I don't understand why this simple regex doesn't work
-
I have a file containing many lines, and some of the lines contain a single pattern within them like
SID=29394030394.My desire is to remove everything from the file except for those strings.
I have the following in the Find/Replace dialog:
Find what:
^.*?(SID=\d+)?.*
Replace with:\1But it simply removes everything from the file (edit: unless
SID=\d+is the first thing on the line).If I remove the second question mark, i.e.,
^.*?(SID=\d+).*, then it will successfully replace each found instance with just the string, but it leaves the rest of the lines intact.What am I missing?
Sample data:
Lorem ipsum dolor sit amet, libero turpis non cras ligula, id commodo, aenean est in volutpat amet sodales, porttitor bibendum facilisi suspendisse, aliquam ipsum ante morbi sed ipsum SID=324221815251191 mollis. Sollicitudin viverra, vel varius eget sit mollis. Commodo enim aliquam suspendisse tortor cum diam, commodo facilisis, rutrum et duis nisl porttitor, vel eleifend odio ultricies ut, orci in SID=32422181753241& adipiscing felis velit nibh. Consectetuer porttitor feugiat vestibulum sit feugiat, voluptates dui eros libero. Etiam vestibulum at lectus. Donec vivamus. Vel donec et scelerisque vestibulum. Condimentum SID=324221819525920 aliquam, mollit magna velit nec, SID=324221821424161 tempor cursus vitae sit -
@pbarney said in I don’t understand why this simple regex doesn’t work:
But it simply removes everything from the file (edit: unless SID=\d+ is the first thing on the line).
You told it: start at the beginning of the line, grab as few characters as possible until
SID=\d+, putSID=\d+into group 1 if that sequence exists or put nothing into group 1 ifSID=\d+isn’t on that line, and grab every remaining character. Then replace that match with just the contents of group 1. So a match isn’t dependent uponSID=\d+being on that line.If you have
. matches newlinecheckmarked, then the.*?at the beginning will grab every character, including newline, from the beginning of the file (which obviously starts at the beginning of a line) until the firstSID=\d+, wherever that is; then put the SID in the group#1, then grab every character after including newlines all the way to the end of the file. And if you don’t haveSID=\d+anywhere, it won’t care, because you told it to match 0 or 1 instances, so a file without any will just match everything else in the file, set group#1 to empty, and replace everything with that empty string.If you unmark
. matches newline, one might think it will be better, in that each.*?will be limited to a single line of data. But because(SID=\d+)?has the?, it will still match 0 or 1 instance of that, so it will still match lines that don’t haveSID=\d+. (Though it will leave a line ending for each line… how kind)I think what you really want is to make sure
. matches newlineis unchecked (or use(?-s)in your regex, which turns off that feature regardless of the checkmark), and remove the?after(SID=\d+), resulting in just keeping the firstSID=\d+for each line:FIND =
(?-s)^.*?(SID=\d+).*your dummy data becomes
Lorem ipsum dolor sit amet, libero turpis non cras ligula, id commodo, aenean est in volutpat amet sodales, porttitor bibendum facilisi suspendisse, aliquam SID=324221815251191 varius eget sit mollis. Commodo enim aliquam suspendisse tortor cum diam, commodo facilisis, rutrum et duis nisl porttitor, vel eleifend odio ultricies ut, orci in SID=32422181753241 vestibulum sit feugiat, voluptates dui eros libero. Etiam vestibulum at lectus. SID=324221819525920 SID=324221821424161 -
You could look at the problem a slightly different way:
- Use
(SID=[^\x20]+)and replace with\r\n${1}\r\n. This puts all those SID strings on seperate lines. - Then bookmark lines with the
SID=on them. - Then remove non bookmarked lines.
It might sound slightly simplistic and indeed if you are wanting to learn more about regex (and push your boundaries) then it can be done in the manner you want. Someone can provide you with that solution in time, however sometimes looking at the solution and breaking it down can be advantageous.
Terry
- Use
-
@PeterJones, thanks for taking a stab at it. The problem here is that is still leaves other, non-SID data in the file.
