Changing Data inside XML element
-
@guy038 said in Changing Data inside XML element:
Alan, do you like it that way ?
I do have some suggestions; will post back after I have some more time to consider it.
-
@guy038 said in Changing Data inside XML element:
(?-i:BSR|(?!\A)\G)(?s:(?!ESR).)*?\K(?-i:FR)
So I experimented a bit, and I found that it could be judged a bit “fragile”, from its higher-level intent. Example:
overall regex:
(?x) (?-i: (?s:B.*?S.*?R) |(?!\A)\G) (?s:(?!E.*?S.*?R).) *?\K (?s-i:F.*?R)data set 1:
B S R FR F R E S R FRresult 1 (intended):

data set 2:
B S R FR F E S R FRresult 2 (unintended):

I certainly understand the reason for failure of result 2.
-
@Alan-kilborn and All,
Alan, you’re cheating a bit ! Let’s me explain :
I’ll use this sample text :
B S R FR F R F F R R F FR E S R FR F R F F R R F FR FRYour FR regex is
(?s-i:F.*?R)which means : “Search for the shortest range, possibly empty, of any char,EOLincluded, between aFletter and aRletter, with that case”So, using only the regex
(?s-i:F.*?R), it matches, in theBSR •••••••• ESRarea :-
The string FR, line
9 -
The string F
CRLFR, lines11and12 -
The string F
CRLFCRLFFCRLFCRLFCRLFR, between the lines14and19 -
The string F
CRLFCRLFFR, between the lines24and26
Now, let’s consider this other FR regex
(?s-i:F\R*R). This regex searches for aF, with that case, followed with a range of consecutiveEOLchars, possibly empty, till aRletter, with that case. I think this definition is close to what we expect to :Using this new version
(?s-i:F\R*R), it matches, in theBSR •••••••• ESRarea :-
The string FR, line
9 -
The string F
CRLFR, lines11and12 -
The string F
CRLFCRLFCRLFR, between the lines16and19 -
The string FR, line
26
So, if we use this overall regex ( only the FR part have been changed ) :
(?x) (?-i: (?s:B.*?S.*?R) | (?!\A)\G) (?s:(?!E.*?S.*?R).) *?\K (?s-i:F\R*R)it correctly matches and marks :
-
The string FR, line
9, right after theBSR -
The string F
CRLFR, lines11and12 -
The string F
CRLFCRLFCRLFR, between the lines16and19 -
The string FR, line
26, right before theESR -
And every other match of the simple regex
(?s-i:F\R*R), located after theESR, are discarded, as expected ;-))
Refer the picture, below, where I’m using the regex in line
3: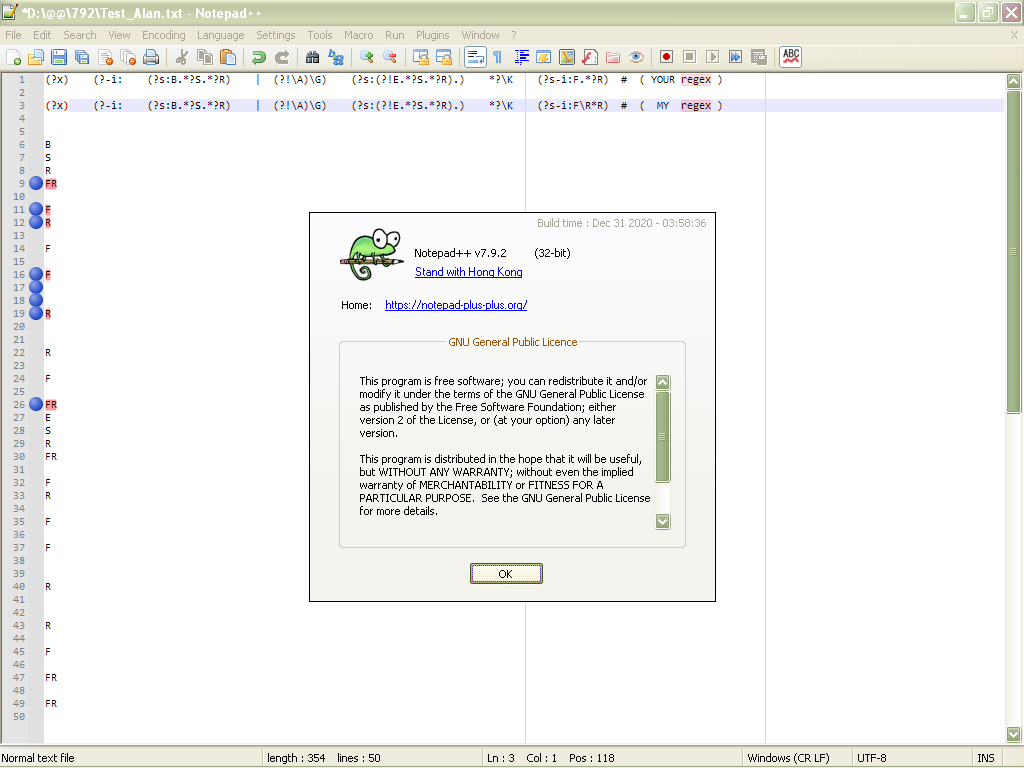
In summary, this generic regex seems quite robust !!
Best Regards,
guy038
-
-
