How to find copy and replace "quoted text" from one text file to another
-
@Terry-R said in How to find copy and replace "quoted text" from one text file to another:
And since the original solution post DID say it needs to run multiple times I think in your case it would be tedious to continue holding the play button down until 0 occurrences completed shows up.
I do need to keep pressing Replace All to do all entries, but a macro being run a few thousand times should fix that, I already tested this after all. It is not tedious, since I only need to record pressing Replace All once as a macro, and then run that macro a few hundred times, the feature is already in Notepad++.
Anyway, I have an idea:
If I had a regex command that looks for every"name" :field in the file, and replaces"name" : "insert text here"with"name" : "123"then the original regex I used in the OP will work, since the \d+ in it definitely works.Nvm, you already gave me the answer there “[^”]+"
I did the following:
Find what: "name" : "[^"]+"
Replace with: "name" : "123"
then I did Find what:
(?-i)(?:(?<group1>(?-s).+)(?<group2>(?s).+?-{10}.+?"name" : )"\d+)|(?:\R+-{10}\R)
and replace with$+{group2}$+{group1}Finally, Run the recorded macro a few hundred times.
It took about 5 minutes to finish, give or take, but it did it.This actually wasnt so bad.
-
@DankiestCitra said in How to find copy and replace "quoted text" from one text file to another:
“name” : “EC-101 standard magazine”,
“name” : “EC series short barrel”,Well to supply you with what you want here it is:
Find What:(?-s)("name" : ")[^"\r\n]+"
Replace With:${1}1234"It does seem from your many posts in this thread that you are finding the regex very difficult to understand. At some point you do need to start the process of understanding. I don’t mean the one that Scott provided, that is a bit more complex, but this one above should be something you could master very quickly. As a suggestion, there is a FAQ post here that’s a very good starting point. Using the regex101.com site to describe a particular regex will definitely help. Bear in mind that it’s test doesn’t always work on a valid regex for Notepad++, since they use different flavours of regular expression engines, but most of the time it will.
Good luck (with the thousands of runs to complete)
TerryPS, just about to post when I see you got it all on your own, well actually you realised I’d already provided the important bit.
-
Terry-R
Do you know how I can merge 2 lines together, i.e. step #9 in your solution in the other thread?
I want to try this method now, see if its actually better in practice.
And better yet, combine your solution with mkupper’s solution, and get the ideal one for my use. -
@DankiestCitra
As I said in a previous post, you need to provide a small set of examples of the combined data. From that I can cook up a suitable regex.Terry
-
Terry-R
Alright Terry, here it is:001 "name" : "EC-101 standard magazine", 002 "name" : "AK-101 30-round polymer magazine", 003 "name" : "EC-101 tactical magazine", 004 "name" : "AK-101 Circle 10 30-round magazine", 005 "name" : "EC series short barrel", 006 "name" : "AK series standard barrel", 007 "name" : "EC series long barrel", 008 "name" : "AK series long barrel", 009 "name" : "EC Tacto SAVV Pistol grip", 010 "name" : "AK FAB Defense AG-43 pistol grip (black)", 011 "name" : "EC Tacto SAVV Pistol grip desert", 012 "name" : "AK FAB Defence AG-43 pistol grip (Flat Dark Earth)", 013 "name" : "EC standard pistol grip", 014 "name" : "AK standard wood pistol grip", 015 "name" : "EC standard pistol grip", 016 "name" : "AK standard polymer pistol grip",This is step #8, I am trying to get to step #9, which would merge the 2nd line of each pair into position in the first line.
This is tab #3 btw. -
@DankiestCitra
Thanks for the examples.This regex should work (provided data copied perfectly into code block)
Find What:
(?-s)^(\d+).+\R\d+(.+\R)
Replace With:${1}${2}Just so you know what it is doing. It keeps (stores) the first line “line number” as that will be used to place it back into the correct position later on. It then reads over the remainder of that line and the number at the start of the second line (of each pair). Then it reads the remainder of the second line, storing that.