So a match isn’t dependent upon SID=\d+ being on that line.
Yes, that is my intention. If there isn’t a
SID=\d+in the line, it should select the entire line and replace it with nothing, but if there is aSID=\d+in the line, it should capture it into group 1, replacing everything on the line with group 1.My attempt here is to render the sample data as:
SID=324221815251191 SID=32422181753241 SID=324221819525920 SID=324221821424161…although I recognize that it will actually contain a number of blank lines, which I’m fine with.
I’m just not sure why it’s not actually capturing my string into the capture group at all.
-
@Terry-R said in I don’t understand why this simple regex doesn’t work:
You could look at the problem a slightly different way […] if you are wanting to learn more about regex (and push your boundaries) then it can be done […] sometimes looking at the solution and breaking it down can be advantageous.
You’re absolutely right! In this case, yes, I am attempting to square up my RegEx skills here, so this question isn’t so much about “how to get the job done” as it is “how to get the job done with RegEx.” In any case, I’ve actually completed the work, I’d just like to know what I’m misunderstanding about my regex.
-
@pbarney said in I don’t understand why this simple regex doesn’t work:
I’d just like to know what I’m misunderstanding about my regex.
I thought that might be the case. I was thinking on some of the steps I’d take when my regex didn’t produce the output I wanted. In your case I’d start like this:
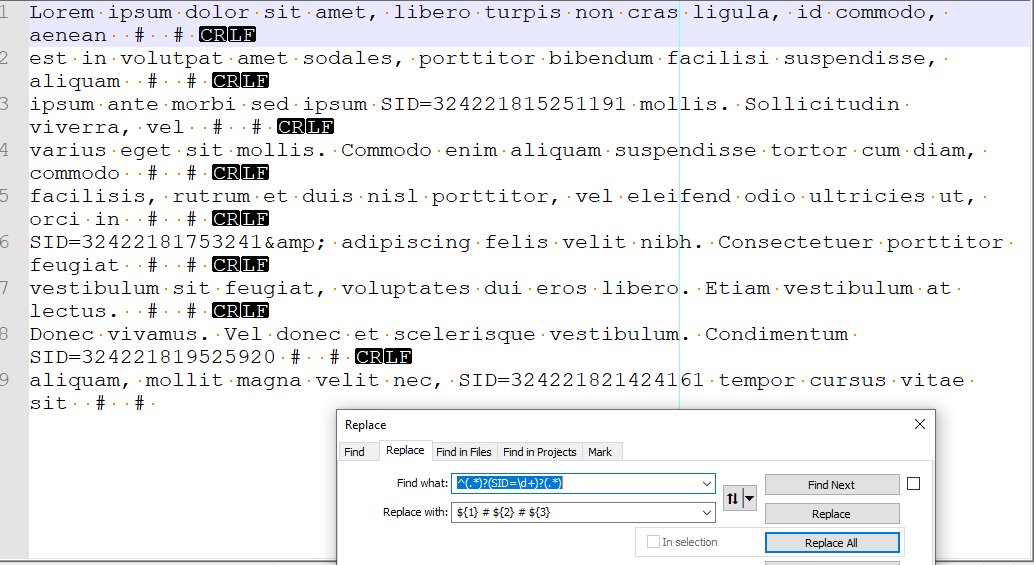
which immediately shows me that the line always seems to put it all into group 1 regardless.
Terry
-
@pbarney said in I don’t understand why this simple regex doesn’t work:
…although I recognize that it will actually contain a number of blank lines, which I’m fine with.
Ah, okay, that wasn’t clear because you didn’t show your desired “after” data.
I’m just not sure why it’s not actually capturing my string into the capture group at all.
