add text to even lines
-
hi everybody, i have a long txt and i need to add some text only to even lines. how to?
example:
#summer
0000-gold
#summer
0001-gold
#summer
0002-goldi need to have:
#summer
text/0000-gold
#summer
text/0001-gold
#summer
text/0002-gold -
Find:
(#summer\n)(.+)
Replace:$1text/$2 -
Oooh, that’s not great. :-(
Why?
-
summerwas not in the requirements (much better would have been a requirement – of the solution – to move the caret to top of file before running, and thus the solution could take care of the “even lines” requirement) -
\nis not good – if this file has windows line-endings, it isn’t going to work – use\Rinstead -
there’s no specification to use regular expression search mode
-
there’s no specification to make sure that
. matches newlineis unticked (and no usage of a leading(?-s)on the find expression)
-
-
@lycan-thrope said in add text to even lines:
Find: (#summer\n)(.+)
Replace: $1text/$2yes, this command does not work
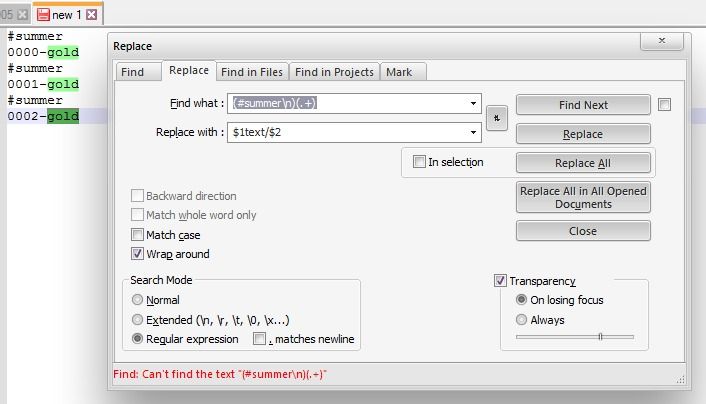
-
I would change the
\nfor\Ras we don’t know the format of the text file in terms of CR (carriage returns) and/or LF (line feeds) for line endings. This covers both bases.But; as in most cases; I suspect the example provided isn’t actually a good representation.
When using a regular expression and selecting “Replace All” AND “Wrap around” the expression WILL start at line 1. So a regex that captures 2 lines will do so in the same manner requested. This was explained in a series of posts here provides a link to those.
For example
(?-s)^(.+\R)(.+\R?)will capture line 1 & 2. Then the next iteration will capture 3 & 4 and so on. The\R?is so the last line which will not have a CR and/or LF will still be captured.There is another method of determining the even numbered lines which involves some steps including adding numbers to the start of each line, as this would require placing the caret in the first position of the file we guarantee correct line placement. Each number would be repeated, so it shows twice, like 1 1 2 2 3 3 4 4… . Then a regex would remove the first one of the pair. The next regex could then identify the added number which references the “even” numbered line and use that as a key to edit the correct line. Lastly the added numbers could be removed. This is a much more involved process and I think unneeded as the “Replace All” and “Wrap around” option will work as intended.
Terry
PS my example regex assumes data on each line
-
thank you to all for replies
anyway, thank to suggestion by Alan Kilborn, the string by Lycan Thrope work fine with simply replace:
find what: (#summer\R)(.+)
replace: $1text/$2 -
another question: from my long txt file, i have found some different value. sometime i have:
#summer:4, 0000-gold #summer:4, 0001-gold #summer:5.625, 0002-gold #summer:4, 0003-gold #summer:7.2, 0004-goldand i need to have:
#summer:4,
text/0000-gold
#summer:4,
text/0001-gold
#summer:5.625,
text/0002-gold
#summer:4,
text/0003-gold
#summer:7.2,
text/0004-goldonly the first part are the same #summer:
so, i have try with:(#summer:\R)(.+)
replace: $1text/$2but this command does not work. how to?
-
if this question it’s hard to get, another solution could be to look on my txt all the values that do not correspond to #summer:4, (as in the case of #summer:5.625,)
this would be enough for me
-
Hello, @cisco779k, @lycan-thrope, @alan-kilborn, @terry-r and All,
The correct regex, in this case, is :
SEARCH
(?-s)^(#summer:.*\R)(.+)REPLACE:
$1text/$2
This search syntax will work, either, with lines
#summer:....and lines#summer!Best Regards,
guy038
-
guy, thank you so much for your string. it work like a charm
all the best
-
G GabrielP referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login