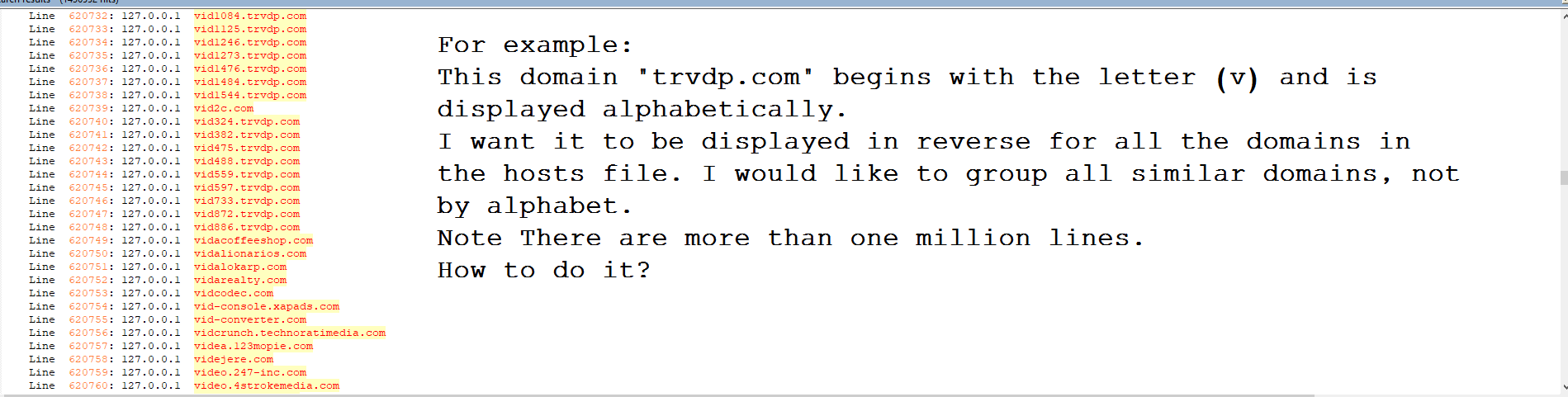
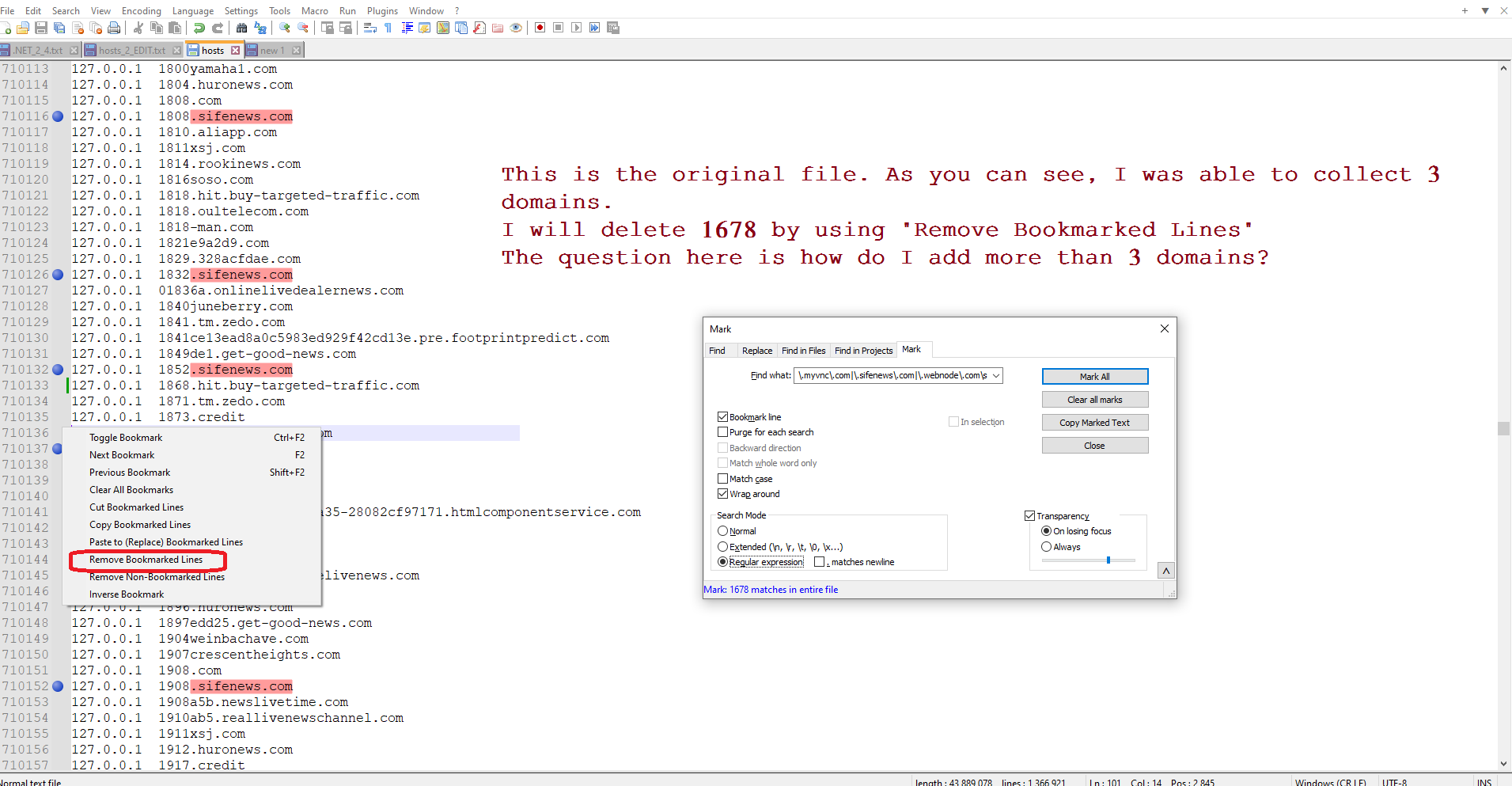
I would like to group all similar domains, not by alphabet.
-
@ guy038 and All,
Thank you my friends for the amazing results.
We have received the correct information. The most commonly used domains cleverly.
In any case, as you can see in the picture, the outcome is wonderful.
How do I write the code like this that you mentioned:
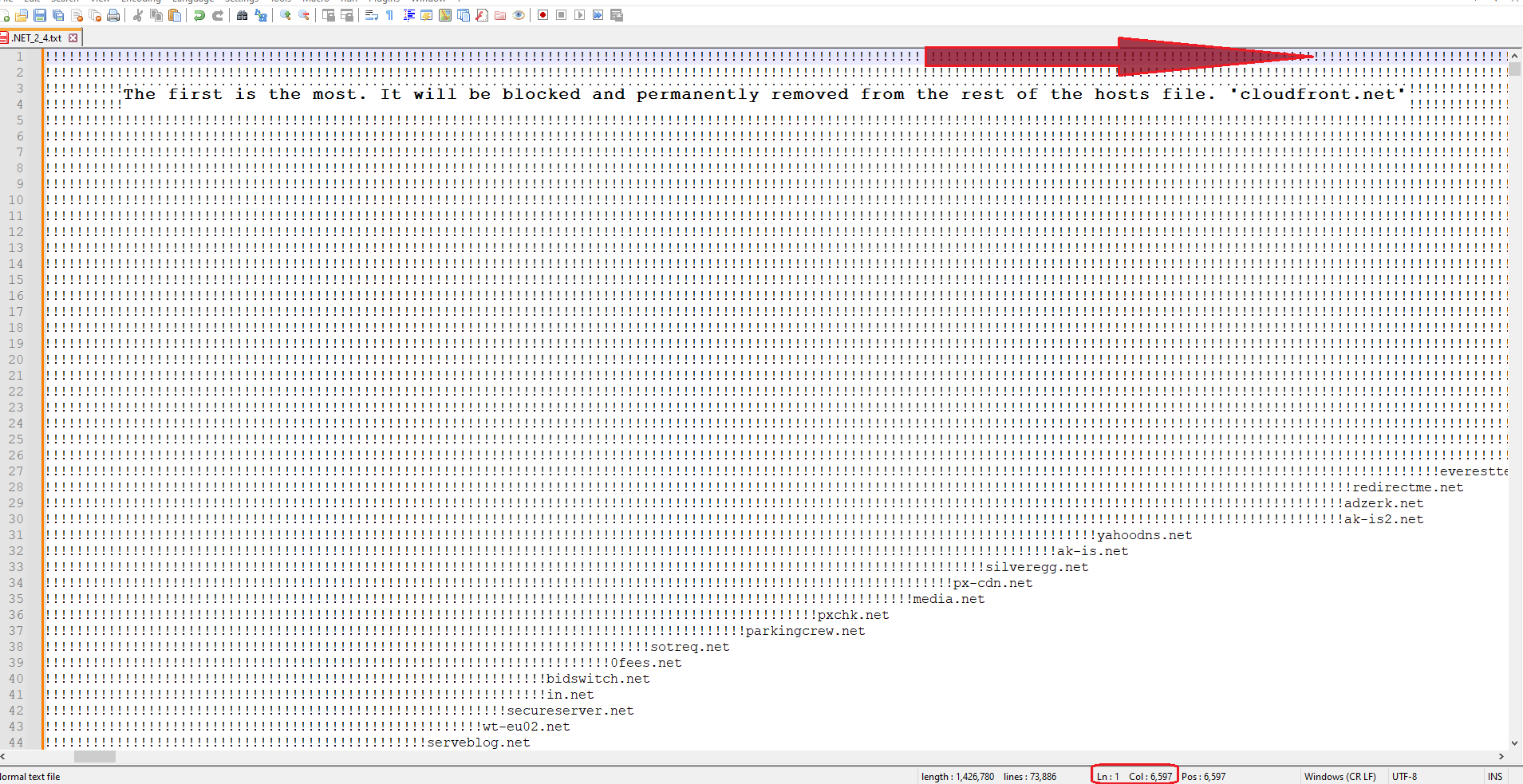
SEARCH (?x-s) ^ ! (?= [^!\r\n]+ ) REPLACE 1\t SEARCH (?x-s) ^ !! (?= [^!\r\n]+ ) REPLACE 2\t SEARCH (?x-s) ^ !!! (?= [^!\r\n]+ ) REPLACE 3\t SEARCH (?x-s) ^ !!!!!!!!!!!!!!!!!!!!!!!!! (?= [^!\r\n]+ ) REPLACE 25\tDid I write until I reached Col: 6,597? I think it is difficult and takes a lot of time. And I want to thank all of you for all your efforts on this fascinating topic.
-
@guy038 OK, I’ll take the bait… If you really want to count exclamation points:
Add the missing exclamation point, but also add a separator:
Find what :
^(!*)
Replace with :$1!/\tNow, group by tens:
Find what :
(!{10})+
Replace with :$0/followed by:
Find what :
!{10}
Replace with :!Repeat the above two steps until the first step finds nothing.
Now, count the exclamation points in each digit and remove the forward slashes:
Find what :
(?:(!{9})|(!{8})|(!{7})|(!{6})|(!{5})|(!{4})|(!{3})|(!{2})|(!{1})|())/
Replace with :(?{1}9)(?{2}8)(?{3}7)(?{4}6)(?{5}5)(?{6}4)(?{7}3)(?{8}2)(?{9}1)(?{10}0)This assumes there are no exclamation points or forward slashes elsewhere in the text. Of course, the forward slash (
/) can be replaced with any character that is not in use. -
Hi, @mohammad-al-thobiti and All,
