I use Notepadd++ as a great way to copy text into Excel VBA. However I notice that the underscore character gets converted to strange character
-
This does not happen with notepad?
Can you tell me how to avoid this problem?
Regards
Alfred (Excel1Star) -
It does not happen in Notepad++, either. Notepad++ will copy whatever text is in the Notepad++ window, and when you paste it into the VBA editor, it will paste that same text into VBA.
The underscores above look correct. You do have comment lines that seem to have a high-codepoint unicode character. But for Notepad++ to have put those in the copy buffer, those characters(*) must have existed in the Notepad++ editor when you copied them. (*: or bytes that looked different in Notepad++ due to encoding settings, but got interpreted by VBA as those characters)
Did you do something strange, like open a binary file in Notepad++, which happened to have some of the text rendered as text, but other characters as binary characters – if so, then when you copied those bytes and pasted them into VBA, maybe VBA interpreted those bytes as the funny characters, and it had nothing to do with Notepad++.
But that’s as much guessing as I can do for now. “It works for me” is the only thing I can be sure of. If you provide us enough information to try to replicate your problem, maybe someone who has access to Excel+VBA will be able to help (depending on what time of day and how busy I am at work, I might be able to try a quick experiment).
-
Maybe, the issue is with file encoding?
Maybe, you need to use a different encoding. Just a guess. -
@peterjones
Sorry to take so long to get back to this topic.
The odd characters are UNICODE
I have a simple function to replace them:
Function ReplaceUniCode()
Dim Instring As String
Dim CodeNumber As Long
Instring = Application.Caller.Offset(0, -2)
ReplaceUniCode = Replace(Instring, WorksheetFunction.Unichar(35239), “-”)
End Function
Regards
Alfred
The UNICODE does not show up in notepad? -
@mere-human
Changing the encoding has no effect.
Alfred -
Unicode works fine in Notepad++, as long as you have font support for the glyphs.
Can you give a step-by-step of exactly what you are doing, and where things look like what, with screenshots (or a screentogif.com-or-similar animated gif) that make it obvious what you’re talking about?
See also the conversation here where I talk more on a similar-sounding issue, with screenshots.
-
@peterjones
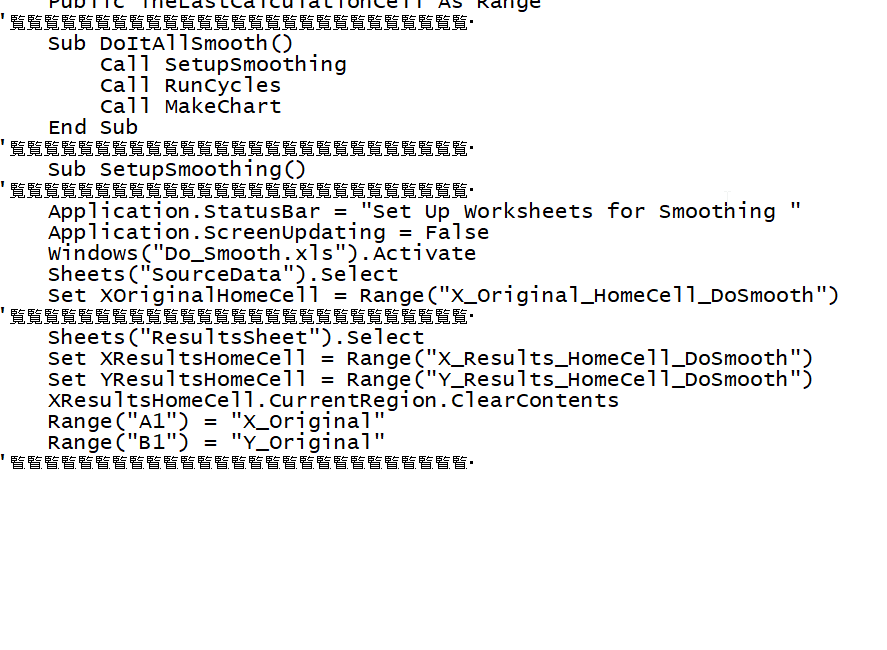
I am using VBA to extract source code for Excel projects.