So the part that bothers me (slightly) is that as a user, I want to think of specifying the search region and the find regexes as independent entities.
Maybe another way of saying it is that I’d like the search region to have precedence over the find.
In my example 2 this doesn’t happen, and maybe there is no way to have it happen.With this, I run the risk of writing a bad replacement, that could be data dependent.
Meaning that I could craft something that works well for a few cases at the top of a file where I’m testing it, but perhaps not all cases farther down in the file (or worse, multiple files).
So I do my “few cases” analysis, deem it working, and then tell it to blast away at the rest of the file(s), and find out some time later that I’ve corrupted my data with errant replacements.Normally, in such a risky situation – if I know/suspect it to be so – I could tell myself “Don’t use this technique in a Replace All situation, just do a Replace (with implied Find Next) so that you can verify each replacement.” But… this technique uses
\Kand individual-replace doesn’t work (certainly not your fault @guy038 – are the devs ever going to make it work?).Perhaps there are just always going to be such risks with certain techniques.
-
Hi, @alan-kilborn and All,
I tried to study the
\Kbehavior, in case of a simple replacement with theReplacebutton and, unfortunately, I cannot deduce a general rule for that assertion :-((-
Open a new tab and paste the simple expression
abgcd ef ghi j -
Select one line of the list , below, containing a regex
-
Open the Replace dialog(
Ctrl + H) -
For all the examples, the
Replace withfield contains only the@character -
Click once on the
Find Nextbutton -
Then, click several times on the
Replacebutton … till no replacement occurs
=>
Results, after : - A "CTRL + HOME" operation - SELECTION of ONE regex or LINE, below - A "CTRL + H" operation - ONE click on the "FIND NEXT" button - SEVERAL clicks on the "REPLACE" button ( NOT the "REPLACE ALL" button ! ) against the string "abgcd ef ghi j", PASTED in a NEW tab : (?x-s).+?\K\x20 # KO ( 3 SPACE chars NOT changed ) (?x-s).*?\K\x20 # OK ( 3 SPACE chars CHANGED into @ ) (?x-is)(ab.*?\Kg|.*?\Kp) # KO ( TWO "g" NOT changed ) (?x-is)(ab.*?\Kg|.*?\Kh) # KO ( TWO "g" NOT changed, "h" CHANGED into @ only ) (?x-is)(ab.*?\Kg|.*?\Kg) # OK ( TWO "g" CHANGED into @ ) (?x-is)(.*?\Kg|.*?\Kp) # OK ( TWO "g" CHANGED into @ ) (?x-is)(.*?\Kg|.*?\Kh) # OK ( TWO "g" and "h" CHANGED into @ ) (?x-is)(.*?\Kg|.*?\Kg) # OK ( Two "g" CHANGED into @ ) (?x-is)a.*?\Kg # KO ( TWO "g" NOT changed ) (?x-is)\l.*?\Kg # KO ( TWO "g" NOT changed ) (?x-is).*?\Kg # OK ( TWO "g" CHANGED into @ ) (?x-is)(ab|)*?\Kg # OK ( TWO "g" CHANGED into @ ) (?x-is)(ab|\G)*?\Kg # OK ( TWO "g" CHANGED into @ )