Let’s recapitulate from the very beginning !
If we start with this kind of INPUT text :
127.0.0.1 a.z.xy.dummy-hyphen.org 127.0.0.1 a.example.com 127.0.0.1 cdef.x.example.com 127.0.0.1 my_site.net 127.0.0.1 b.dummy-hyphen.org 127.0.0.1 b.cde.fgh.example.com 127.0.0.1 abc.defgji.kkkkk.my_site.net 127.0.0.1 cd.xyztuv.ab-cd.4567.example.com 127.0.0.1 dummy-hyphen.org 127.0.0.1 example.comWith the following regex S/R :
SEARCH
(?x) ^ \Q127.0.0.1 \E \h+ (?: [\w-]+ \. )* ( [\w-]+ \. [\w-]+ ) $REPLACE
\1=> We just keep the main domain ;
dummy-hyphen.org example.com example.com my_site.net dummy-hyphen.org example.com my_site.net example.com dummy-hyphen.org example.comOf course, your present file deals with about
181,170lines !So, instead of using the last @coises’s method to find out the different occurrences of each line ( again, a very clever method ! ), I will simplify the goal by using a
Pythonscript to get the job done more quickly !This script is an adaptation from a @alan-kilborn’s script. I named this script
Count_Strings_Occurences.py# -*- coding: utf-8 -*- ''' Adapted from : https://community.notepad-plus-plus.org/topic/20598/show-a-list-of-same-word-before-replacement/2 and .../20 By DEFAULT, this script PASTES, in a NEW tab, a SORTED list of ALL the STRINGS of the CURRENT file, with their NUMBER of occurrences IF a NORMAL selection EXISTS, the script PASTES a SORTED list of ALL the STRINGS of the SELECTION, with their NUMBER of occurrences NOTES : - The CURRENT file processed DO NOT need to be SORTED, in any way ! - If you want a SORTED list of ALL the LINES with their NUMBER of occurrences, don't FORGET to INCLUDE all the POSSIBLE chars of the lines in the REGEX ! For example, if file may contain the line 'zip-archive.net', the REGEX, after editor.research, should be r'[\w.