My style for VBA coding is to use a line of '——————— to block off “paragraphs” of code.
I like to use char(151) because it divides the line in the middle.
When I open the extracted source code in NotePad++ I see the weird Unicode.
If I open the same source in notepad - no Unicode is displayed?
How can I send you a sample source code file?
Regards
Alfred -
@alfred-vachris said :
I like to use char(151) because it divides the line in the middle.
You say
char(151)but to me that implies you are NOT using Unicode, i.e., UTF-8.In some non-Unicode character sets, including whichever one my Notepad++ is using for ANSI files, 151 is a nice long dash character, apparently:
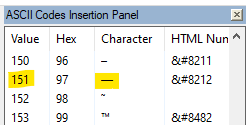
That’s all well and good, but if you try to mix a single-byte 151 value into a bunch of other characters that are UTF-8, you are going to have a mess (and what you’re getting is a hint of that).
So probably the root of your problem is that you aren’t consistently using Unicode, even though you think you are, and this is mucking things up for you.
Maybe a better choice for you is to use U+2014 as a long dash?
-
@alfred-vachris said in I use Notepadd++ as a great way to copy text into Excel VBA. However I notice that the underscore character gets converted to strange character:
My style for VBA coding is to use a line of '——————— to block off “paragraphs” of code.
Okay, now you’ve given us something to go on.
You don’t say whether you copy/paste, or whether you use the Excel VBA’s Right Click > Export feature. I assume the latter, because copy/paste between the two works right on that character (I just tried).
I exported a VBA module that was just
' ———————… when I opened in Notepad++, Notepad++ decided it was ANSI, as it shows in the next-to-last section of the status bar:
On my machine, the default ANSI codepage is 1252 (so standard western charset)
If Notepad++ had mis-interpreted it as UTF-8, it would show a bunch of
x97in dark boxes, because the char(151) is 0x97, and is not a valid byte on its own in UTF-8.

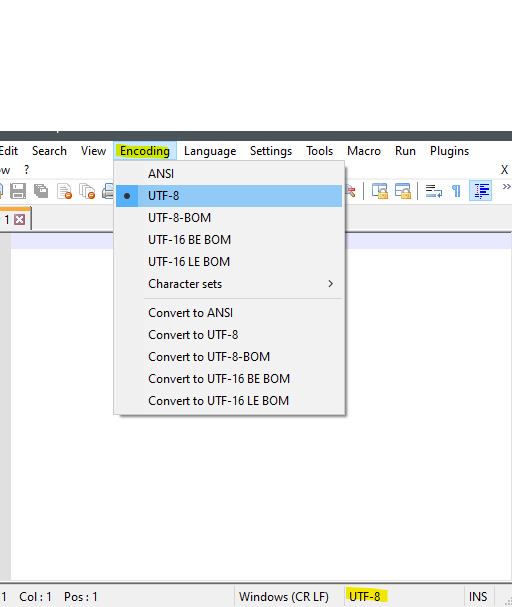
If that were the case, you could use Encoding > ANSI (note: not Encoding > Convert to ANSI) to get Notepad++ to re-interpret as ANSI (and for me, 1252).But your original screenshot showed something that looks like a non-Western character… so it doesn’t seem to be interpreting it as UTF-8. My guess is that you have a different default character set. If your status bar says ANSI (or a different character set than Windows 1252) when it’s showing those non-Western character, you might try Encoding > Character sets > Western European > Windows 1252, which would cause Notepad++ to re-interpret your file as Win-1252, which I think is what Excel uses during export (at least, it did for me… but again, my PC’s default character set is 1252, so…)

-
@peterjones
How can I send you a simple bas file -
@alfred-vachris  image url)
image url)
-
@alfred-vachris ,
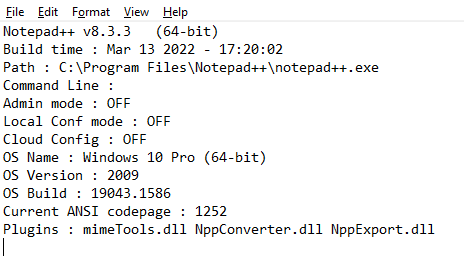
You have yet to post your debug information by copying the information from the ? in Notepad++, so the folks here can actually see what your NPP version is showing it’s using. Although anytime I see a Kanji type character my first thought is that you have a codepage set that doesn’t match one or the other applications setting that you are copying from, and pasting to. Please provide this information so they can better get a sense of what they’re working with. -
-
Remember when I mentioned the status bar? Did you notice what you left out of every single one of your Notepad++ screenshots: the status bar. It has the encoding/charset information that was required for us to give you any more information.