Although the
\Kbehavior is rather difficult to interpret, it seems, however, from the last example(?x-is)(ab|\G)*?\Kg, that the generic regex is compatible with several “step by step” replacements, using theReplacebutton only. So :- Paste the text, below, in a new tab :
F R FR B S R FR F R F F R R F FR E S R FR F R F F R R F FR FR-
Move back to the very beginning (
Ctrl + Home) -
Open the Replace dialog (
Ctrl + H)
SEARCH (?x) (?: (?s-i:B.*?S.*?R) | (?!\A)\G ) (?s-i:(?!E.*?S.*?R).)*? \K (?s-i:F\R*R) # With my FR version REPLACE @-
Click once on the Find Next button ( it should select the first FR, after “BSR” )
-
Then, click four times on the
Replacebutton
=> One at a time, the selected matched zone is replaced with the
@sign ;-))and you should get that picture :
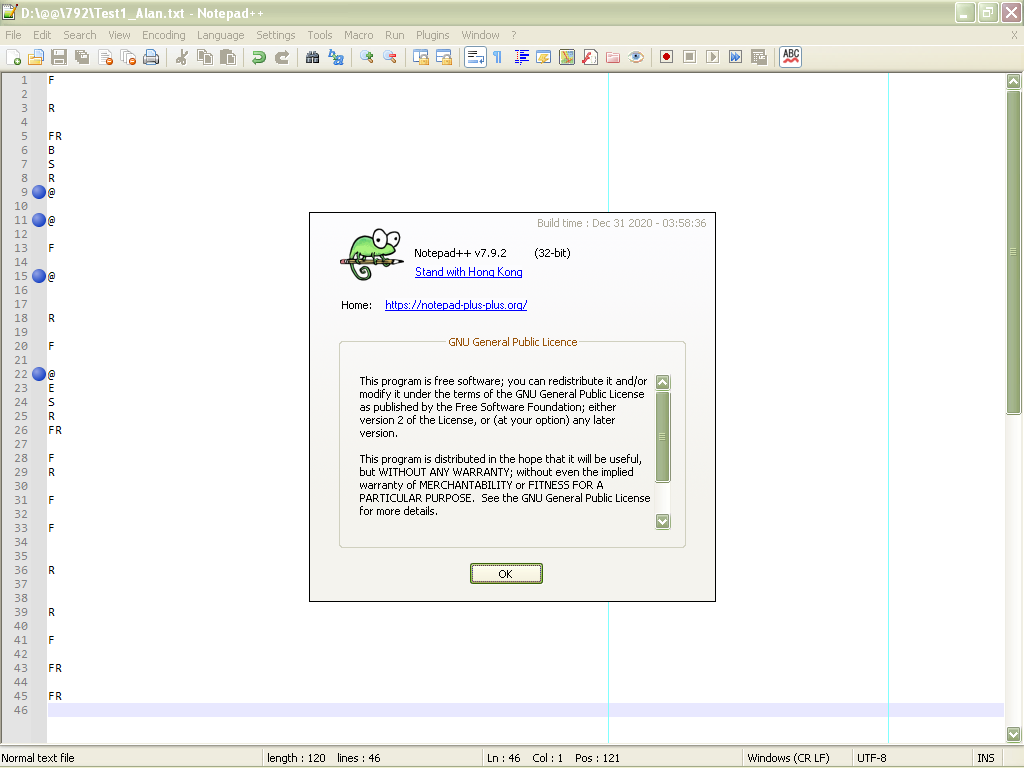
Now, Alan, it quite possible to avoid the
\Kassertion, with that syntax :SEARCH (?x) ( (?: (?s-i:B.*?S.*?R) | (?!\A)\G ) (?s-i:(?!E.*?S.*?R).)*? ) (?s-i:F\R*R) # With my FR version REPLACE \1@Remark that the replacement is
\1@( instead of@). After running this S/R, in the same conditions as above, we get similar results ;-)However, note that, if we just search for the FR or try to mark the FR zones, that second syntax, without
\K, is quite annoying and not really exact, as it does select FR, but it also selects :-
The BSR part and anything till FR
-
Anything since last match till FR
Thirdly, Alan, regarding the precedence of the region to search for, over the effective FR match :
As your FR regex
(?s-i:F.*?R)contains a range of any char,EOLincluded, you need to restrict this area to an area not containing the ESR, too ! Thus, this fact changes your regex to :SEARCH (?x) (?: (?s-i:B.*?S.*?R) | (?!\A)\G ) (?s-i:(?!E.*?S.*?R).)*? \K (?s-i:F((?!E.*?S.*?R).)*?R) # With your FR version <--- Find Regex---- FR ---> REPLACE @Of course, your regex does not match exactly like my FR regex ! But the matches are correct and correctly limited in the
BSR •••• ESRarea. Moreover, the step by step replacement is still effective and give the picture below :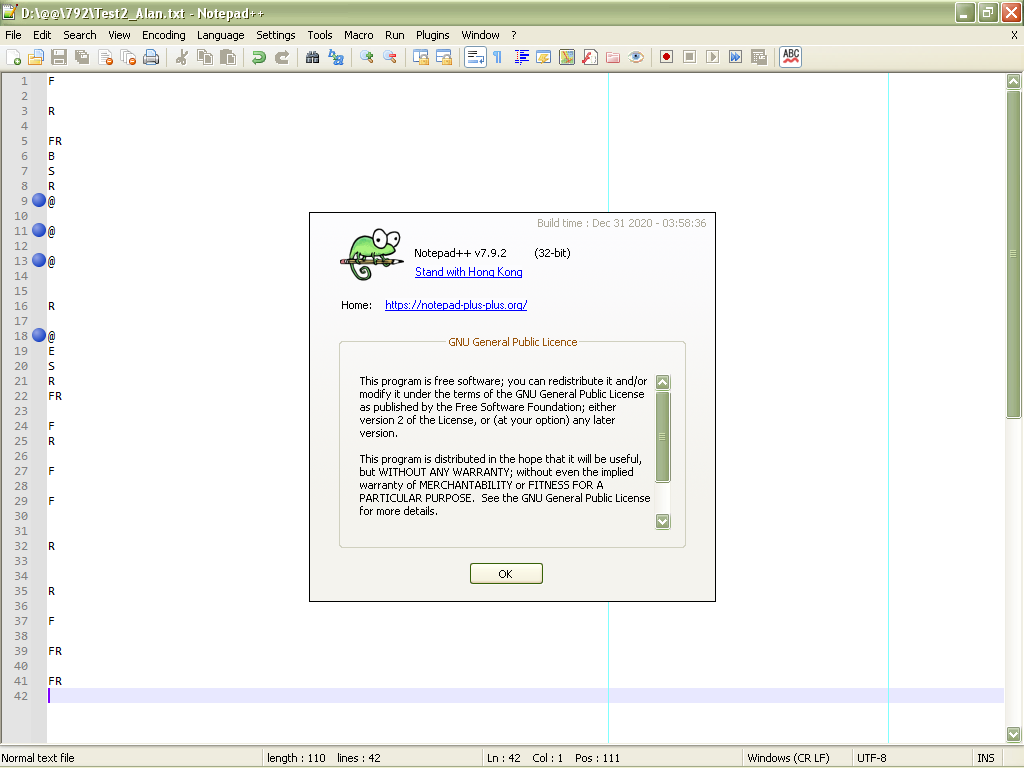