-]+', which includes the DOT and the DASH ! ''' from Npp import editor sel_start = 0 sel_end = editor.getLength() # Refer to : https://community.notepad-plus-plus.org/topic/22378/pythonscript-ops-on-selection-if-any-all-text-otherwise/3 sel_start, sel_end = editor.getUserCharSelection() word_matches = [] def match_found(m): word_matches.append(editor.getTextRange(m.span(0)[0], m.span(0)[1])) editor.research(r'[\w.-]+', match_found, 0 , sel_start, sel_end) histogram_dict = {} for word in word_matches: if word not in histogram_dict: histogram_dict[word] = 1 else: histogram_dict[word] += 1 output_list = [] for k in histogram_dict: output_list.append('{0:.<50} {1}'.format(k, histogram_dict[k])) #for k in histogram_dict: output_list.append('{}={}'.format(k, histogram_dict[k])) # INITIAl format of Alan Kilborn # For SPECIFICATIONS on the OUTPUT format, refer to : # https://doc.python.org/2.7/library/string.html#format-specification-mini-language # https://doc.python.org/2.7/library/string.html#format-examples output_list.sort() editor.copyText('\r\n'.join(output_list)) notepad.new() editor.paste() # console.clear() ; editor.research (r'\w+', lambda m: console.write (m.group(0) + '\n'))
- So, select the random list of
168lines, below.
Note that I suppose that the
