autoCompletion Issue
-
Good day (or night :) Greetings from Colombia.
I typed the commands and keywords of a language in uppercase and the functions and methods in lowercase (camelCase), but even though the language is not case sensitive and the tag
<Environment ignoreCase="yes"..../>, the lexer forces me to to type the commands in uppercase and the functions in lowercase as they are in the languageX.xml file in the notepad++\autoCompletion folder when the idea is that, it does not matter if the keywords are in uppercase in the file, the lexer recognizes it, if I start typing them in lowercase and vice-versa for functions. What would prevent me from constantly changing from uppercase to lowercase on the keyboard.I appreciate any suggestion :)
-
@José-Luis-Montero-Castellanos
If I understand correctly, this works for me.
For example, when using SQL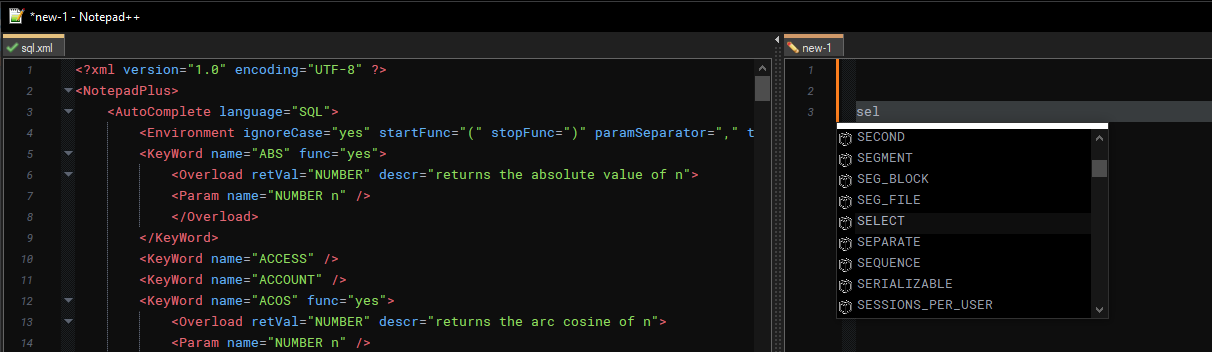
Can you give it a try with SQL?
-
@José-Luis-Montero-Castellanos ,
Besides any help you get from @Ekopalypse , when I was doing my autoCompletion for the dBASE Plus language with similar issues as yours, I worked around the problem by duplicating in upper and lower case in the autoCompletion file, the commands and keywords, (and methods and functions)
Unless something else was able to be done, that’s how I had to overcome that issue. It was a PITA, but I had to do it that way. :-)
In addition, if you do this, you need to read the documentation for doing an autoCompletion file, because if you do upper/lower cases, you have to insert them in the file in the proper order…not having the manual open right now, just checked my file, and what you have to do is put them all caps first, and lowercase below all the caps list. If you don’t the list won’t work at all, and that’s the PITA part I mentioned, because I tried to use them with overloads in the same order alphabetically, but it needed to be done lexicographically. :)
I’m not sure how you would make camelHumped wording work, so it may be even more complicated…maybe inserting them in the proper order…which I’m not sure how that would workl :(
Good Luck.
-
@José-Luis-Montero-Castellanos ,
If the autocompletion file is set to ignore case, you do not have to have both versions in there.
As @Lycan-Thrope says, the manual explains that the KeyWord entries should be sorted according to the ignoreCase setting: if ignoreCase is yes, then Sort Lines Lex. Ascending Ignoring Case, or if no use Sort Lines Lexicographically Ascending. (The “sorting” section of the manual was written before there was the ignore-case sort option native in Notepad++… I should really fix that.)
But there has been recent discussion here, where I seem to have slightly different results on the sorted version of the KeyWord list than others. And @Lycan-Thrope just claimed behavior that said the keywords had to be duplicated in different cases. I have never seen the odd behaviors (as long as keywords stay restricted to alphanumeric).