Best Regards,
guy038
P.S. :
An other example :
Let’s consider this text :
/ / The licenses/for most {software are/designed to/take away your} freedom/to share/and change it. {By contrast, the/GNU General Public/License is } intended to/guarantee/your {freedom/to share and/change} free/software This General/Public License/applies to {most of/the Free Software/Foundation's software} {/} / /-
Paste it in a new tab
-
Move back to the beginning (
Ctrl + Home)
Now, let’s suppose that we want to change any
/character into a@character, but ONLY in areas delimited by curly braces{ •••• }. Note that, in our sample, the second line contains two{ ••••• }zones. So :-
FR =
/ -
RR =
@ -
BSR =
\{ -
ESR =
\}
And gives this overall S/R :
SEARCH (?x-si) (?: \{ | (?!\A)\G ) (?: (?!\}). )*? \K / REPLACE @Remark that the part
(?:(?!ESR).)*?, implicitly, defines an area which does not contain any}character till the next/char to search for. In other words, it tries to find a/before a possible further}character !=> After
1click on theFind Nextbutton and9clicks on theReplacebutton, you’ll see that all occurrences of/, which are included in areas between curly braces ONLY, have been replaced, as expected, with the@symbol ;-)) -
-
So I was intrigued by your \K results, but let me confine my response to just this small part of your posting:
(?x-s).+?\K\x20 # KO ( 3 SPACE chars NOT changed ) (?x-s).*?\K\x20 # OK ( 3 SPACE chars CHANGED into @ ) abgcd ef ghi j 1111 <- tens, and 01234567890123 <- ones position in docBut rather than looking at it as a user and regex guru as you did, I cheated – because I’m not the same guru – and looked at the N++ source code.
So, what Notepad++ does, when you click on the Replace button is, it runs its Find Next code search (transparently) and sets a variable called “nextFind”. This search starts at the minimum position of the current selection (or just the caret position if no selection is active) and proceeds toward higher positions in the doc.
If what comes out of that search is a match of the same selected text position range as you began with, then the replacement is made.
If what results from the Find Next search is some different text selected (or you had nothing selected originally), the replace is not done, but the new text selection is now the nearest match higher in the doc (presumably convenient for your next press of Replace!).