IPV4addresses and the sub-domains were previously deletedzioninfosystems.net zingcoach.net ziph.net zinoiosijek031.net zindova.net zip.net zinoiosijek031.net zip-archive.net zinfandelreviews.net zindova.net zip.net zinoiosijek031.net zioninfosystems.net zip-archive.net ziomik.net zioninfosystems.net zip.net zindova.net zindova.net ziph.net ziph.net zinfandelreviews.net zinoiosijek031.net zindova.net zioninfosystems.net zindova.net zip.net zindova.net ziph.net zinfandelreviews.net zinoiosijek031.net ziph.net zinfandelreviews.net zinoiosijek031.net zinfandelreviews.net zinfandelreviews.net ziobaweek.net zinoiosijek031.net zinfandelreviews.net zindova.net zindova.net zinoiosijek031.net zinoiosijek031.net zipaphoto.net zinfandelreviews.net zinfandelreviews.net zingardi.net zip.net zipexpose.net zindova.net zip-archive.net zip-archive.net zindova.net zioninfosystems.net zipexpose.net zipaphoto.net ziph.net zipbah.net zinoiosijek031.net zinfandelreviews.net zip.net zindova.net zip.net zindova.net zingcoach.net zinoiosijek031.net zip.net ziomik.net zindova.net zinoiosijek031.net zioninfosystems.net ziph.net zioninfosystems.net zinfandelreviews.net zingardi.net zinoiosijek031.net zingardi.net zingardi.net ziph.net zingardi.net zinoiosijek031.net zinoiosijek031.net zingcoach.net zindova.net zip.net zindova.net zip-archive.net ziph.net ziobaweek.net zinfandelreviews.net zip.net zinoiosijek031.net zip.net ziomik.net zingardi.net zindova.net zinfandelreviews.net ziph.net ziobaweek.net zinoiosijek031.net zindova.net zinfandelreviews.net zip.net zingcoach.net zip-archive.net zip-archive.net zindova.net zinfandelreviews.net zingardi.net zioninfosystems.net zinoiosijek031.net ziph.net zioninfosystems.net ziobaweek.net zingcoach.net ziph.net zinoiosijek031.net ziobaweek.net zinfandelreviews.net zip.net zinoiosijek031.net ziph.net