Your problem is that the encoding isn’t right for the file you are trying to read. But you are not telling us anything about what encoding Notepad++ thinks it is. Even if you refuse to do that, you could have tried my experiment of changing the charset
Remember when I said “I assume the latter”: I was expecting you to either confirm that assumption, or contradict it. Your silence on that matter gave no new information.
If you want us to help you, you have to answer questions we ask, and try experiments we suggest. If you refuse, you will not get your problem solved, because we are not mind readers.
How can I send you a simple bas file
This forum doesn’t host arbitrary files as a downloadable file. And my IT blocks downloads for most file sharing sites, so if you posted it somewhere else, I wouldn’t be able to grab it.
But a VBA .bas export should be a plain text file. Just copy the text from the ms-notepad window, then come into your reply, hit the
</>button, and paste your contents over the highlighted text – this will put it in a black box, like my example above where I pasted the' ———————from Notepad++ into the forum.
But when when you do that, and I paste those contents into Notepad++, I guarantee it will match what you pasted in the post… because my working theory,
as I’ve said before, is that your problem is that your copy of Notepad++ is not interpreting the bytes correctly. And until you give us a screenshot that includes the status bar, we cannot give you any more information than that.Please note: if you respond in any way that doesn’t answer all the questions and issues I’ve raised, I will assume you don’t actually want help, and will stop replying.
Good luck.
-
-
@peterjones
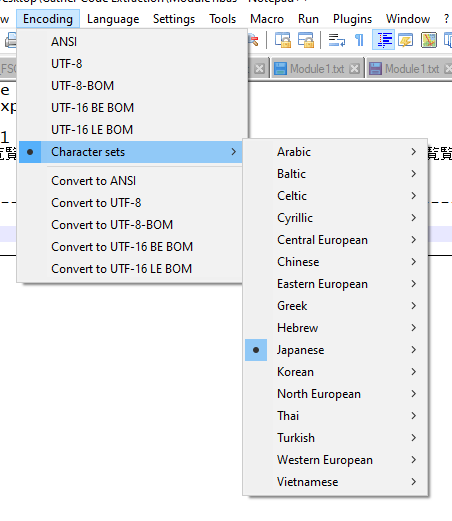
Ok, the encoding has somehow switched to Japanese?
How would this happen? -
There must be some sequence of characters in the extracted VBA code that is triggering the switch to Japanese?
-
Even though you still didn’t show me the status bar – it’s the little information row at the bottom of Notepad++ – I will give you one more gift. I am doing this because the alternate information was sufficient. I can now replicate what you see easily:

And the fix shown is something I said to try two hours ago.
My guess is that you have a different default character set. If your status bar says ANSI (or a different character set than Windows 1252) when it’s showing those non-Western character, you might try Encoding > Character sets > Western European > Windows 1252, which would cause Notepad++ to re-interpret your file as Win-1252, which I think is what Excel uses during export
But since you decided against trying what I suggested, then you didn’t get your solution then.
Ok, the encoding has somehow switched to Japanese?