On actual replacement, it then moves the selection to the following match it finds (meaning that internally it runs another Find Next). For the case where the replacement was made, the following search starts at the very righthand side of the newly inserted text.
That’s kind of a wordy explanation for this part, but hopefully it makes some sense.Okay, so what does this all this mean for regexes using
\K, specifically yours above where the first one doesn’t work and the second one does ?analysis of “first” regex:
(?x-s).+?\K\x20move caret to start-of-file, data as stated above:
abgcd ef ghi jfirst press of Replace button:
active selection range at time of button press: (0,0)
code runs at Replace press:
calculates “nextFind” selection range = (5,6)
no (selection range) equivalency to (0,0) so NOTHING IS REPLACED
selection moves to (5,6) which is the space betweendandesecond press of Replace button:
active selection range at time of button press: (5,6)
code runs at Replace press:
calculates “nextFind” selection range = (8,9)
no (selection range) equivalency to (5,6) so NOTHING IS REPLACED
selection moves to (8,9) which is the space betweenfandgthird press of Replace button:
active selection range at time of button press: (8,9)
code runs at Replace press:
calculates “nextFind” selection range = (12,13)
no (selection range) equivalency to (8,9) so NOTHING IS REPLACED
selection moves to (12,13) which is the space betweeniandjetc.
analysis of “second” regex:
(?x-s).*?\K\x20move caret to start-of-file, data as stated above:
abgcd ef ghi jfirst press of Replace button:
active selection range at time of button press: (0,0)
code runs at Replace press:
calculates “nextFind” selection range = (5,6)
no (selection range) equivalency to (0,0) so NOTHING IS REPLACED
selection moves to (5,6) (the space betweendande)second press of Replace button:
active selection range at time of button press: (5,6)
code runs at Replace press:
calculates “nextFind” selection range = (5,6)
have (selection range) equivalency to (5,6) so REPLACEMENT IS MADE
selection moves to (8,9) which is the next match between thefandgthird press of Replace button:
active selection range at time of button press: (8,9)
code runs at Replace press:
calculates “nextFind” selection range = (8,9)
have (selection range) equivalency to (8,9) so REPLACEMENT IS MADE
selection moves to (12,13), which is the next match between theiandjetc.