zinfandelreviews.net zindova.net zindova.net zindova.net zip-archive.net zip.net ziph.net zindova.net zioninfosystems.net zinoiosijek031.net zinoiosijek031.net ziph.net zinfandelreviews.net zip.net zingcoach.net zinfandelreviews.net zinoiosijek031.net zingardi.net zip-archive.net zip.net zinfandelreviews.net zinoiosijek031.net zindova.net zinfandelreviews.net zip.net zioninfosystems.net zingardi.net zioninfosystems.net zip-archive.net zingcoach.net zinoiosijek031.net ziomik.net zip.net zingardi.net zinfandelreviews.net zip-archive.net zindova.net ziomik.net zinoiosijek031.net zindova.net zinoiosijek031.net zinfandelreviews.net zinfandelreviews.net ziph.net zinoiosijek031.net zingardi.net- Run the
Plugins > Python Script > Scripts > Count_Strings_Occurrences.pyPython script
=> At once, a new tab will open with all the results :
zindova.net....................................... 26 zinfandelreviews.net.............................. 24 zingardi.net...................................... 11 zingcoach.net..................................... 7 zinoiosijek031.net................................ 28 ziobaweek.net..................................... 5 ziomik.net........................................ 5 zioninfosystems.net............................... 12 zip-archive.net................................... 11 zip.net........................................... 18 zipaphoto.net..................................... 2 zipbah.net........................................ 1 zipexpose.net..................................... 2 ziph.net.......................................... 16Note that the entries are sorted by the line contents, to easily access any of these !
