Search in folder (encoding)
-
Hi @mayson-kword and All,
Sorry, in my previous post I said :
МиÑтиin your configuration asANSIrepresents really theWindows-1251encoding
Мисти, with my configuration asANSIrepresents really theWindows-1252encoding
In fact, the correct phrasing is the opposite :
-
МиÑтиin my configuration asANSIrepresents really theWindows-1252encoding -
Мисти, with your configuration asANSIrepresents really theWindows-1251encoding
Note that I also modified my previous post to be exact !
BR
guy038
-
@guy038, converting file to ANSI works for my search, but it’s not a solution.
- As I said in my first post, I have a lot of files - 3222 (in all sub-folders) at this moment. I can’t open them all and convert to ANSI, then edit, then convert back to UTF8 (because I need them in UTF8).
- Even if I had few files converting them to UTF8 and back to ANSI is not a solution because the result is not equal to original file. See the image. I need no such structure changes because theese files will be put in a specific archive and used in game. Ah, it’s all very fragile.
Some users can fix this problem, of course. Convert file to ANSI and back to UTF8 / remove problematic symbols / open all files in current session. But I can’t do such thing because converting and such editing changes my files too much, also there are too many files to open them all.
Look at this post once again. The difference between case 2 and case 3 is only one “NUL” symbol - and it makes N++ not be able to find anything I want. I can provide more files to compare. Search works wierd if file contains wrong data - Pic 1 and Pic 2.
-
@Mayson-Kword said in Search in folder (encoding):
Even if I had few files converting them to UTF8 and back to ANSI is not a solution
Sorry for mistake.
I mean “Even if I had few files converting them to ANSI and back to UTF8 is not a solution”.
Can’t edit post after 3 minutes. -
What did you mean by:
Also plugin AutoCodepage was my try to solve this problem, but it didn’t help. However, it works pretty nice when I open files
Do you have problems detecting encoding in general? If so there is no reason to expect search to work for non-ascii strings.
Try saving as UTF8 with BOM. The BOM makes detection of UTF8 files explicit. -
@gstavi said in Search in folder (encoding):
Do you have problems detecting encoding in general?
Yes and no, it only happens with some rare files if I don’t use “autodetect character encoding” feature. Sometimes even with it on. In that case N++ open them using ANSI, so I can’t read anything and I need to select encoding manually. AutoCodepage with my own rules just do this work automatically instead of me.
However there is an idea in your words. After some investigations I can suggest that N++ can’t search as expected in file using “Find in files” if file is not currently opened and if N++ can’t autodetect its encoding. Am I right?
Also using UTF8 with BOM solves this problem in a best way, I think. No data loss at least. Is there any way to automatically convert thousands of files from UTF8 w/o BOM to UTF8 with BOM?
-
Adding BOM is not conversion it is just adding 3 bytes (for utf-8 bom) at the beginning of the file.
https://stackoverflow.com/questions/3127436/adding-bom-to-utf-8-filesThe 2 risks are:
- Adding BOM into already “BOMed” file.
- Adding UTF-8 BOM into file with another encoding (e.g. UCS-2).
I never needed to use AutoCodepage and don’t know what hook from Notepad++ it uses to apply its functionality but maybe either its author or Notepad++ main developers can “fix” the problem by ensuring that it is called during search as well.
-
Ok, using files with BOM solves my problem because I can easily check files for BOM and change them if needed using Python scripting. However, N++ still doesn’t search properly in closed file if fails to autodetect its encoding.
Thank you all for your participation, that’s all.
