Duplicate value in cvs column
-
Hi,
I need to identify duplicate value in 1 column of csv file having 10 columns and mark the row.
The column that am checking for duplicates have 4 digits and it contains alphanumeric and regex like (,@{,},+,-The csv contains 35k records and more.
Thanks in advance
-
@Ramkrishnan-R said in Duplicate value in cvs column:
I need to identify duplicate value in 1 column of csv file having 10 columns and mark the row.
The column that am checking for duplicates have 4 digits and it contains alphanumeric and regex like (,@{,},+,-It is very likely possible using regex and bookmarking, but without seeing an example of the data it makes it very hard to provide a possible solution.
Please read the pinned post called “Please Read This Before Posting” (in the General Discussion area) and a linked FAQ post called “FAQ Desk: Formatting Forum Posts”.
From there, use the information you read to provide samples in the required method so someone can help you.
Issues such as whether any columns in the CSV contain commas also and may therefore be inside of quotes can affect the ability to identify the correct data to check for duplicates.
Terry
-
The data looks like this
Header:
Name|loc|userid|contactnbr|Addresssline1|addressline2|Am searching only inthe “userid” column for duplicate and highlight entire row. It’s present in the 3rd column of csv file.
There is not , in the user id field. That’s validated.
Sample record
Krish|USA|H@+|36 Yorkdale dr|AZ|
Tom|USA|+{6|36 Yorkdale dr|AZ -
@Terry-R
I missed to update the contact nbr field value. -
@Ramkrishnan-R said in Duplicate value in cvs column:
I missed to update the contact nbr field value.
You have NOT followed the request in those pinned posts.
Your data should look like this. It is called a code block and prevents the markdown engine (which drives these posts) from altering the data You could just enter the sample, then select it and click on the </> icon just above the post windowTerry
-
@Ramkrishnan-R said in Duplicate value in cvs column:
I need to identify duplicate value in 1 column of csv file having 10 columns and mark the row.
I’ve done a bit of testing while you wonder my last question.
The initial method (non-destructive) would identify the field on the current line, then look forward to see if another occurrence exists. This does take quite a considerable amount of time. Just think, for the first record in a 35K line file, it needs to search possibly every other line; 34999; to see if the string exists. On the 2nd line it would again search up to 34998 other lines for a match. Even though the searching is done very fast, a test with 36K records found the search took about 12 minutes. The time is dependent on lots of environmental factors but that will give you a idea.
Another method, which is destructive, would be much faster but takes more effort and depending what your intentions are with the result may still require further effort to complete. It involves moving the field to the start of the line, for all lines. Then the file is sorted by this field (as it is at the start of the line). A match can then take place much faster as ONLY the next record needs to be checked as duplicates will ALWAYS be on consecutive lines. However with this method you will ONLY get the duplicate field information, not the actual line is was originally on. For that you would need to use the Find function on the original file, and search for each of the duplicate strings.
Terry
-
@Ramkrishnan-R
Have you tried the CSVLint or CSVQuery plugins?
Those are good solutions for problems like this, although CSVQuery requires you to write a SQL query.
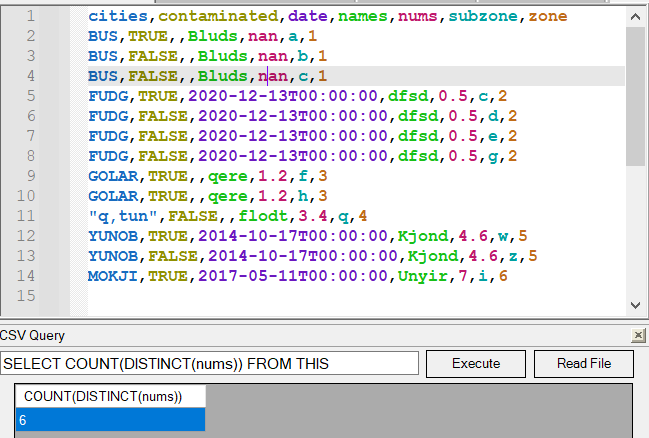
The pretty colors are from CSVLint, and the table view with SQL is from CSVQuery.
Honestly I would just use pandas, but you wanted a solution inside Notepad++ so… -
@Mark-Olson I haven’t tried this tool, let me check…
need some admin permission to install them on my office laptop and that be little hustle. Thank you @Mark-Olson -
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login