-
Thus, do a zero-length RECTANGULAR selection of all the numbers of this new tab, at column
52 -
Run the
Edit > Line Operations > Sort Lines As Integers Descendingoption
=> You should get your expected OUTPUT :
zinoiosijek031.net................................ 28 zindova.net....................................... 26 zinfandelreviews.net.............................. 24 zip.net........................................... 18 ziph.net.......................................... 16 zioninfosystems.net............................... 12 zingardi.net...................................... 11 zip-archive.net................................... 11 zingcoach.net..................................... 7 ziobaweek.net..................................... 5 ziomik.net........................................ 5 zipaphoto.net..................................... 2 zipexpose.net..................................... 2 zipbah.net........................................ 1Here you are !
-
Proceed, in the same way, with your present file
-
Switch to your file tab ( selection and sort are not required )
-
Run again the
Plugins > Python Script > Scripts > Count_Strings_Occurrences.pyPython script -
In the opened new tab, do a zero-length RECTANGULAR selection of all the numbers, at column
52 -
Run the
Edit > Line Operations > Sort Lines As Integers Descendingoption
Bingo !
Best Regards,
guy038
- So, select the random list of
-
Hello @ guy038 & All
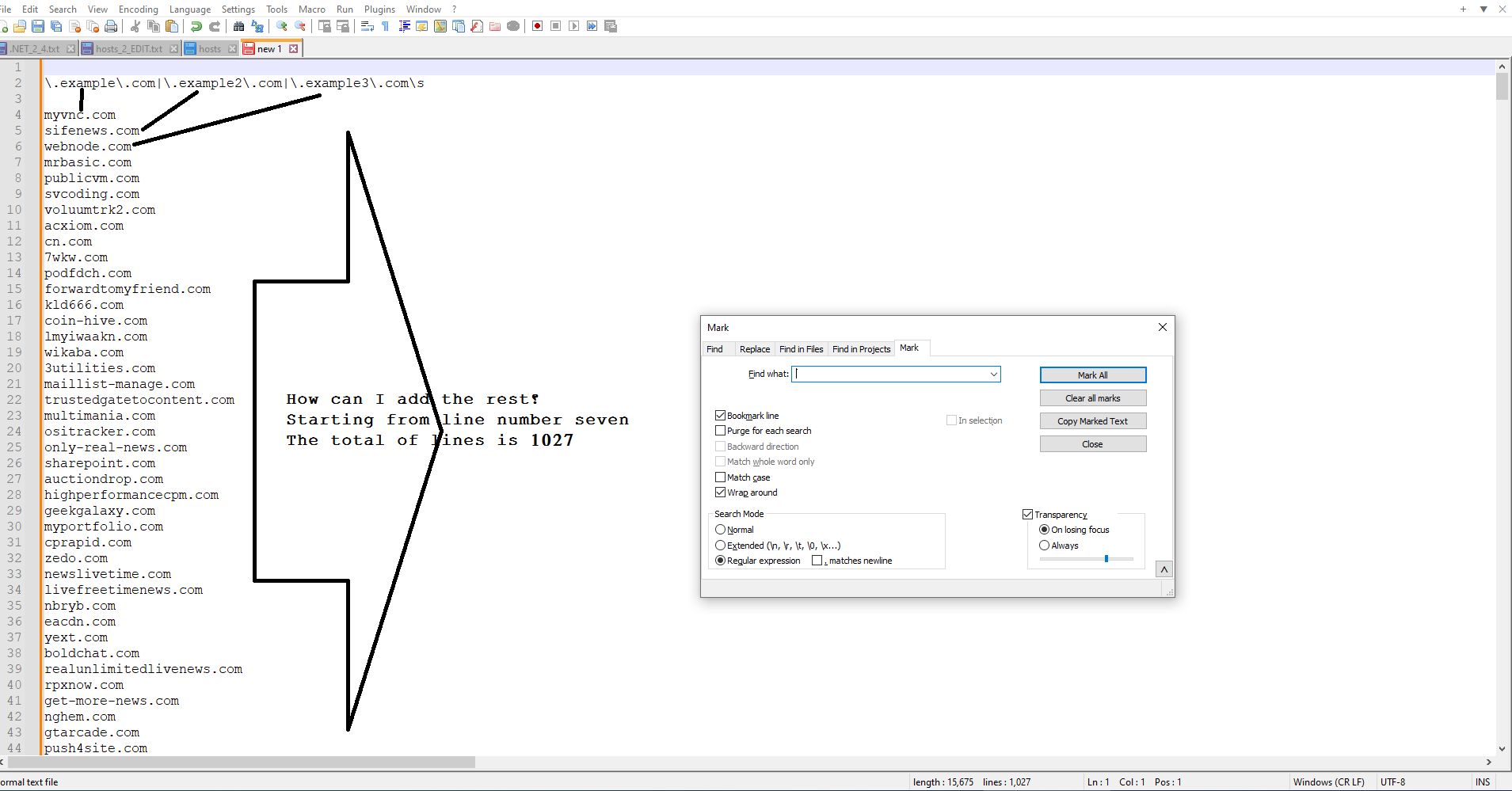
Thank you. everything is ok, I need to add more than one domine to the Find what:
as you can see
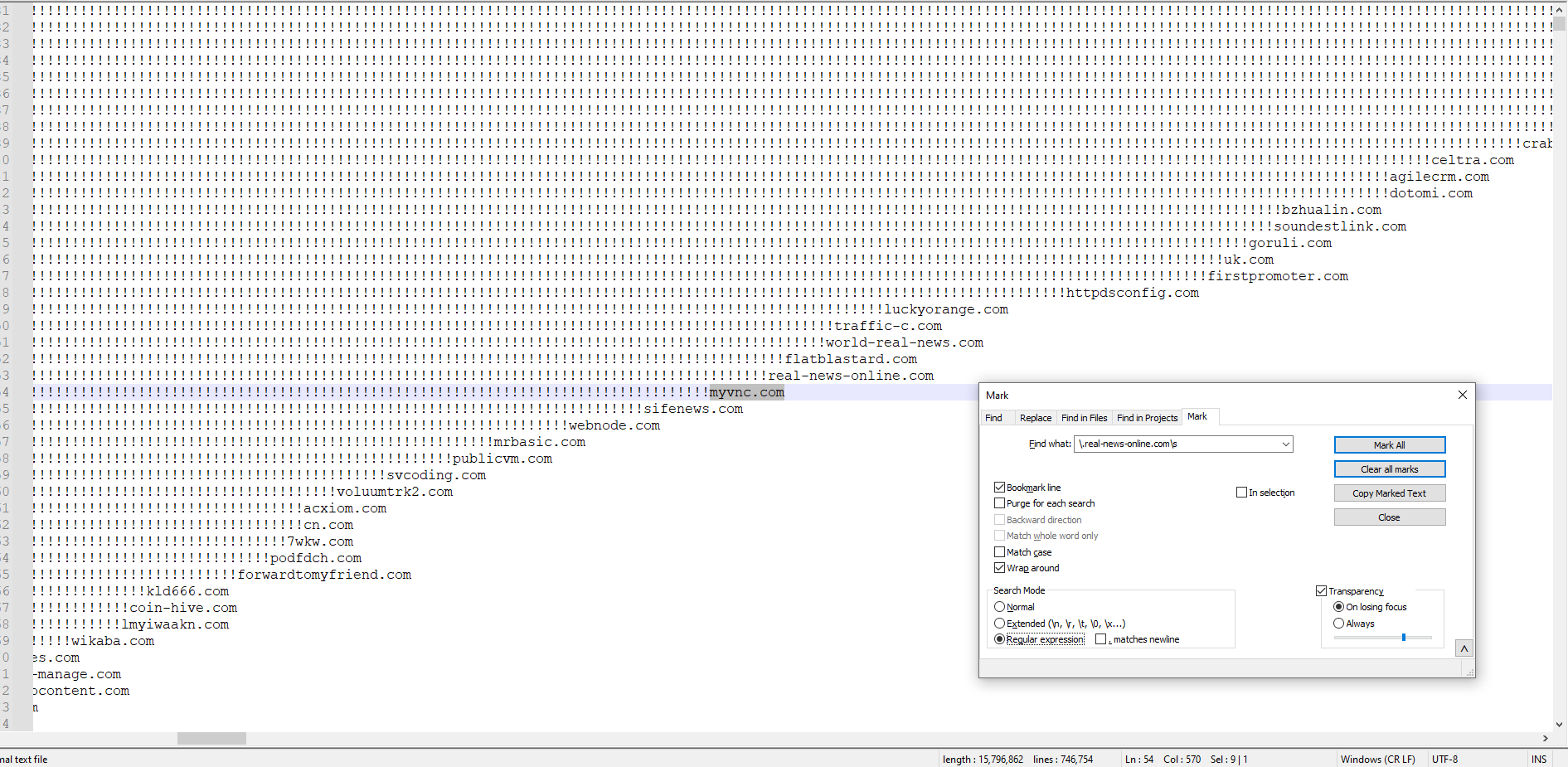