Because 0-or-1 instances ofUnfortunately, even with aSID=\d+followed by a greedy number of characters after will allow the characters-after to be greedy and the ? to match 0, thus matching an empty string in the group and the SID and everything after it as part of the.*.$anchor at the end, and making the end one non-greedy, one of the two.*seems to be taking precedence over the 0-or-1 – oh, as Terry’s experiments showed, it appears to be the left.*?.So with that knowledge, I can fix it by using a negative lookahead trick: the pattern
(?!NEG).will match one of any character that is not the start ofNEG, and(?:(?!NEG).)*?will match 0-or-more-characters non-greedy, as long as those characters aren’t the start ofNEG.Taking that concept, replace each
.*?with(?:(?!SID=\d+).)*?, and it will work:- FIND =
(?-s)^(?:(?!SID=\d+).)*?(SID=\d+)?(?:(?!SID=\d+).)*?$ - REPLACE =
$1 - RESULT
… of the 9 lines, 4 are replaced with something and 5 become empty except for newlineSID=324221815251191 SID=32422181753241 SID=324221819525920 SID=324221821424161
- FIND =
-
@PeterJones, wow! Thank you for taking the time to do that. It’s a real trip around the block for what seems like should be just a quick stop next door.
Interestingly, I can get the result I want also, if I break it up into two steps:
Step 1:
.*?(SID=\d+).*
Step 2:.*?(SID=\d+)?.*Not sure why this works. The second step by itself seems to be able to identify when the first group isn’t there, but can’t identify when it is there.
-
Hi @pbarney
… but can’t identify when it is there
Well I don’t have a rigorous answer (without digging deep into regex engine details) except to say the form of the expression
<any text><optional text><any text>gives the engine a lot of freedom, clearly too much, to efficiently meet the match condition.You would benefit from learning about alternates (in matching) and Substitution Conditionals in Substitutions (“Replace with” fields).
Consider:
water milk water bottle carton of milk water bottleTo preserve only watery lines:
Find:(^.*?water.*(?:\R|\z))|^.*(?:\R|\z)
To preserve only milky lines:
Find:(^.*?milk.*(?:\R|\z))|^.*(?:\R|\z)
In either of the above cases use:
Replace with:?1$1:Empty lines anywhere, and trailing lines that don’t have an end-of-line, are handled as one would hope.
Also, when experimenting with F&R actions, ctl-z is a reliable friend.
-
Hello, @pbarney, @peterjones, @terry-r, @neil-schipper and All,
For this specific search, I think we could imagine this process :
-
All the text is a simple single line, so we’ll use the leading
(?s)modifier -
Search for anything followed with a first string
SID=\d+, stored as group1 -
Replace with group
1followed with a line-break, if group1exists -
Redo the two previous steps as long as a
SID=\d+string can be found -
Finally, delete any remaining text, when the
SID=\d+string cannot be found, anymore
Thus, from this INPUT text :
Lorem ipsum dolor sit amet, libero turpis non cras ligula, id commodo, aenean est in volutpat amet sodales, porttitor bibendum facilisi suspendisse, aliquam ipsum ante morbi sed ipsum SID=324221815251191 mollis. Sollicitudin viverra, vel varius eget sit mollis. Commodo enim aliquam suspendisse tortor cum diam, commodo facilisis, rutrum et duis nisl porttitor, vel eleifend odio ultricies ut, orci in SID=32422181753241& adipiscing felis velit nibh. Consectetuer porttitor feugiat vestibulum sit feugiat, voluptates dui eros libero. Etiam vestibulum at lectus. Donec vivamus. Vel donec et scelerisque vestibulum. Condimentum SID=324221819525920 aliquam, mollit magna velit nec, SID=324221821424161 tempor cursus vitae sitThe following regex S/R :
SEARCH
(?xs) .*? ( SID = \d+ ) | .+or(?s).*?(SID=\d+)|.+REPLACE
?1\1\r\nWould immediately produce this OUTPUT text :
SID=324221815251191 SID=32422181753241 SID=324221819525920 SID=324221821424161Best Regards,
guy038
-
-
@Neil-Schipper said:
You would benefit from learning about alternates (in matching) and Substitution Conditionals in Substitutions (“Replace with” fields).
I agree! I’ve used alternates a bit, but I was completely unaware of substitution conditionals. Thank you for pointing that out. I think that will prove to be a powerful tool for me!