Here’s the conclusion I draw from this:
If you use
\Kin a regex, if the part of the regex to the left of the\Kmatches as zero-length, the Replace button press WILL work to replace data. If, however, the part of the regex to the left of\Kmatches one or more characters, a press of Replace will NOT perform a textual substitution, but will rather just move to the next higher match.Following this rule: Because the “first” regex demands that a minimum of one character be matched to the left of
\K, no Replace ments are made. Because the “second” regex has a minimum-of-zero requirement, when it does match zero, that match comes to the left of\K, so a Replace is allowed to actually replace.Probably a zero-length match to the left of
\Kin a regex isn’t very useful often; perhaps that is why I don’t recall hearing of\Kand single-step replace “working only sometimes” in the past? Typically, it is, “doesn’t work”. -
Hello, @alan-kilborn and All,
You said :
If you use \K in a regex, if the part of the regex to the left of the \K matches as zero-length, the Replace button press WILL work to replace data. If, however, the part of the regex to the left of \K matches one or more characters, a press of Replace will NOT perform a textual substitution, but will rather just move to the next higher match.
Not totally exact, Alan !
For instance, let’s imagine this text, in a new tab, beginning with two blank lines :
78464 13232178913 894654465464 12231 52632abc9526271 026238121 945135 s1658 6479123789 456134 978941 13454 46464646l 4567861341 128978 10313 111386460abc9564 6240 17868913345100544 4867864Note that the lines
5and11, only, contains the stringabc
And let’s use a simple regex, derived from our generic regex, presently studied in the previous posts :
(?-s)(abc|(?!\A)\G).*?\K\x20Now, in this new tab, containing the sample text :
-
Move back to the beginning (
Ctrl + Home) -
Open the Replace dialog
Ctrl + H)-
SEARCH
(?-s)(abc|(?!\A)\G).*?\K\x20 -
REPLACE
@
-
-
Click once on the
Replacebutton ( identical to a click on theFind Nextbutton ! )
=> The first space character, of line
5, is matched. As the caret was initially on a blank line, it cannot match any standard character. So the part(?-s)(?!\A)\G.*?\K\x20, with the second alternative, has not been used by the regex engineThus, the regex engine uses, necessarily, the first alternative ( the regex
(?-s)abc.*?\K\x20), which indeed, contains a part, before\K, which is not a zero-length area, as equal to(?-s)abc.*?However, if you click a second time on the
Replacebutton, the first space char of line5is, as expected, changed into the@symbol !Of course, any further space char, located in lines containing the
abcstring, are replaced, in the same way, after successive clicks on theReplacebutton
You also said :
Probably a zero-length match to the left of \K in a regex isn’t very useful often;
But it just so happens that our generic regex S/R :
SEARCH
(?s-i:BSR|(?!\A)\G)(?s-i:(?!ESR).)*?\K(?s-i:FR)REPLACE
RRseems to work correctly with “step-by-step” replacement ;-))
Note that the search syntax above corresponds to the particular case where :
-
The search is sensible to the case of letters
-
The search may extend to a multi-lines area
-
No subset of FR, is needed in the replacement regex => All groups are non-capturing ones
Best Regards,
guy038
-
-
@guy038 said in Changing Data inside XML element:
Not totally exact, Alan !
But it just so happens that our generic regex S/R…
Ok, then, back to the drawing board.
More analysis work on this for me!
I’ll return with the answers.
Well…if I find them. -
So this is all very confusing until one breaks it down! :-)
And even then it is still confusing. :-(Following your steps:
Now, in this new tab, containing the sample text :
Move back to the beginning ( Ctrl + Home )
Open the Replace dialog Ctrl + H )
SEARCH (?-s)(abc|(?!\A)\G).*?\K\x20
REPLACE @
Click once on the Replace button ( identical to a click on the Find Next button ! )Then, without doing anything else (without pressing any more buttons), you say:
Thus, the regex engine uses, necessarily, the first alternative ( the regex (?-s)abc.?\K\x20 ), which indeed, contains a part, before \K, which is not a zero-length area, as equal to (?-s)abc.?