-
Hi @mayson-kword and All,
I was able to download your
txt.ziparchive and correctly extract your two filesexample file 01.txtandexample file 02.txtWith these two files opened in N++
v7.9.2, I got two occurrences of the stringони должныsearching in all opened tabs of the current session. So, I could not, again reproduce the issue !After a while, I realized that, for a correct search, you need to tick the option
Settings > Preferences > MISC. > Autodetect character encodingIf this option is not checked, the string
они должныis found in the fileexample file 02.txtonly, which does not contains an ending\x00, whatever the files are opened or not in current N++ session
- When this option is enabled, and the two files opened in current session, a click on the
Find All in All Opened Documents, of theFinddialog, produces :
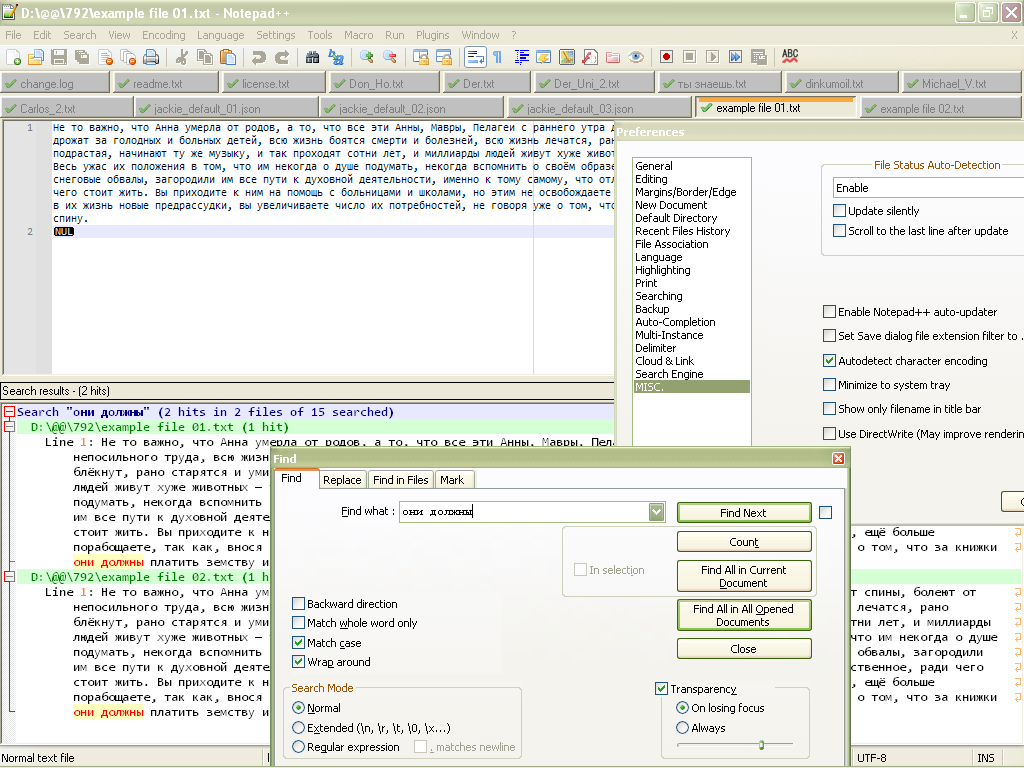
- When this option is enabled, and your two files not opened, a click on the
Find Allbutton, of theFind in Filesdialog, produces :
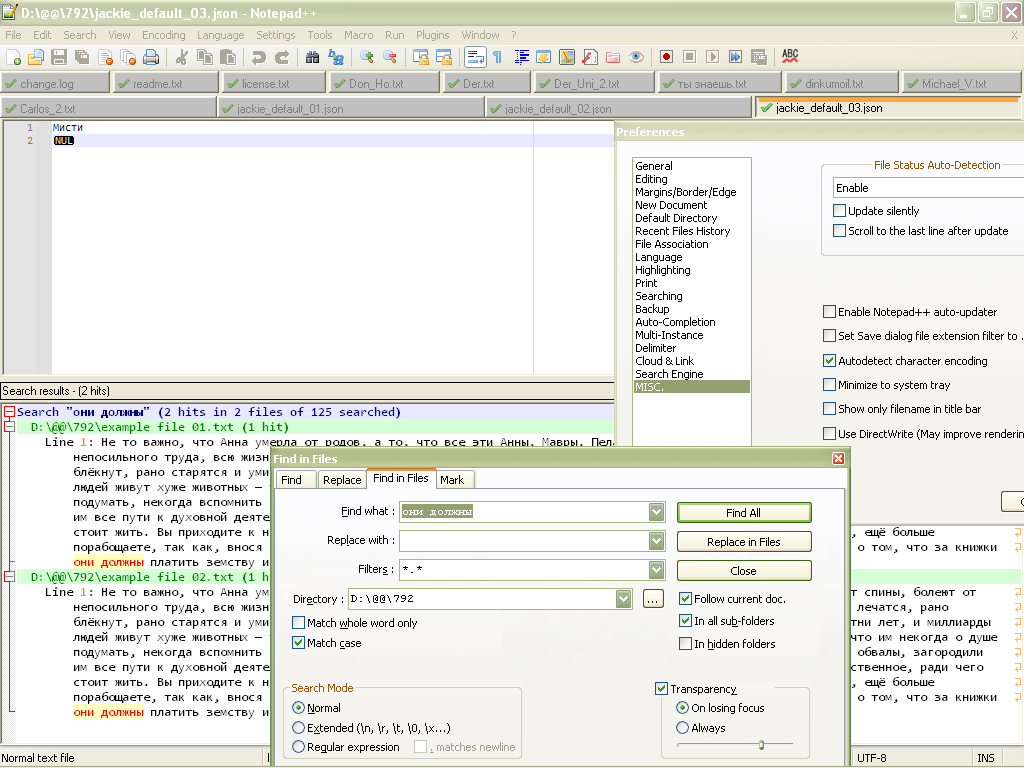
Now, about the possibility of changing an
UTF-8to anUTF-8-BOMencoded file, this is very easy, from withinNotepad++-
Open the Find in Files dialog (
Ctrl + Shift + F) -
SEARCH
\A -
REPLACE
\x{FEFF} -
Select the
Regular expressionsearch mode -
Select the folder containing all your
UTF-8files which have to be modified -
Select the appropriate files filter
-
Click on the
Replace Allbutton and confirm the dialog
Voilà !
