Replacing a digit with exception
-
@guy038 merci.
I’m going to read this carefully.
Actually I have to change your following code (?-s)($|\G)[[:xdigit:]]*?\K2 because it does not work if there are already digits in the 8 characteres strings : the search is going to the next line each time it encounters a letter, even if it didn’t red the entire string.
I have to scratch my head a little bit to try to find a solution, I’ll tell you if I find a solution :) -
@jean-francois-trehard and All,
I don’t understand ! In the picture showing the text, below, I added some pure hexadecimal characters, either, in lower or upper case, in many locations, even after the
; Tile #string. Seemingly, all2digits, before comments only, are correctly marked !?dc.l $02A20620 ; Tile #42 dc.l $0BaC2021 dc.l $55111003 ; Tile #9A56 dc.l $55001111 dc.l $54000116 ; Tile #1b628 dc.l $dF022222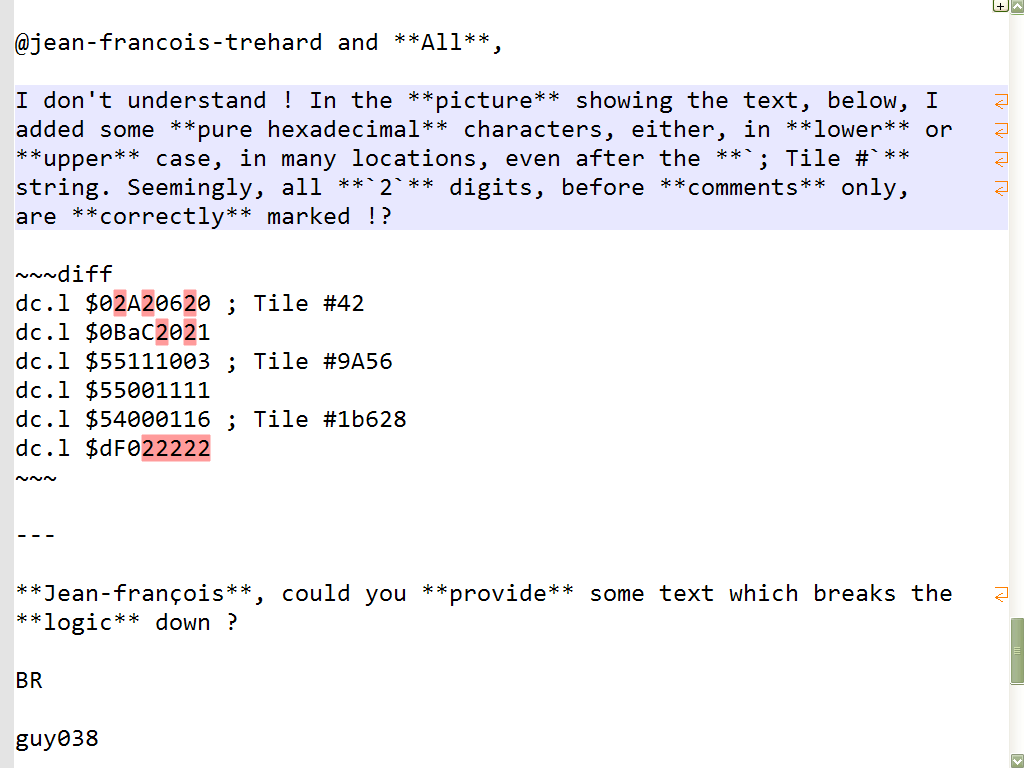
Jean-françois, could you provide some text which breaks the logic down ?
