How do I find some text but skip some other slightly different text?
-
I have a block of HTML followed by text, an example of which is:-
<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'><span style='font-size:13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family: "Times New Roman";mso-bidi-font-family:"Times New Roman";color:#075296; mso-ansi-language:EN-US'>-Skin lumpy, thick, hard. Excoriations, cracks or fissures. Gluey moisture. <br> <br> Moist, crusty eruptions. Obesity. Sourness. </span><span style='font-size: 13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family:"Times New Roman"; mso-bidi-font-family:"Times New Roman";mso-ansi-language:EN-US'><o:p></o:p></span></p> </td> </tr> <tr style='mso-yfti-irow:1'> <td width=101 valign=top style='width:75.75pt;border:solid #BFDBFF 1.0pt; mso-border-alt:solid #BFDBFF .75pt;padding:3.75pt 3.75pt 3.75pt 3.75pt'> <p class=MsoNormal style='margin-bottom:0in;margin-bottom:.0001pt;line-height: normal'><b><span style='font-size:13.5pt;font-family:"Verdana","sans-serif"; mso-fareast-font-family:"Times New Roman";mso-bidi-font-family:"Times New Roman"; color:red;mso-ansi-language:EN-US'>COMMON NAME </span></b><span style='font-size:13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family: "Times New Roman";mso-bidi-font-family:"Times New Roman";mso-ansi-language: EN-US'><o:p></o:p></span></p> </td> <td width=642 valign=top style='width:481.5pt;border:solid #BFDBFF 1.0pt; mso-border-alt:solid #BFDBFF .75pt;padding:3.75pt 3.75pt 3.75pt 3.75pt'> <p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'><span style='font-size:13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family: "Times New Roman";mso-bidi-font-family:"Times New Roman";color:black; mso-ansi-language:EN-US'>-Black lead, Amorphous Carbon </span><span style='font-size:13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family: "Times New Roman";mso-bidi-font-family:"Times New Roman";mso-ansi-language: EN-US'><o:p></o:p></span></p>and the string (HTML+text) is different for each file/webpage (of multiple such files). If I try to find it with the RegEx,
(?<=mso-bidi-font-family:"Times New Roman";color:black'>)-([^<]*), the first block of HTML+text is also found which I want it to skip. The RegEx,(?<=mso-bidi-font-family:"Times New Roman";color:black'mso-ansi-language:EN-US'>)-([^<]*)finds no matches.
Please help me with a RegEx to skip replacing the first string (HTML+text) and replace only the second string (HTML+text). -
@Scott-Nielson I want to find (and replace) this,
<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'><span style='font-size:13.5pt;font-family:"Verdana","sans-serif";mso-fareast-font-family: "Times New Roman";mso-bidi-font-family:"Times New Roman";color:black; mso-ansi-language:EN-US'>-only! -
@Scott-Nielson Sorry, this,
-Skin lumpy, thick, hard. Excoriations......should be,Skin lumpy, thick, hard. Excoriations.....(the dash/hyphen got added by mistake). -
@Scott-Nielson This
(?s)(?<=<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'>).*?(?=-)RegEx finds both, despite the first string (HTML+text) not having the “dash/hyphen”. -
This,
(?s)(?<=mso-ansi-language:EN-US'>-)seems to skip the first string but is it correct? -
I also want the “dash/hyphen” to disappear after the replacement as I’m using this in the replace field:
<table style="text-align: left; width: 100%;" border="0" cellpadding="2" cellspacing="2"><tbody><tr><td align="left" valign="top"><span style="color: rgb\(0, 0, 0\); font-family: Verdana,sans-serif; font-size: 18px; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; display: inline ! important; float: none;">-</span></td><td align="left" valign="top"><span style="color: rgb\(0, 0, 0\); font-family: Verdana,sans-serif; font-size: 18px; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; display: inline ! important; float: none;">$1</span></td></tr></tbody></table> -
The “-” remains after the replacement right now!