The replace field writes the 2 stored values back.Hope that helps.
TerryPS forgot to add, make sure the last line contains nothing, so in effect add a blank line. this is necessary as the regex expects a CR and/or LF after EVERY line.
-
@Terry-R
But this simply deleted the original ones. What is the point of that? -
@DankiestCitra said in How to find copy and replace "quoted text" from one text file to another:
But this simply deleted the original ones
Nope, you said move merge the 2nd line of each pair into position in the first line. That’s what the regex does. So you will be left with the original line number together with the new data. Isn’t that what you want? Then that tab#3 data can be reinserted into the original file, resorted and the line numbering removed.
Terry
-
@Terry-R
I’m sorry, I know you are probably annoyed a lot by me right now, but this method has confused the hell out of me.
Your regex really did delete every other line, honestly. I am sure I didnt mess it up, its just a copy/paste.I did some digging, found a different regex, and now I use this modified version of it:
Find: (?-s)^(.+)\R(.+)\R
Replace: \1\2\r\nThis successfully merged 2 lines together, every other line.
I will actually go for mkupper’s solution as this is closest to what I really want to do. -
@DankiestCitra said in How to find copy and replace "quoted text" from one text file to another:
I know you are probably annoyed a lot by me right now, but this method has confused the hell out of me.
No, not annoyed but it does seem as if you didn’t understand the concept. When I used your examples and my regex I get this:
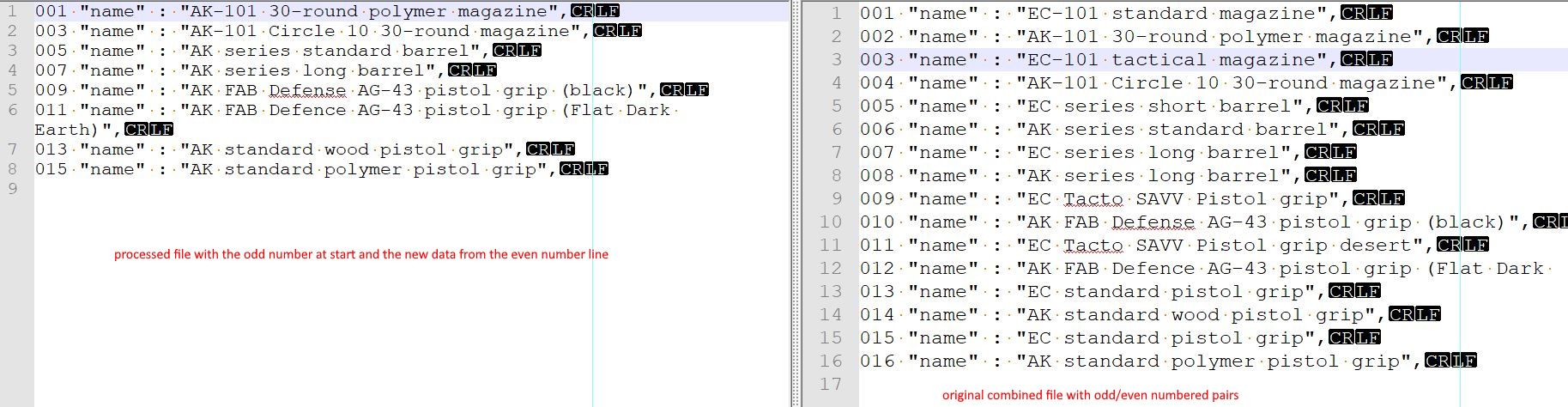
which is what I think you need. There is no need to keep both sets of data as you are only interested in re-inserting this updated data back into the original file. The other file was only a donor and doesn’t need to be kept. or at least if kept then make sure you are working on a copy which you can edit without affecting the real files.