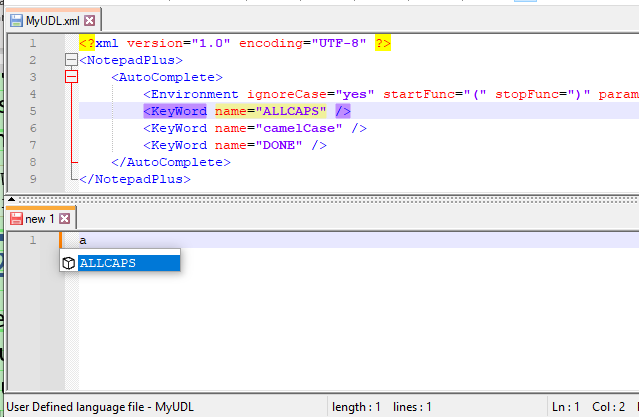
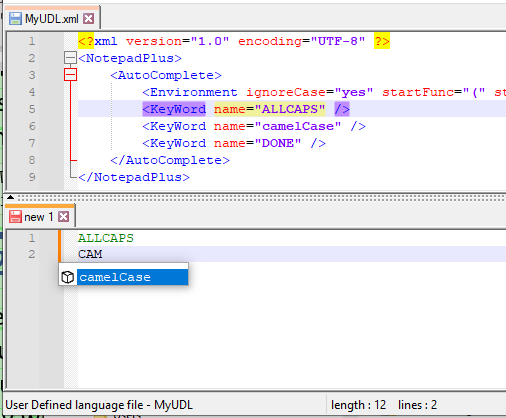
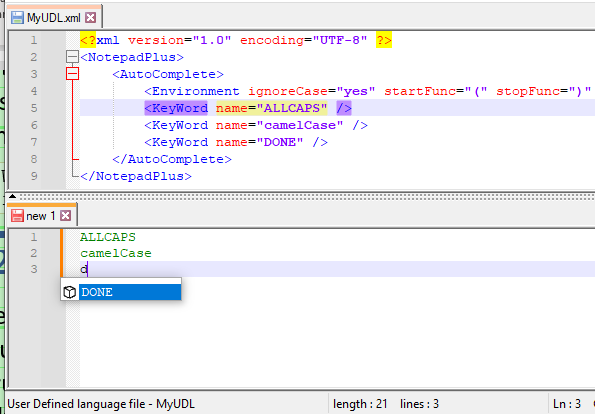
I’d love it if someone were to post a minimalist autocompletion file, akin to my MyUDL.xml, but that shows a problem where auto-completion doesn’t work
<?xml version="1.0" encoding="UTF-8" ?> <NotepadPlus> <AutoComplete> <Environment ignoreCase="yes" startFunc="(" stopFunc=")" paramSeparator="," terminal=";" /> <KeyWord name="ALLCAPS" /> <KeyWord name="camelCase" /> <KeyWord name="DONE" /> </AutoComplete> </NotepadPlus>Please note:
- as short as possible to show the problem
- no hyphens, underscores, or other non-alphanumeric in the keyword name (for now)
- screenshots to prove it’s not working would be helpful. Remember to restart Notepad++ after editing MyUDL.xml, to make sure the changes are read. Keep the Status Bar, shown, so we can see that the UDL is actually selected
- please include ?-menu Debug Info
- I couldn’t get it to have an effect on completion, but maybe checkmarking the Language > Define Your Language > ☑ Ignore Case option for your language will help you.
-
@Lycan-Thrope
Thanks:
Precisely I am working on xBase, a derivative of dBase called HMG or Harbor MiniGUI, I want to clarify that if a command like BROWSE, I registered it in the file in uppercase.<KeyWord name="BROWSE"/>And I want it to be returned or auto-completed in uppercase, because it seems appropriate to me to keep commands or keywords in uppercase.
My idea has more to do with keyboard input, it doesn’t matter if I write “browse” in lowercase, the Lexer recognizes it and returns it to me in uppercase “BROWSE”.
Anyway, I’ll take your suggestion into account.
-
@Ekopalypse
Good day.
I’m going to take a look at the sql.xml, see what I can deduce from it. The language is a derivative of SQL, it’s dBase, I think you know it. -
@José-Luis-Montero-Castellanos
Hello, first of all, thank you for your contribution.As I told my friend @Lycan-Thrope, My idea has more to do with keyboard input, that it doesn’t matter if I type “browse” in lowercase, The Lexer should recognize it in the hmgui.xml (language autoComplete) file and return it to me in uppercase letters “BROWSE”.
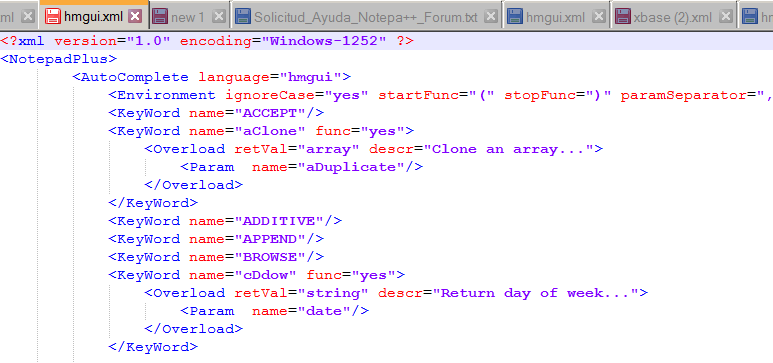
It seems that the
<Environment ignoreCase="yes".../>attribute has more to do with pleasing the language compiler than with making typing and auto-completion easier.As you can see the ordering is valid -> ACCEPT, aClone, ADDITIVE, APPEND, BROWSE and cDow.
