How to find and remove duplicate strings of alphanumeric characters from multiple files?
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
How to find and remove duplicate strings of alphanumeric characters from multiple files?
That is a question that has so many answers. You need to provide us with an example of what you are looking for.
- How long is the string of characters, you seem to suggest a complete line?
- Is the string case sensitive, so a
howdoes not equal aHow? - Is there just 1 string to look for or multiple?
- What do you want to do to the duplicates, remove all, first or last one?
There may be other questions as well. It’s just that it’s not worth anyone’s time wasting it to help you if you don’t provide the necessary information.
Terry
-
@Terry-R Answers to your questions:-
- Yes, complete lines
- Yes, it is case sensitive
- Multiple lines but I want to do one line at a time so that I can check after each command (to find and remove) is executed
- Remove all duplicates but keep the original
Thanks for your time and help!
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
Remove all duplicates but keep the original
Keeping the original will pose problems. However there is a solution. If you first read the excellent solution provided by @guy038 here. With his solution it will leave the last copy ONLY. The only change to make is to have
(?-is)instead of(?-s)as this allows you to identify with case sensitivity enabled.But if you reverse the lines, see the following posts to the above link. Again @guy038 comes up with adding a line number to the start of each line then sorting numerically descending, then removing the duplicates and lastly re-ordering numerically ascending.
Just remember to use the “Replace” button, not replace all as that allows you to see (and remove) the duplicates one by one.
Give that a go.
Terry
-
@Terry-R I did what @guy038 typed there but it is removing even the brackets in the CSS section of my .html files/pages (CSS can have just one bracket in a line). Any better suggestion?
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
but it is removing even the brackets in the CSS section of my .html files/pages
I asked the question is it complete lines to which you said yes. So now you have changed the request.
How can you expect us to help you if you don’t provide enough information and examples.
At this point I’m out.
Terry
-
-
-
This post is deleted! -
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
but it is removing even the brackets in the CSS section of my .html files/pages (CSS can have just one bracket in a line). Any better suggestion?
You have yet to supply any examples. Regardless I will give you some help.
Since you are using the “Replace” button to see changes 1 at a time, when it gets to a line you don’t want to change press the “Find Next” button instead as this means you don’t change what is currently selected, instead it finds the next occurrence.
It might be possible to adjust the regex to ignore lines based on the characters on it but that needs examples provided.
Terry
-
-
As has been explained to you before, this process works best if you show two black boxes, one with the way your data is now (“have”); and the second with the way you want the data to look (“want”)
have:
blah { blah }want:
something < yada >Since you don’t seem to remember this guidance, I will re-post it. If you don’t follow these guidelines, you will find it hard to convince people to help you, especially since you’re asking so many questions.
----
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
@PeterJones @guy038 I would like all the matter/characters between the
<and>which have duplicates to be removed.
For example,<link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all"> <link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all">should become:-
<link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all">``` -
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
I would like all the matter/characters between the < and > which have duplicates to be removed.
Thank you for finally giving us some examples. From those examples I can say that the original solution I linked from @guy038 along with his subsequent line numbering and reversing should do that. But I think you probably know that already.
What is missing is examples of the Suppose I want to avoid removing the flower brackets, question you asked earlier. Can you provide examples of the lines they are in or is it that these brackets are on lines by themselves, possibly with spaces before the bracket? This is very important information.
Terry
-
@Terry-R In the CSS section of my webpages (just after my
meta tagsright at the top), some lines are just{or}and I don’t want those to be removed or replaced -
@Ramanand-Jhingade said:
I would like all the matter/characters between the < and > which have duplicates to be removed.
For example…@Terry-R said
From those examples I can say that the original solution I linked … along with … subsequent line numbering and reversing should do that.
I’m confused why this command was not recommended for this task, given the example data provided:
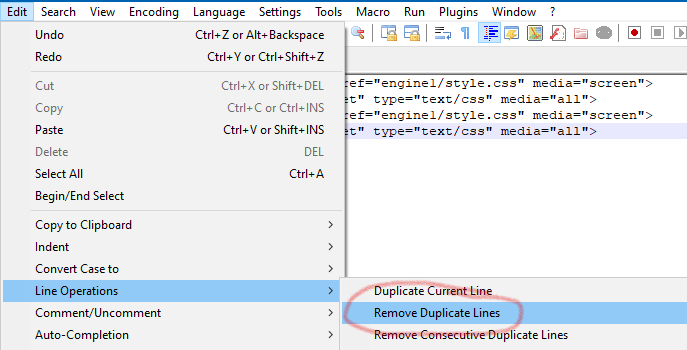
-
@Alan-Kilborn OP wants to use “Replace” in single mode, presumably to verify each removal. And considering he also has the
{}characters to contend with I don’t blame him.Terry
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
some lines are just { or } and I don’t want those to be removed or replaced
As you never showed me examples of these lines I have to assume some things.
Consider adding
^(?=[^\{\}]+$)to the regex immediately behind the(?-is)if that’s what you have. This means look forward at the line and make sure there are NO{or}characters on it. If none then process the line to check if a duplicate.Terry
-
@Terry-R Thanks. I don’t want to mess up things, so please clarify if I should use
(?-is)^(?=[^\{\}]+$)^\d+\h+(.+\R)(?=(?is:.*)^\d+\h+\1)in the Regular expression mode with the “new line” checked/ticked and click on the Find button?
If everything is done correctly, can I use Replace all for all files of the folder. @Alan-Kilborn says that searchingbackwardswill not give accurate results in the post you linked to, but since we are reversing the order of the lines and searching, that should not be a problem, right (it will not be searching backwards)? -
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
Thanks. I don’t want to mess up things, so please clarify if
So assuming you are adding line numbers as @guy038 post mentioned in the link I provided and then sorting numerically descending the lines, then the search will be a forward search. Yes a backwards search is problematic but you are not doing that.
So the regex should be
(?-is)^(?=[^\{\}]+?$)\d+\h+(.+\R)(?=(?s:.*)^\d+\h+\1)I did make 3 amendments:
- We don’t need to include
^twice. - I included a
?in my latest addition, this should prevent it taking too long if there aren’t any more{or}in the remainder of the file. Previously it would have searched multiple lines. The outcome is still the same but it was an omission I’d prefer to fix. - Remove the
iyou added near the end of the regex. This changes the search to a case insensitive one. You wanted it to be sensitive (h not equal H), not insensitive (h = H).
As for using “Replace in All Files” I would not do that until you have fully tested a number of files. Complicated regexes as this may have an effect on a line that you did not advise us about and that you did NOT want removed. I refer to the
{and}lines which you did NOT originally mention, there may be others.Open a file, complete the steps @guy038 mentioned for adding line numbers and sorting, then use the “Find” button first. If you get a line which you don’t want to remove, press the “Find Next” button NOT the “Replace” button. If the line can be removed, press the “Replace” button. Continue though the file until completed. For any lines which you don’t want to remove, you need to copy those elsewhere and then after finishing show us all of them. Only by doing that can we possibly amend the regex to ignore those lines as well, just like I did for the
{and}lines.Good luck
Terry - We don’t need to include