But if you can cobble together a process that makes you feel happy and seems to work for you, then good.
Terry
-
@Terry-R
But why do this long process just to keep the data that I need to insert? I can already do that easily by Marking, bookmarking and Copy/pasting the bookmarked lines.
Then I can manipulate the beginning and end of the text as I see fit, to add/remove spaces, characters at the end, etc.But you are correct in that I didn’t actually understand what your regex was supposed to do, I misunderstood completely, and I apologize for that.
In any case, your solution did help me, because it taught me how to separate the lines into alternating pairs, numbered appropriately, and now I successfully used @mkupper 's solution, together with your steps 1 through 8 (in the other thread), which are fairly straightforward and easy, I formatted the text I wanted into the format that mkupper showed me, and this works and is actually faster and better, with fewer mistakes possible.
Thank you very much @mkupper and @Terry-R for your input, I do realize I am a complete noob, but I did learn some things in the process.
P.S. The solution ended up being quite complicated for me, with more than 16 total steps to complete, but now that I learned it, it just seems easy.
-
@DankiestCitra said in How to find copy and replace "quoted text" from one text file to another:
But why do this long process just to keep the data that I need to insert?
I couldn’t understand that statement until I looked again at my original solution in #16287.
So I think I now see some of your confusion. You tried to follow the steps in #16287, but as I had alluded to earlier I was going to redo it for your requirement. The original solution relied on the data being dissimilar enough that the pairs would align correctly. In the end you just wanted a regex and I complied.
What I should have done was to redo that solution for you. In essence what we need to do for both files is:
- add line numbers to all lines starting from 1 onwards
- bookmark and then cut and paste in another tab the “name” lines
- redo line numbering but this time one set will have odd numbers and the 2nd set will have even numbers. this might mean they are pasted into different tabs first, given new numbers and then combined into 1 tab.
- sort lines based on their line numbering. This combines them so new data is alongside the old data.
- use a regex (as I showed earlier) to combine the 2 lines so that the “original” line number now has the new data. this also removes the 2nd line numbering added in step #3.
- Re-insert the combined data into the original file and re-sort based on line numbers.
- remove the line numbers.
The “donor” file which had the new data was being edited in the process, so that if needed in it’s original state would have meant a copy would be required for this process. The recipient file is being edited, on purpose and can be either a copy (generally the best idea especially when running a new process through the first few times), or the original if the process is tried and true. If a copy then it’s copied over top of the original after spot checking the result.
Hopefully that makes it a bit clearer.
Terry
-
@Terry-R
I already did 1 through 7 basically as you described here, except I do step 7 before inserting the combined data into the original file I want to modify.Everything works smoothly, I did some very very minor adjustments upon mkupper’s regex (for my needs I mean), and even wrote a guide for myself, because I am bound to forget things, so…yeah.
I am not quite sure what you mean about the “donor” file and the “original” here, I am always modifying copies, the original files are always untouched.
Oh and, with this solution now, I simply run the recorded Macro and select Run Macro Multiple Times > Run until the end of the file.
It takes about 1.5 seconds to complete it and go through several thousand lines of code in total :)
It is super fast, and does exactly what I want.In any case, thank you and @mkupper once again, for providing the solution to me, albeit with some slight needed modifications, but still, thanks a lot to both of ya.
-
I’m glad the OP was able to find a solution, and I appreciate the spirit of patience, exploration and iterative improvement that they and everyone else involved in the discussion exhibited throughout this whole process. I have nothing but good things to say about the OP’s attitude, but I still want to make this observation in case they are interested in further improving upon the solution:
While 1.5 seconds to process several thousand lines of code may seem fast, the script I posted above processes several hundred thousand lines of JSON in less than a second.
I am saying this because I believe that the OP has the personality traits of a successful programmer, and it is absolutely within their power, if they believe it is worthwhile, to learn a scripting solution that would provide better performance.
-
T Terry R referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login