Functions list comment bug
-
I should have mentioned the language, my bad; it’s JavaScript. This issue doesn’t occur in PHP files though at least. I’d rather not gunk up my code because of editor bugs, I’ve had to do this ever since I started using editors and I’m tired of it. Don’t get me wrong, I’ve seen the code that handles code and that isn’t (at least) my idea of weekend fun. On the bright side Notepad++ is only using ~38MB of RAM, I’ve used an editor in the past that literally gobbled up over a GB…for editing code!
-
@Michael-Vincent said in Functions list comment bug:
This is known
Is this an overwhelmingly hard one to fix?
I recall that this one provokes these types of inquiries every so often.
I presume you’ve had some sort of look into it. -
@Alan-Kilborn said in Functions list comment bug:
I presume you’ve had some sort of look into it.
No, I’m only repeating what I’ve been told. Probably should have linked that in my first post.
Cheers.
-
If it only required one space between the
{and the//, I would be tempted to say “suck it up and deal”. I wouldn’t say it, but I would be tempted. 😉 But with requiring two spaces, that’s a bit much.I know that @MAPJe71 knew about the problem, and thus it’s technically known, but the FAQ entry didn’t link to an issue…
Trying to search through, it appears that #3685 and others that are linked to that one all describe at least part of the problem. I’m not sure that any of them list both the conditions that @MAPJe71 put into the FAQ – and in fact, one of his comments implies that a single space was sufficient between the
{and//in v7.6.3 – but in the FAQ and my experiments in v7.9.1, there are definitely still two spaces required: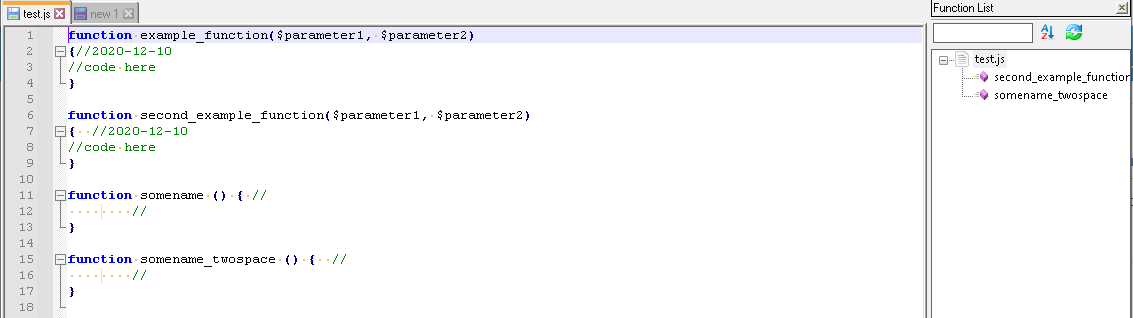
And, my initial joking aside, telling people to “just suck it up and deal”, when maybe their corporate style guide requires zero spaces between the opening
{and the comment showing the date (or whatever other comment the style guide requires), doesn’t seem like a good idea. Even if it’s not a corporate mandate, forcing people to change their coding style to accommodate a quirk (bug) in an editor seems rather the wrong way around.(With a single space, I can understand the coding argument inside the application: “it’s harder to distinguish between a single-unit
{//and{ //, when my parser was already written to require a boundary of some sort between tokens”. But to require two whitespace between the brace and the comment is going a bit far.)@MAPJe71 , do you have any insight into the code, as to why it’s requiring two spaces. I saw that in some of the comments in the issues, you had mentioned it was caused by an offset in the function list search code. But a single offset doesn’t jive with what you say in the FAQ, and what my v7.9.1 screenshot just showed: that for brace-to-comment, there have to be two spaces, not just one. If you have insight into the code that does that parsing, does it look like it’s a solvable problem? Or are we going to be stuck with it for all eternity? If it looks solvable, is there a way we could post a suggestion for how to solve it in one (or more) of those open issues, and see if we can get some traction on getting that fixed?
I’m at least posting a bump on #3685 .
