How do I replace a particular sentence across multiple files?
-
@Scott-Nielson
Good afternoon :
There is an even shorter form, is the\ℕin the replacement field: whereℕis1digit from 1 to 9.Replace with: \1\2The forms ${1}${2}…
${ℕ}are useful when the capturing group exceeds 9 for example${10}“two digits!”. But each reference uses two more characters.Success doing the test :¬)
-
@José-Luis-Montero-Castellanos said in How do I replace a particular sentence across multiple files?:
There is an even shorter form, is the \ℕ in the replacement field: where ℕ is 1 digit from 1 to 9.
Whilst that is correct it also introduces some uncertainty, especially when someone new to regular expressions sees the “\1” form and also the “${10}” form. Also when you see “\10” it can lead to confusion, is it really only group 1 or group 10.
I myself learnt on the “\1” form but have; like most seasoned regex creators on this forum; changed to the “${10}” form as one can be consistent across all solutions provided and it is unambiguous. Given the Replace field is certainly long enough to cater for even the MOST complex of replacements, saving a few characters doesn’t make up for the confusion it can sometimes create.
Terry
-
@José-Luis-Montero-Castellanos ,
The underlying Boost regex documentation does not actually guarantee that
\ℕwill work in REPLACEMENT, as that syntax is only technically defined in the SEARCH syntax; that means that Boost regex would be within their rights to drop support for\ℕin replacements at a whim, without any notification. As such, I argue against the usage of\ℕin replacements.Further, while both
$ℕor${ℕ}are documented both by Boost and in the Notepad++ User Manual, the regulars in the forum tend to recommend${ℕ}, especially to newbies, because that way if the user ends up making a 10th group or beyond, they won’t have to change the notation that they learned. (And @Terry-R expounded on the ambiguities involved while I was typing this up, so I won’t go into any more on that.) -
@Terry-R
Hello:
That was why I specified that thebackslash \is only used with numbers from 1 to 9 because it is understood that the escape\character is only followed by a single character in aescape sequence. And that helps reinforce that basic RegEx knowledge. Not only functional or applicable in Npp or Boost but in a wider field.I also think there are two or three more ways to do this task. I have only shown the
"reduced"or"simplified"form.And most of the time you do not get to accumulate many capturing groups that exceed 9, the most common is 2 or 3. In this help thread! = 2.
Did you do the test? Had success?
Anyway it is good, to share broad views :)
-
@José-Luis-Montero-Castellanos The
\1\2works but I will stick to what has been advised above! Thanks a lot to all of you @Alan-Kilborn @José-Luis-Montero-Castellanos @Terry-R @PeterJones -
Is this the best RegEx to use in this case:
(?=Please\K\s*E-mail)\K([\S\s]*?treatment)? -
@Scott-Nielson said in How do I replace a particular sentence across multiple files?:
Is this the best RegEx to use in this case: (?=Please\K\sE-mail)\K([\S\s]?treatment) ?
I applaud you for trying something, but it appears more like you have just added in stuff until you got it to work, rather than fully understand what it is you are creating. Do you understand what the
\Kdoes, or even the[\S\s]?Your use of ${1} and ${2} in an earlier post suggests you think the lookahead is the first capture group, it is not.
I was doing a bit of work on your request, and although I haven’t yet completed it I will show you what I have thus far.
(?-s)(Please)(?:(\s|\R)+)(E-mail)(?:(\s|\R)+)(.+?(?:(\s|\R)+)?treatment)Now it isn’t finished as I think you need to elaborate on exactly the formats your text will present as. From that a better regex can be produced. But my initial Find expression above covers these scenarios:
Please E-mail .............. treatment (a <p........> string)Please E-mail ............treatment (a <p........> string)Please E-mail ............treatmentTerry
-
@Terry-R I understand that a
\Kwil help stop finding/matching text or something else that follows at that point and\s*is to find what follows even if it is on the next line. The RegEx you gave just above is Greek to me but it does not find the very first instance of the text,Please
E-mail
blah blah blah blah blah blah blah
treatment
I hope you can help find/match that also.