Finally, ? Debug
Notepad++ v7.9.2 (32-bit) Build time : Dec 31 2020 - 03:58:36 Path : D:\PR\Notepad++\notepad++.exe Admin mode : ON Local Conf mode : ON OS Name : Windows 7 Ultimate (64-bit) OS Build : 7601.0 Current ANSI codepage : 1252 Plugins : mimeTools.dll NppConverter.dll NppExport.dll -
@José-Luis-Montero-Castellanos said in autoCompletion Issue:
Notepad++ v7.9.2 (32-bit)
There’s a problem. There was an auto-completion ignore-case bug that was fixed in v8.0. So v7.9.2 will have that bug. You will have to update if you want a chance of it working.
-
@PeterJones
Hello,
I read your suggestion on Tips for a correct sorting - I installed the most recent version of Notepad++ and it works fine for me, as I wanted (Thank you very much! :). The version I had,v7.92latest for XP was to be able to run the program from multiple partitions (different windows systems).Now, I have to install Notepad++ twice, once for XP and once for (Win7 - 10) . Fortunately, it does not take up much space.
I wish you the best in your work, good day.
-
To be fair, I believe I was creating that UDL before the 8.0 versions, and the problem was existent then to me, as dBASE, FoxPro, the one the OP mention, all use caps for command words, if you follow the language’s typographic style. Many of the commands were from when dBASE was simply a procedural language, but when it became OOP, it became a bit more nuanced as the following snippet shows:
DELETE is a command delete is a property DELETED( ) is a function delete( ) is a methodThe language itself is NOT case sensitive, so my attempt was to make the UDL not work counter to the programmer’s style. Some kept the typographical style, others didn’t and I didn’t want to force a change of it, since dBASE Plus the OOP version, can still be used with some of the older langauge commands and such. Though internally many have been made OOP, they allow programmers of the language to still use the “procedural” commands in the environment.
In light of your showing the camelHump style, I may have to revisit this issue later, but when I finished, it was done that way to not interfere with the programmer’s choice of how the UDL should respect their choice of case, upper or lower.
When I was doing the UDL, the multi word commands also had to be done lexicographically and in case order, at the beginning of the file, because of the included hex codes to enable it to be sorted properly using the required separation of
 between words and have them sorted and chosen.When I did the UDL, that’s the way I ended up having to arrange things with the ignoreCase=“no”
This is the command section at the top of the file, where that sequence is used for multi-word commands and switches from the upper case to the lower case versions. After the special characters were done, then the continuation of the alphabetical upper and then lower case were done for the single word commands and function from there also.
<KeyWord name="SET SKIP"/> <KeyWord name="SET SPACE"/> <KeyWord name="SET TIME"/> <KeyWord name="SET UNIQUE"/> <KeyWord name="SET VIEW"/> <KeyWord name="STORE AUTOMEM"/> <KeyWord name="UPDATE ON"/> <KeyWord name="alter table"/> <KeyWord name="append automem"/> <KeyWord name="append from"/> <KeyWord name="append from array"/> <KeyWord name="append memo"/> <KeyWord name="clear all"/>Like said, I did the dual list in order so as not to change the way the programmer chose to type his case style.
-
@José-Luis-Montero-Castellanos ,
As I mention in my response to Peter, besides the base language of the procedural elements, I also had to work with the aspects of dBASE Plus being an OOP language but still being able to use the older commands in programs also. My problem, however, was that I did not want to force the typographical style on the programmers, because the language as you know is NOT case sensitive…at least dBASE wasn’t, so since the language has expanded it didn’t make sense to try and force a case insensitive language to act like a case sensitive language enforced editor. So to keep the choice with the programmer, I duplicated the keyword and function completion list with the
ignorecase = nosetting, and left the choice of case typing to the programmer while also making them available in either typed format.I’m glad Peter’s help has perhaps solved your problem, for you. God luck.
-
To be fair, I believe I was creating that UDL before the 8.0 versions
Glad you were able to work around the bugs that were present before v8.0.
If you need to use older N++ for unknown reasons, or if
ignoreCase="yes"gives you more flexibility in some dimension even though it requires you to duplicate keywords in various cases, then feel free to keep doing it in that way, even in v8.0 and beyond.My only intention with my brief assessment was to explain that indeed, there was a bug related to
ignoreCase="yes"prior to v8.0, and that if anyone wants the properignoreCase="yes"behavior in Notepad++ auto-completion, they need to use v8.0 or newer. -
Thanks again.