How would this happen?
There must be some sequence of characters in the extracted VBA code that is triggering the switch to Japanese?This happens because you’ve told Notepad++ to try to guess the encoding in the Notepad++ options
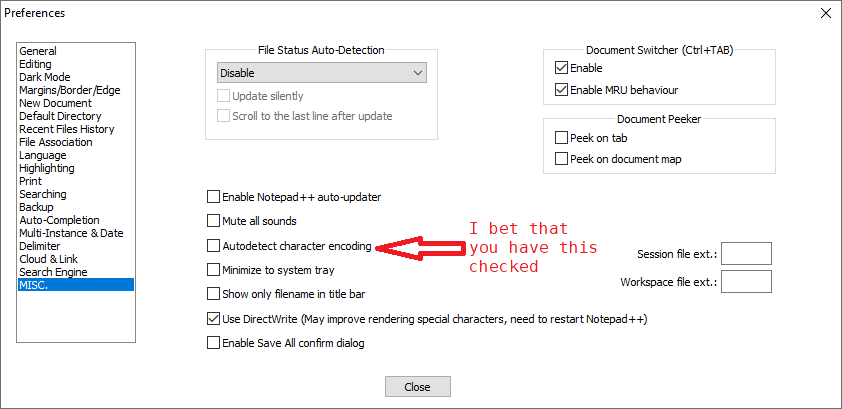
Notepad++ does its best. But some sequences of characters confuse it. As you can see, I turn that off.If you ever leave it on, if the characters show up and they don’t look like what you expect, always check the encoding (on the Status Bar, also shown in the Encoding menu, and change the encoding to match the encoding of the source file)
-
@peterjones
Thanks
You were spot on about the autodetect character encoding.
That has cleared up my problem.
Now my extracts are a thing of beauty! -
Hello @alfred-vachris, @mere-human, @peterjones, @alan-kilborn, @lycan-thrope and All,
I’m a bit late and I should had suspected, like Peter, the
Autodetect character encodingoption !Now, of course, it easy to understand all the story…
-
Start Notepad++
-
Select the option
Settings > Preferences... > MISC -
Untick, if necessary, the
Autodetect character encodingoption -
Close the
Preferencesdialog -
Open a new tab (
Ctrl + N) -
Whatever your default encoding, choose the option
Encoding > Convert to ANSI -
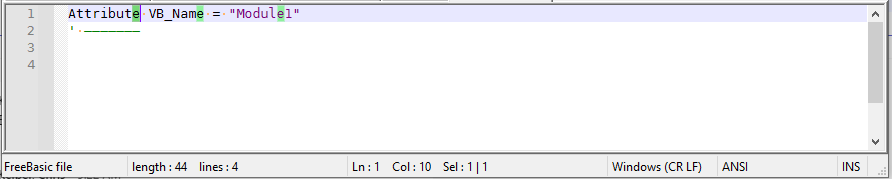
Then, insert the text below :
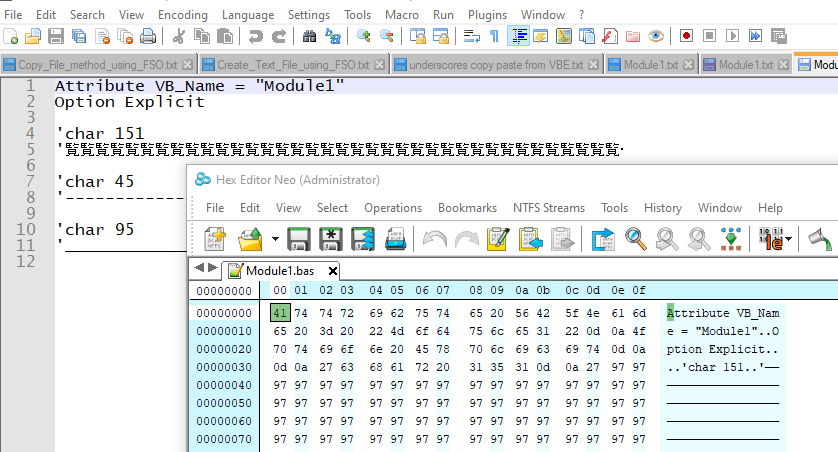
Attribut VB_Name = "Module 1" Option Explicit 'char 151 ————————————————————————————————————————— 'char 45 ----------------------------------------- 'char 95 _________________________________________- Select the menu option
View > Show Symbol > Show All Characters
Note that each line of symbols contains
41characters, followed with CRLF- Save it with the name
Test.txt
=> In the status bar, you see the expected encoding
ANSI-
Now, close the file
Test.txt(Ctrl + W) -
Select, again, the
Settings > Preferences... > MISCoption -
Tick the
Autodetect character encodingoption -
Close the
Preferencesdialog -
Restore recent closed file (
Ctrl + Shift + T)
=> This time, the line of the
41EM dash chars is replaced with a line of20identical ideograms, followed by a kind of dot and theLFchar=> In the status bar, the encoding have been changed to
Shift-JIS!How to explain this result ?
