (
-
@guy038 said in File display using multiple fonts simultaneously?:
Did you know that it’s very easy to spot invisible characters with the Mark feature ?
I did not, and thanks much for pointing it out. I just tried it, and it worked well, although I prefer the PythonScript solution referred to here overall, since it lets me see what the different characters are.
But @Peterjones & @Alan-Kilborn: It seemed that the script
SetRepresentationForSpecialCharacters.pydid not actively show the extra invisible characters until I toggledShow All Charactersfrom the menu, which is fine by me, but after I toggled it a second time, the extra characters remain visible. Is there a way to turn that off? -
The script, as written in that other thread, does not have any interaction with
Show All Characters. Perhaps it was a coincidence; you just thought that was what you saw happen?Here’s how that script works:
It is installed at startup time.
Every time you switch the active tab in N++, the resident part of the script runs and makes the non-viewable characters seeable.
It has to do this because N++ itself resets this behavior with every tab change and makes those characters unseeable again – just a quirk in its behavior. So then the script logic comes along and “fixes” it after the fact.The script is NOT intended to be run multiple times, say, in order to toggle the feature on/off. If this is desired, we can tweak the script, but for my purposes (after all, I wrote the script for ME!) I always want to see the unseeable.
Another possibility is to make the script only do its special thing for certain tabs.
I’m not opposed to doing further work on the script, for the benefit of others, but said others will have to let me know what they really want as far as features for it. :-)
-
@Alan-Kilborn said in File display using multiple fonts simultaneously?:
The script, as written in that other thread, does not have any interaction with Show All Characters.
Or maybe there is an interaction, due to the nature of the script having to reconfigure the tab to bring back the special representation of certain characters…
If so, I’d say:
Set N++'s View menu > Show Symbol to the setting you want. Switch to a tab you don’t care about, then switch back to your tab of interest. That should have N++ showing the whitespace/end-of-line characters per your preference, then the script will show you the normally invisible.
I’d say this is only a concern when you want to change N++'s Show Symbol setting.
Just remember that N++ has its own idea about what its choice of Show All Characters means, and it has nothing to do with the script.
Note: I think Show All Characters is bad UI text, because of what it implies. It should really be something like “Show spaces and tabs and line-endings”.
-
@M-Andre-Z-Eckenrode said in File display using multiple fonts simultaneously?:
… did not actively show the extra invisible characters until …
As @Alan-Kilborn said, I don’t think it suddenly appearing after toggling that particular setting had anything to do with that particular setting.
My theory: you needed to force Notepad++ to redraw the current window, and toggling the Notepad+±controlled character visibility is one such way. I know in the past, I had the setRepresentation and similar commands seemingly not work because of that.
It might help to add something like,
p = editor.getCurrentPos() editor.addText(u'Z\uFEFFZ') editor.deleteRange(p, editor.getCurrentPos() - p)to the end of the script, which adds the character (and some others) then immediately deletes them, which might trigger the redraw.
Or maybe use
notepad.new() notepad.close()which will create a new tab with a new file, then immediately close it… which should force a redraw on the active window that has the special characters
-
I think the script is OK the way it is.
I tested having the script active and changing the View > Show symbol options to various selections.
I always saw things shown that corresponded to the menu items as well as the special representations the script is doing.
Thus, I don’t know what happened for the OP, but for me at least everything is fine the way it is. -
Yes, it usually does work right. I’ve just seen rare occasions when setRepresentation or other such code didn’t immediately update in the display, where forcing a re-draw then makes it look right. I have a feeling that this strange outlier situation is the circumstance the OP has found himself in.
In my day job of programming finicky electronic systems to do specific things, I have found (more often than I like) that even though I’m doing everything I should have to do, it doesn’t start behaving the way I expect it to until I “kick it” with something that shouldn’t matter (akin to my recommendation of opening and closing a new tab), so this is a debug/kluge technique that is now in my toolbox, even in non-physical programming.
-
The script is NOT intended to be run multiple times, say, in order to toggle the feature on/off. If this is desired, we can tweak the script
I wouldn’t mind seeing such a feature, but it’s fine without it. I’d sooner have it also reveal the following code points when the encoding is ANSI/cp1252, which I actually use more often than Unicode:
129,141,143,144,157= All undefined in NPP’s character panel, and everywhere else I’ve consulted.160= Non-breaking spacePerhaps it was a coincidence; you just thought that was what you saw happen?
Maybe, but I’m not worried about it enough to investigate.
I think Show All Characters is bad UI text, because of what it implies
I agree, and have thought the same thing.
One email correspondent of mine often sends messages that have ASCII non-breaking spaces in them, which he claims to have no idea why they’re in there, but it trips me up when editing quoted text in my replies, as I often use Ctrl-Left Arrow and Ctrl-Right Arrow to navigate horizontally, and it ends up skipping over multiple words that are only separated by NBS.
It might help to add something like,
Or maybe useI’ll keep them in mind, thanks. It’s actually not that big of a deal.
-
@PeterJones wrote:
It seems to be a bug only in Windows 7, so it’s probably to do with Windows 7 font-handling for Unicode.
It’s now 2024, and I just had this problem happen for me while using Windows 11.
So, it’s definitely not a problem with “Windows 7 font-handling for Unicode”. And I don’t believe it is a Windows problem at all…
Since it’s dependent on the version of Windows, rather than Notepad++, there’s probably not much we can do.
I (somehow) had an invisible character in my text which I copied from another Windows app into NPP. It did not cause problems with the font-handling in the other app, nor in regular Windows Notepad, nor even in Google Docs.
