Unicode problem !
-
…but… what is the real issue you are experiencing with this?
Meaning,
\xe9t\xe9really isété, it is just expressed differently when you view it a certain way. So there’s no loss of data…so I’m just wondering why this is a problem for you?For example, here’s two ways to view it; one shows what I presume you want to see, and one shows what your complaint was about:
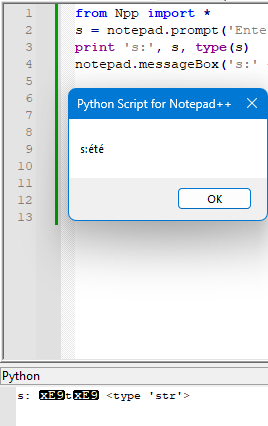
It’s chopped off in the screenshot, but the msgbox’s argument is
's:' + s. -
Hi, @alan-kilborn and All,
Here is my problem :
Let’s start with this simple python script, below :
editor.beginUndoAction() editor.documentStart() Start = editor.getCurrentPos() End = editor.getTextLength() s = notepad.prompt('Enter SEARCH regex:', '', '') if s != None and len(s) > 0: r = notepad.prompt('Enter REPLACE regex:', '', '') if r != None: editor.rereplace(s, r, 0, Start, End) editor.endUndoAction()And create a new tab, containing only these three lines :
fourth quatrième quatriemeAs you can, see the word
quatrièmeis the correct french word for the english wordfourthand, in the third line, it’s just the same word without the accent on letter e !-
Now, run my above script
-
For search =
fourthand replace =4th=> No trouble, the replacement occurs. Logic, as all input text is justASCIItext -
For search =
quatrièmeand replace4ème=> No replacement !? -
For search =
quatriemeand replace =4ème=> a replacement occurs but displays the string4xe8me, with xe8 in inverse video, instead of the french4ème?! -
For search =
quatriemeand replace =4eme=> No trouble again, the replacement occurs, as onlyasciichars have been used, again ! However, it’s far from correct French :-))
BR
guy038
-
-
@alan-kilborn and All,
I forgot to mention that I’m cleaning up the Python scripts on my
old XPlaptop, which is stuck on Notepad++v.7.9.2. So, I cannot install something superior to Python scriptv1.5.4!May be all this issue will be over, after moving these scripts on my new
Windows 10laptop and the installation of Python Scriptv3.0.16!BR
guy038
-
For search = fourth and replace = 4th => No trouble, the replacement occurs. Logic, as all input text is just ASCII text
…For search = quatrieme and replace = 4eme => No trouble again, the replacement occurs, as only ascii chars have been used, again ! However, it’s far from correct French :-))
I can’t replicate any of the problems in those bullet points; I suspect it may have something to do with the language your computer is using, or possibly the fact that you’re using an older PythonScript version.
I personally hate working with diacritics and umlauts because, e.g.,
ècan be represented as (\x300(COMBINING GRAVE ACCENT) followed by ASCIIe) OR literalè(\xe8), and Notepad++ treats them differently even though they are identical graphemes. -
@guy038 said in Unicode problem !:
after moving these scripts on my new Windows 10 laptop and the installation of Python Script v3.0.16
I would recommend this.
Dealing with ANSI encoding issues is a general pain, and that’s what you have when you want to use “special” characters with PS2 (and earlier).But you may still have the trouble @Mark-Olson points out, even with PS3. I know you love regex, but working with “special” characters and regex is, shall we say, challenging. :-(
-
Hello, @mark-olson, @alan-kilborn and All,
You’re probably right about my Python version which must be too old (
v1.5.4) !You said :
I personally hate working with diacritics and umlauts
I can understand your point of view. However, sorry but I"m French and I would like to deal with these accentuated chars as well ! Do you know, for instance, that even the very very old
qbasic.exeprogram of Microsoft does handle them correctly !!If you still have an old
32-bitsmachine, just run this BASIC one-line programLINE INPUT "Votre réponse : ;r$: PRINT r$=> Everything is correctly displayed, even the label ! To be rigorous, on reflection, my qbasic version use theMultilingual Latin_1 850encoding which is still far from Unicode, I’ll give you that !But, nowadays, with the Unicode standard and the universal
UTF-8encoding, I suppose that any computer language should handle these Unicode chars properly !