Well, the
Shift-JISencoding is a Japanese double byte character set (DBCS). This name is a bit of a misnomer as it should be called a Multi-Byte character set ! Indeed, like Chinese and Korean encodings, this encoding maps some characters with1byte and some others with2bytes.The layout of the
Shift-JISencoding is :ONE byte : 0x00 - 0x80 FIRST byte : 0x81 SECOND byte : 0x40 - 0xFC FIRST byte : 0x82 SECOND byte : 0x4F - 0xF1 FIRST byte : 0x83 SECOND byte : 0x40 - 0xD6 FIRST byte : 0x84 SECOND byte : 0x40 - 0xBE FIRST byte : 0x88 SECOND byte : 0x9F - 0xFC FIRST byte : 0x89 - 0x9F SECOND byte : 0x40 - 0xFC ONE byte : 0xA0 - 0xDF FIRST byte : 0xE0 - 0xE9 SECOND byte : 0x40 - 0xFC FIRST byte : 0xEA SECOND byte : 0x40 - 0xA4 ONE byte : 0xF0 - 0xFFand here is the complete contents of the
Shift-JISencoding :https://unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/SHIFTJIS.TXT
Now, as the hex value of the
151char is0x97, this means that it is a lead byte for theShift-JISencodingAnd it happens that, in the part :
0x9795 0x85CD # <CJK> 0x9796 0x862D # <CJK> 0x9797 0x89A7 # <CJK> 0x9798 0x5229 # <CJK> 0x9799 0x540F # <CJK> 0x979A 0x5C65 # <CJK> 0x979B 0x674E # <CJK>The
0x9797values ( first and second byte ) corresponds to the Unicode char0x89A7. This is, also, in line with the decimal value35239, used by @alfred-vachris, in the ReplaceUnicode() function :Function ReplaceUniCode() Dim Instring As String Dim CodeNumber As Long Instring = Application.Caller.Offset(0, -2) ReplaceUniCode = Replace(Instring, WorksheetFunction.Unichar(35239), “-”) End Function
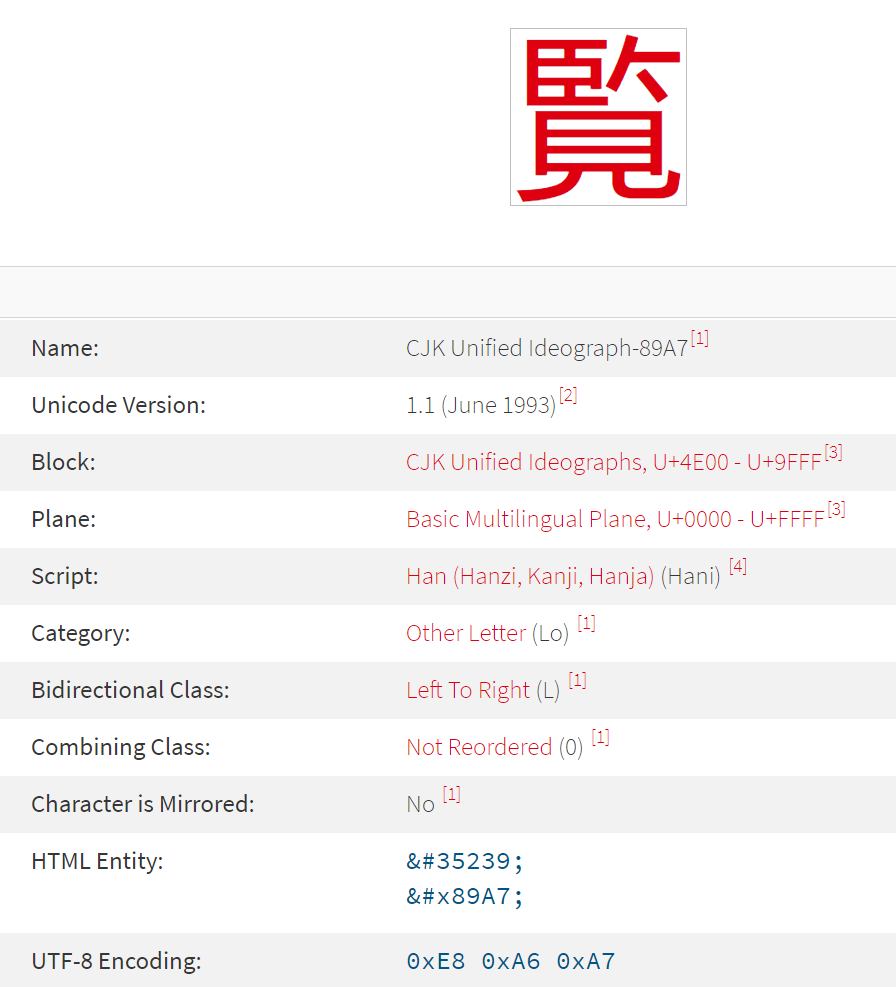
So, the first
