How to find and remove duplicate strings of alphanumeric characters from multiple files?
-
@Terry-R In the CSS section of my webpages (just after my
meta tagsright at the top), some lines are just{or}and I don’t want those to be removed or replaced -
@Ramanand-Jhingade said:
I would like all the matter/characters between the < and > which have duplicates to be removed.
For example…@Terry-R said
From those examples I can say that the original solution I linked … along with … subsequent line numbering and reversing should do that.
I’m confused why this command was not recommended for this task, given the example data provided:
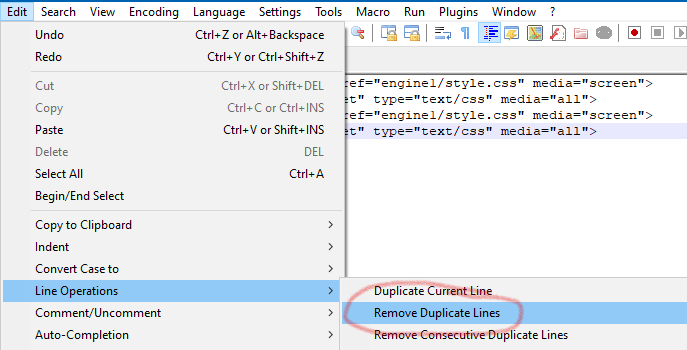
-
@Alan-Kilborn OP wants to use “Replace” in single mode, presumably to verify each removal. And considering he also has the
{}characters to contend with I don’t blame him.Terry
-
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
some lines are just { or } and I don’t want those to be removed or replaced
As you never showed me examples of these lines I have to assume some things.
Consider adding
^(?=[^\{\}]+$)to the regex immediately behind the(?-is)if that’s what you have. This means look forward at the line and make sure there are NO{or}characters on it. If none then process the line to check if a duplicate.Terry
-
@Terry-R Thanks. I don’t want to mess up things, so please clarify if I should use
(?-is)^(?=[^\{\}]+$)^\d+\h+(.+\R)(?=(?is:.*)^\d+\h+\1)in the Regular expression mode with the “new line” checked/ticked and click on the Find button?
If everything is done correctly, can I use Replace all for all files of the folder. @Alan-Kilborn says that searchingbackwardswill not give accurate results in the post you linked to, but since we are reversing the order of the lines and searching, that should not be a problem, right (it will not be searching backwards)? -
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
Thanks. I don’t want to mess up things, so please clarify if
So assuming you are adding line numbers as @guy038 post mentioned in the link I provided and then sorting numerically descending the lines, then the search will be a forward search. Yes a backwards search is problematic but you are not doing that.
So the regex should be
(?-is)^(?=[^\{\}]+?$)\d+\h+(.+\R)(?=(?s:.*)^\d+\h+\1)I did make 3 amendments:
- We don’t need to include
^twice. - I included a
?in my latest addition, this should prevent it taking too long if there aren’t any more{or}in the remainder of the file. Previously it would have searched multiple lines. The outcome is still the same but it was an omission I’d prefer to fix. - Remove the
iyou added near the end of the regex. This changes the search to a case insensitive one. You wanted it to be sensitive (h not equal H), not insensitive (h = H).
As for using “Replace in All Files” I would not do that until you have fully tested a number of files. Complicated regexes as this may have an effect on a line that you did not advise us about and that you did NOT want removed. I refer to the
{and}lines which you did NOT originally mention, there may be others.Open a file, complete the steps @guy038 mentioned for adding line numbers and sorting, then use the “Find” button first. If you get a line which you don’t want to remove, press the “Find Next” button NOT the “Replace” button. If the line can be removed, press the “Replace” button. Continue though the file until completed. For any lines which you don’t want to remove, you need to copy those elsewhere and then after finishing show us all of them. Only by doing that can we possibly amend the regex to ignore those lines as well, just like I did for the
{and}lines.Good luck
Terry - We don’t need to include
-
@Terry-R said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
As for using “Replace in All Files” I would not do that until you have fully tested a number of files.
@Ramanand-Jhingade
On further reflection I realize that you will not be able to use the “Find in all Files”. The reason is that you need to add line numbers and sort before using the regex. Then afterwards you need to sort back to the original order and lastly remove the line numbers.Most of those steps must be completed on an open file. On a positive note, these steps can be recorded as a macro. The steps would be (once macro recorded).
- Open all the files
- Run the macro. This macro moves cursor to first position, adds line numbers (with a possible blank between numbers and original line), sorts descending. Then it saves and closes the file. You can get a macro to run xx times where xx is the number of open files.
- Run the regex using “find in files” option.
- Re-open all the files and run a 2nd macro which sorts back to original order and removes the line numbers. Then it saves and closes the files by running it xx times as for step 2.
These steps will only be of an advantage if this is a function you need to carry out on a regular basis. If you are just fixing a problem once then I suggest opening each file one at a time and perform the steps.
Terry
-
@Terry-R I thought you may be waiting for feedback. On using the code you gave, I got a
Can't find the text (?-is)^(?=[^\{\}]+?$)\d+\h+(.+\R)(?=(?s:.*)^\d+\h+\1)message, so I clicked on the link you gave and used the code mentioned by @guy038 and searched for duplicate lines one by one. I then observed that only the 2 lines I typed above and their duplicates were a problem, so I removed all 4 lines. I then used the next line which happened to be unique and added the 2 lines I mentioned above using the extended mode withline1\r\nline2\unique lineand added those 2lines in all the files of the folder. I thank you for your time and help. I also thank @PeterJones and @Alan-Kilborn for their inputs and @guy038 for the code! -
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
<link rel=“stylesheet” type=“text/css” href=“engine1/style.css” media=“screen”>
<link href=“css/style.css” rel=“stylesheet” type=“text/css” media=“all”>
<link rel=“stylesheet” type=“text/css” href=“engine1/style.css” media=“screen”>
<link href=“css/style.css” rel=“stylesheet” type=“text/css” media=“all”>This will find any duplicate line, but also the blank ones:
Search:
(?-s)^(.*)\R(?s)(?=.*^\1(?:\R|\z)) -
@Ramanand-Jhingade said in How to find and remove duplicate strings of alphanumeric characters from multiple files?:
@PeterJones @guy038 I would like all the matter/characters between the
<and>which have duplicates to be removed.
For example,<link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all"> <link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all">should become:-
<link rel="stylesheet" type="text/css" href="engine1/style.css" media="screen"> <link href="css/style.css" rel="stylesheet" type="text/css" media="all">```I believe the solution will be:
FIND:
(^<link.+)\R(?=[\s\S]*\1)
Replace by:LEAVE EMPTY -
@Robin-Cruise Thank you. I already did the needful!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login