Another encoding issue
-
So, encoding has been a theme here recently in the Community.
Or, maybe it is just me bringing it up all the time. :-)
I’m not even working with obscure encodings, just UTF-8 (no BOM).Here’s the latest:
Confirm my encoding setting:

I had some text I was working on, which contained this UTF-8 character ➤ :
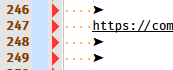
And I used the arrow key to caret up from the
httpline so that I could put some text after the “right arrow” on the line above, and what I was seeing changed to: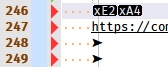
I can’t say for sure much more than that.
I could undo to get the original text back for the screenshot, but I couldn’t say what my actions were before this happened.
Meaning, I don’t know what position I was on on line 247 when I pressed up-arrow and got the weirdness.
(And no matter what I’ve tried, I can’t reproduce it.)But, I know that the “x” position on a line is retained sometimes so that when a move up or down is made, the x position can be maintained. Perhaps in this case this somehow caused the caret to end up in the middle of the UTF-8 character?
This is with 7.9, BTW.
-
Not sure. I cannot get anything like that to happen.
Even in this example:
➤ x ➤ https://com ➤ ➤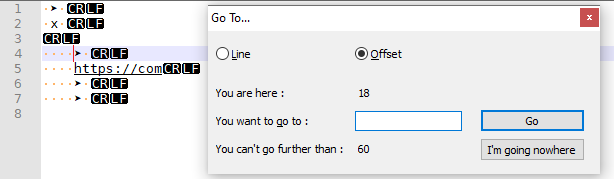
… where the cursor is at offset 18, shown in red: if I try to go to offset 19,20, or 21, it places the cursor after the➤(those are the three byte offsets for the UTF8 encoding of that character), and 22 places it after the space.So I don’t know how you convinced it to break that character apart. Also, ➤ is U+27A4, so it’s three bytes should be 0xE2, 0x9E, 0xA4… so your screenshot shows that it took the two outer bytes, but the central byte is apparently missing.
Ooh, that gave me a hint: in my example, if I go to offset 19 then hit DEL, it changed to
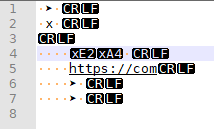
So I am guessing what happened is that you somehow got it to the central offset in the multi-byte character and deleted it – though for me, UNDO works to fix that. So maybe you triggered a script which deleted the byte from the character but plays with the UNDO history so UNDO didn’t work.
-
So first, thanks for your thoughts and your experimentation.
maybe you triggered a script which deleted the byte from the character
I suppose this IS possible, although I don’t have any scripts that do any deleting when I’m just careting around. :-)
It seems like even scripts should be somewhat insulated from getting into the middle of multibyte characters. Sure, it should be possible for those that need it (not me), but I pretty much always want to deal with things at a character level. So such a thing should be “difficult” to have happen, if truly caused by a script.
But, alas, I don’t have more data on this, so that’s the end of conclusions.
Regarding “character level”, it is a bit disturbing to me that Notepad++ allows the user to jump to an offset right in the middle of a multibyte character. Again, I would expect to be restricted to the character level by this.
-
Hello, @alan-kilborn, @peterjones and All,
So I created a new issue about this disturbing behavior ;-))
Best regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login