BR
guy038
-
@guy038 oh I wrote something wrong :
“because it does not work if there are already digits in the 8 characteres strings”
I meant this : “because it does not work if there are already letters in the 8 characters strings” -
@jean-francois-trehard and All,
Ah OK, I understood the problem. Actually, you meant that, once an S/R has been processed to replace, for instance, a
2digit with theQletter, a second search, for instance, of the6digit will not find all occurrences of the6digit, because the letterQis not an hexadecimal number !Indeed, the regex must be changed as below :
SEARCH
(\$|\G)\w*?\K2REPLACE
Q
BTW, note that we can, also, express the search regex, using the free-spacing mode
(?x), for a better readability :(?x) ( \$ | \G ) \w *? \K 2
Now, concerning the explanations, in my previous post, simply change any string “hexadecimal character” with the string “word character” !!
Cheers,
guy038
P.S.
I also think that my previous explanations need to be reread. I’ll see tomorrow !
-
That is awsome, thank you. This is very complex for a pure beginner.
Do you know if we can do multiple replacements at once in Notepad++ ?
Like replacing all my 0 with G, all my 1 with H, etc, in one “Replace all”.
I’m now checking it :) -
This is not working >
Find : (($|\G)\w*?\K0)|(($|\G)\w*?\K1)
Replace : (?1G)(?2H)If I have 01001110, then I get GH1GHGH111GH
-
@Jean-Francois-Trehard said in Replacing a digit with exception:
Do you know if we can do multiple replacements at once in Notepad++ ?
If you go with my regex, altered to cater for the different changes to be made you can do it ALL in 1 pass.
So the new regex is
Find What:(?-s)(;.*$)|(0)|(1)|(2)|(3)|(4)
Replace With:(?1\1)(?2G)(?3H)(?4I)(?5J)(?6K)This is just an example as you have not provided ALL the changes you want, but the idea is the same. My regex can be extended to cater for as many characters as you want changed in the one run.
Terry
-
@Terry-R said in Replacing a digit with exception:
(?1\1)(?2G)(?3H)(?4I)(?5J)(?6K)
Actually just thinking that you possibly need to change more than 9 groups (in total), the more correct coding would be:
(?{1}\1)(?{2}G)(?{3}H)(?{4}I)(?{5}J)(?{6}J)
So this allows for lots of groups to be identified. In your case you would be using …(?{10}X)(?{11}Y)(?{12}Z)as an example.Terry
-
Hi, @jean-francois-trehard, @terry-r and All,
No problem too. We can do miracles with regexes ;-))
This time :
-
We must use a non-capturing group at the very beginning of the regex
-
We must add a second non-capturing group to get the
\Kfeature for search of, either, the digits0,1or3, only -
We must add inner real groups in order that :
-
Group
1is defined when a0digit is matched -
Group
2is defined when a1digit is matched -
Group
3is defined when a2digit is matched
-
And the replacement zone is self-explanatory !
So, given this text :
dc.l $02A20620 ; Tile #42 dc.l $0BaC2021 dc.l $55111003 ; Tile #9A56 dc.l $55001111 dc.l $54000116 ; Tile #1b628 dc.l $dF022222The following regex S/R :
SEARCH
(?:\$|\G)\w*?\K(?:(0)|(1)|(2))REPLACE
(?1G)(?2H)(?3I)will output, in one pass, the expected text, leaving the comments untouched
dc.l $GIAIG6IG ; Tile #42 dc.l $GBaCIGIH dc.l $55HHHGG3 ; Tile #9A56 dc.l $55GGHHHH dc.l $54GGGHH6 ; Tile #1b628 dc.l $dFGIIIII
Again, if we use the
(?x)modifier for the free-spacing behavior, the search regex becomes :(?x) (?: \$ | \G ) \w *? \K (?: (0) | (1) | (2) )However, note that the replacement regex cannot be expressed with the free-spacing mode, but, for this specific replacement, the order of the
(?#<letter>blocks does not matter !So, the replacement regex
(?3I)(?2H)(?1G)would be correct, as well !BR
guy038
-
-
-
Hello, @jean-francois-trehard and All,
In wanting to explain, my regex S/R, provided in my previous post, I realized that we should add an hypothesis :
- You must move the caret to a blank line, located before the text to be processed by the S/R
So, let’s start with the last version :
SEARCH
(?:\$|\G)\w*?\K(?:(0)|(1)|(2))REPLACE
(?1G)(?2H)(?3I)
-
Globally, the regex
(?:\$|\G)\w*?\K(?:(0)|(1)|(2)), searches, from after a literal$symbol OR after the end of the previous search, if any, for the smallest range, even empty, of words characters, till a0,1or2digit, then only selects this last digit and replaces it, respectively, with theG,HorIletters -
Note that the
\Gassertion forces the regex engine to ask itself : does the current match attempt, immediately follows the previous match ? In case of a positive answer, the current match attempt is a possible match, so far ! -
As this regex only looks for consecutive words chars, it’s easy to understand why the characters, located, in the second part of a line, after the
#sign, are not concerned !