Although I was able to solve the problem, your last suggestions still work for me, for example, I didn’t know how to insert spaces where I needed them in commands like “SET ALTERNATE TO” - I had replaced it with the underscore_(SET_ALTERNATE_TO) which would later remove. I’ll try with and then I’ll tell you :) -
@José-Luis-Montero-Castellanos said in autoCompletion Issue:
I had replaced it with the underscore
_(SET_ALTERNATE_TO) which would later remove. I’ll try with That will just mean instead of having to later remove the
_after auto-completion is done, you would have to later remove the non-breaking-space (U+00A0) – maybe with FIND =\xA0and REPLACE =\x20and mode = regular-expression (or type a space in the replace string, but that cannot be copy/pasted from the forum). Well, unless your language happens to treat the non-breaking-space character the same as other whitespace (like space or tab) between code tokens. I haven’t seen a language that accepts nbsp as a token-separator, but that doesn’t mean it doesn’t exist. -
Good morning.
What I understand is that I have to do the manual work of search and replace in the same way, since the space is understood to be visible, but different from\x20. I have to try compiling with\xA0to see what happens or find another solution. Or make a request to the Npp programmer to see if it’s possible or keep it in mind, Which would also work for SQL and derivatives.I was surprised by your quick response :) Thank you…
-
@José-Luis-Montero-Castellanos
I suppose that a script that converted
\xA0characters to\x20on every user save might be handy? -
@Alan-Kilborn , Hi :)
I guess so, I was thinking of an Npp macro, good use of RegEx, a keyboard shortcut, and leave the manual work for writing the code. -
@José-Luis-Montero-Castellanos said in autoCompletion Issue:
I was thinking of an Npp macro, good use of RegEx, a keyboard shortcut
True, but then you have to remember to run it.
With a script it becomes just something that tags along when you save.
But also, you could include “save” as the final action in your macro, and just replace the default Ctrl+s save functionality with the running of your macro (to make it no-brainer automatic). -
@José-Luis-Montero-Castellanos ,
You’re welcome. I mentioned that particular aspect because that was maddening to me when I was building the autoCompletion list, and trying to keep them sorted and in some kind of consistent order, because when I was building it, one sequence out of order and the list would refuse to run. :(Here’s a screenshot of that part of “Set” keywords in the autoCompletion dropdown list so it shows and inserts what you see, without any additional cleanup code:
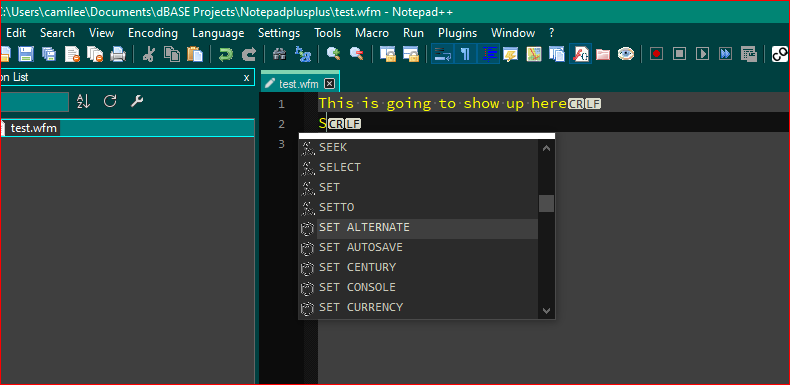
It took a lot of work with @PeterJones, @guy038 , @Alan-Kilborn , @Ekopalypse and others to learn all the nuances at the time that had to be overcome to make the language work with many of the features available in NPP for a UDL, short of building a lexer for it, like you’re doing now. :)
-
@José-Luis-Montero-Castellanos ,
Here’s an additional screenshot, showing it using the lower case display:
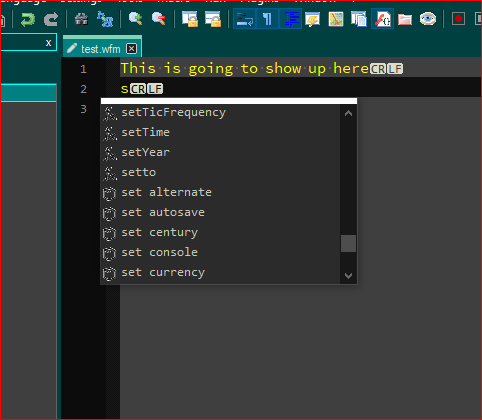
Notice that the list isn’t the same, because some functions and methods used in the OOP version, don’t have capital counterparts, because when they’re used, they usually get inserted after a
., which doesn’t happen with strict procedural parts of the langauge, so if someone typed, for instance theSETcommand, and then a period, it wouldn’t show in the dropdown box, because there is no existent equivalent in the language. However if someone created one, then it would show in the dropdown list as previous words in the document, and allow them to reselect it. It took a while to figure out how to make NPP capabilities and dBASE’s OOP language extensions work together without forcing strict adherence to typographical conventions. :)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login