-
Perhaps it is worth considering the option of using the ctags output (https://ru.wikipedia.org/wiki/Ctags) to build a list of functions, as I did in the project https://github.com/trdm/jn-npp-scripts
I have been parsing texts for several years and I know that regular expressions have their limitations.
True, I have not yet mastered the full power of boost RegEx and cannot judge their effectiveness. -
Oops …
ctags is not very efficient.
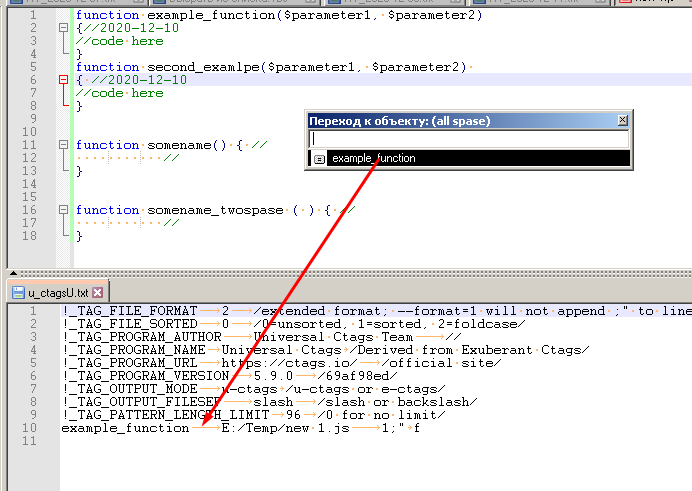
It’s good that there is a fallback :)
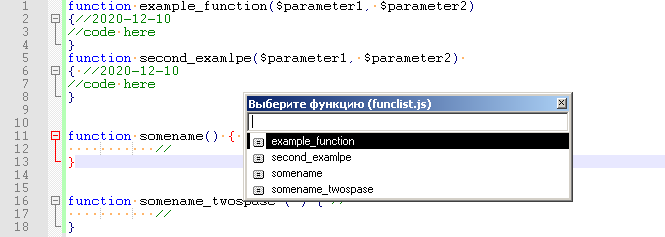
-
We encountered an official build of PHP that was absolutely wretched. We can understand if someone forgot something like cURL but the build was missing numerous critical functions, including MySQLi!
Because of that terrible build we implemented a scanner function (just for Administrators on a particular page) that literally combs through all of the PHP source code to determine all of the function names. Now when we test a new version PHP we run that particular page to ensure that build of PHP was created competently before deploying to our live environments. We didn’t construct it using regular expressions.
So from our perspective why does it have to use regular expressions? Not that Notepad++ is by any means sluggish though regex just seems pointlessly convoluted to maintain past a point and from all of the pages we’ve encountered talking about regex a very few ever seem to work flawlessly past a rough length of complexity.
-
@jabcreations said in Functions list comment bug:
why does it have to use regular expressions
It presumably doesn’t have to; it just does. I don’t actually know what Function List uses under the hood which added the offset (for the offset thing, I’m just repeating what has been said elsewhere) – so I don’t know whether internally, it uses regex or character-based parsing; and for the recognition of the classes and function names, to be user-configurable, regex still seems the most accessible option.
But doing a complete rewrite of the Function List, so that it doesn’t use regex either for the internal parsing or for the user-configurable function-and-class recognition – that would be a huge rewrite that is not likely to happen.
-
@PeterJones I understand the lack of desire to rewrite though is the regex at least per language or is it some suicidal everything-must-be-the-same madness? I’m all for reusable code (ours is very dynamic) though there are limits, human limits.
-
@jabcreations said in Functions list comment bug:
is the regex at least per language or is it some suicidal everything-must-be-the-same madness?
Have a look for yourself …
-
-
@jabcreations said in Functions list comment bug:
@PeterJones I understand the lack of desire to rewrite though is the regex at least per language or is it some suicidal everything-must-be-the-same madness? I’m all for reusable code (ours is very dynamic) though there are limits, human limits.
In terms of the user-configurable regex, it’s per language. I don’t know about the internals, but it’s presumably the same wrapper for every language on the inside, and just makes use of the user-configurable regex per-language. But the code that @Michael-Vincent pointed you to is the only way to know for sure (and I’ve never looked at it)