Now, if you’re still in the fog, let’s go into a little more detail and start the search, for instance, with caret on an empty line, right before the first line
dc.l $02220620 ; Tile #42Beware, everything below is a bit “off-putting” but, in any case, it happens like that if you break the process down into smaller basic actions !
-
The regex engine first searches for a range of consecutive words characters till a
0,1or2digit, either, after a literal$or after the end of the previous search. As no search has been performed, so far,\Gsyntax matches, by default, at current position, the beginning of the empty line, which is a zero-length string -
As no word char exists in that empty line, the regex engine skips the
EOLchars and moves to the beginning of the next linedc.l $02220620 ; Tile #42. You could say : it should match thedcstring, which are word chars, also ? No, no ! Because the initial location, in the empty line, and thedclocation are not contiguous. Indeed, there is a gap of the two chars :\rand\n) -
Thus, the
\Gassertion is not true, presently. So the regex engine tries to match the first alternative and skips to the literal$and the next0digit to search for -
The
\Kfeature cancels any match, so far and resets the regex engine working position => So, it only matches this first0digit. Remember that this configuration is possible as the range of chars before digit0,1or2to search for, may be empty -
As the group
1is defined, when matching the0digit, the regex engine replaces it with the stringG -
Now, as no more
$symbol exists, the regex engine needs to use the second alternative, the\Gassertion, which represents the location right between the letterGand the next range of word chars till a0,1or2digit. So it just matches the first2digit, right after and, again, only selects that digit2 -
As the group
3is defined when matching the2digit, the regex engine replaces it with the stringI -
The second, third and fourth
2digit, of current line, as well as the second0digit, are matched, in the same way as above, and replaced, consequently, with the appropriate letter -
Then, the regex engine matches the
62digit, right after the previousGletter, which verifies the\Gassertion and selects only the fourth digit2of current line, due to the\Ksyntax -
Again, this
2digit is replaced with aIletter, as group3is defined when matching the2digit -
The regex engine advances one position and matches the last
0digit of current line and replaces it with theGletter -
Now, things become interesting : the regex engine must find a next range of consecutive word chars, possibly empty, ending with, either, a
0,1or2digit. Obviously, this next range of contiguous word chars is the string42, located some chars after the end of our previous search ! So the\Gassertion is not verified anymore and, as there is no other$symbol, either, the overall search fails. Thus, the regex engine skips the remaining chars of that first line, after the third0digit, which has been changed intoGand moves to the beginning of the second line where the process resumes ! -
And, when a line just ends with a first range of word chars, without any comments zone, it, necessarily, will search for a literal
$symbol, as the\Gfeature cannot be true, due to the gap produced by theEOLcharacters of current line !
As you may notice, the key point, in this kind of data, is that, the several ranges of words characters are not juxtaposed. So, the
\Gassertion forces, automatically, the process to cancel any further search after examination of each first range of consecutive words chars of each line, following a$symbol ;-))Note also that, due to the
\Ksyntax, inside this search regex, you cannot use a step by step replacement with several clicks on theReplacebutton. However, you can use theFind Nextbutton, to get the different matches
Wow ! Glad to see that you’re still there, after these long explanations ;-)) Thank you for your patience and full attention !
Best Regards,
guy038
-
This post is deleted!