-
I guess this RegEx,
(?s)(?<=mso-ansi-language:EN-US'>-)I used to search, is a problem - maybe the “-” should be searched for as another string. -
I spent a couple minutes looking, but I couldn’t get your initial subexpressions to match the sections you claimed they did, because the data you presented in
</>has newlines, but your regex doesn’t have any. If you want help, you need to make it easy for us to help, by just copy/paste. If we cannot easily copy/paste to be able to replicate your problems and attempts, we aren’t going to be motivated to help you.For example, your example data has the following, where i have searched for “black” to highlight those

but the regexes you showed

would never be able to match. Either regex would requirecolor:blackto be followed by a single-quote'… but the only place in your example data that hascolor:blackis followed immediately by a semicolon and a newline and a couple spaces. That is obviously not going to match. The only way you are going to get complicated regex to work is to make sure you understand how to get every individual piece to work, and then spend the effort to join them together. If you’re going to ask for help, it’s your job to make sure that the data comes across correctly to us.(And again, like I hinted in one of my previous replies to another of your HTML-regex questions, I recommend against using MSWord or similar for generating your HTML; it creates horrible HTML where it embeds the same styles in every paragraph, because it doesn’t generate a stylesheet or use classes, so it has tons of redundant information. If you are stuck fixing the HTML that someone else created with MSWord, I am sorry; but using regex to slowly fix it is going to take you forever, and you are going to have a hard time crafting things to fix all the oddities that were put in with all that mso-junk. And unfortunately, your replacement strings are indicating that instead of removing repetative cruft, you are adding in more repeated HTML styles rather than using classes, making the future maintenance even more difficult. This is a bad idea. I know you didn’t ask for that advice, but you need to hear it.)
Moving on,
This
(?s)(?<=<p class=MsoNormal style='margin-bottom:12.0pt;line-height:normal'>).*?(?=-)RegEx finds both, despite the first string (HTML+text) not having the “dash/hyphen”.What do you mean that one has a hyphen and the other doesn’t? They both have
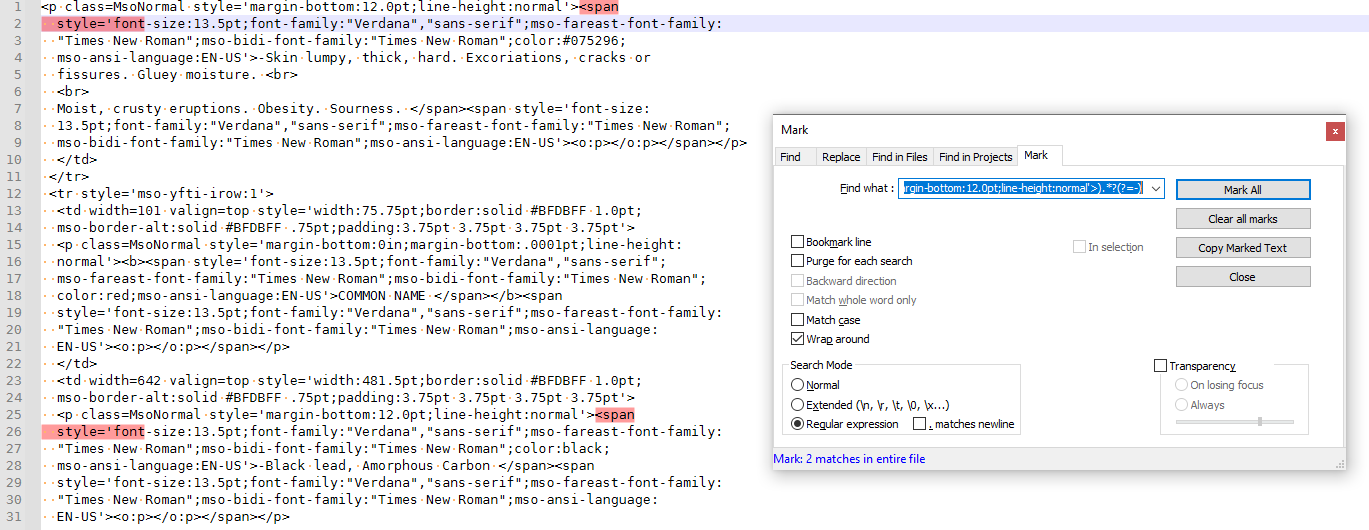
<span style="'font-, which has a hyphen right afterfont. That’s the hyphen that’s being matched.If you learn to use the FIND NEXT button in the FIND tab of that dialog, or even better, the MARK ALL button in the MARK tab of that dialog, you will have a better idea of where the strings are actually matching, so you can figure out why it’s not working.
