Encodage utf-8 sans BOM
-
Hi
Good morning,
For some time, the utf8 encoding without BOM is no longer in the list of encodings.
It’s a shame, for the development and proper functioning of a cms I need this encoding
Can review this position no longer put it?
This editor is very practical, I have been using it for a very long time
Cordially -
@bidule said in Encodage utf-8 sans BOM:
the utf8 encoding without BOM is no longer in the list of encodings
Which list are you referring to?
If you mean “on the Encoding menu”, then, these options are what you seek:
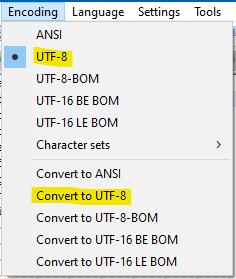
It is true that quite some time ago, these menu entries in Notepad++ had the text “without BOM” on them.
It’s probably better now, anyway. I mean, well, the old way could have said:
UTF-8 without BOM and without pickles and without saltBetter to say what is contained rather than what isn’t.
-
Hello, @bidule, @alan-kilborn and All,
@bidule, probably, your previous installed version was quite old. Because, in very very old Notepad++ releases, the
Encodingmenu look like this :
This picture is, for example, from the
v.6.4.5release of N++Best Regards,
guy038
-
@guy038
Hi J know that,
th version is
I went back with this V7 version, because it is important to keep UTF-8 without BOM.
But why this abandonment?
Already in 2012, it had been reassembled!
Good day -
@bidule said in Encodage utf-8 sans BOM:
But why this abandonment?
There’s no “abandonment”.
If you want “without BOM”, in newer N++, simply chose the command that DOES NOT say “with BOM”.
This is the yellow highlighting in my screenshot earlier.
I realize that you are probably not a native speaker, but please tell us that you understand this. -
Hi, @bidule, @alan-kilborn and All,
Well, I noticed that in my last
v.7.9.2version, compatible with Windows XP, myEncodingmenu looks like this :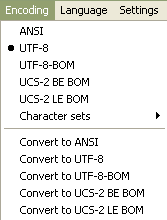
As you notice, between this
v7.9.2screenshot and thev8.5screenshot of @alan-kilborn, in his post, there differences in the names of the nonUTF_8/ANSIencodings :-
For
7.9.2release :-
UCS-2 BE BOM
-
UCS-2 LE BOM
-
Convert to UCS-2 BE BOM
-
Convert to UCS-2 LE BOM
-
-
For
8.5release and versions fromv8.0:-
UTF-16 BE BOM
-
UTF-16 LE BOM
-
Convert to UTF-16 BE BOM
-
Convert to UTF-16 LE BOM
-
The differences is that :
-
The encodings relative to
UCS-2can ONLY encode characters of theBMPUnicode plane, between\x{0000}and\x{FFFF} -
The encodings relative to
UTF-16can encode ALL Unicode characters, between\x{0000}and\x{10FFFF}, as well as theUTF-8encoding
So, since the
v8.0release, there is a significant improvement about writing the exact characters, when they have an Unicode code-point over\x{FFFF}!
However, note that, when you want to search any character over the
BMPso> \x{FFFF}, you MUST use the equivalent surrogate regex syntax of this character !For instance the
💦character, with the Unicode code-point1F4A6cannot be searched with the regex\x{1F4A6}but can be reached with its equivalent regex syntax\x{D83D}\x{DCA6}. Of course, you may also directly paste this specific character in the search field !Refer to any Internet site relative to characters to get the correspondance between the hexadecimal code-point of a character and its
surrogatevalue, expressed in a two consecutive double-byte stringBest Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login