I also observed that there are now 5 capture groups -
@Terry-R
\sand\S, equate to “match any whitespace” and “match any non-whitespace” respectively. That is, if you specify[\s\S], your regular expression will match any one character, regardless of what it is, and if you use[\s\S]*your regular expression will match anything. -
Please E-mail .............. treatment (a <p........> string)Please E-mail ............treatment (a <p........> string)Please E-mail ............treatmentafter replacement, should become:
<b>Please E-mail .............. treatment</b> (a <p........> string)<b>Please E-mail ............treatment</b> (a <p........> string)<b>Please E-mail ............treatment</b>That means, I want a
<b>and</b>to be added on either side of the text I posted above, in this “reply” to you -
You keep on changing your spec. At some point, you need to start learning how to do it yourself rather than asking a particular Community member to keep editing all the free regex they’ve already given you.
Give it a try. Read the docs. Ask specific questions if you don’t understand specific syntax.
-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
-—
Useful References
-
@PeterJones I could only think of this RegEx:
(?=Please\K\s*E-mail)\K([\S\s]*?treatment)which may or may not be the appropriate RegEx (but it works) - I asked if that is best which is why @Terry-R responded. I am waiting for his response. You may also reply. Like I said, I want to add<b>and</b>on either side of what is searched for. -
Peter was trying to say that this is a place for giving you some hints in the right direction, not solving your exact problem for you, then you change the problem and someone solves that exact problem, then you change the problem yet again…
For the regulars here, this gets boring fast, and they are less and less likely to provide the requested stuff. For example, I’m already very bored with this thread and will be “clicking thru” it as more posts are added.
It’s about the power of learning, after you receive some pointers in the right direction. If you can show that you’ve learned something and have a nuancy follow-up question about something specific, that is well-tolerated.
But continuously changing/growing the problem and expecting a ready answer for every tweak is probably not going to get you far.
but it appears more like you have just added in stuff until you got it to work, rather than fully understand what it is you are creating
That’s a problem, too.
-
@Scott-Nielson said in How do I replace a particular sentence across multiple files?:
Like I said, I want to add <b> and </b> on either side of what is searched for.
Like the other members, it is hard helping you if you keep changing the criteria. However I will oblige with 1 further solution.
But first, you need to understand that while we will help, we won’t keep supporting every little change you make to the request. So before I provide a solution (as I see it) I need from you:
- Every type of variety of line format you are looking for.
- The required solution for each variety. Maybe this just means saying “I want the line(s) selected to be returned as is with the <b> at the start and </b> at the end”. At least that’s what your recent reply to my interim solution seems to state.
And as we talk about my interim solution, I find that it does select the first of those 3 varieties. See this image:
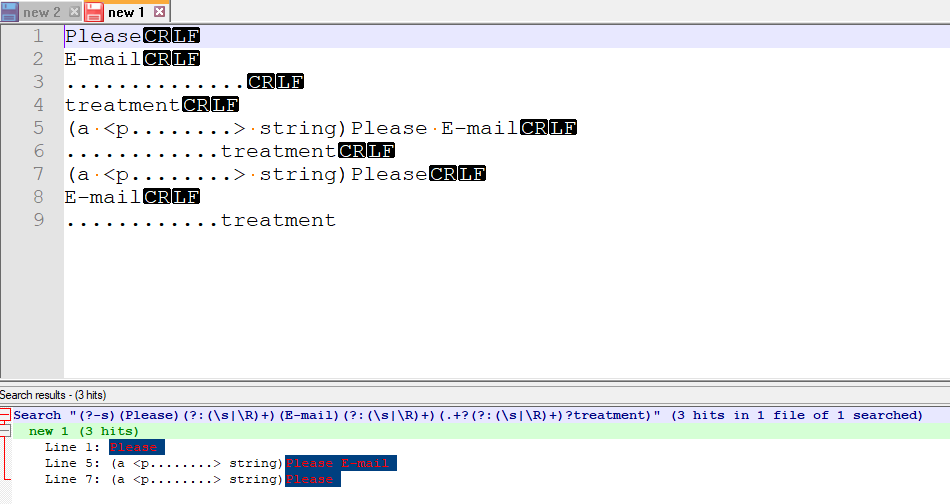
Terry
PS maybe as you saw it you weren’t changing the criteria, but you certainly weren’t telling us the whole story. Having to extract information is very hard and is another reason why we just give up helping some posters!
-
Hello, @scott-nielson, @terry-r, @alan-kilborn, @peterjones and All,
Referring to your post, where you showed us your given BEFORE data and your expected AFTER data, I’ve got a very simple solution !