-
@guy038, thank you so much for coming up with that. That approach is a less intuitive approach for me, but I’m continuing to learn that there can many ways to approach problems with regular expressions.
I see how yours is working, and it makes complete sense to me now, although I’m still wondering why the regex engine is interpreting my original search in the way that it does. I suppose it will be a mystery for the ages. I’m just happy that you see this stuff clearly enough to point out alternatives.
You’re like a jungle guide who knows where the dangers are on the well-traveled trails, so you know alternate trails to take instead.
-
@pbarney said in I don’t understand why this simple regex doesn’t work:
although I’m still wondering why the regex engine is interpreting my original search in the way that it does.
What I showed in my test to show which group was capturing the characters was that in every line my group 1 captured the entire line.
If you consider your original regex, you gave the first portion a non-greedy option
.*?, then group 1 (inside the brackets) you also gave it the option to NOT capture by using the?.Now in my mind (trying to relate to how the regular expression engine will work) I’m thinking that I start capturing using the
.*?in a non-greedy fashion, eventually getting to the end of the line. I then look at group 1 and as it contains the?as well I feel that I don’t need to backtrack to release characters so group 1 can capture them, so I don’t.As the first portion of your regex satisfied the requirements (matched) and the remainder of the regex didn’t require captures to be made there was no requirement to backtrack.
Terry
-
Hello, @pbarney and All,
I’ll try to explain you why your initial regex
^.*?(SID=\d+)?.*cannot work !To begin with, let’s consider the first part of your regex :
^.*?(SID=\d+)?If you try this regex, against your text :
Lorem ipsum dolor sit amet, libero turpis non cras ligula, id commodo, aenean est in volutpat amet sodales, porttitor bibendum facilisi suspendisse, aliquam ipsum ante morbi sed ipsum SID=324221815251191 mollis. Sollicitudin viverra, vel varius eget sit mollis. Commodo enim aliquam suspendisse tortor cum diam, commodo facilisis, rutrum et duis nisl porttitor, vel eleifend odio ultricies ut, orci in SID=32422181753241& adipiscing felis velit nibh. Consectetuer porttitor feugiat vestibulum sit feugiat, voluptates dui eros libero. Etiam vestibulum at lectus. Donec vivamus. Vel donec et scelerisque vestibulum. Condimentum SID=324221819525920 aliquam, mollit magna velit nec, SID=324221821424161 tempor cursus vitae sitYou’ll note that it always matches a zero-length string but the
6-thline, beginning with theSID=....string. Why ?Well, as you decided to put a lazy quantifier (
*?( or also{0,}?), the regex engine begins to match the minimum string, i.e. the empty string, at beginning of line and, of course, cannot see the stringSID=...at this beginning. But, it does not matter as theSID=...string is optional. So, the regex engine considers that this zero-length match is a correct match for the current line ! And so on till …The
6thline, where theSid=...string does begin the line. So, the regex engine considers this string as a correct match for this6thline. And so on…
Now, when you add the final part
.*, then, at each beginning of line, due to the lazy quantifier, your regex is equivalent to :-
^.*?.*( in other words equivalent to.*), if theSID=...string is not at the beginning of current line. Thus, as the group1is not taken in account, the regex engine simply replaces the current line, without its line-break, with nothing, as the group1is not defined, resulting in an empty line -
(SID=\d+).*if theSID=...string begins the current line. In this case the group1is defined and the regex engine changes all contents of current line with the stringSID=.....
Finally, note that your second regex
^.*?(SID=\d+).*matches ONLY the lines containing aSID=...string. Thus, it’s obvious that the other lines remain untouched !Neverthless, it was easy to solve your problem. You ( and I ) could have thought of this regex S/R !
SEARCH
(?-s)^.*(SID=\d+).*|.+\RREPLACE
\1-
When a line contains the
SID=....string, it just rewrites that string ( group1) -
When a line does not contain a
SID=....string, the second alternative of the regex,.+\Rgrabs all contents of current line WITH its line-break. But, as this second alternative does not refer at all about the group1, nothing is rewritten during the replacement, and the lines are just deleted
Best Regards,
guy038
-