40EM dash chars are changed into20characters0x89A7! Then, the 41th char0x97is again a leading byte which is followed by the0x0Dchar, as a second byte. However, the sequence0x97 - 0x0Ddoes not correspond to a valid char, as the correct two bytes range is from0x97 - 0x40to0x97 - 0xFC. Thus, theShift-JISuses a replacement character.By successive tries, I found out that the final “dot” char is the
\x{30FB}character ( KATAKANA MIDDLE DOT ). And, in the Unicode article :https://www.unicode.org/versions/Unicode14.0.0/ch18.pdf
it is said, at bottom of page
755:Punctuation-like Characters.
U+30FBkatakana middle dot is used to separate words when writing non-Japanese phrases.So I suppose that the
\x{30FB}char is used as the replacement char of the last unknown sequence0x97 - 0x0D, because theShift-JISencoding considers this sequence as possible non-Japanese text ?Of course, the structure of the line is preserved thanks to the EOL char
\x0A!Refers also :
https://en.wikipedia.org/wiki/Shift_JIS
Note that if you do not have the Autodetection ticked, the
ANSItext above will also show these ideograms if you normally choose theShift-JISencoding !-
Close the file
Test.txt(Ctrl + W) -
Select the option
Settings > Preferences... > MISC -
Untick, if necessary, the
Autodetect character encodingoption -
Close the
Preferencesdialog -
Restore recent closed file (
Ctrl + Shift + T)
=> The line of EM dash
\x{2014}is normally displayed=> In the status bar, you see the mention
ANSI- Choose the menu option
Encoding > Character sets Japanese > Shift-JIS
=> Again, the ideograms are present with
\x0Aonly as line-ending=> In the status bar, you see that the expected encoding is
Shift-JISBest Regards,
guy038
-