this is the code:\.real-news-online.com, myvnc.com, 1example.com, 2example.com\sis this the correct method?
How can I do this? -
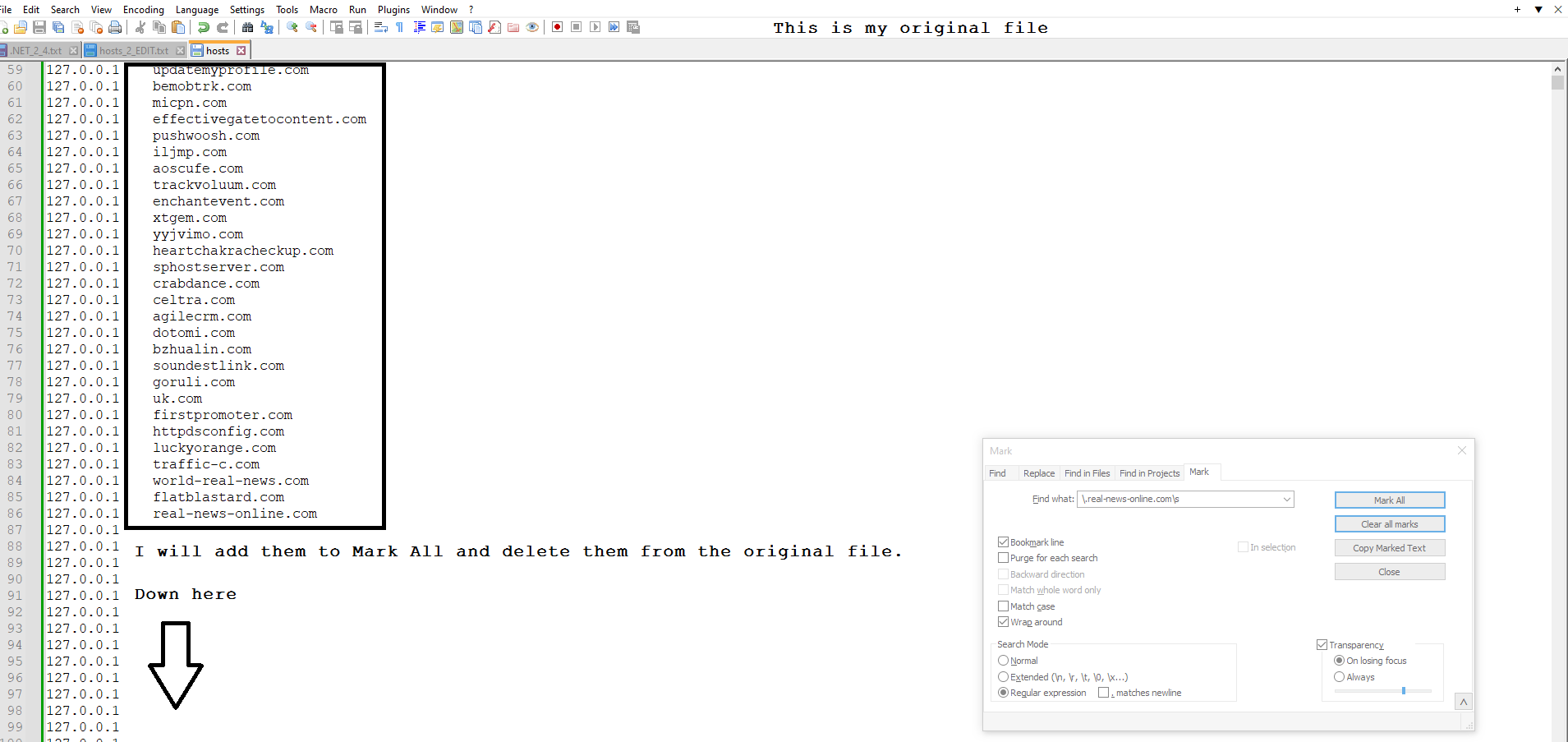
-
.example.com|.example2.com|.example3.com\s
OK
-
-
-
@Mohammad-Al-Thobiti said in I would like to group all similar domains, not by alphabet.:
How can I do this?
At some point, you need to take the lessons you’ve been taught through the dozens of regexes that people have handed you throughout this discussion, and try to figure it out yourself.
-—
Useful References
- Please Read Before Posting
- Template for Search/Replace Questions
- Formatting Forum Posts
- Notepad++ Online User Manual: Searching/Regex
- FAQ: Where to find other regular expressions (regex) documentation
-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
-
@ PeterJones
Ok, Thank you -
Hi, @mohammad-al-thobiti and All,
Again, I’m going to simplify the problem, using a
Pythonscript, calledReplacements_Lists.py, listed below :''' Refer to : https://community.notepad-plus-plus.org/topic/19889/ - Given TWO files : - A MAIN one, located in the MAIN view, containing a LIST of strings or lines - A SECOND one, located in the SECONDARY view, containing : - A LIST of strings to REPLACE, EACH followed with a TABULATION and its CORRESPONDING replacement string This script replaces EACH expression of the MAIN file by the CORRESPONDING replacement string, found in the SECONDARY file NOTES : - The REPLACEMENT strings may be ABSENT IF you do NOT write anything AFTER the TABULATION separator. Thus, these SPECIFIC searched strings will be DELETED - The strings of the MAIN file, NOT found in the