If you want, first, to test this technique :
-
Open an
UTF-8file ( In the status bar, you should seeUTF-8( and notUTF-8-BOM) -
Open the Replace dialog (
Ctrl + H) -
Tick the
Wrap aroundversion -
Select the
Regular expressionsearch mode -
Click, ONCE only, on the Replace All button ( Do not click, previously, on the
Find Nextbutton or any other button ! )
=> Message
Replace All: 1 occurrence was replaced in entire file-
Save, immediately, the modifications with
Ctrl + S( Just note that it still mentions theUTF-8encoding, in the status bar ) -
Close this file (
Ctrl + W) -
Re-open the file (
Ctrl + Shift + T)
=> In the status bar, we can verify, this time, the indication
UTF-8-BOM, which proves that we are dealing, now, with a real UTF-8 file with aBOM.Best Regards
guy038
- When this option is enabled, and the two files opened in current session, a click on the
-
@guy038 said in Search in folder (encoding):
about the possibility of changing an UTF-8 to an UTF-8-BOM encoded file, this is very easy, from within Notepad++
One thing to note about this is that it is a one-way operation.
You can’t go the other way (UTF-8-BOM —> UTF-8) using a similar technique (a N++ replacement).
@guy038, am I right about it? -
Hi, @alan-kilborn,
Totally exact, Alan. Indeed, the
BOMstructure is not considered as part of file contents by Notepad++ !Note also, that I found out a bug, relative to the
\Aassertion, while testing my method to add theBOMwith a regex S/RLet me some minutes to expose the problem and you tell me if I must create an issue for such a behaviour !
BR
guy038
-
Hi, @alan-kilborn and All,
Sorry for the wait, I need to eat a little bit !
Alan, I think that you already spoke about a similar behaviour, but I cannot remember the exact post
Just follow all these steps to see the issue !
-
Open a new tab (
Ctrl + N) -
Type the three letters
bar, only -
Save this new tab as
Test.txt -
Open the
Replacedialog (Ctrl + H) -
SEARCH
\A -
REPLACE
foo -
Tick on the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click on the
Replace Allbutton
=> As expected, the file contents are changed into the string
foobar!Now :
-
Undo the modifications (
Ctrl + Z) -
Re-open the
Replacedialog (Ctrl + H) -
SEARCH
\A( Verify that text is indeed\A) -
REPLACE
foo -
Tick on the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click, first, on the
Find Nextbutton ( Important )
=> The classical call tip appears, saying
zero length match- Now, click on the
Replace Allbutton
=> This time, no replacement occurs, even of you click, again, on the
Replace Allbutton- Even if you switch to an other tab and switch back to the
Test.txtfile
=> The same regex S/R, as above, with, only, a click on the
Replace Allbutton does not work anymore ! And you always get the messageReplace All: 0 occurrences were replaced in entire file
-
In order to get the expected behaviour, you must :
-
Close this file (
Ctrl + W) -
Re-open the Test.txt file (
Ctrl + Shift + T)
or
- Close and re-start Notepad++, of course !
After these operations, a click on the
Replace Allbutton is, again, functional and do add the stringfoo, right before the stringbar!
Here is my debug -info :
Notepad++ v7.9.2 (32-bit) Build time : Dec 31 2020 - 03:58:36 Path : D:\@@\792\notepad++.exe Admin mode : OFF Local Conf mode : ON OS Name : Microsoft Windows XP (32-bit) OS Build : 2600.0 Current ANSI codepage : 1252 Plugins : DSpellCheck.dll mimeTools.dll NppConverter.dll NppExport.dllBest Regards
guy038
-
-
I can reproduce that ; nice instructions!
You should open a real issue on that.
It’s a weird one.