Which I wholly agree with.
But… the point where I talked (in my previous post) about a zero-length string to the left of \K has not come into play (yet)!
We are left sitting and looking at:
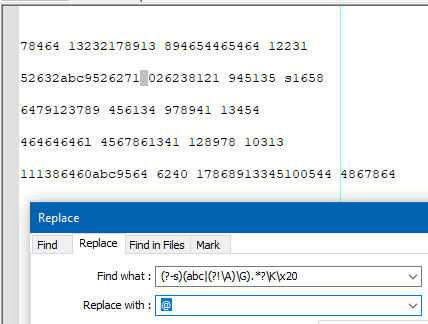
Note the single space selected in line 5.
At this point Replace is pressed a second time.
The internal find is again run and the match that occurs is going to effectively be this part of the regex:(?!\A)\G.*?\K\x20and that IS going to be zero-length to the left of the
\K!The key point might be that
\Gwill match because it by definition “matches at the start of string-to-search at the first attempt”. And because this search is indeed a new search, we are AT the first attempt. The start of the string-to-search is going to be the left side of the selected space character.So in summary, to the left of the
\Kfor the match we have:(?!\A)-> match of zero-length\G-> match of zero-length (from “key point” just above).*?-> match of zero-length (because \x20 will match next and since we are a minimal match, we match zero)
Add up all those zeroes to obtain: 0+0+0=0
And thus my postulate from the previous posting seems to hold: If the match to the left of
\Kis a zero-length match, the replacement WILL be made. So in this case the@replaces the space.Any time the Replace button is pressed, it only replaces if the current selection matches the find-expression – do we agree on this? Regex or not…right?
Because
\K“cancels out” what comes before it in a regex (and it must cancel it very deeply in the regex engine – because(?<...)doesn’t have the same difficulty\Kdoes), the only way a current selection is going to match an expression using\Kis if what is to the left of the\Khas no length to it.I’d be happy to have you poke holes in my logic here! :-)
-
Hello, @alan-kilborn and All,
Alan, I did numerous tests and, I’m afraid, that all that story does not depend on the
\Gassertion, anyway but only on the\Kone !! Yes, really not easy :-((So here is, below, how I imagine the process, after clicking, either, on the
Find Nextor theReplaceof the Replace dialog, whatever the search mode. Note that we will not speak about theReplace Allbehavior, at all !
After any click on the
Find Nextbutton, the regex engine starts searching for a match of the search regex :-
From the
endof a present normal selection -
From the present position of the caret, if
NOselection exists
Then :
-
IF
NOmatch exists, the overall process stops -
IF a match has been found, it is selected
After any click on the
Replacebutton, the regex engine starts searching for a match of the search regex :-
From the
startof a present normal selection -
From the present position of the caret, if
NOselection exists
Then :
-
IF
NOmatch exists, the overall process stops -
IF a match has been found :
-
IF the match is
strictly identicalto the previous selection :-
The selection/match is
replacedwith the replacement regex -
The current position is reset to the location, right after the
endof the replacement regex -
And the regex engine re-starts searching, further on, for a
nextmatch of the search regex :-
IF such a match can be found, it is selected
-
IF
NOmatch exists, the overall process stops
-
-
-
IF the match is
differentfrom the previous selection OR IFnoprevious selection exists :- This match is just selected,
withoutany replacement process
- This match is just selected,
-
So, the complete solution, in order that the
step by stepreplacement works correctly, is that the current search, in any mode, matches the previous selection, whatever the way that selection was obtained :-
By a previous click on the
Replacebutton ( standard case of subsequent replacements ) -
By a previous click on the
Find Nextbutton ( standard case of a first replacement ) -
By a manual selection or move of the caret, generated intentionally, by the user !