SECONDARY file, are simply REWRITTEN - The LEADING strings of the SECONDARY file, NOT found in the MAIN file, are simply NOT used - The list of the DIFFeRENT ranges < SEARCHED string > \t < REPLACEMENT string > must END with a FINAL line-break or NOTHING else ( \z ) ''' from Npp import editor1, editor2 replacements = dict(line.split('\t') for line in editor2.getText().splitlines() if line) def replace_with(m): try: r = replacements[m.group()] except KeyError: r = m.group() return r editor1.rereplace('(?-s).+', replace_with)
So, just follow this road map :
-
Open your entire file containing all your records ( about
181,170) in the main view -
Open your file containing the
1.027lines, whose all the occurrences must be deleted in the main file -
Move this file in the secondary view ( IMPORTANT )
I suppose that these two files ONLY contains main domain names, one per line
Run the
Edit > Blank operations > Trim Leading and Trailing Spaceoption for the two files-
Now, in the secondary view, use this regex S/R :
-
SEARCH
(?<=.)$ -
REPLACE
\t
-
in order to produce a correct replacement list for some domain’s names by nothing
-
Move back to your file in the main view
-
Run the
Plugins > Python Script > Scripts > Replacements_List.pyoption
=> Immediately, all the lines, of the
mainview, which match one of the lines of thesecondaryview, have been replaced with an empty line-
Run the
Edit > Line Operations > Remove Empty Lines -
Finally save your uptaded file, in the main view
Voilà !
Best Regards,
guy038
P.S. :
If you need to install the
Python Scriptplugin, follow this FAQ -
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login