So, given your INPUT text, below :
Please E-mail .............. treatment (a <p........> string)Please E-mail ............treatment (a <p........> string)Please E-mail ............treatment I even ADDED this case : (a <p........> string)Please........E-mail............treatment..............-
Open the Replace dialog (
Ctrl + H) -
SEARCH
(?s)Please.+?E-mail.+?treatment -
REPLACE
<b>$0</b> -
Uncheck all BOX options
-
Check the
Wrap aroundoption -
Check the
Mach caseoption, if necessary -
Select the
Regular expressionsearch mode -
Click once on the
Replace Allbutton or several times on theReplacebutton
You should get your expected OUTPUT text :
<b>Please E-mail .............. treatment</b> (a <p........> string)<b>Please E-mail ............treatment</b> (a <p........> string)<b>Please E-mail ............treatment</b> I even ADDED this case : (a <p........> string)<b>Please........E-mail............treatment</b>..............Best Regards,
guy038
-
-
Thanks a lot @guy038 - you made my efforts fruitful!
-
@guy038 said in How do I replace a particular sentence across multiple files?:
SEARCH (?s)Please.+?E-mail.+?treatment
REPLACE <b>$0</b>
I initially thought it would be that simple, but then considered the following (admittedly possibly not real-life examples):
Please E-mail .............. treatment (a <p........> string)Please E-mail ............treatment (a <p........> string)Please E-mail ............treatment Please mail ............eatment Please E-mail ............treatment Please E-mail ............reatment Please E-mail ............treatmentSo the regex is forcing to be true, so it will expand until it DOES find the required text. So I was thinking of using
(?s)and also.{1,5}to limit the expansion. It does seem a bit rough but might be enough to limit the regex to ONLY what it should capture.Admittedly one thing that was lacking in the OP’s original request was what they wanted to do with it. The multiple scenarios with possible CR/LF’s in between (or not) complicates matters.
Terry
-
@Terry-R said in How do I replace a particular sentence across multiple files?:
The multiple scenarios with possible CR/LF’s in between (or not) complicates matters.
For what it’s worth, I continued down the road with my idea. This solution will prevent finding occurances of “Please” immediately followed by something which is NOT the text sought, but is followed by another occurance of the “Please…treatment” text to be found. As examples see:
Please E-mail .............. treatment (a <p........> string)Please E-mail ............treatment (a <p........> string)Please E-mail ............treatment Please find attached ............travel Please E-mail ............treatment Please E-mail ............find me Please E-mail ............treatmentNote there are 2 situations in the above example where “Please” is followed by something other than the text required. My solution will prevent an incorrect capture to occur.
Find What:
(?-s)Please(.+)?\R?E-mail((.+)?\R?){1,2}treatment
Replace With:<b>${0}</b>So the OP can understand the regex:
(?-s)= do not allow any.to include the CR and LF (carriage return and line feed)
Please(.+)?\R?= Find “Please” followed by possibly some characters excluding CR and LF, and then maybe a CR and LF
E-mail((.+)?\R?){1,2}= Find “E-mail” followed by possibly some characters excluding the CR and LF and then possibly a CR and LF, allowing this set to occur once or twice. I haven’t fully tested but{2}maybe OK as well.
treatment= complete the selection with the word “treatment”
and in the Replacement field the${0}refers to everything that has been found/selected.Of course if the OP’s files will ONLY ever include the word “Please” once there isn’t a reason for them to return to read this.
Terry
-
Hi, @terry-r,
Of course, in absolute terms, you’re quite right about it ! But I would say that people are responsable of what they write !
My regex finds a word
Please, followed later with the nearest wordE-mail, followed later with the nearest wordtreatmentIf, because of some typos, one or several of these
3words are truncated or modified in any way, due to the initial(?s)modifier, the regex engine will always try to find out, by all means, a match, if any !Note that I suppose a possible variation by telling, in my previous post : " Check the
Mach caseoption, if necessary "
Thus :
-
Any malformed word is just considered as stuff, part of the regex part
.+? -
And for the smallest range of characters containing these
3words in that order (Please ... E-mail .... treatment) :-
A
<b>string is inserted before the first wordPlease -
A
</b>string is inserted after the final wordtreatment
-
No more, no less !
BR
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login