Thus :
- In case of a search, in the
NormalorExtendedmode OR if no\Kassertion is used, inRegexmode :
=> The previous selection, generated by a click on the
Find NextorReplacebutton AND the present match, met at the start of the selection, are always identical, meaning that theStep by Stepreplacement feature is always functional !- In the case of the particular use of the
\Kassertion, inRegexmode, the present selection, before clicking on theReplacebutton, is the part of the regex, located after\Kstructure. So the rule is :
=> A simple replacement can occur ONLY IF the overall regex can match the part of the regex located after the
\Ksyntax !In other words, if we consider the general regex form
........\K••••••••, this means that :The overall regex
........\K••••••••must match, exactly, the same expression than the••••••••sub-regex
For instance :
-
(A) The regex
(?-s).*?\Kabcdoes match the sub-regexabc, after\K=> The step-by-step replacement is possible -
(B) Similarly, the regex
(?-s).*?\Kabc\ddoes match the sub-regexabc\d, after\K=> The step-by-step replacement is OK -
(C) And the regex
(?-s).*?\K\dabcdoes match the sub-regex\dabc, after\K=> The step-by-step replacement will work
But, on the contrary :
-
(D) The regex
(?-s)\d.*?\Kabcdoes not match the sub-regexabc, after\K=> The step-by-step replacement is not possible -
(E) Similarly, the regex
(?-s)\d.*?\K\dabcdoes not match the sub-regex\dabc, after\K=> The step-by-step replacement is KO -
(F) Now, the regex
(?-s)\d.*?\K\d?abcnever matches the sub-regex\d?abc, after\K, too => The step-by-step replacement will not work. However, by clicking successively on theReplacebutton, it produces :-
Firstly, a selection of the
\dabcstring, if that string is preceded, itself, with a digit -
Secondly, a selection of the
abcstring
-
-
(G) Note that the use of the regex
(?-s)\d?.*?\K\d?abc, is more difficult to understand, although logical : by clicking successively on theReplacebutton, it produces, either :-
A selection of
abc, if the previous selection was\dabc -
A replacement by the
@symbol, if the previous selection wasabc
-
-
(H) To end with, remark that, making the first
\d?expression lazy, the resulting regex(?-s)\d??.*?\K\d?abcdoes match the sub-regex\d?abc, after\K. So :-
The step-by-step replacement works nice
-
Any click on the
Replacebutton, from the second, does change the matched string\dabcinto a@symbol
-
-
Test all these regexes, above, against the text
123abc456abc0abc789abc0, pasted in a new tab -
The Replace regex is just
@, in all cases -
Select the
Regular expressionsearch mode -
Click only on the
ReplaceorFind Nextbutton ( Do not use theReplace Allbutton )
Alan, the crucial point is to move the caret or create a normal selection, by yourself, before one or some click(s) on the
Replacebutton, and observe the results with the hope of deducing a logical behavior, as I did ! This will allow you to confirm or deny my assertions ;-))Best Regards,
guy038
-
-
Hi, All,
See my results of testing the @sasumner’s build, about the
\Kassertion and thestep by stepreplacement :https://github.com/notepad-plus-plus/notepad-plus-plus/issues/8434#issuecomment-784583153
See, also, an interesting helping post, of @ArkadiuszMichalski, regarding how to test new N++ builds !
https://github.com/notepad-plus-plus/notepad-plus-plus/issues/9493#issuecomment-781344297
Best Regards,
guy038
-
@guy038 said in Changing Data inside XML element:
See, also, an interesting helping post, of @ArkadiuszMichalski, regarding how to test new N++ builds !
https://github.com/notepad-plus-plus/notepad-plus-plus/issues/9493#issuecomment-781344297Seems to be official now:
https://github.com/notepad-plus-plus/notepad-plus-plus/wiki/Testing
Good job @ArkadiuszMichalski !
Cheers.
-
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
 G guy038 referenced this topic on
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
G guy038 referenced this topic on
-
P PeterJones referenced this topic on
-
-
-
-
-
-
-
 M Mark Olson referenced this topic on
M Mark Olson referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login