Strange behavior of Find All in Current Document with Regular Expression
-
I am using 32-bit N++ 7.3, and I have run into IMO some very strange behavior, which I would consider a bug. However, I’m open to having someone show me that this is working as designed, or something…
I have quite a large (116MB) text file containing XML. I was hoping to make it smaller by removing some unnecessary XML elements, using Regular expression search and replace. To test the search part of this, I set up my regular expression query like this:
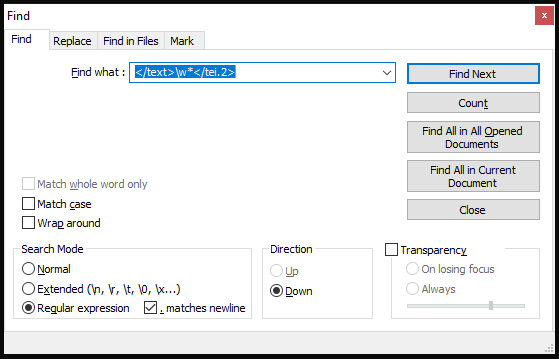
When I click on Find Next, it correctly finds the first match.
But when I Cancel the Find dialog, go back to the top of the document, then do Find again, this time clicking on Find All in Current Document, it automagically changes the search parameters to prior to searching and doesn’t find anything! Here are the changed search parameters:
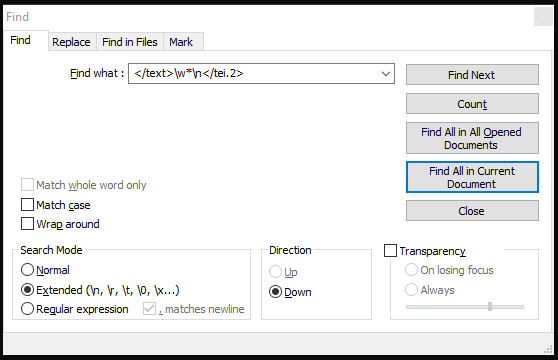
The search string now has \n inserted into it, and the Search Mode has been changed! This, of course, is why there are no matches.
I tried the same thing where the file size is only 3.6MB and contains only 1 match, but the same problem occurs.
Is this working as designed??? Is this somehow a result of working in a large file? (If so, is there a known limit to the size of file that N++ can reliably handle?)
-
Notepad++ 7.3 was released on the first day of 2017, making it fairly “old” by today’s measurement standards.
I would suggest upgrading to the latest release and trying your scenario again. -
Sorry, I didn’t realize that there is no automatic update feature in N++, so I didn’t think my version was so back-level. (Is it because I am using N++ portable?)
I tried again, this time I found that clicking on Find Next no longer works. So there has been some kind of change. Even though I have checked . matches newline, the \w option no longer seems to match the CR or LF characters.
So I changed my RegEx expression to: </text>[\w\n\r]*</tei.2>
This now works. Or, at least it seems to give me what I would expect.
-
@Todd-Hoatson said in Strange behavior of Find All in Current Document with Regular Expression:
the \w option no longer seems to match the CR or LF characters.
Hmm…
\whas always matched a “word” character, and since line-ending characters are not word characters, they don’t match.You don’t really discuss the specifics of the data you are trying to match.
I might take a “wild guess” that the following regular expression is what you want:(?s)</text>.*?</tei.2>but as I said, it is a wild guess.
BTW, the usage of
(?s)at the start of the regex allows one to ignore the. matches newlinecheckbox (something we do in solutions presented here, because it keeps things simpler).(?s)is equivalent to. matches newlineticked
(?-s)is equivalent to. matches newlineunticked -
@Todd-Hoatson said in Strange behavior of Find All in Current Document with Regular Expression:
I didn’t realize that there is no automatic update feature in N++, so I didn’t think my version was so back-level. (Is it because I am using N++ portable?)
The portable instance does not enable the auto-updater, because the auto-updater downloads the installer, which would really confuse users.
If you’re unsure about the version, you can always look here in the Announcements thread, or at the official downloads page, or at the latest github release for the truly most-recent release… Or you can look at the same URL as the updater uses (https://notepad-plus-plus.org/update/getDownloadUrl.php) to see what version is being pushed to the updater as “most recent” (that XML at that URL only gets updated once the developer is convinced a release is stable enough to go to auto-update)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login