I guess this RegEx,
(?s)(?<=mso-ansi-language:EN-US'>-)I used to search, is a problem - maybe the “-” should be searched for as another string.Well, the
-is in the lookbehind, so it must be matched, but it’s not considered part of the match, so it won’t be eliminated by the replacement. So if you want that hyphen eliminated by the replacement, then it cannot be in the lookbehind. -
@PeterJones Sorry, I did not update the solution that worked for me here. I put this in the “find” field:
(?s)(?<=mso-ansi-language:EN-US'>)-(.*?) *(?=</span>)and this in the “replace” field:-
<table style="text-align: left; width: 100%;" border="0" cellpadding="2" cellspacing="2"><tbody><tr><td align="left" valign="top"><span style="color: rgb\(0, 0, 0\); font-family: Verdana,sans-serif; font-size: 18px; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; display: inline ! important; float: none;">-</span></td><td align="left" valign="top"><span style="color: rgb\(0, 0, 0\); font-family: Verdana,sans-serif; font-size: 18px; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; display: inline ! important; float: none;">$1</span></td></tr></tbody></table> -
@PeterJones How do I skip replacing a “hyphen” or “dash” if the </span> is immediately after the “hyphen” or “dash” (for what I’ve posted right at the top)? Please tweak the RegEx so that it skips it. Thanks in advance for your help!
-
If you want to require at least one character after the hyphen, then why not make your regex require “1 or more” characters instead of “0 or more” characters after the hyphen: specifically, change
(.*?)to(.+?)-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
-
@PeterJones Like you said, I used the RegEx,
(?s)(?<=mso-ansi-language:EN-US'>)-(.+?) *(?=</span>)and that skips finding the immediate next </span> and finds the next one but I want the RegEx to skip replacing a “hyphen” or “dash” if the </span> is immediately after the “hyphen” or “dash” (without any space in between) which means the (.+?) is not needed here. There’s a difference between “finding” and “replacing”. Please help! -
@PeterJones When this is found:
-</span>), with no space in between, no replacement should happen. -
@Scott-Nielson said in How do I find some text but skip some other slightly different text?:
(.+?)
change
(.+?)=>((?:(?!</span>).)+?)– this gets complicated, and you will need to study the manual and play with it to fully understand. But basically, the(?!</span>)is a negative lookahead saying that the next characters cannot be</span>, but doesn’t grab any; then the.following grabs the first character that doesn’t start</span>. Then the()+says continuing doing this (grab one character as long as it isn’t the start if</span>) as long as I can. -
This post is deleted! -
@PeterJones Like you said, I used the RegEx,
(?s)(?<=mso-ansi-language:EN-US'>)-((?:(?!</span>).)+?)and that finds the hyphen/dash and the immediate next character (which is not what I want). I think, we need a RegEx with a (SKIP) in it. -
You got rid of parts of your previous regex which I didn’t say to remove, which my answer assumed would still be used. If you really need SKIP, you’ll have to wait for someone else, because I have never understood it. But I personally don’t think you need it.
DATA =
mso-ansi-language:EN-US'>-blah blah blah</span> <!-- yes this one --> mso-ansi-language:EN-US'>-</span> <!-- not this one --> mso-ansi-language:EN-US'>- </span> <!-- unsure about this one -->FIND =
(?s)(?<=mso-ansi-language:EN-US'>)-((?:(?!</span>).)+?) *(?=</span>)
That seems to match what you said, where you want it to not match if it’s
-</span>with no space between; you weren’t clear whether it should match with a space in between; the one I had intended you to use (which I just showed) assumed one with hyphen space span should match, like in my screenshot. If not, then tweak it again to not allow spaces before the spanFIND =
(?s)(?<=mso-ansi-language:EN-US'>)-((?:(?!\h*</span>).)+?) *(?=</span>)
At this point though, if you want more help, you will have to do a better job showing your problem – what you have, what you get, and what you actually want, without irrelevant bits – and do a better job of doing what we suggest; you will also have to wait for someone who knows FAIL, and has the ability to answer in ways that you will understand – so you’ll have to have patience while waiting for someone else to show up.
-
@PeterJones The RegEx you gave me worked like a charm and I’m happy with it but if someone does post about how to use SKIP and FAIL, it’d be nice.
-
For what it’s worth, here are some links I’ve collected which discuss
(*SKIP),(*FAIL), or both:- https://community.notepad-plus-plus.org/post/55467
- https://community.notepad-plus-plus.org/post/60429
- https://community.notepad-plus-plus.org/topic/20432
- https://community.notepad-plus-plus.org/post/64421
- https://community.notepad-plus-plus.org/post/60332
- https://community.notepad-plus-plus.org/post/60220
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login