It only causes a problem in NPP. Also, I find it odd that Show Symbol > Show All Characters does not reveal that this character is there. Even more disturbing is the following:
-
When I change the Default Style (Settings > Style Configurator) font size to 20, a different set of characters is rendered in the odd font (always including the invisible character).
-
Using Show Symbol > Show All Characters, I see an orange dot as a representation for each space, but for several spaces surrounding the invisible character, the orange dot is misplaced, overwriting some other character. The number of spaces which have this problem, and the amount of the displacement, are dependent on the font size.
So I conclude that all of this odd behavior is due to some problem in NPP.
-
-
And…you’re going to say all of that…and then not say what this “invisible character” actually is?
I find that incredible. -
@Todd-Hoatson-0 said in File display using multiple fonts simultaneously?:
@PeterJones wrote:
It seems to be a bug only in Windows 7, so it’s probably to do with Windows 7 font-handling for Unicode.
It’s now 2024, and I just had this problem happen for me while using Windows 11.
So, it’s definitely not a problem with “Windows 7 font-handling for Unicode”. And I don’t believe it is a Windows problem at all…
It also happens when the font that you have chosen does not contain the appropriate glyphs, and Windows OS (not Notepad++) substitutes a glyph from a different font. (Update: but, unlike the problem from four years ago, it only affects that glyph, not a whole group of glyphs thereafter. The problem that was described four years ago really was Win7-dependent.)
It would have been nice if you’d shown a screenshot , so we could know what the problem you are describing manifests as. (Update 2: and, as Alan suggested, telling us what character was causing the problem. I was originally going to give you the benefit of the doubt, that you didn’t know how to figure out the character… but rereading the original discussion above, four years ago, I described how to use the Plugins > MIME Tools > URL Encode to reveal the codes behind even invisible characters. So you could have done at least that much.)
I (somehow) had an invisible character in my text which I copied from another Windows app into NPP. It did not cause problems with the font-handling in the other app, nor in regular Windows Notepad, nor even in Google Docs.
It only causes a problem in NPP. Also, I find it odd that Show Symbol > Show All Characters does not reveal that this character is there.
And what version of Notepad++ are you using? Because newer Notepad++ have more options in that menu, and Show All Characters (by enabling all those options) does a better job than it used to. If your Show Symbol menu doesn’t look like this screenshot, you should update Notepad++:
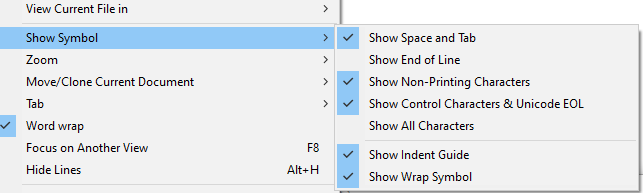
The Show Non-Printing Characters option is the one that will show alternatives for Zero Width characters and most invisible characters, like the
U+2060 WORD JOINERorU+200B ZERO WIDTH SPACE.on 
off 
… and you don’t need all of Show All Characters; as you can see by my screenshot, I tend to turn them all on except End of Line, so that way I don’t get pestered by the CRLF most of the time (I sometimes turn it on when I’m having newline difficulties, or showing someone here something about their newlines, but then turn it back off). But I love that newer Notepad++ allows me to show the special characters for the zero-width and joiner characters, because those are often characters you get from copy/pasting from other apps.
-
When I change the Default Style (Settings > Style Configurator) font size to 20, a different set of characters is rendered in the odd font (always including the invisible character).
-
Using Show Symbol > Show All Characters, I see an orange dot as a representation for each space, but for several spaces surrounding the invisible character, the orange dot is misplaced, overwriting some other character. The number of spaces which have this problem, and the amount of the displacement, are dependent on the font size.
Again, A screenshot would help you explain those better. But if I understand correctly, it sounds like you’ve found some Unicode character which wants to join the previous and next character together (which can be used for the modifying accents, or for giving skin tone options to emojis, and similar).
So I conclude that all of this odd behavior is due to some problem in NPP.
That might be. For some problems, Direct Write needs to be turned on; for others, it needs to be turned off; and for some combos of problems, neither option is sufficient. But I think that Show Non-Printing Characters in a recent Notepad++ will help you better diagnose your problem.
(You might also need to turn on Settings > Preferences > Editing 2 > Non-Printing Characters > ☑ Apply Appearance Settings to C0, C1, & Unicode EOL (which makes sure it works for ASCII control characters and for the “Unicode EOL” like LS and PS – the characters described in this screenshot from Wikipedia’s Newline#Unicode:

-
-
@Todd-Hoatson-0 said in File display using multiple fonts simultaneously?:
Also, I find it odd that Show Symbol > Show All Characters does not reveal that this character is there
It depends on the character. Unicode has quite a few characters, such as in the Combining Diacritical Marks block, that will cause odd shifts much like the " the orange dot is misplaced, overwriting some other character" that you are seeing.
Notepad++'s “show all characters” feature enables display of what are known as the non-printing characters. The Combining Diacritical Marks and other Unicode characters that cause display changes are defined as “printing characters” and so are not included in the list of things that become visible with Notepad++'s show all characters.
When need a true “show all characters” then I do a hex dump of the file. As you seem to have a good idea of where the strange stuff is in your file you can copy/paste just that fragment into a hex dump utility. I see there are on-line hex dumps. There are also on-line UTF-8 decoders that may highlight the unusual or invisible characters you are dealing with.