Luckily, with the help of regexes, I can by-pass the Python script completely and, as said @alan-kilborn, just run the following S/R, even in
Normalmode :-
SEARCH
quatrième -
REPLACE
4ème
Best regards,
guy038
-
-
@guy038 said in Unicode problem !:
For search = quatrieme and replace = 4ème => a replacement occurs but displays the string 4xe8me, with xe8 in inverse video, instead of the french 4ème ?!
It sounds as if your text is in utf-8, but Python is working in Windows-1252, ISO-8859-1 or ISO-8859-15. I presume the problem goes away if your file is “ANSI” rather than Unicode?
I know nothing about Python, but is there some way to tell it to work in utf-8 instead of the current Windows codepage?
-
Probably relevant useful info is here:
https://docs.python.org/3/howto/unicode.htmlDon’t have time to comment on which sections are most relevant here
-
@Mark-Olson said in Unicode problem !:
Probably relevant useful info is here:
https://docs.python.org/3/howto/unicode.htmlActually, since @guy038 is still on PythonScript 1.5.4, it’s using Python 2, not Python 3, so the right URL is https://docs.python.org/2.7/howto/unicode.html , because, as @Alan-Kilborn pointed out, Python 3 did a fundamental change in how it handles unicode strings between 2 and 3.
-
@guy038 said in Unicode problem !:
But, nowadays, with the Unicode standard and the universal UTF-8 encoding, I suppose that any computer language should handle these Unicode chars properly !
TLDR: Unicode is hard.
You know the joke that goes, “There’s a sort of person who sees a problem and thinks, ‘I know! I’ll use regular expressions!’ Now that person has two problems.”? One could say the same of Unicode.
Modern Windows is natively Unicode… but it’s UTF-16. Nearly everything else (including Scintilla) that uses Unicode does it as UTF-8.
And most programming languages — as well as most regular expression implementations! — think of “characters” as fixed-length entities in memory. By choosing UTF-16, Windows at least makes handling the Basic Multilingual Plane fairly straightforward, so long as you don’t mind converting nearly everyone else’s version of Unicode to Windows’ version. OK for short strings… not so good when you have megabytes or gigabytes of file data.
C++ had some limited Unicode-related functions in its standard library, but has now deprecated even those and just says one should use an appropriate library.
Even if you’re willing to convert to UTF-32 (which means quadrupling the storage requirements of ASCII characters), so that every Unicode code point is the same size in memory, not all Unicode characters are a single Unicode code point. The complexity just keeps increasing, and increasing… the hope that Unicode would “simplify” using all the world’s scripts has not exactly been realized.
When I wanted to incorporate Boost.Regex directly into my Columns++ plugin, I first thought to use its Unicode facilities. Then I saw that while Boost.Regex is a header-only library (if you don’t know C++, read that as “easy to include in a project without changing the way the project is structured”), its Unicode facilities require ICU4C — and if there’s any simple, straightforward way to incorporate that monstrosity into an otherwise simple, straightforward project, I couldn’t find it. I settled for the same “hack” that Notepad++ itself uses: convert UTF-8 to UTF-16 on the fly, use Windows’ support of UTF-16 where needed, and let the chips fall where they may for anyone bold enough to use combining characters or characters outside the basic multilingual plane.
Unicode is so complex, so full of details (What characters are “the same” when you ignore case? Well, that depends on the current locale…), that support is a project in itself, and attempts to be reasonably complete (ICU) are gigantic and constantly being updated.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login