I thought it might have something to do with the call-tip being active, but no, it doesn’t seem to have any bearing on it.Allan, I think that you already spoke about a similar behaviour, but I cannot remember the exact post
I don’t remember this at all, but at my advanced age…
I’m sure you could find the post, point me to it, and it would be like a stranger had written it. :-) -
You cannot reproduce the issue because N++ autodetect encoding properly for most of files if using feature “Autodetect character encoding”. But there are some files that N++ cannot interpret right even with this option on. My file “jackie_default_01.json” is one of them. Also 3221 more files are one of them.
In case if you didn’t see my words, I can repeat myself from this post. N++ doesn’t search properly in closed file if fails to autodetect its encoding. Maybe I should repeat this once more in a different way? Conditions to reproduce the issue are:
- File is not opened.
- N++ cannot autodetect its encoding.
You said “I could not, again reproduce the issue” just because you don’t meet the second condition.
-
Hello, @alan-kilborn and All,
Ah, here we are, I found out this related post :
https://community.notepad-plus-plus.org/topic/19456/regex-replace-doesn-t-work/4
Remember : At this time ( May 2020 ), @uhf7 still did not change the behaviour of the
look_behindstructures. This was done in October and functional with theV7.9.1version !https://github.com/notepad-plus-plus/notepad-plus-plus/pull/9008
So, in the log text, below, the OP wanted to change the
_between date and time, with a single space character2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Power: 0 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Voltage: 268 2020-01-01_00:02:13 MQTT2_DVES_834483 Time: 2020-01-01T01:02:12 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_ApparentPower: 0 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Today: 0.000 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Current: 0.000 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_ReactivePower: 0 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Factor: 0.00 2020-01-01_00:02:13 MQTT2_DVES_834483 ENERGY_Period: 0And the OP asked why the following regex
(?<=\d)_(?=\d)did not work when using the Replace button, onlyLuckily, since the
v7.9.1version you can, first, get the first match with a click on theFind Nextbutton, then hit, repeatedly, theReplacebutton to do one replacement at a time. Many thanks @Uhf7 for this improvement ;-))
So, Alan, I thought that the behaviour of the
\Aassertion was related to the search buffer. Indeed, as soon as the zero length match, standing for the very beginning of current file, is matched, by a click on theFind Nextbutton, it’s just as if the regex engine has forgotten everything about the current position, which should be found because of theWrap aroundoption which loops the search from the end to the start of current file !?As it’s about midnight, in France, I’ll create a GitHub issue tomorrow !
BR
guy038
-
Here is my video with the issue. https://www.youtube.com/watch?v=RSQpqvL6cHI
-
I am sorry to be the bearer of bad news: The file you are showing in that video does not appear to be a text file.
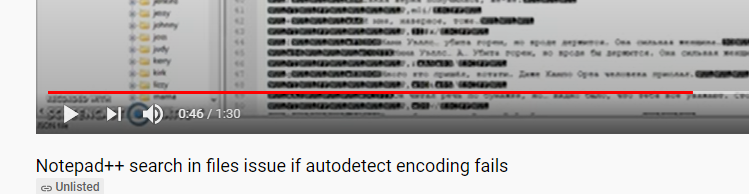
With all those black-boxed characters, it appears to be a binary file that happens to have some of its information look like text. Notepad++ cannot be expected to handle any arbitrary binary data that you throw at it, whether or not that binary data happens to contain some number of text strings. The non-text bytes interfere with its ability to do the job Notepad++ was designed to do: edit text. In some situations, you might be able to abuse the application to edit the text included in the binary file, but you have pushed beyond that.
Just because something can be loaded in Notepad++, and even just because you can read some of the text from that file in Notepad++, does not mean that the underlying file is actually a plaintext file. For example, when I look at
notepad++.exein Notepad++, I can find areas that look quite similar to what is shown in your video:
 – it’s got plain text, that I can absolutely read, and be confident that it was intended to be text… but that’s really an excerpt of bytes from an executable file, not from a text file.
– it’s got plain text, that I can absolutely read, and be confident that it was intended to be text… but that’s really an excerpt of bytes from an executable file, not from a text file.Expecting a meaningful search or search-and-replace result when using a text editor to edit non-text files is a rather unfair expectation, in my opinion.
see also this faq
You said “I could not, again reproduce the issue” just because you don’t meet the second condition.
Guy was showing results from the files you provided! Don’t complain to him for not meeting your condition when you supplied the file.
Getting back to my main point: while the video you showed does not appear to be a plain text file, the screenshots Guy showed of your example files does appear to be text. (I don’t download arbitrary zip files from users I don’t already trust, so I cannot verify myself that they are nothing more than plain text). But, if they really are text like it appears, then it is more reasonable to expect Notepad++ to be able to handle them.
In that case, if you wanted to share files that show the problem you are encountering, then share those, and maybe Guy or some other brave soul will download an arbitrary .zip and try to replicate your problem. If you believe that one or both of the files from that already-shared zip do show the problem, then Guy’s assessment disagrees with you, and you’ll have to explain again exactly how to replicate the problem with the files you shared.
-
@PeterJones, got it. If my files are not text files, so N++ cannot understand them properly and then there is no issue at all. Thank you, my apologies for being rude. But also I want to mention that I really provided problem file - “jackie_default_01.json” from “json.zip” archive. It’s equal to file in video. So your words “if you wanted to share files that show the problem you are encountering, then share those” sounds strange. Guy’s assessment disagrees with me because Guy ignores “jackie_default_01.json” file for some reason.
-
Ah, if you think only one file is not enough, here 5 more files for any brave soul.
-
Hi, @mayson-kword @peterjones, @alan-kilborn and All,
I did some tests and I draw these conclusions :
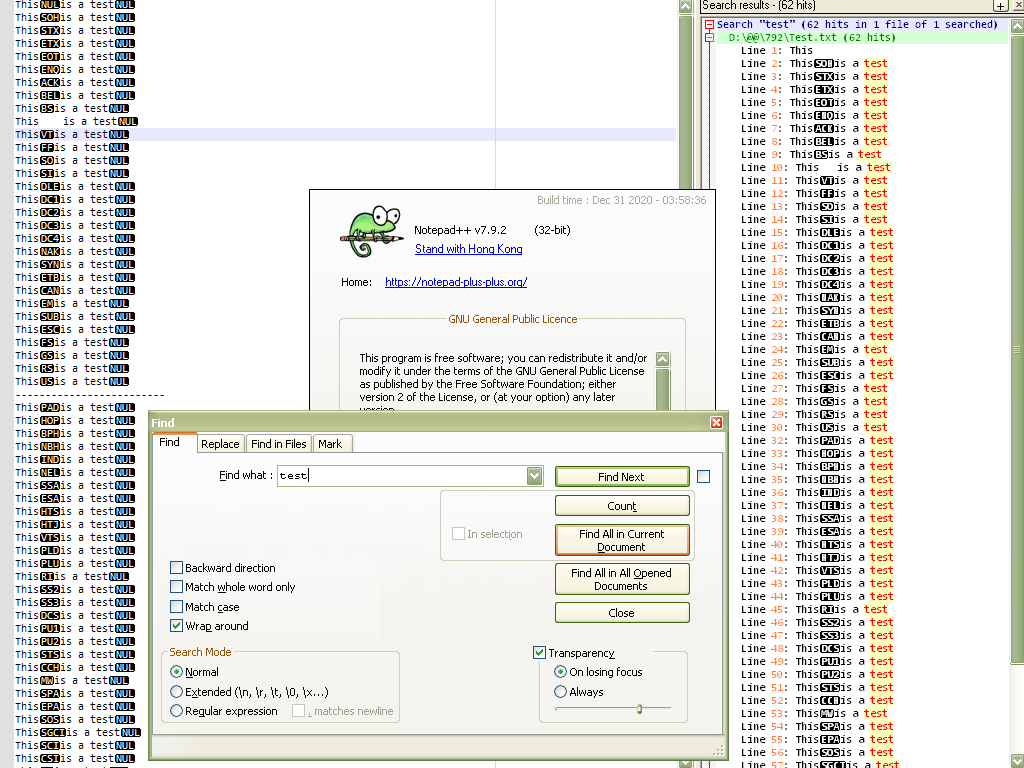
For a non pure text file, which can contain many control codes, in reverse video, including the
NULcharacter :-
Any line ends with either the first Windows
CRLF, the UnixLFor the MACCRcontrol code(s) -
In the
Findresult panel, anycontrol C1orControl C2character, except for theNUL, theLFand theCRcharacters are simply displayed as standard characters -
In the
Findresult panel, any line containing the search string is displayed till the firstNULchar met -
Thus, if any line, as defined above, just begins with a
NULcharacter, nothing is displayed, although it did find the search string for that line !
Demonstration :
I also verified that this behaviour occurs with
ANSIor anyUNICODEencoding and does not depend on the type ofEOLcharacters, too !So, @mayson-kword, unless you decide to work on a copy of your non-text files, in order to delete all the
\x00characters, it’s seems impossible to correctly get all the lines in theFind resultwindow :-((Best regards
guy038
-
-
@guy038, thank you a lot. There is no way to improve autodetect encoding feature, but you’ve done as much as possible, including advice to use BOM, that solves my issue very well.
Have a nice day, all of you are great.
{kind=link}
{kind=link}
{kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login